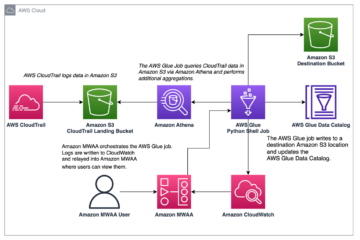
Recentemente, anunciamos a disponibilidade geral de Amazon OpenSearch sem servidor , uma nova opção para Serviço Amazon OpenSearch que facilita a execução de cargas de trabalho de pesquisa e análise em grande escala sem a necessidade de configurar, gerenciar ou dimensionar clusters OpenSearch. Com o OpenSearch Serverless, você obtém os mesmos tempos de resposta interativos em milissegundos que o OpenSearch Service com a simplicidade de um ambiente sem servidor.
Nesta postagem, você aprenderá como migrar seus índices existentes de um domínio de cluster gerenciado do serviço OpenSearch para uma coleção sem servidor usando o Logstash.
Com domínios OpenSearch, você obtém clusters seguros e dedicados configurados e otimizados para suas cargas de trabalho em minutos. Você tem controle total sobre a configuração dos recursos de computação, memória e armazenamento em clusters para otimizar o custo e o desempenho de seus aplicativos. O OpenSearch Serverless oferece uma maneira ainda mais simples de executar cargas de trabalho de pesquisa e análise, sem nunca ter que pensar em clusters. Você simplesmente cria uma coleção e um grupo de índices e pode começar a ingerir e consultar os dados.
Visão geral da solução
Logstash é um software de código aberto que fornece ETL (extrair, transformar e carregar) para seus dados. Você pode configurar o Logstash para se conectar a uma origem e um destino por meio de plug-ins de entrada e saída. No meio, você configura filtros que podem transformar seus dados. Esta postagem orienta você pelas etapas necessárias para configurar o Logstash para conectar um domínio de serviço OpenSearch (entrada) a uma coleção sem servidor OpenSearch (saída).
Você define os plug-ins de origem e destino no arquivo de configuração do Logstash. O arquivo de configuração tem seções para Input, Filter e Output. Uma vez configurado, o Logstash enviará uma requisição para o domínio OpenSearch Service e lerá os dados de acordo com a consulta que você colocou no input seção. Depois que os dados são lidos do serviço OpenSearch, você pode, opcionalmente, enviá-los para o próximo estágio Filter para transformações como adicionar ou remover um campo dos dados de entrada ou atualizar um campo com valores diferentes. Neste exemplo, você não usará o Filter plugar. O próximo é o Output plugar. A versão de código aberto do Logstash (Logstash OSS) fornece uma maneira conveniente de usar a API em massa para fazer upload de dados para suas coleções. O OpenSearch Serverless suporta o logstash-saída-opensearch plug-in de saída, que suporta Gerenciamento de acesso e identidade da AWS (IAM) credenciais para controle de acesso a dados.
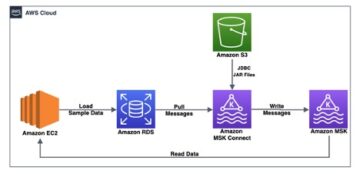
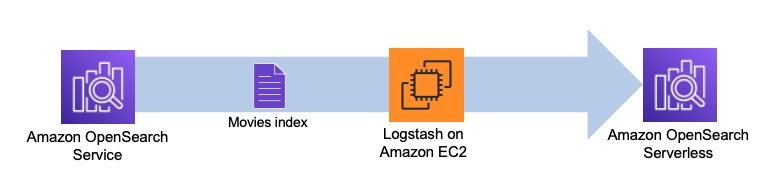
O diagrama a seguir ilustra nosso fluxo de trabalho de solução.
Pré-requisitos
Antes de começar, certifique-se de ter concluído os seguintes pré-requisitos:
- Anote o ARN, o nome de usuário e a senha do domínio do serviço OpenSearch.
- Crie uma coleção sem servidor do OpenSearch. Se você é novo no OpenSearch Serverless, consulte Análise de log da maneira mais fácil com o Amazon OpenSearch Serverless para obter detalhes sobre como configurar sua coleção.
Configure o Logstash e os plug-ins de entrada e saída para OpenSearch
Conclua as etapas a seguir para configurar o Logstash e seus plug-ins:
- Baixar
logstash-oss-with-opensearch-output-plugin. (Este exemplo usa a distro para macos-x64. Para outras distros, consulte o artefatos.) - Extraia o tarball baixado:
- Atualize o
logstash-output-opensearchplugin para a versão mais recente: - Instale o
logstash-input-opensearchplugar:
Teste o plug-in
Vamos entrar em ação e ver como o plugin funciona. O arquivo de configuração a seguir recupera dados do movies indexe em seu domínio de serviço OpenSearch e indexe esses dados em sua coleção sem servidor OpenSearch com o mesmo nome de índice, movies.
Crie um novo arquivo e adicione o seguinte conteúdo e salve o arquivo como opensearch-serverless-migration.conf. Forneça os valores para o endpoint de domínio OpenSearch Service em HOST, NOME DE USUÁRIO e SENHA no input seção e os detalhes do ponto de extremidade da coleção OpenSearch Serverless em HOST e o REGIÃO, AWS_ACCESS_KEY_ID e AWS_SECRET_ACCESS_KEY no output seção.
Você pode especificar uma consulta no input seção da configuração anterior. O match_all consulta corresponde a todos os dados no movies índice. Você pode alterar a consulta se quiser selecionar um subconjunto dos dados. Você também pode usar a consulta para paralelizar a transferência de dados executando vários processos Logstash com configurações que especificam diferentes fatias de dados. Você também pode paralelizar executando processos Logstash em vários índices, se os tiver.
Iniciar logstash
Use o seguinte comando para iniciar o Logstash:
Depois de executar o comando, o Logstash recuperará os dados do índice de origem de seu domínio do OpenSearch Service e gravará no índice de destino em sua coleção OpenSearch Serverless. Quando a transferência de dados é concluída, o Logstash é encerrado. Veja o seguinte código:
Verifique os dados no OpenSearch Serverless
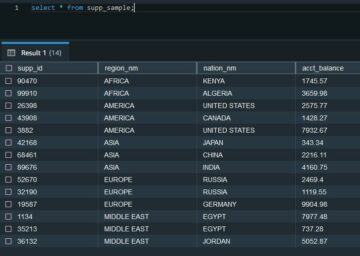
Você pode verificar se o Logstash copiou todos os seus dados comparando a contagem de documentos em seu domínio e sua coleção. Execute a seguinte consulta a partir do ferramentas de desenvolvimento guia ou com curl, postman, ou um cliente HTTP semelhante. A consulta a seguir ajuda você a pesquisar todos os documentos do movies index e retorna os principais documentos junto com a contagem. Por padrão, o OpenSearch retornará a contagem de documentos até um máximo de 10,000. Adicionando o track_total_hits sinalizador ajuda a obter a contagem exata de documentos se a contagem de documentos exceder 10,000.
Conclusão
Nesta postagem, você migrou dados de seu domínio de serviço OpenSearch para sua coleção sem servidor OpenSearch usando os plug-ins de entrada e saída OpenSearch do Logstash.
Fique atento a uma série de postagens com foco nas várias opções disponíveis para você criar análises de log eficazes e soluções de pesquisa usando o OpenSearch Serverless. Você também pode consultar o Introdução ao Amazon OpenSearch Serverless workshop para saber mais sobre o OpenSearch Serverless.
Se você tiver comentários sobre esta postagem, envie-os na seção de comentários. Se você tiver dúvidas sobre esta postagem, inicie um novo tópico no Fórum do Amazon OpenSearch Service or entre em contato com o suporte da AWS.
Sobre os autores
 Prashant Agrawal é Arquiteto de Soluções Especialista em Pesquisa Sênior no Amazon OpenSearch Service. Ele trabalha em estreita colaboração com os clientes para ajudá-los a migrar suas cargas de trabalho para a nuvem e ajuda os clientes existentes a ajustar seus clusters para obter melhor desempenho e economizar custos. Antes de ingressar na AWS, ele ajudou vários clientes a usar o OpenSearch e o Elasticsearch para seus casos de uso de pesquisa e análise de log. Quando não está trabalhando, você pode encontrá-lo viajando e explorando novos lugares. Resumindo, ele gosta de fazer Comer → Viajar → Repetir.
Prashant Agrawal é Arquiteto de Soluções Especialista em Pesquisa Sênior no Amazon OpenSearch Service. Ele trabalha em estreita colaboração com os clientes para ajudá-los a migrar suas cargas de trabalho para a nuvem e ajuda os clientes existentes a ajustar seus clusters para obter melhor desempenho e economizar custos. Antes de ingressar na AWS, ele ajudou vários clientes a usar o OpenSearch e o Elasticsearch para seus casos de uso de pesquisa e análise de log. Quando não está trabalhando, você pode encontrá-lo viajando e explorando novos lugares. Resumindo, ele gosta de fazer Comer → Viajar → Repetir.
 Jon Handler (@_searchgeek) é Arquiteto Principal de Soluções Sênior na Amazon Web Services com sede em Palo Alto, CA. Jon trabalha em estreita colaboração com as equipes CloudSearch e Elasticsearch, fornecendo ajuda e orientação para uma ampla gama de clientes que têm cargas de trabalho de pesquisa que desejam mover para a Nuvem AWS. Antes de ingressar na AWS, a carreira de Jon como desenvolvedor de software incluiu quatro anos de codificação de um mecanismo de pesquisa de comércio eletrônico em larga escala.
Jon Handler (@_searchgeek) é Arquiteto Principal de Soluções Sênior na Amazon Web Services com sede em Palo Alto, CA. Jon trabalha em estreita colaboração com as equipes CloudSearch e Elasticsearch, fornecendo ajuda e orientação para uma ampla gama de clientes que têm cargas de trabalho de pesquisa que desejam mover para a Nuvem AWS. Antes de ingressar na AWS, a carreira de Jon como desenvolvedor de software incluiu quatro anos de codificação de um mecanismo de pesquisa de comércio eletrônico em larga escala.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/migrate-your-indexes-to-amazon-opensearch-serverless-with-logstash/
- 000
- 10
- 100
- 28
- 39
- 7
- a
- Sobre
- Acesso
- Segundo
- Alcançar
- Açao Social
- Depois de
- contra
- Agente
- Todos os Produtos
- Amazon
- Amazon Web Services
- analítica
- e
- anunciou
- api
- aplicações
- disponibilidade
- disponível
- AWS
- baseado
- antes
- Melhor
- entre
- amplo
- construir
- CA
- Oportunidades
- casos
- CD
- alterar
- cliente
- de perto
- Na nuvem
- Agrupar
- código
- Codificação
- coleção
- coleções
- comentários
- comparando
- completar
- Efetuado
- Computar
- Configuração
- Contato
- conteúdo
- ao controle
- Conveniente
- Custo
- crio
- Credenciais
- Clientes
- dados,
- acesso a dados
- dedicado
- Padrão
- destino
- detalhes
- Developer
- diferente
- inválido
- documento
- INSTITUCIONAIS
- fazer
- domínio
- domínios
- down
- comer
- Loja virtual
- Eficaz
- ou
- ElasticSearch
- Ponto final
- Motor
- Meio Ambiente
- Éter (ETH)
- Mesmo
- SEMPRE
- exemplo
- excede
- existente
- Explorando
- extrato
- retornos
- campo
- Envie o
- filtros
- Encontre
- focando
- seguinte
- da
- cheio
- Geral
- ter
- obtendo
- Grupo
- ter
- ajudar
- ajudou
- ajuda
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTTPS
- IAM
- Dados de identificação:
- in
- incluído
- índice
- índices
- Índices
- info
- entrada
- instalar
- interativo
- IT
- juntando
- Saber
- em grande escala
- mais recente
- APRENDER
- carregar
- a Principal
- fazer
- FAZ
- gerencia
- gerenciados
- máximo
- Memória
- migrado
- milissegundo
- minutos
- mais
- mover
- Filmes
- múltiplo
- nome
- você merece...
- Novo
- Próximo
- open source
- Software livre
- Otimize
- otimizado
- Opção
- Opções
- Oss
- Outros
- Palo Alto
- Senha
- atuação
- oleoduto
- Locais
- platão
- Inteligência de Dados Platão
- PlatãoData
- plug-in
- plugins
- Publique
- POSTAGENS
- pré-requisitos
- Diretor
- Prévio
- processos
- fornecer
- fornece
- fornecendo
- colocar
- Frequentes
- alcance
- Leia
- recentemente
- região
- registro
- Removido
- removendo
- repetir
- solicitar
- Recursos
- resposta
- retorno
- Retorna
- Execute
- corredor
- corrida
- mesmo
- Salvar
- Escala
- Pesquisar
- motor de busca
- Seção
- seções
- seguro
- Série
- Serverless
- serviço
- Serviços
- conjunto
- Baixo
- Encerre
- Shuts
- semelhante
- simplicidade
- simplesmente
- Software
- solução
- Soluções
- fonte
- especialista
- Etapa
- começo
- começado
- Passos
- armazenamento
- enviar
- entraram com sucesso
- tal
- suportes
- equipes
- A
- A fonte
- deles
- Através da
- vezes
- para
- topo
- transferência
- Transformar
- transformações
- viagens
- Viagens
- verdadeiro
- para
- Atualizar
- atualização
- usar
- Utilizador
- Valores
- vário
- verificar
- versão
- via
- web
- serviços web
- qual
- QUEM
- precisarão
- sem
- de gestão de documentos
- trabalhar
- trabalho
- oficina
- Workshops
- escrever
- anos
- investimentos
- zefirnet