Cu utilizarea cloud computingului, a datelor mari și a instrumentelor de învățare automată (ML), cum ar fi Amazon Atena or Amazon SageMaker au devenit disponibile și utilizabile de oricine fără prea mult efort în crearea și întreținerea. Companiile industriale se uită din ce în ce mai mult la analiza datelor și la luarea deciziilor bazate pe date pentru a crește eficiența resurselor în întregul lor portofoliu, de la operațiuni până la efectuarea de întreținere predictivă sau planificare.
Datorită vitezei de schimbare în IT, clienții din industriile tradiționale se confruntă cu o dilemă de competențe. Pe de o parte, analiștii și experții în domeniu au o cunoaștere foarte profundă a datelor în cauză și a interpretării acestora, dar adesea le lipsește expunerea la instrumentele de știință a datelor și limbaje de programare la nivel înalt, cum ar fi Python. Pe de altă parte, experții în știința datelor nu au adesea experiența necesară pentru a interpreta conținutul datelor mașinii și a-l filtra pentru ceea ce este relevant. Această dilemă împiedică crearea de modele eficiente care utilizează date pentru a genera perspective relevante pentru afaceri.
Amazon SageMaker Canvas abordează această dilemă oferind experților din domeniu o interfață fără cod pentru a crea modele de analiză și ML puternice, cum ar fi modele de prognoză, clasificare sau regresie. De asemenea, vă permite să implementați și să partajați aceste modele cu specialiștii ML și MLOps după creare.
În această postare, vă arătăm cum să utilizați SageMaker Canvas pentru a selecta și selecta caracteristicile potrivite din datele dvs., apoi pregătiți un model de predicție pentru detectarea anomaliilor, folosind funcționalitatea fără cod a SageMaker Canvas pentru reglarea modelului.
Detectarea anomaliilor pentru industria prelucrătoare
La momentul scrierii, SageMaker Canvas se concentrează pe cazuri tipice de utilizare în afaceri, cum ar fi prognoza, regresia și clasificarea. Pentru această postare, demonstrăm cum aceste capabilități pot ajuta, de asemenea, la detectarea punctelor complexe de date anormale. Acest caz de utilizare este relevant, de exemplu, pentru a identifica defecțiunile sau operațiunile neobișnuite ale mașinilor industriale.
Detectarea anomaliilor este importantă în domeniul industriei, deoarece mașinile (de la trenuri la turbine) sunt în mod normal foarte fiabile, cu perioade între defecțiuni care se întind pe ani. Majoritatea datelor de la aceste mașini, cum ar fi citirile senzorului de temperatură sau mesajele de stare, descriu funcționarea normală și au o valoare limitată pentru luarea deciziilor. Inginerii caută date anormale atunci când investighează cauzele fundamentale ale unei defecțiuni sau ca indicatori de avertizare pentru erori viitoare, iar managerii de performanță examinează datele anormale pentru a identifica potențiale îmbunătățiri. Prin urmare, primul pas tipic în trecerea către luarea deciziilor bazate pe date se bazează pe găsirea acelor date relevante (anormale).
În această postare, folosim SageMaker Canvas pentru a selecta și selecta caracteristicile potrivite în date, apoi antrenăm un model de predicție pentru detectarea anomaliilor, folosind funcționalitatea fără cod SageMaker Canvas pentru reglarea modelului. Apoi implementăm modelul ca punct final SageMaker.
Prezentare generală a soluțiilor
Pentru cazul nostru de utilizare de detectare a anomaliilor, antrenăm un model de predicție pentru a prezice o trăsătură caracteristică pentru funcționarea normală a unei mașini, cum ar fi temperatura motorului indicată într-o mașină, din caracteristici care influențează, cum ar fi viteza și cuplul recent aplicat în mașină. . Pentru detectarea anomaliilor pe un eșantion nou de măsurători, comparăm predicțiile modelului pentru caracteristica caracteristică cu observațiile furnizate.
Pentru exemplul motorului mașinii, un expert în domeniu obține măsurători ale temperaturii normale a motorului, cuplului motor recent, temperatura ambiantă și alți factori potențiali de influență. Acestea vă permit să antrenați un model pentru a prezice temperatura din celelalte caracteristici. Apoi putem folosi modelul pentru a prezice temperatura motorului în mod regulat. Când temperatura prezisă pentru acele date este similară cu temperatura observată în acele date, motorul funcționează normal; o discrepanță va indica o anomalie, cum ar fi defecțiunea sistemului de răcire sau o defecțiune a motorului.
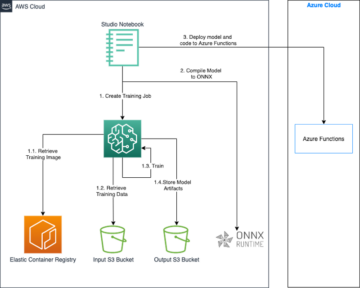
Următoarea diagramă ilustrează arhitectura soluției.
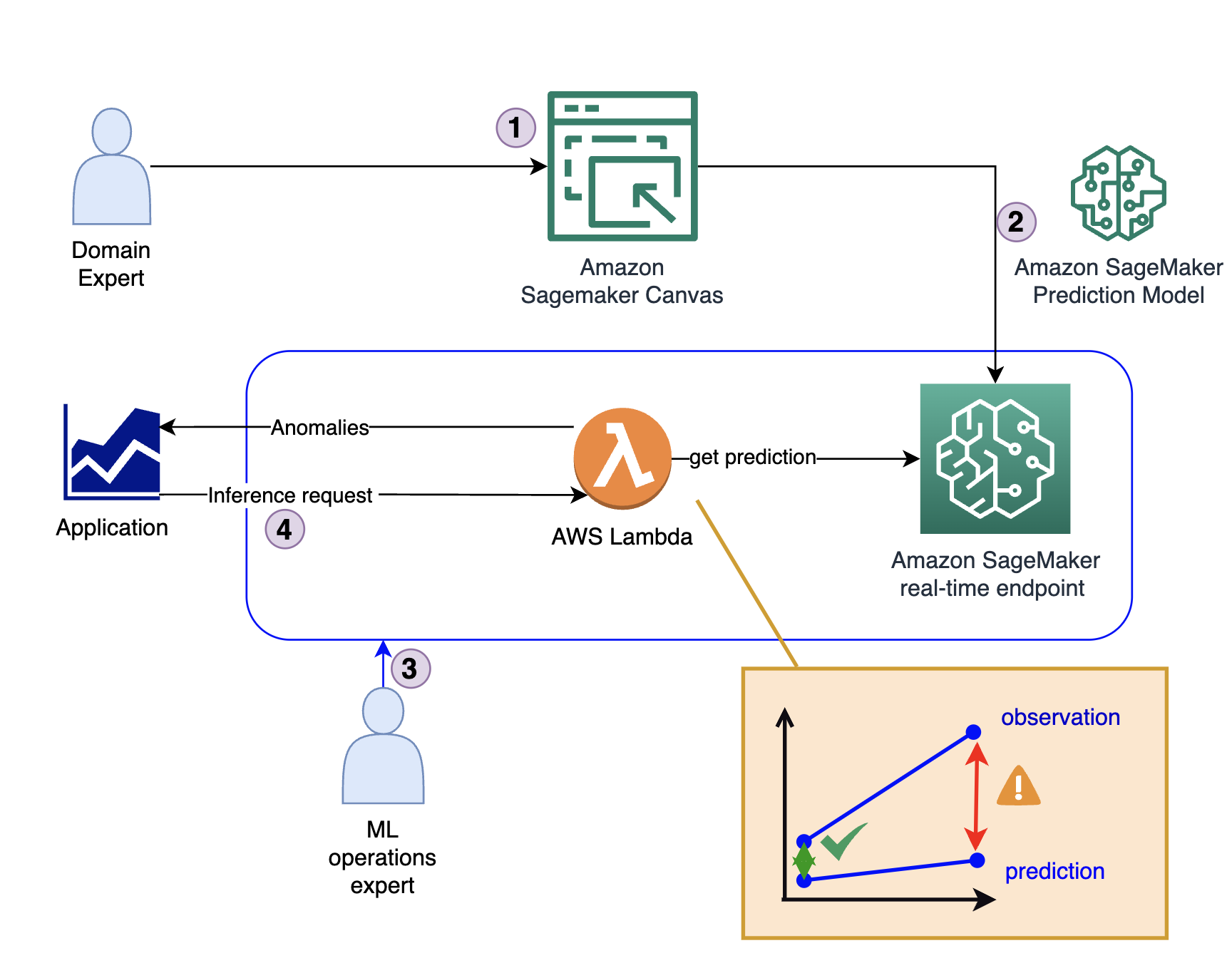
Soluția constă din patru pași cheie:
- Expertul în domeniu creează modelul inițial, inclusiv analiza datelor și curatarea caracteristicilor folosind SageMaker Canvas.
- Expertul în domeniu împărtășește modelul prin intermediul Registrul de modele Amazon SageMaker sau îl implementează direct ca punct final în timp real.
- Un expert MLOps creează infrastructura de inferență și codul transpunând rezultatul modelului dintr-o predicție într-un indicator de anomalie. Acest cod rulează de obicei într-un AWS Lambdas Funcția.
- Când o aplicație necesită detectarea unei anomalii, apelează funcția Lambda, care utilizează modelul pentru inferență și oferă răspunsul (indiferent dacă este sau nu o anomalie).
Cerințe preliminare
Pentru a urma această postare, trebuie să îndepliniți următoarele cerințe preliminare:
Creați modelul folosind SageMaker
Procesul de creare a modelului urmează pașii standard pentru a crea un model de regresie în SageMaker Canvas. Pentru mai multe informații, consultați Începeți cu utilizarea Amazon SageMaker Canvas.
În primul rând, expertul în domeniu încarcă date relevante în SageMaker Canvas, cum ar fi o serie temporală de măsurători. Pentru această postare, folosim un fișier CSV care conține măsurătorile (generate sintetic) ale unui motor electric. Pentru detalii, consultați Importați date în Canvas. Exemplele de date utilizate sunt disponibile pentru descărcare ca a CSV.
Curățați datele cu SageMaker Canvas
După ce datele sunt încărcate, expertul în domeniu poate folosi SageMaker Canvas pentru a selecta datele utilizate în modelul final. Pentru aceasta, expertul selectează acele coloane care conțin măsurători caracteristice pentru problema în cauză. Mai precis, expertul selectează coloanele care sunt legate între ele, de exemplu, printr-o relație fizică, cum ar fi o curbă presiune-temperatura, și unde o modificare a acestei relații este o anomalie relevantă pentru cazul lor de utilizare. Modelul de detectare a anomaliilor va învăța relația normală dintre coloanele selectate și va indica când datele nu sunt conforme cu aceasta, cum ar fi o temperatură anormal de mare a motorului, având în vedere sarcina curentă a motorului.
În practică, expertul în domeniu trebuie să selecteze un set de coloane de intrare adecvate și o coloană țintă. Intrările sunt de obicei o colecție de cantități (numerice sau categorice) care determină comportamentul unei mașini, de la setările de cerere, până la sarcină, viteză sau temperatura ambiantă. Ieșirea este de obicei o cantitate numerică care indică performanța funcționării mașinii, cum ar fi o temperatură care măsoară disiparea energiei sau o altă măsurătoare de performanță care se schimbă atunci când mașina funcționează în condiții suboptime.
Pentru a ilustra conceptul de cantități de selectat pentru intrare și ieșire, să luăm în considerare câteva exemple:
- Pentru echipamentele rotative, cum ar fi modelul pe care l-am construit în acest post, intrările tipice sunt viteza de rotație, cuplul (actual și istoric) și temperatura ambiantă, iar obiectivele sunt temperaturile rezultate ale rulmentului sau ale motorului, care indică condiții bune de funcționare ale rotațiilor.
- Pentru o turbină eoliană, intrările tipice sunt istoricul curent și recent al vitezei vântului și al setărilor palelor rotorului, iar cantitatea țintă este puterea produsă sau viteza de rotație
- Pentru un proces chimic, intrările tipice sunt procentul de diferite ingrediente și temperatura ambiantă, iar obiectivele sunt căldura produsă sau vâscozitatea produsului final
- Pentru echipamentele în mișcare, cum ar fi ușile glisante, intrările tipice sunt puterea de intrare către motoare, iar valoarea țintă este viteza sau timpul de finalizare a mișcării.
- Pentru un sistem HVAC, intrările tipice sunt diferența de temperatură și setările de sarcină realizate, iar cantitatea țintă este consumul de energie măsurat
În cele din urmă, intrările și țintele potrivite pentru un anumit echipament vor depinde de cazul de utilizare și de comportamentul anormal de detectat și sunt cel mai bine cunoscute de un expert în domeniu care este familiarizat cu complexitățile setului de date specific.
În cele mai multe cazuri, selectarea cantităților de intrare și țintă adecvate înseamnă selectarea numai a coloanelor din dreapta și marcarea coloanei țintă (pentru acest exemplu, bearing_temperature). Cu toate acestea, un expert în domeniu poate folosi și caracteristicile fără cod ale SageMaker Canvas pentru a transforma coloanele și a rafina sau agrega datele. De exemplu, puteți extrage sau filtra anumite date sau marcaje de timp din date care nu sunt relevante. SageMaker Canvas acceptă acest proces, afișând statistici privind cantitățile selectate, permițându-vă să înțelegeți dacă o cantitate are valori aberante și răspândirea care poate afecta rezultatele modelului.
Antrenați, reglați și evaluați modelul
După ce expertul în domeniu a selectat coloanele adecvate din setul de date, ei pot antrena modelul pentru a afla relația dintre intrări și ieșiri. Mai precis, modelul va învăța să prezică valoarea țintă selectată din intrări.
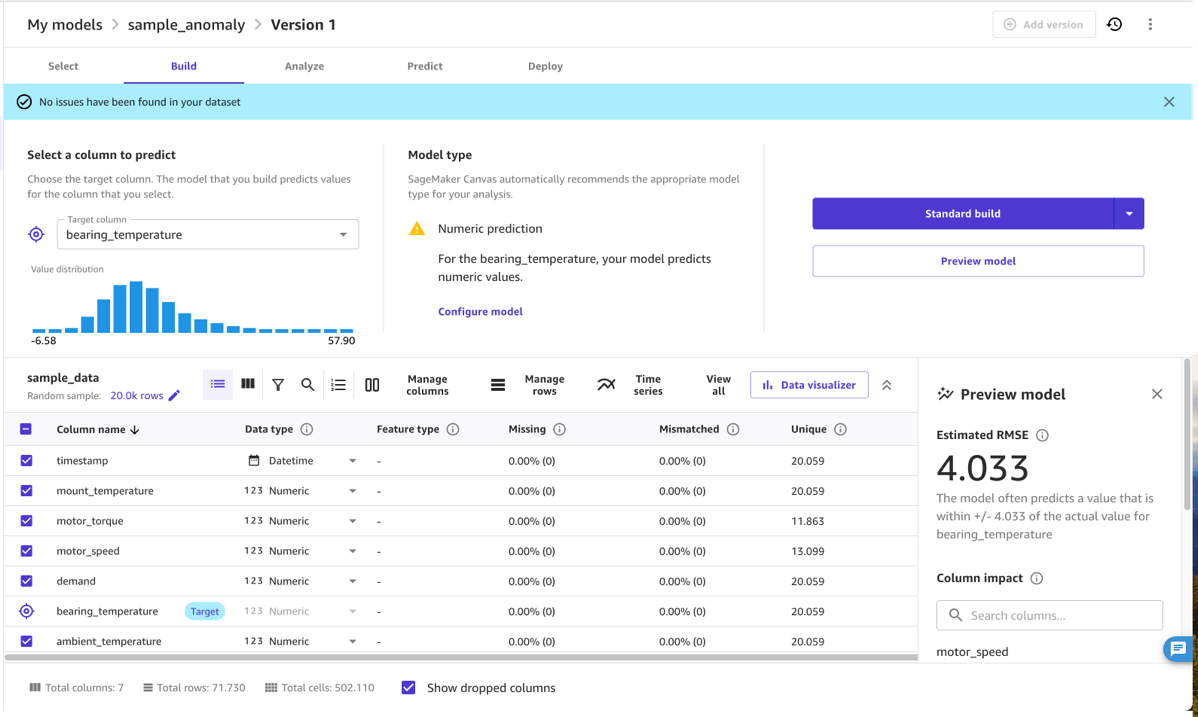
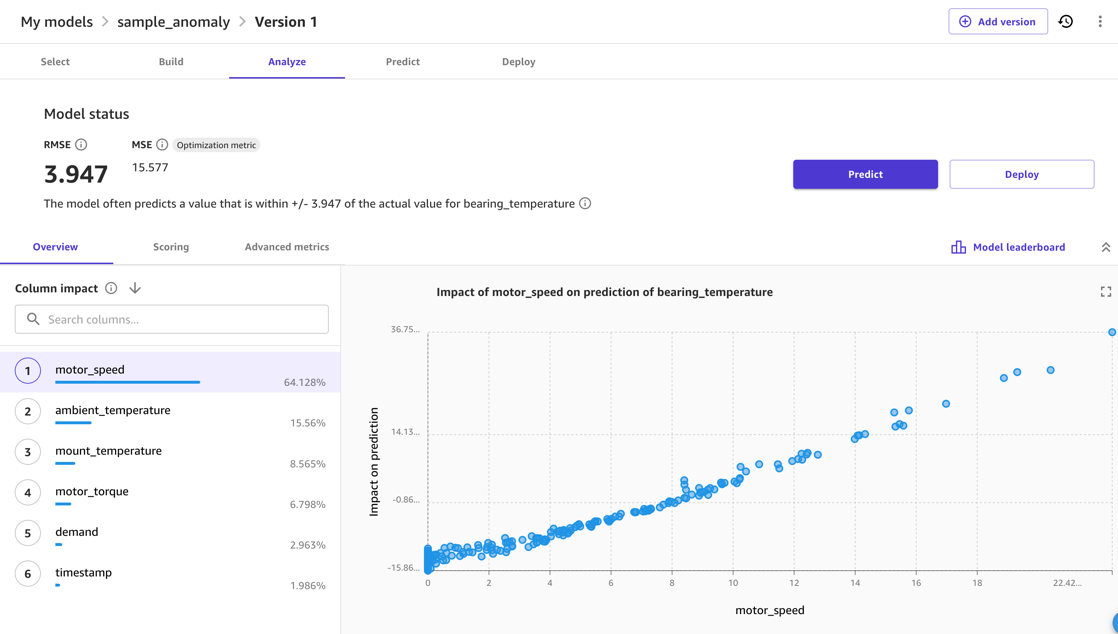
În mod normal, puteți utiliza SageMaker Canvas Previzualizare model opțiune. Acest lucru oferă o indicație rapidă a calității modelului la care să vă așteptați și vă permite să investigați efectul pe care diferitele intrări îl au asupra valorii de ieșire. De exemplu, în următoarea captură de ecran, modelul este cel mai afectat de motor_speed și ambient_temperature metrici la predicție bearing_temperature. Acest lucru este sensibil, deoarece aceste temperaturi sunt strâns legate. În același timp, frecarea suplimentară sau alte mijloace de pierdere a energiei pot afecta acest lucru.
Pentru calitatea modelului, RMSE al modelului este un indicator cât de bine modelul a fost capabil să învețe comportamentul normal în datele de antrenament și să reproducă relațiile dintre măsurile de intrare și de ieșire. De exemplu, în următorul model, modelul ar trebui să fie capabil să prezică corect motor_bearing temperatură în intervalul de 3.67 grade Celsius, deci putem considera o abatere a temperaturii reale de la o predicție model care este mai mare, de exemplu, 7.4 grade ca o anomalie. Cu toate acestea, pragul real pe care l-ați folosi va depinde de sensibilitatea necesară în scenariul de implementare.
În cele din urmă, după ce evaluarea și reglarea modelului s-au terminat, puteți începe antrenamentul complet al modelului care va crea modelul de utilizat pentru inferență.
Implementați modelul
Deși SageMaker Canvas poate folosi un model pentru inferență, implementarea productivă pentru detectarea anomaliilor necesită implementarea modelului în afara SageMaker Canvas. Mai precis, trebuie să implementăm modelul ca punct final.
În această postare și pentru simplitate, implementăm modelul ca punct final din SageMaker Canvas direct. Pentru instrucțiuni, consultați Implementați modelele dvs. la un punct final. Asigurați-vă că luați notă de numele implementării și luați în considerare prețul tipului de instanță pe care îl implementați (pentru această postare, folosim ml.m5.large). SageMaker Canvas va crea apoi un punct final model care poate fi apelat pentru a obține predicții.
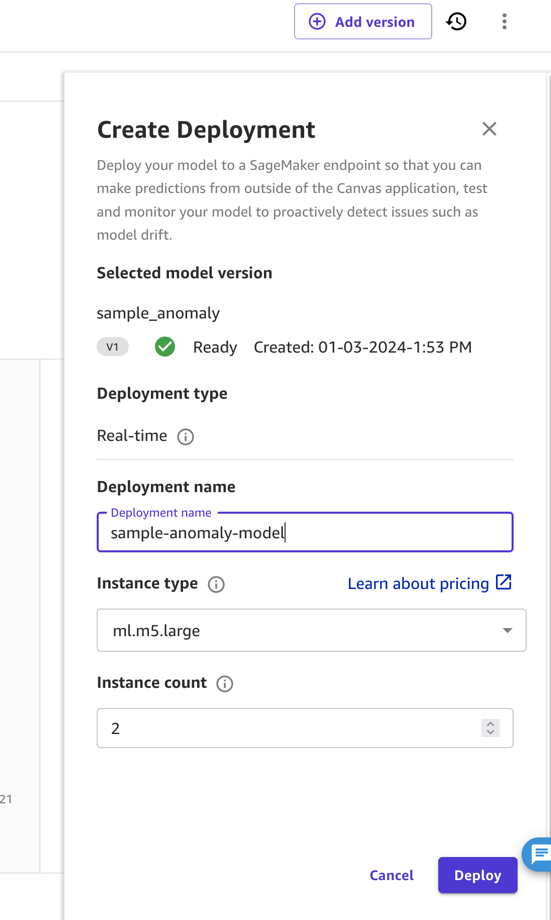
În medii industriale, un model trebuie să fie supus unor teste amănunțite înainte de a putea fi implementat. Pentru aceasta, expertul în domeniu nu îl va implementa, ci va împărtăși modelul la SageMaker Model Registry. Aici, un expert în operațiuni MLOps poate prelua. De obicei, expertul respectiv va testa punctul final al modelului, va evalua dimensiunea echipamentului de calcul necesar pentru aplicația țintă și va determina implementarea cea mai eficientă din punct de vedere al costurilor, cum ar fi implementarea pentru inferența fără server sau inferența în lot. Acești pași sunt în mod normal automatizați (de exemplu, folosind Conducte Amazon Sagemaker sau Amazon SDK).
Utilizați modelul pentru detectarea anomaliilor
În pasul anterior, am creat un model de implementare în SageMaker Canvas, numit canvas-sample-anomaly-model. O putem folosi pentru a obține predicții pentru a bearing_temperature valoare bazată pe celelalte coloane din setul de date. Acum, vrem să folosim acest punct final pentru a detecta anomalii.
Pentru a identifica datele anormale, modelul nostru va folosi punctul final al modelului de predicție pentru a obține valoarea așteptată a valorii țintă și apoi va compara valoarea prezisă cu valoarea reală a datelor. Valoarea estimată indică valoarea așteptată pentru valoarea noastră țintă pe baza datelor de antrenament. Prin urmare, diferența acestei valori este o măsură pentru anormalitatea datelor reale observate. Putem folosi următorul cod:
Codul precedent efectuează următoarele acțiuni:
- Datele de intrare sunt filtrate până la caracteristicile potrivite (funcția „
input_transformer"). - Punctul final al modelului SageMaker este invocat cu datele filtrate (funcția „
do_inference„), unde ne ocupăm de formatarea de intrare și de ieșire în conformitate cu exemplul de cod furnizat la deschiderea paginii de detalii a implementării noastre în SageMaker Canvas. - Rezultatul invocării este alăturat datelor de intrare inițiale, iar diferența este stocată în coloana de eroare (funcția „
output_transform").
Găsiți anomalii și evaluați evenimentele anormale
Într-o configurare tipică, codul pentru obținerea anomaliilor este rulat într-o funcție Lambda. Funcția Lambda poate fi apelată dintr-o aplicație sau Gateway API Amazon. Funcția principală returnează un scor de anomalie pentru fiecare rând de date de intrare - în acest caz, o serie temporală a unui scor de anomalie.
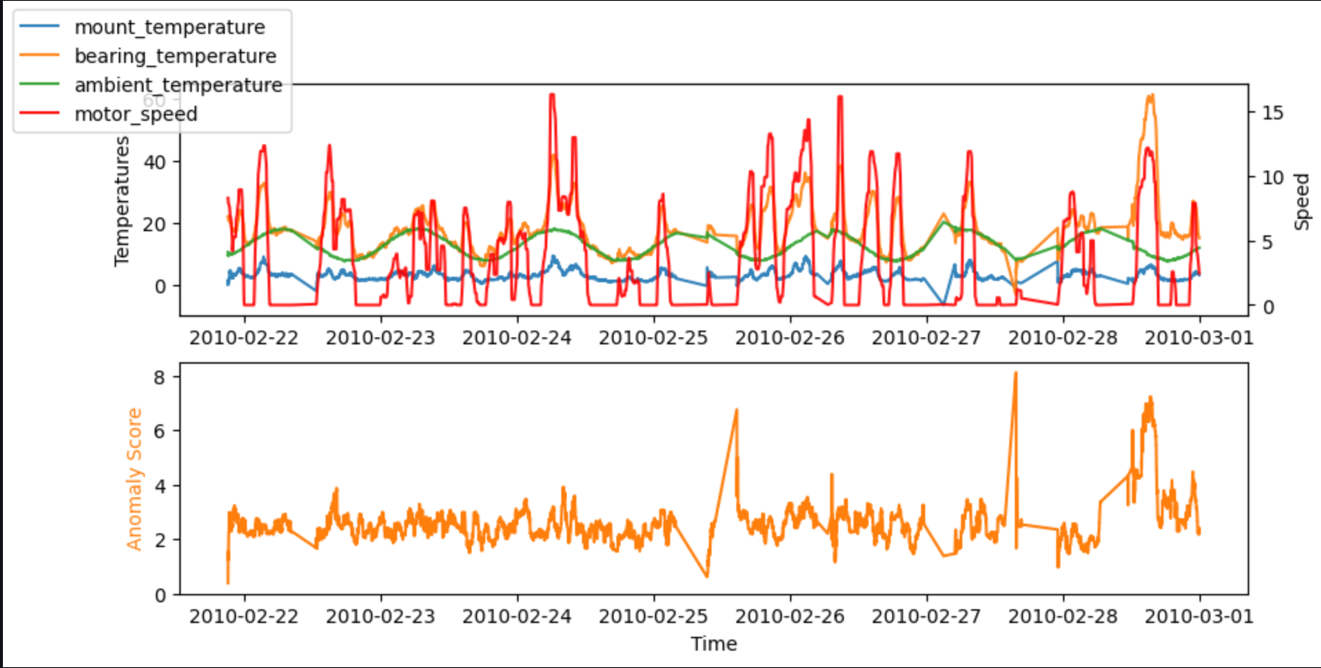
Pentru testare, putem rula codul și într-un notebook SageMaker. Următoarele grafice arată intrările și ieșirile modelului nostru atunci când se utilizează datele eșantionului. Vârfurile abaterii dintre valorile prezise și cele reale (scorul anomaliilor, afișat în graficul de jos) indică anomalii. De exemplu, în grafic, putem vedea trei vârfuri distincte în care scorul de anomalie (diferența dintre temperatura așteptată și cea reală) depășește 7 grade Celsius: primul după un timp lung de inactivitate, al doilea la o scădere abruptă de bearing_temperature, iar ultimul unde bearing_temperature este ridicat în comparație cu motor_speed.
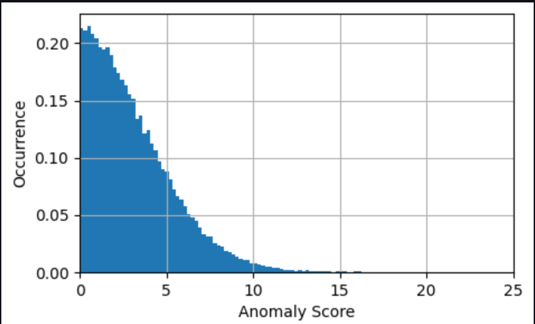
În multe cazuri, cunoașterea seriei temporale a scorului anomaliei este deja suficientă; puteți seta un prag pentru când să avertizați despre o anomalie semnificativă pe baza necesității de sensibilitate a modelului. Scorul curent indică apoi că o mașină are o stare anormală care necesită investigație. De exemplu, pentru modelul nostru, valoarea absolută a scorului anomaliei este distribuită așa cum se arată în graficul următor. Acest lucru confirmă faptul că majoritatea scorurilor de anomalie sunt sub (2xRMS=)8 grade găsite în timpul antrenamentului pentru model ca eroare tipică. Graficul vă poate ajuta să alegeți manual un prag, astfel încât procentul corect al probelor evaluate să fie marcat ca anomalii.
Dacă rezultatul dorit sunt evenimente de anomalii, atunci scorurile de anomalie furnizate de model necesită rafinare pentru a fi relevante pentru utilizarea în afaceri. Pentru aceasta, expertul ML va adăuga de obicei postprocesare pentru a elimina zgomotul sau vârfurile mari ale scorului de anomalie, cum ar fi adăugarea unei medii rulante. În plus, expertul va evalua de obicei scorul anomaliei printr-o logică similară cu ridicarea unui Amazon CloudWatch alarma, cum ar fi monitorizarea pentru depășirea unui prag pe o anumită durată. Pentru mai multe informații despre configurarea alarmelor, consultați Utilizarea alarmelor Amazon CloudWatch. Rularea acestor evaluări în funcția Lambda vă permite să trimiteți avertismente, de exemplu, prin publicarea unui avertisment către un Serviciul de notificare simplă Amazon (Amazon SNS) subiect.
A curăța
După ce ați terminat de utilizat această soluție, ar trebui să curățați pentru a evita costurile inutile:
- În SageMaker Canvas, găsiți implementarea modelului dvs. final și ștergeți-l.
- Deconectați-vă de la SageMaker Canvas pentru a evita taxele pentru funcționarea inactivă.
Rezumat
În această postare, am arătat cum un expert în domeniu poate evalua datele de intrare și poate crea un model ML folosind SageMaker Canvas fără a fi nevoie să scrie cod. Apoi am arătat cum să folosim acest model pentru a realiza detectarea anomaliilor în timp real folosind SageMaker și Lambda printr-un flux de lucru simplu. Această combinație le permite experților din domeniu să își folosească cunoștințele pentru a crea modele ML puternice fără pregătire suplimentară în știința datelor și le permite experților MLOps să utilizeze aceste modele și să le facă disponibile pentru inferență în mod flexibil și eficient.
Un nivel gratuit de 2 luni este disponibil pentru SageMaker Canvas, iar ulterior plătiți doar pentru ceea ce utilizați. Începeți să experimentați astăzi și adăugați ML pentru a profita la maximum de datele dvs.
Despre autor
 Helge Aufderheide este un pasionat de a face datele utilizabile în lumea reală, cu un accent puternic pe automatizare, analiză și învățare automată în aplicații industriale, cum ar fi producția și mobilitatea.
Helge Aufderheide este un pasionat de a face datele utilizabile în lumea reală, cu un accent puternic pe automatizare, analiză și învățare automată în aplicații industriale, cum ar fi producția și mobilitatea.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/detect-anomalies-in-manufacturing-data-using-amazon-sagemaker-canvas/
- :are
- :este
- :nu
- :Unde
- $UP
- 100
- 25
- 4
- 67
- 7
- a
- Capabil
- anormal
- anomalie
- Despre Noi
- Absolut
- Accept
- accesate
- Conform
- realizat
- peste
- acțiuni
- curent
- adăuga
- adăugare
- plus
- Suplimentar
- adrese
- afecta
- afectat
- După
- după aceea
- împotriva
- agregat
- alarmă
- permite
- Permiterea
- permite
- de-a lungul
- deja
- de asemenea
- Amazon
- Amazon SageMaker
- Amazon SageMaker Canvas
- Amazon Web Services
- Înconjurător
- an
- analiză
- analiști
- Google Analytics
- și
- detectarea anomaliilor
- O alta
- oricine
- api
- aplicație
- aplicatii
- aplicat
- arhitectură
- SUNT
- AS
- At
- Automata
- Automatizare
- disponibil
- evita
- AWS
- AWS Lambdas
- Axă
- bazat
- bază
- BE
- deoarece
- deveni
- înainte
- comportament
- de mai jos
- Benchmark
- CEL MAI BUN
- între
- Mare
- Datele mari
- BLADE
- corp
- încălcarea
- construi
- afaceri
- dar
- buton
- by
- denumit
- apeluri
- CAN
- pânză
- capacități
- mașină
- caz
- cazuri
- cauze
- Celsius
- Schimbare
- schimbarea
- caracteristică
- taxe
- chimic
- Alege
- clasificare
- curat
- îndeaproape
- Cloud
- cloud computing
- cod
- colectare
- Coloană
- Coloane
- combinaţie
- Companii
- comparaţie
- comparație
- Completă
- completare
- complex
- tehnica de calcul
- concept
- Condiții
- Configuraţie
- Lua în considerare
- constă
- consum
- conţine
- conţinut
- sistem de răcire
- corecta
- A costat
- crea
- a creat
- creează
- creaţie
- preot
- custozi
- Curent
- curba
- clienţii care
- de date
- analiza datelor
- Analiza datelor
- puncte de date
- știința datelor
- Pe bază de date
- Date
- Luarea deciziilor
- scade
- adânc
- Def
- șterge
- Cerere
- demonstra
- depinde
- implementa
- dislocate
- desfășurarea
- implementează
- descrie
- dorit
- detalii
- detecta
- Detectare
- Determina
- deviere
- diagramă
- diferenţă
- diferit
- direct
- discrepanţă
- distinct
- distribuite
- Nu
- domeniu
- Uși
- jos
- Descarca
- Picătură
- durată
- în timpul
- fiecare
- efect
- eficiență
- eficient
- eficient
- efort
- imputerniceste
- permite
- capăt
- Punct final
- energie
- Consumul de energie
- inginerii
- entuziast
- Întreg
- echipament
- eroare
- Eter (ETH)
- evalua
- evaluat
- evaluare
- evaluări
- evenimente
- examina
- exemplu
- exemple
- aștepta
- de aşteptat
- experienţă
- experimentarea
- expert
- experți
- Expunere
- extrage
- cu care se confruntă
- factori
- în lipsa
- eşecuri
- familiar
- defect
- defecte
- Caracteristică
- DESCRIERE
- puțini
- Fișier
- filtru
- final
- Găsi
- descoperire
- First
- în mod flexibil
- Concentra
- se concentrează
- urma
- următor
- urmează
- Pentru
- prognoze
- găsit
- patru
- Gratuit
- frecare
- din
- funcţie
- funcționalitate
- viitor
- genera
- generată
- obține
- dat
- bine
- grafic
- grafice
- mână
- manipula
- Manipularea
- Avea
- ajutor
- aici
- Înalt
- la nivel înalt
- istorie
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- hvac
- Sistem HVAC
- identifica
- Idle
- if
- ilustra
- ilustrează
- imagine
- import
- important
- îmbunătățiri
- in
- Inclusiv
- Crește
- tot mai mult
- index
- indica
- indicată
- indică
- indicând
- indicaţie
- Indicator
- Indicatorii
- industrial
- industrii
- industrie
- influențarea
- informații
- Infrastructură
- ingrediente
- inițială
- intrare
- intrări
- în interiorul
- perspective
- instanță
- in schimb
- instrucțiuni
- interfaţă
- interpretare
- în
- complexități
- investiga
- investigare
- investigaţie
- invocat
- IT
- ESTE
- alăturat
- jpg
- JSON
- Cheie
- Cunoaștere
- cunoştinţe
- cunoscut
- lipsă
- Limbă
- mare
- mai mare
- Nume
- AFLAȚI
- învăţare
- ca
- Probabil
- Limitat
- liniar
- linii
- încărca
- loturile
- logică
- Lung
- Uite
- de pe
- LOWER
- maşină
- masina de învățare
- Masini
- Principal
- întreținere
- face
- Efectuarea
- defecțiuni
- Manageri
- manual
- de fabricaţie
- multe
- marcat
- marcare
- Mai..
- însemna
- mijloace
- măsurători
- măsuri
- măsurare
- Întâlni
- mesaje
- metric
- Metrici
- ML
- MLOps
- mobilitate
- model
- Modele
- Monitorizarea
- mai mult
- cele mai multe
- Motor
- Motoare
- în mişcare
- mult
- trebuie sa
- my
- nume
- Nevoie
- nevoilor
- Nou
- Zgomot
- normală.
- în mod normal
- nota
- caiet
- notificare
- acum
- observații
- observate
- obține
- obține
- apariţie
- of
- de multe ori
- on
- ONE
- afară
- de deschidere
- operaţie
- operațional
- Operațiuni
- Opțiune
- or
- original
- Altele
- al nostru
- afară
- producție
- iesiri
- exterior
- peste
- Prezentare generală
- pagină
- panda
- Plătește
- procent
- efectua
- performanță
- efectuarea
- efectuează
- fizic
- imagine
- planificare
- Plato
- Informații despre date Platon
- PlatoData
- Punct
- puncte
- portofoliu
- Post
- potenţial
- putere
- puternic
- practică
- tocmai
- prezice
- a prezis
- estimarea
- prezicere
- Predictii
- predictivă
- Pregăti
- premise
- precedent
- de stabilire a prețurilor
- Problemă
- proces
- Produs
- productiv
- Programare
- limbaje de programare
- furniza
- prevăzut
- furnizează
- furnizarea
- Editare
- Piton
- calitate
- cantitate
- întrebare
- Rapid
- ridicare
- Citeste
- real
- lumea reală
- în timp real
- recent
- trimite
- rafina
- registru
- regres
- regulat
- legate de
- relaţie
- Relaţii
- de încredere
- scoate
- necesita
- necesar
- Necesită
- resursă
- răspuns
- rezultat
- rezultând
- REZULTATE
- reveni
- Returnează
- dreapta
- Rulare
- rădăcină
- RÂND
- Alerga
- funcţionare
- ruleaza
- sagemaker
- acelaşi
- probă
- scenariu
- Ştiinţă
- scor
- scorurile
- Al doilea
- vedea
- selecta
- selectate
- selectarea
- trimite
- Sensibilitate
- serie
- serverless
- Servicii
- set
- instalare
- setări
- configurarea
- Distribuie
- Acțiuni
- să
- Arăta
- a arătat
- arătând
- indicat
- Emisiuni
- semnificativ
- asemănător
- simplu
- simplitate
- Mărimea
- set de calificare
- alunecare
- So
- soluţie
- unele
- tensiune
- specialiști
- specific
- viteză
- viteze
- răspândire
- standard
- Începe
- început
- Stat
- statistică
- Stare
- Pas
- paşi
- stocate
- puternic
- suboptimal
- astfel de
- suficient
- potrivit
- Sprijină
- sigur
- depășește
- sintetic
- sistem
- Lua
- Ţintă
- obiective
- test
- Testarea
- decât
- acea
- Graficul
- lor
- Lor
- apoi
- prin urmare
- Acestea
- ei
- acest
- minuțios
- aceste
- trei
- prag
- Prin
- Nivelul
- timp
- Seria de timp
- ori
- la
- astăzi
- Unelte
- top
- subiect
- față de
- tradiţional
- Tren
- Pregătire
- trenuri
- Transforma
- ton
- de reglaj
- turbină
- Două
- tip
- tipic
- tipic
- în
- suferi
- înţelege
- inutil
- Ciudat
- utilizabil
- utilizare
- carcasa de utilizare
- utilizat
- utilizări
- folosind
- valoare
- Valori
- Viteză
- foarte
- de
- vrea
- de avertizare
- a fost
- we
- web
- servicii web
- BINE
- Ce
- Ce este
- cand
- dacă
- care
- OMS
- voi
- vânt
- turbină eoliană
- fereastră
- cu
- în
- fără
- flux de lucru
- de lucru
- lume
- ar
- scrie
- scrie cod
- scris
- ani
- încă
- tu
- Ta
- zephyrnet