Pentru a construi orice aplicație AI generativă, este imperativă îmbogățirea modelelor de limbaj mari (LLM) cu date noi. Aici intervine tehnica Retrieval Augmented Generation (RAG). RAG este o arhitectură de învățare automată (ML) care utilizează documente externe (cum ar fi Wikipedia) pentru a-și spori cunoștințele și pentru a obține rezultate de ultimă generație în sarcinile intensive în cunoștințe. . Pentru a ingera aceste surse de date externe, au evoluat bazele de date Vector, care pot stoca înglobări vectoriale ale sursei de date și permit căutări de similaritate.
În această postare, arătăm cum să construim o conductă de asimilare a extragerii, transformării și încărcării RAG (ETL) pentru a ingera cantități mari de date într-un Serviciul Amazon OpenSearch cluster și utilizare Amazon Relational Database Service (Amazon RDS) pentru PostgreSQL cu extensia pgvector ca depozit de date vectoriale. Fiecare serviciu implementează algoritmi k-nearest neighbor (k-NN) sau aproximativ cel mai apropiat vecin (ANN) și metrici de distanță pentru a calcula similaritatea. Introducem integrarea de Rază în mecanismul de recuperare a documentelor contextuale RAG. Ray este o bibliotecă de calcul distribuită, cu sursă deschisă, Python, de uz general. Permite procesării datelor distribuite să genereze și să stocheze înglobări pentru o cantitate mare de date, paralelizând pe mai multe GPU-uri. Folosim un cluster Ray cu aceste GPU-uri pentru a rula asimilarea și interogarea paralelă pentru fiecare serviciu.
În acest experiment, încercăm să analizăm următoarele aspecte pentru serviciul OpenSearch și extensia pgvector pe Amazon RDS:
- Ca magazin de vectori, capacitatea de a scala și de a gestiona un set mare de date cu zeci de milioane de înregistrări pentru RAG
- Posibile blocaje în conducta de ingerare pentru RAG
- Cum să obțineți performanțe optime în timpii de asimilare și de recuperare a interogărilor pentru OpenSearch Service și Amazon RDS
Pentru a înțelege mai multe despre depozitele de date vectoriale și rolul lor în construirea de aplicații AI generative, consultați Rolul depozitelor de date vectoriale în aplicațiile AI generative.
Prezentare generală a serviciului OpenSearch
Serviciul OpenSearch este un serviciu gestionat pentru analiza securizată, căutarea și indexarea datelor de afaceri și operaționale. Serviciul OpenSearch acceptă date la scară petabyte cu capacitatea de a crea mai mulți indici pe text și date vectoriale. Cu o configurație optimizată, urmărește o reamintire ridicată a interogărilor. Serviciul OpenSearch acceptă ANN, precum și căutarea k-NN exactă. OpenSearch Service acceptă o selecție de algoritmi din NMSLIB, FAISS, și Lucene biblioteci pentru a alimenta căutarea k-NN. Am creat indexul ANN pentru OpenSearch cu algoritmul Hierarchical Navigable Small World (HNSW) deoarece este considerat o metodă de căutare mai bună pentru seturi mari de date. Pentru mai multe informații despre alegerea algoritmului de index, consultați Alege algoritmul k-NN pentru cazul tău de utilizare la scară de un miliard cu OpenSearch.
Prezentare generală a Amazon RDS pentru PostgreSQL cu pgvector
Extensia pgvector adaugă o căutare de similaritate vector open source la PostgreSQL. Folosind extensia pgvector, PostgreSQL poate efectua căutări de similaritate pe înglobările vectoriale, oferind companiilor o soluție rapidă și competentă. pgvector oferă două tipuri de căutări de similaritate vectorială: cel mai apropiat vecin exact, care are ca rezultat o reamintire de 100% și cel mai apropiat vecin (ANN), care oferă performanțe mai bune decât căutarea exactă cu un compromis la rechemare. Pentru căutări peste un index, puteți alege câte centre să utilizați în căutare, mai multe centre oferind o reamintire mai bună cu un compromis de performanță.
Prezentare generală a soluțiilor
Următoarea diagramă ilustrează arhitectura soluției.
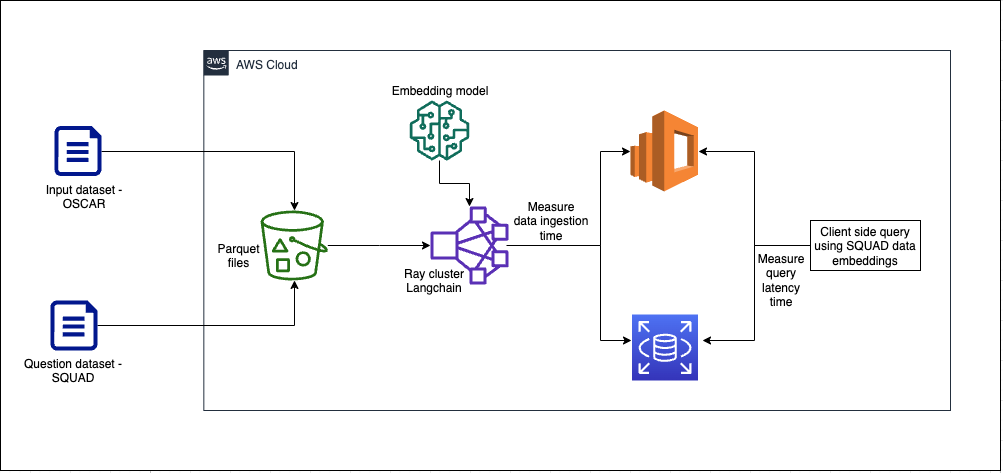
Să ne uităm la componentele cheie mai detaliat.
Setul de date
Folosim datele OSCAR ca corpus și setul de date SQUAD pentru a furniza exemple de întrebări. Aceste seturi de date sunt mai întâi convertite în fișiere Parquet. Apoi folosim un cluster Ray pentru a converti datele Parquet în înglobări. Înglobările create sunt ingerate în OpenSearch Service și Amazon RDS cu pgvector.
OSCAR (Open Super-large Crawled Aggregated corpus) este un uriaș corpus multilingv obținut prin clasificarea și filtrarea limbilor Crawl comun corpus folosind negoliant arhitectură. Datele sunt distribuite în funcție de limbă atât în formă originală, cât și în formă deduplicată. Setul de date Oscar Corpus este de aproximativ 609 milioane de înregistrări și ocupă aproximativ 4.5 TB ca fișiere JSONL brute. Fișierele JSONL sunt apoi convertite în formatul Parquet, ceea ce reduce dimensiunea totală la 1.8 TB. Am redus în continuare setul de date la 25 de milioane de înregistrări pentru a economisi timp în timpul ingerării.
SQuAD (Stanford Question Answering Dataset) este un set de date de înțelegere a lecturii format din întrebări puse de lucrătorii mulțimii pe un set de articole Wikipedia, unde răspunsul la fiecare întrebare este un segment de text sau deschidere, din fragmentul de lectură corespunzător sau întrebarea ar putea fi fără răspuns. Folosim ECHIPĂ, licențiat ca CC-BY-SA 4.0, pentru a oferi exemple de întrebări. Are aproximativ 100,000 de întrebări cu peste 50,000 de întrebări fără răspuns, scrise de lucrători pentru a arăta asemănătoare cu cele care pot răspunde.
Cluster de raze pentru ingerare și crearea de înglobări vectoriale
În testarea noastră, am constatat că GPU-urile au cel mai mare impact asupra performanței la crearea înglobărilor. Prin urmare, am decis să folosim un cluster Ray pentru a ne converti textul brut și a crea înglobările. Rază este un cadru de calcul unificat cu sursă deschisă care permite inginerilor ML și dezvoltatorilor Python să scaleze aplicațiile Python și să accelereze sarcinile de lucru ML. Clusterul nostru a fost format din 5 g4dn.12xlarge Cloud Elastic de calcul Amazon (Amazon EC2). Fiecare instanță a fost configurată cu 4 GPU-uri NVIDIA T4 Tensor Core, 48 vCPU și 192 GiB de memorie. Pentru înregistrările noastre text, am ajuns să le împărțim fiecare în 1,000 de bucăți cu o suprapunere de 100 de bucăți. Aceasta ajunge la aproximativ 200 pe înregistrare. Pentru modelul folosit pentru crearea înglobărilor, ne-am hotărât all-mpnet-base-v2 pentru a crea un spațiu vectorial cu 768 de dimensiuni.
Configurarea infrastructurii
Am folosit următoarele tipuri de instanțe RDS și configurații de cluster de servicii OpenSearch pentru a ne configura infrastructura.
Următoarele sunt proprietățile noastre de tip de instanță RDS:
- Tip de instanță: db.r7g.12xlarge
- Spațiu de stocare alocat: 20 TB
- Multi-AZ: Adevărat
- Stocare criptată: adevărat
- Activați statistici privind performanța: adevărat
- Reținerea Performanței: 7 zile
- Tip de stocare: gp3
- IOPS furnizate: 64,000
- Tip index: FIV
- Număr de liste: 5,000
- Funcția distanță: L2
Următoarele sunt proprietățile clusterului nostru OpenSearch Service:
- Versiune: 2.5
- Noduri de date: 10
- Tipul instanței nodului de date: r6g.4xlarge
- Noduri primare: 3
- Tipul instanței nodului primar: r6g.xlarge
- Index: motor HNSW:
nmslib - Interval de reîmprospătare: 30 de secunde
ef_construction: 256- m: 16
- Funcția distanță: L2
Am folosit configurații mari atât pentru clusterul OpenSearch Service, cât și pentru instanțele RDS, pentru a evita orice blocaj de performanță.
Implementăm soluția folosind un Kit AWS Cloud Development (AWS CDK) stivui, după cum este subliniat în secțiunea următoare.
Implementați stiva AWS CDK
Stack-ul AWS CDK ne permite să alegem OpenSearch Service sau Amazon RDS pentru ingerarea datelor.
Cerințe prealabile
Înainte de a continua cu instalarea, sub cdk, bin, src.tc, modificați valorile booleene pentru Amazon RDS și OpenSearch Service la adevărat sau fals, în funcție de preferințele dvs.
De asemenea, aveți nevoie de un serviciu legat Gestionarea identității și accesului AWS (IAM) pentru domeniul OpenSearch Service. Pentru mai multe detalii, consultați Biblioteca Amazon OpenSearch Service Construct. De asemenea, puteți rula următoarea comandă pentru a crea rolul:
Această stivă AWS CDK va implementa următoarea infrastructură:
- Un VPC
- O gazdă jump (în interiorul VPC)
- Un cluster OpenSearch Service (dacă utilizați serviciul OpenSearch pentru asimilare)
- O instanță RDS (dacă utilizați Amazon RDS pentru asimilare)
- An Manager sistem AWS document pentru implementarea clusterului Ray
- An Serviciul Amazon de stocare simplă (Amazon S3) găleată
- An AWS Adeziv job pentru conversia fișierelor JSONL ale setului de date OSCAR în fișiere Parquet
- Amazon CloudWatch tablouri de bord
Descărcați datele
Rulați următoarele comenzi de la gazda de salt:
Înainte de a clona git repo, asigurați-vă că aveți un profil Hugging Face și acces la corpus de date OSCAR. Trebuie să utilizați numele de utilizator și parola pentru clonarea datelor OSCAR:
Convertiți fișierele JSONL în Parquet
Stack-ul AWS CDK a creat jobul AWS Glue ETL oscar-jsonl-parquet pentru a converti datele OSCAR din JSONL în formatul Parquet.
După ce rulați oscar-jsonl-parquet job, fișierele în format Parquet ar trebui să fie disponibile în folderul parchet din găleata S3.
Descărcați întrebările
De pe gazda dvs. de salt, descărcați datele întrebărilor și încărcați-le în compartimentul S3:
Configurați clusterul Ray
Ca parte a implementării stivei AWS CDK, am creat un document Systems Manager numit CreateRayCluster.
Pentru a rula documentul, parcurgeți următorii pași:
- Pe consola Systems Manager, sub Documente în panoul de navigare, alegeți Deținut de Mine.
- Deschideți
CreateRayClusterdocumentului. - Alege Alerga.
Pagina de comandă de rulare va avea valorile implicite populate pentru cluster.
Configurația implicită solicită 5 g4dn.12xlarge. Asigurați-vă că contul dvs. are limite pentru a accepta acest lucru. Limita relevantă a serviciului este Rularea instanțelor G și VT la cerere. Valoarea implicită pentru aceasta este 64, dar această configurație necesită 240 de procesoare.
- După ce examinați configurația clusterului, selectați gazda de salt ca țintă pentru comanda de rulare.
Această comandă va efectua următorii pași:
- Copiați fișierele cluster Ray
- Configurați clusterul Ray
- Configurați indecșii serviciului OpenSearch
- Configurați tabelele RDS
Puteți monitoriza rezultatul comenzilor pe consola Systems Manager. Acest proces va dura 10-15 minute pentru lansarea inițială.
Rulați ingerarea
Din gazda de salt, conectați-vă la clusterul Ray:
Prima dată când vă conectați la gazdă, instalați cerințele. Aceste fișiere ar trebui să fie deja prezente pe nodul principal.
Pentru oricare dintre metodele de asimilare, dacă primiți o eroare ca următoarea, aceasta este legată de acreditările expirate. Soluția actuală (de la momentul scrierii acestui articol) este plasarea fișierelor de acreditări în nodul Ray head. Pentru a evita riscurile de securitate, nu utilizați utilizatorii IAM pentru autentificare atunci când dezvoltați software special creat sau când lucrați cu date reale. În schimb, utilizați federația cu un furnizor de identitate, cum ar fi AWS IAM Identity Center (succesorul AWS Single Sign-On).
De obicei, acreditările sunt stocate în fișier ~/.aws/credentials pe sistemele Linux și macOS și %USERPROFILE%.awscredentials pe Windows, dar acestea sunt acreditări pe termen scurt cu un token de sesiune. De asemenea, nu puteți suprascrie fișierul de acreditări implicit și, prin urmare, trebuie să creați acreditări pe termen lung fără simbolul de sesiune folosind un nou utilizator IAM.
Pentru a crea acreditări pe termen lung, trebuie să generați o cheie de acces AWS și o cheie de acces secretă AWS. Puteți face asta din consola IAM. Pentru instrucțiuni, consultați Autentificați-vă cu acreditările de utilizator IAM.
După ce creați cheile, conectați-vă la gazda de salt folosind Manager sesiune, o capacitate a Systems Manager și rulați următoarea comandă:
Acum puteți relua pașii de asimilare.
Ingerați date în Serviciul OpenSearch
Dacă utilizați serviciul OpenSearch, rulați următorul script pentru a asimila fișierele:
Când este complet, rulați scriptul care rulează interogări simulate:
Ingerați date în Amazon RDS
Dacă utilizați Amazon RDS, rulați următorul script pentru a asimila fișierele:
Când este finalizat, asigurați-vă că executați un vid complet pe instanța RDS.
Apoi rulați următorul script pentru a rula interogări simulate:
Configurați tabloul de bord Ray
Înainte de a configura tabloul de bord Ray, ar trebui să instalați Interfața liniei de comandă AWS (AWS CLI) pe computerul dvs. local. Pentru instrucțiuni, consultați Instalați sau actualizați cea mai recentă versiune a AWS CLI.
Parcurgeți următorii pași pentru a configura tabloul de bord:
- instalaţi Pluginul Session Manager pentru AWS CLI.
- În contul Isengard, copiați acreditările temporare pentru bash/zsh și rulați în terminalul local.
- Creați un fișier session.sh în mașina dvs. și copiați următorul conținut în fișier:
- Schimbați directorul în care este stocat acest fișier session.sh.
- Rulați comanda
Chmod +xpentru a acorda permisiunea executabilului fișierului. - Rulați următoarea comandă:
De exemplu:
Veți vedea un mesaj ca următorul:
Deschideți o filă nouă în browser și introduceți localhost:8265.
Veți vedea tabloul de bord Ray și statisticile despre joburile și clusterul care rulează. Puteți urmări valorile de aici.
De exemplu, puteți utiliza tabloul de bord Ray pentru a observa încărcarea clusterului. După cum se arată în următoarea captură de ecran, în timpul ingestării, GPU-urile rulează aproape de 100% de utilizare.

Puteți folosi, de asemenea, RAG_Benchmarks Tabloul de bord CloudWatch pentru a vedea rata de absorbție și timpii de răspuns la interogări.
Extensibilitatea soluției
Puteți extinde această soluție pentru a conecta alte magazine de vectori AWS sau terțe părți. Pentru fiecare nou magazin de vectori, va trebui să creați scripturi pentru configurarea depozitului de date, precum și pentru ingerarea datelor. Restul conductei poate fi refolosit după cum este necesar.
Concluzie
În această postare, am împărtășit o conductă ETL pe care o puteți folosi pentru a pune date RAG vectorizate atât în serviciul OpenSearch, cât și în Amazon RDS cu extensia pgvector ca depozite de date vectoriale. Soluția a folosit un cluster Ray pentru a oferi paralelismul necesar pentru a ingera un corpus mare de date. Puteți utiliza această metodologie pentru a integra orice bază de date vectorială la alegere pentru a construi conducte RAG.
Despre Autori
 Randy DeFauw este arhitect principal principal de soluții la AWS. El deține un MSEE de la Universitatea din Michigan, unde a lucrat la viziunea computerizată pentru vehicule autonome. De asemenea, deține un MBA de la Universitatea de Stat din Colorado. Randy a ocupat o varietate de poziții în spațiul tehnologic, de la inginerie software la managementul produselor. A intrat în spațiul big data în 2013 și continuă să exploreze acea zonă. Lucrează activ la proiecte în spațiul ML și a prezentat la numeroase conferințe, inclusiv Strata și GlueCon.
Randy DeFauw este arhitect principal principal de soluții la AWS. El deține un MSEE de la Universitatea din Michigan, unde a lucrat la viziunea computerizată pentru vehicule autonome. De asemenea, deține un MBA de la Universitatea de Stat din Colorado. Randy a ocupat o varietate de poziții în spațiul tehnologic, de la inginerie software la managementul produselor. A intrat în spațiul big data în 2013 și continuă să exploreze acea zonă. Lucrează activ la proiecte în spațiul ML și a prezentat la numeroase conferințe, inclusiv Strata și GlueCon.
 David Christian este un arhitect principal de soluții cu sediul în California de Sud. Are licența în securitatea informațiilor și o pasiune pentru automatizare. Domeniile sale de interes sunt cultura și transformarea DevOps, infrastructura ca cod și reziliența. Înainte de a se alătura AWS, a deținut roluri în securitate, DevOps și inginerie de sistem, gestionând medii cloud private și publice la scară largă.
David Christian este un arhitect principal de soluții cu sediul în California de Sud. Are licența în securitatea informațiilor și o pasiune pentru automatizare. Domeniile sale de interes sunt cultura și transformarea DevOps, infrastructura ca cod și reziliența. Înainte de a se alătura AWS, a deținut roluri în securitate, DevOps și inginerie de sistem, gestionând medii cloud private și publice la scară largă.
 Prachi Kulkarni este arhitect senior de soluții la AWS. Specializarea ei este învățarea automată și lucrează activ la proiectarea de soluții folosind diverse oferte AWS ML, date mari și analize. Prachi are experiență în mai multe domenii, inclusiv asistență medicală, beneficii, comerț cu amănuntul și educație și a lucrat într-o serie de poziții în ingineria și arhitectura de produs, management și succesul clienților.
Prachi Kulkarni este arhitect senior de soluții la AWS. Specializarea ei este învățarea automată și lucrează activ la proiectarea de soluții folosind diverse oferte AWS ML, date mari și analize. Prachi are experiență în mai multe domenii, inclusiv asistență medicală, beneficii, comerț cu amănuntul și educație și a lucrat într-o serie de poziții în ingineria și arhitectura de produs, management și succesul clienților.
 Richa Gupta este arhitect de soluții la AWS. Este pasionată de arhitectura de soluții end-to-end pentru clienți. Specializarea ei este învățarea automată și modul în care aceasta poate fi folosită pentru a construi noi soluții care să conducă la excelență operațională și să genereze veniturile afacerii. Înainte de a se alătura AWS, ea a lucrat în calitate de inginer software și arhitect de soluții, construind soluții pentru marii operatori de telecomunicații. În afara serviciului, îi place să exploreze locuri noi și adoră activitățile de aventură.
Richa Gupta este arhitect de soluții la AWS. Este pasionată de arhitectura de soluții end-to-end pentru clienți. Specializarea ei este învățarea automată și modul în care aceasta poate fi folosită pentru a construi noi soluții care să conducă la excelență operațională și să genereze veniturile afacerii. Înainte de a se alătura AWS, ea a lucrat în calitate de inginer software și arhitect de soluții, construind soluții pentru marii operatori de telecomunicații. În afara serviciului, îi place să exploreze locuri noi și adoră activitățile de aventură.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/
- :are
- :este
- :Unde
- $3
- $UP
- 000
- 1
- 10
- 100
- 15%
- 150
- 2%
- 20
- 200
- 2013
- 25
- 254
- 30
- 4
- 410
- 48
- 5
- 50
- 7
- 8
- 9
- a
- capacitate
- Despre Noi
- accelera
- acces
- Cont
- Obține
- peste
- activ
- activităţi de
- Adaugă
- aventuros
- agregate
- AI
- isi propune
- Algoritmul
- algoritmi
- permite
- permite
- deja
- de asemenea
- Amazon
- Amazon EC2
- Amazon RDS
- Amazon Web Services
- sumă
- Sume
- an
- analiză
- Google Analytics
- analiza
- și
- ann
- răspunde
- telefonic
- Orice
- Apache
- aplicație
- aplicatii
- aproximativ
- aproximativ
- arhitectură
- SUNT
- ZONĂ
- domenii
- bunuri
- AS
- aspecte
- At
- atașa
- încercare
- spori
- augmented
- Autentificare
- Automatizare
- autonom
- autovehicule autonome
- disponibil
- evita
- AWS
- Formarea AWS Cloud
- AWS Adeziv
- bazat
- BE
- deoarece
- Beneficiile
- Mai bine
- Mare
- Datele mari
- Cea mai mare
- BIN
- corp
- atât
- blocaje
- pauze
- browser-ul
- construi
- Clădire
- afaceri
- întreprinderi
- dar
- by
- calcula
- California
- denumit
- CAN
- capacitate
- Capacitate
- caz
- CAT
- CD
- Centru
- Centre
- Schimbare
- alegere
- Alege
- clasificare
- cli
- Închide
- Cloud
- Grup
- cod
- Colorado
- COM
- vine
- Completă
- componente
- Calcula
- calculator
- Computer Vision
- tehnica de calcul
- conferințe
- Configuraţie
- configuraţiile
- configurat
- configurarea
- Conectați
- Conectarea
- Conexiuni
- Constând
- Consoleze
- construi
- conţinut
- contextual
- continuă
- converti
- convertit
- de conversie a
- copiaţi
- Nucleu
- Corespunzător
- crea
- a creat
- Crearea
- CREDENTIALĂ
- scrisori de acreditare
- mulţime
- Cultură
- Curent
- client
- Succesul clienților
- clienţii care
- tablou de bord
- de date
- de prelucrare a datelor
- Baza de date
- baze de date
- seturi de date
- hotărât
- Mod implicit
- În funcție
- implementa
- Implementarea
- desfășurarea
- proiect
- detaliu
- detalii
- Dezvoltatorii
- în curs de dezvoltare
- Dezvoltare
- DevOps
- diagramă
- director
- distanţă
- distribuite
- calcul distribuit
- prelucrare distribuită a datelor
- do
- document
- documente
- domeniu
- domenii
- făcut
- Dont
- jos
- Descarca
- conduce
- în timpul
- fiecare
- ecou
- Educaţie
- oricare
- permite
- criptate
- un capăt la altul
- încheiat
- Motor
- inginer
- Inginerie
- inginerii
- îmbogățitor
- Intrați
- a intrat
- medii
- eroare
- Eter (ETH)
- Fiecare
- evoluat
- exact
- exemplu
- Excelență
- experienţă
- experiment
- explora
- exporturile
- extinde
- extensie
- extern
- extrage
- Față
- fals
- Federaţie
- Fișier
- Fişiere
- filtrare
- First
- prima dată
- Concentra
- următor
- Pentru
- formă
- format
- Înainte
- găsit
- Cadru
- din
- Complet
- funcţie
- mai mult
- General
- genera
- generaţie
- generativ
- AI generativă
- obține
- merge
- GitHub
- Da
- unități de procesare grafică
- manipula
- Avea
- he
- cap
- de asistență medicală
- Held
- ei
- aici
- Înalt
- lui
- deține
- gazdă
- Cum
- Cum Pentru a
- HTML
- http
- HTTPS
- mare
- IAM
- ID
- Identitate
- if
- ilustrează
- Impactul
- imperativ
- ustensile
- in
- În altele
- Inclusiv
- index
- indexurile
- informații
- securitatea informațiilor
- Infrastructură
- inițială
- în interiorul
- înţelegere
- perspective
- instala
- instalare
- instanță
- cazuri
- in schimb
- instrucțiuni
- integra
- integrare
- interval
- în
- introduce
- IT
- ESTE
- Loc de munca
- Locuri de munca
- aderarea
- jpeg
- jpg
- JSON
- a sari
- Cheie
- chei
- cunoştinţe
- limbă
- mare
- pe scară largă
- Ultimele
- lansa
- conduce
- învăţare
- biblioteci
- Bibliotecă
- Autorizat
- ca
- îi place
- LIMITĂ
- Limitele
- Linie
- linux
- liste
- încărca
- local
- pe termen lung
- Uite
- iubeste
- maşină
- masina de învățare
- MacOS
- face
- gestionate
- administrare
- manager
- de conducere
- multe
- MBA
- mecanism
- Memorie
- mesaj
- metodă
- Metodologie
- Metode
- Metrici
- Michigan
- ar putea
- milion
- milioane
- minimizează
- minute
- ML
- model
- Modele
- monitor
- mai mult
- multiplu
- nume
- Navigare
- necesar
- Nevoie
- necesar
- vecin
- Nou
- noi soluții
- Nu.
- nod
- noduri
- Nici unul
- numeroși
- Nvidia
- observa
- obținut
- of
- ofertele
- on
- La cerere
- cele
- deschide
- open-source
- deschis
- operațional
- Operatorii
- optimă
- optimizate
- or
- original
- Oscar
- Altele
- al nostru
- afară
- a subliniat
- producție
- exterior
- peste
- suprapune
- trece peste
- pagină
- pâine
- Paralel
- parte
- trecere
- pasiune
- pasionat
- Parolă
- pentru
- efectua
- performanță
- permisiune
- piese
- conducte
- Loc
- Locuri
- Plato
- Informații despre date Platon
- PlatoData
- ștecher
- populat
- pozat
- poziţii
- Post
- postgresql
- putere
- prezenta
- prezentat
- Principal
- anterior
- privat
- proces
- prelucrare
- Produs
- management de produs
- Profil
- Proiecte
- proprietăţi
- furniza
- furnizorul
- furnizează
- furnizarea
- public
- Norul public
- scop
- pune
- Piton
- interogări
- întrebare
- întrebare
- Întrebări
- cârpă
- gamă
- variind
- rată
- Crud
- RAY
- Citind
- real
- record
- înregistrări
- trimite
- privit
- regiune
- legate de
- cereri de
- Cerinţe
- Necesită
- răspuns
- timpii de răspuns
- REST
- REZULTATE
- cu amănuntul
- retenţie
- regăsire
- reutilizate
- venituri
- revizuiască
- Riscurile
- Rol
- rolurile
- Alerga
- funcţionare
- ruleaza
- probă
- Economisiți
- Scară
- scalate
- scenariu
- script-uri
- Caută
- Cautari
- Secret
- Secțiune
- sigur
- securitate
- riscuri de securitate
- vedea
- segment
- selecta
- selecţie
- senior
- serviciu
- Servicii
- sesiune
- set
- Stabilit
- comun
- ea
- Pe termen scurt
- să
- Arăta
- indicat
- asemănător
- simplu
- singur
- Mărimea
- mic
- So
- Software
- Inginer Software
- Inginerie software
- soluţie
- soluţii
- Sursă
- Surse
- Sudic
- Spaţiu
- rapid
- stivui
- stanford
- Pornire
- Stat
- de ultimă oră
- statistică
- paşi
- depozitare
- stoca
- stocate
- magazine
- succes
- astfel de
- a sustine
- Sprijină
- sigur
- sincronizare
- sistem
- sisteme
- Lua
- ia
- Ţintă
- sarcini
- tehnică
- Tehnologia
- telecom
- temporar
- zeci
- Terminal
- Testarea
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- decât
- acea
- lor
- apoi
- prin urmare
- Acestea
- terț
- acest
- timp
- ori
- la
- semn
- Total
- urmări
- Transforma
- Transformare
- adevărat
- Două
- tip
- Tipuri
- în
- înţelege
- unificat
- universitate
- Universitatea din Michigan
- Actualizează
- us
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizatorii
- utilizări
- folosind
- folosire
- Utilizand
- Vid
- Valori
- varietate
- diverse
- vector
- Vehicule
- versiune
- viziune
- Aşteptare
- a fost
- we
- web
- servicii web
- BINE
- cand
- care
- Wikipedia
- voi
- ferestre
- cu
- fără
- Apartamente
- a lucrat
- muncitorii
- de lucru
- lume
- scris
- scris
- tu
- Ta
- zephyrnet