Introducere
Dacă ești începător și abia începi să înveți MLOps, ai putea avea o întrebare: Ce sunt MLOps?
Cu cuvinte simple, MLOps (Machine Learning Operations) este un set de practici de colaborare și comunicare între oamenii de știință de date și profesioniștii în operațiuni. Aplicarea acestor practici crește calitatea, simplifică procesul de management și automatizează implementarea modelelor de învățare automată și de învățare profundă în medii de producție pe scară largă. Este mai ușor să aliniați modelele cu nevoile de afaceri și cerințele de reglementare. În acest articol, vom implementa proiectul nostru folosind Prefect și CometML.
În acest proiect MLOps, vom construi cel mai bun model posibil de Machine Learning folosind hiperparametri optimi pentru a prezice prețul de vânzare al unui buldozer. După cum probabil știți, un buldozer este un vehicul puternic pentru săpături și șanțuri la mică adâncime.

obiective de invatare
- Aflați conceptele MLOps și fluxul de lucru ML de la capăt la capăt.
- Implementați pipeline MLOps cu Prefect și CometML.
- Realizați fluxuri de lucru ML automatizate și reproductibile.
- Evaluați și monitorizați modelele ML.
- Experiență MLOps de la capăt la capăt.
Acest articol a fost publicat ca parte a Blogathonul științei datelor.
Cuprins
Ce este Prefect și CometML?
prefect
prefect este un open-source Biblioteca Python care vă ajută să definiți, să programați și să gestionați bine fluxurile de lucru de date. Simplifică orchestrarea și automatizarea fluxurilor de lucru complexe de date, ușurând sarcinile. Exemple sunt extragerea datelor, transformarea și formarea modelului. Le puteți face într-un mod sistematic și repetabil.
pip install prefectUn alt lucru pe care ar trebui să-l menționez este Prefect Cloud. Prefect Cloud este o platformă bazată pe cloud furnizată de Prefect pentru gestionarea, orchestrarea și monitorizarea fluxurilor de lucru de date în MLOps.
CometML
CometML este o platformă pentru gestionarea și urmărirea experimentelor de învățare automată în MLOps. Oferă instrumente pentru versiunea, colaborarea și vizualizarea rezultatelor. Ajută la eficientizarea dezvoltării și monitorizării modelelor de învățare automată.
pip install comet_mlProiectul MLOps: Să începem.
Explorarea datelor
Pe măsură ce construim un capăt la capăt masina de învățare model, ne vom concentra mai mult pe ciclul de viață ML decât pe construirea modelului.
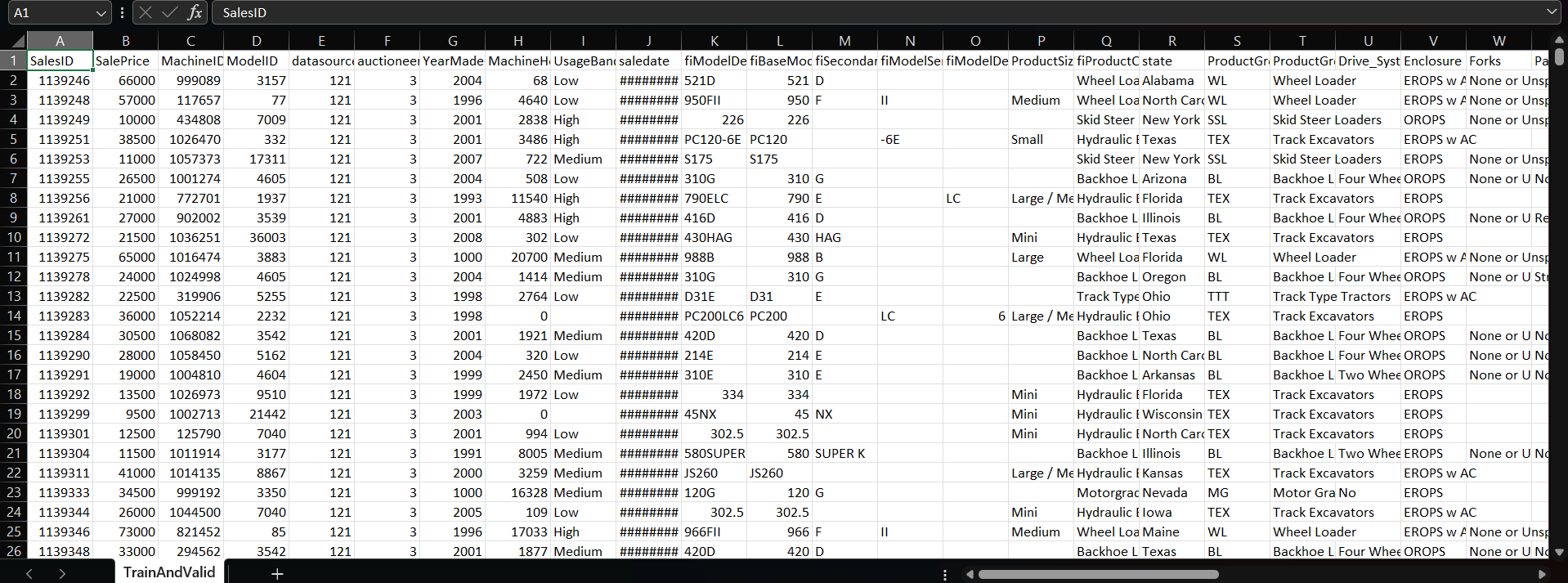
Dacă observați setul de date, veți vedea că există 53 de coloane. Vom folosi toate cele 52 de coloane pentru caracteristicile de intrare sau X, și din moment ce variabila noastră țintă este Preț de vânzare, acesta va fi y. În partea de explorare a datelor, am efectuat tot felul de explorări, de la df.info() până la trasarea valorilor lipsă folosind un grafic de dispersie. Veți găsi toți pașii în caietul meu în depozitul GitHub. De asemenea, puteți descărca setul de date de acolo. Acum, să începem să lucrăm la proiect.
Configurați un mediu virtual
Ce este Mediul Virtual și de ce avem nevoie de el?
Un mediu virtual este un spațiu de lucru Python autonom pentru izolarea dependențelor proiectului.
Instalați multe biblioteci pe computer pentru mai multe proiecte. Este posibil să fi instalat Python3.11, dar uneori, aveți nevoie de Python3.9 pentru un alt proiect. Pentru a evita conflictul, trebuie să configurați un mediu virtual.
Crearea unui mediu virtual
- Pentru Windows:
python -m venv myenv
#then for activation
myenvScriptsactivate- Pentru Linux/macOS:
python3 -m venv myenv
#then for activation
source myenv/bin/activateStructura fișierului
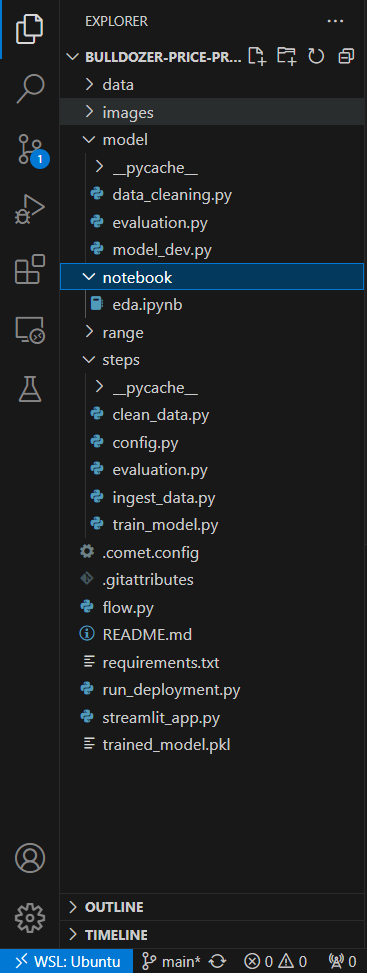
Configurați CometML și Prefect
Pentru a configura CometML, trebuie să creați un fișier numit .comet.config în directorul proiectului și să definiți parametrii de configurare ai acestuia. Iată un exemplu despre cum puteți structura un fișier de bază .comet.config:
[comet]
api_key = your_api_key
workspace = your_workspace
project_name = your_project_nameAr trebui să vă înscrieți Cometă pentru o cheie api, un spațiu de lucru și un nume_proiect. Să aruncăm o privire la cum să configurați un cont Comet.
Configurați un cont Comet
- Vă rugăm să creați un cont nou. Este ușor și gratuit.
Cheia API
- Când contul dvs. este creat în colțul din dreapta sus, faceți clic pe avatar, apoi selectați Setări cont.
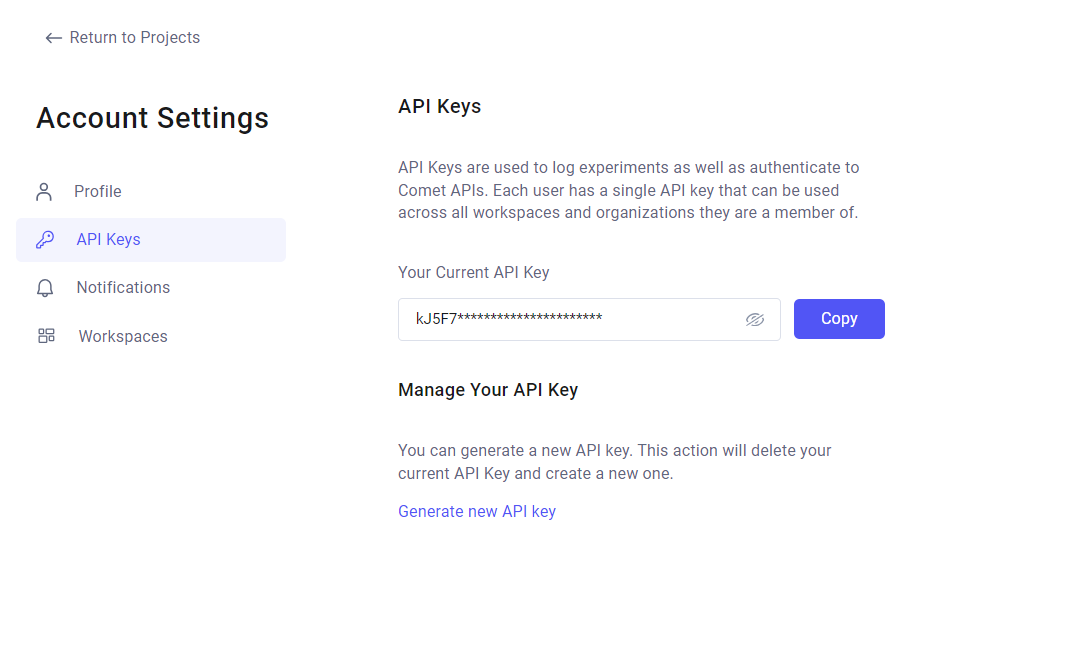
- Pentru a obține cheia API, faceți clic pe fila Chei API. Cheia dvs. API actuală este afișată acolo. Faceți clic pe Copiere pentru a copia cheia API.
- Puteți vedea numele spațiului de lucru și numele proiectului în fila Spații de lucru.
Deci acum să configuram Prefect.
Stabiliți prefectul
Prefect oferă o platformă cloud și API pentru gestionarea și monitorizarea fluxurilor de lucru. Prin înscriere, putem folosi Prefect Cloud. Are un tablou de bord pentru urmărirea fluxurilor de lucru. Poate seta notificări, poate analiza jurnalele și multe altele. Partea interesantă este că putem implementa modelul nostru de învățare automată.
- Pasul 1: Instalați Prefect
pip install -U prefectA se vedea ghid de instalare pentru mai multe detalii.
- Pasul 2: Conectați-vă la API-ul Prefect
Funcționalitatea Prefect se bazează pe un API cloud backend. API-ul gestionează execuția fluxurilor de lucru și a conductelor de date. Trebuie să conectăm instalația Prefect la acest API. Acest lucru deblochează funcții utile. De exemplu, un tablou de bord central poate fi folosit pentru a urmări rulările fluxului de lucru. De asemenea, vă permite să setați notificări. Puteți să le obțineți atunci când sarcinile eșuează, să analizați jurnalele și să urmăriți istoricul sarcinilor. În cele din urmă, vă permite să scalați sarcinile de lucru într-un cluster. Putem construi fluxuri de lucru la nivel local fără API. Dar nu le putem face operaționale sau pregătite pentru producție. Prefect Cloud se ocupă de programare și reîncercări. Respectă limitele stabilite prin API. Deci, utilizarea Prefect cu serviciul său API oferă o platformă fără server. Este pentru gestionarea fluxurilor de lucru complexe fără a fi nevoie să vă găzduiți propriii coordonatori.
- Creați un cont nou sau conectați-vă la
- Utilizați comanda prefect cloud login CLI pentru a
Autentificare în cloud prefect
Alegeți Conectați-vă cu un browser web și faceți clic pe butonul Autorizare din fereastra deschisă a browserului.
Instanță de server Prefect auto-găzduită
Puteți rula acest lucru și pe mașina dvs. locală. Vezi tutorial pentru ajutor. Rețineți că trebuie să vă găzduiți propriul server și să vă rulați fluxurile pe propria infrastructură.
- Pasul 3: Transformă-ți funcția într-un flux Prefect
A se vedea curgere.py fișier în care am adăugat decoratorul @flow. Acesta este cel mai rapid mod de a începe cu Prefect. Un „flux” este un grafic aciclic direcționat (DAG) care reprezintă un flux de lucru. În Prefect, o sarcină este o unitate fundamentală de lucru în fluxul de lucru. Vom discuta mai multe sarcini mai târziu în acest tutorial.
5 pași pentru implementarea acestui proiect MLOps folosind Prefect și CometML
Iată cei 5 pași pentru implementarea proiectului MLops folosind Prefect și CometML
Pasul 1 – Ingerați date
În acest pas, ne ingerăm datele din folderul nostru de date. Să aruncăm o privire la fișierul nostru ingest_data.py din dosarul Steps
class IngestData:
"""Ingests data from a CSV file."""
def __init__(self, data_path: str):
self.data_path = data_path
def get_data(self):
logging.info(f"Ingest data from {self.data_path}")
return pd.read_csv(self.data_path)
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1))
def ingest_df(data_path: str) -> pd.DataFrame:
"""
Ingest data from the specified path and return a DataFrame.
Args:
data_path (str): The path to the data file.
Returns:
pd.DataFrame: A pandas DataFrame containing the ingested data.
"""
try:
ingest_obj = IngestData(data_path)
df = ingest_obj.get_data()
print(f"Ingesting data from {data_path}")
experiment.log_metric("data_ingestion_status", 1)
return df
except Exception as e:
logging.error(f"Error while ingesting data: {e}")
raise e
finally:
# Ensure that the experiment is ended to log all data
experiment.end()În Prefect, o sarcină este o unitate fundamentală de lucru într-un flux de lucru. Reprezintă o unitate de calcul individuală sau o operație care trebuie efectuată. Deci, în acest caz, prima noastră sarcină este să ingerăm datele.
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1))Acest decorator de sarcini Prefect specifică parametrii de stocare în cache, utilizând task_input_hash ca funcție cheie cache și setând o expirare a memoriei cache de o oră. Puteți afla mai multe despre acest lucru în documentul prefectului.
Pasul 2 – Curățați datele
În acest pas, ne vom curăța datele, iar codul de mai jos va returna X_train, X_test, y_train, y_test, pentru antrenarea și testarea modelului nostru ML. Hai să aruncăm o privire
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1))
def clean_df(data: pd.DataFrame) -> Tuple[
Annotated[pd.DataFrame, 'X_train'],
Annotated[pd.DataFrame, 'X_test'],
Annotated[pd.Series, 'y_train'],
Annotated[pd.Series, 'y_test'],
]:
"""
Data cleaning class which preprocesses the data and divides it into train and test data.
Args:
data: pd.DataFrame
"""
try:
preprocess_strategy = DataPreprocessStrategy()
data_cleaning = DataCleaning(data, preprocess_strategy)
preprocessed_data = data_cleaning.handle_data()
divide_strategy = DataDivideStrategy()
data_cleaning = DataCleaning(preprocessed_data, divide_strategy)
X_train, X_test, y_train, y_test = data_cleaning.handle_data()
logging.info(f"Data Cleaning Complete")
experiment.log_metric("data_cleaning_status", 1)
return X_train, X_test, y_train, y_test
except Exception as e:
logging.error(e)
raise e
finally:
# Ensure that the experiment is ended to log all data
experiment.end()
Până în acest punct, dacă observați cu atenție codul de mai sus, s-ar putea să vă gândiți, unde sunt definite DataPreprocessStrategy() și DataDivideStrategy() în folderul model, definim aceste metode; Hai să aruncăm o privire
class DataPreprocessStrategy(DataStrategy):
"""
Data preprocessing strategy which preprocesses the data.
"""
def handle_data(self, data: pd.DataFrame) -> pd.DataFrame:
try:
"""
Performs transformations on df and returns transformaed df.
"""
# Convert 'saledate' column to datetime
data['saledate'] = pd.to_datetime(data['saledate'])
data["saleYear"] = data.saledate.dt.year
data["saleMonth"] = data.saledate.dt.month
data["saleDay"] =data.saledate.dt.day
data["saleDayOfWeek"] = data.saledate.dt.dayofweek
data["saleDayOfYear"] = data.saledate.dt.dayofyear
data.drop("saledate", axis=1, inplace=True)
# Fill the numeric row with median
for label, content in data.items():
if pd.api.types.is_numeric_dtype(content):
if pd.isnull(content).sum():
# Add a binary column which tells us if the data was missing
# or not
data[label+"is_missing"] = pd.isnull(content)
# Fill missing numeric values with median
data[label] = content.fillna(content.median())
# Filled categorical missing data and turn categories into numbers
if not pd.api.types.is_numeric_dtype(content):
data[label+"is_missing"] = pd.isnull(content)
# We add +1 to the category code because pandas encodes
# missing categories as -1
data[label] = pd.Categorical(content).codes+1
return data
except Exception as e:
logging.error("Error in Data handling: {}".format(e))
raise e
În mea GitHub depozit, puteți găsi toate metodele.
Pasul 3 – Modelul trenului
Vom antrena un model simplu de regresie liniară folosind biblioteca Scikit Learn.
# Create a CometML experiment
experiment = Experiment()
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1))
def train_model(
X_train: pd.DataFrame,
X_test: pd.DataFrame,
y_train: pd.Series,
y_test: pd.Series,
config: ModelNameConfig = ModelNameConfig(),
) -> RegressorMixin:
"""
Train a regression model based on the specified configuration.
Args:
X_train (pd.DataFrame): Training data features.
X_test (pd.DataFrame): Testing data features.
y_train (pd.Series): Training data target.
y_test (pd.Series): Testing data target.
config (ModelNameConfig): Model configuration.
Returns:
RegressorMixin: Trained regression model.
"""
try:
model = None
if config.model_name == "random_forest_regressor":
model = RandomForestRegressor(n_estimators=40,
min_samples_leaf=1,
min_samples_split=14,
max_features=0.5,
n_jobs=-1,
max_samples=None,
random_state=42)
trained_model = model.fit(X_train, y_train)
# Save the trained model to a file
model_filename = "trained_model.pkl"
with open(model_filename, 'wb') as model_file:
pickle.dump(trained_model, model_file)
print("train model finished")
experiment.log_metric("model_training_status", 1)
return trained_model
else:
raise ValueError("Model name not supported")
except Exception as e:
logging.error(f"Error in train model: {e}")
raise e
finally:
# Ensure that the experiment is ended to log all data
experiment.end()Pasul 4 – Evaluați modelul
# Create a CometML experiment
experiment = Experiment()
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1))
def evaluate_model(
model: RegressorMixin, X_test: pd.DataFrame, y_test: pd.Series
) -> Tuple[Annotated[float, "r2"],
Annotated[float, "rmse"],
]:
"""
Args:
model: RegressorMixin
x_test: pd.DataFrame
y_test: pd.Series
Returns:
r2_score: float
rmse: float
"""
try:
prediction = model.predict(X_test)
# Using the MSE class for mean squared error calculation
mse_class = MSE()
mse = mse_class.calculate_score(y_test, prediction)
experiment.log_metric("MSE", mse)
# Using the R2Score class for R2 score calculation
r2_class = R2Score()
r2 = r2_class.calculate_score(y_test, prediction)
experiment.log_metric("R2Score", r2)
# Using the RMSE class for root mean squared error calculation
rmse_class = RMSE()
rmse = rmse_class.calculate_score(y_test, prediction)
experiment.log_metric("RMSE", rmse)
# Log metrics to CometML
experiment.log_metric("model_evaluation_status", 1)
print("Evaluate model finished")
return r2, rmse
except Exception as e:
logging.error(f"Error in evaluation: {e}")
raise e
finally:
# Ensure that the experiment is ended to log all data
experiment.end()Am înregistrat toate acele valori, cum ar fi scorul r2, mse și rmse. Puteți vedea codul de mai sus. Putem vizualiza acele matrici pe tabloul de bord CometML. Cu toate acestea, atunci când rulați fluxul, puteți vedea tabloul de bord. În pasul următor, discutăm despre asta.
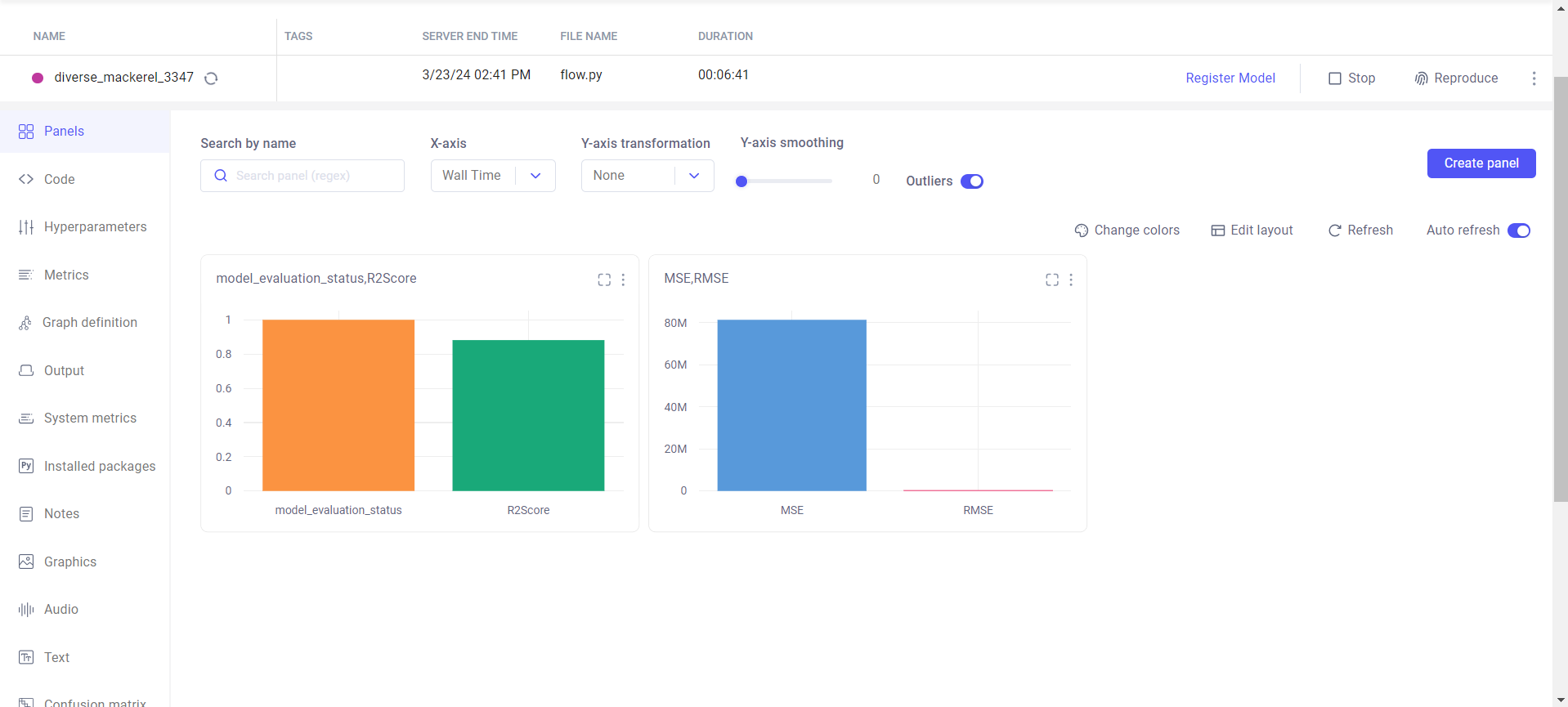
Pasul 5 – Rulați fluxul (pasul final)
Trebuie să rulăm fluxul.
Importăm toate sarcinile și fluxurile în fișierul flow.py și rulăm fluxul de acolo.
python3 flow.pyfrom prefect import flow
from steps. ingest_data import ingest_df
from steps.clean_data import clean_df
from steps.train_model import train_model
from steps.evaluation import evaluate_model
## import comet_ml at the top of your file
from comet_ml import Experiment
## Create an experiment with your api key
@flow(retries=3, retry_delay_seconds=5, log_prints=True)
def my_flow():
data_path="/home/dhrubaubuntu/gigs_projects/Bulldozer-price-prediction/data/TrainAndValid.csv"
df = ingest_df(data_path)
X_train, X_test, y_train, y_test = clean_df(df)
model = train_model(X_train, X_test, y_train, y_test)
r2_score, rmse = evaluate_model(model, X_test, y_test)
# Run the Prefect Flow
if __name__ == "__main__":
my_flow()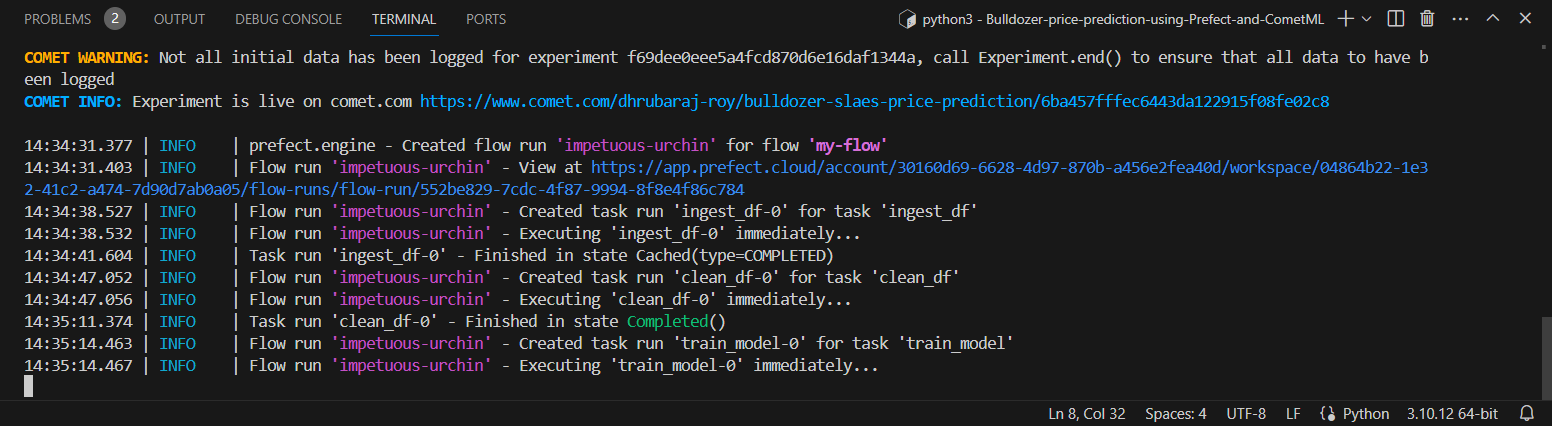
Aici, puteți vedea toate tablourile de bord ale fluxului de rulare din Prefect
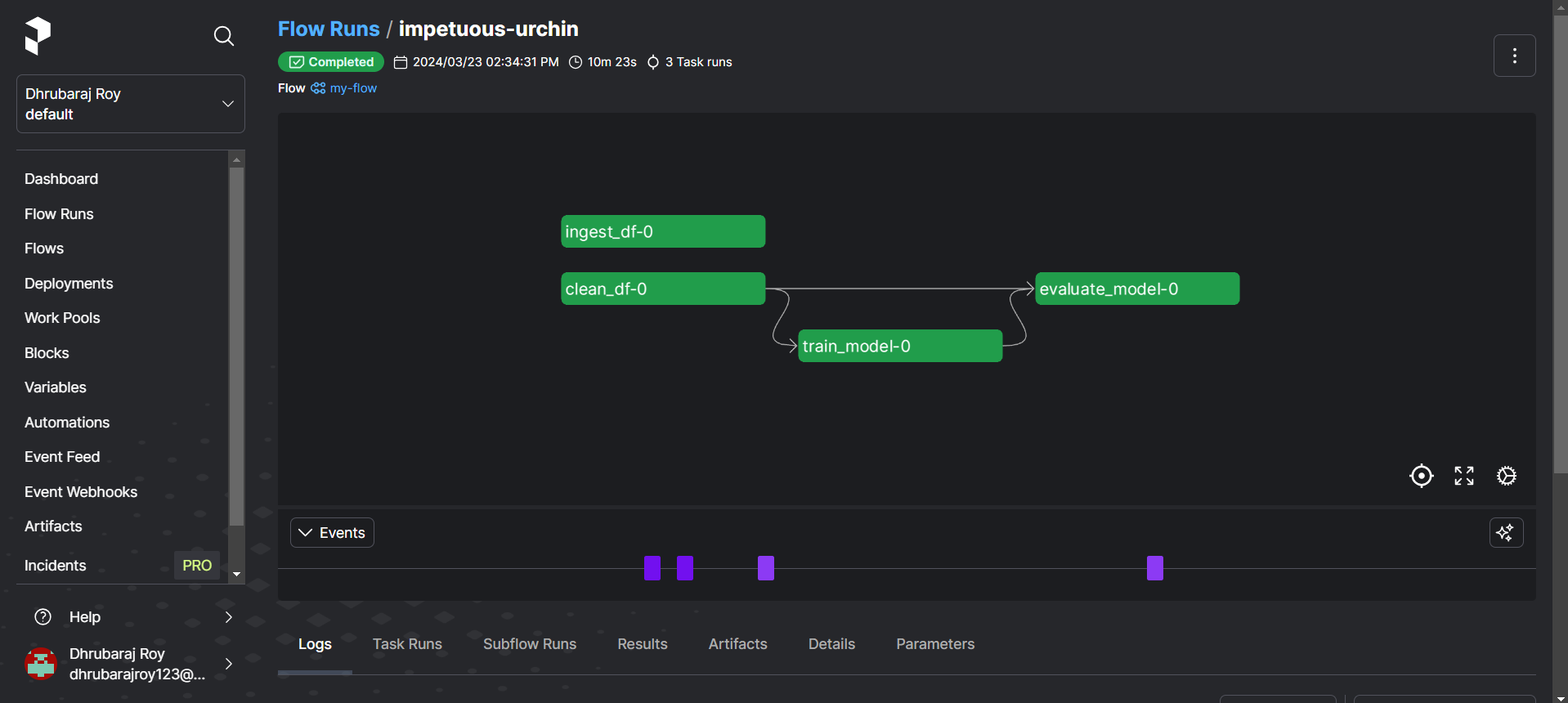
Concluzie
Implementarea MLOps end-to-end permite organizațiilor să extindă în mod fiabil soluțiile de învățare automată în producție. Acest tutorial a demonstrat un flux de lucru automat pentru prezicerea intervalelor de vehicule electrice folosind biblioteci open-source precum Prefect și CometML.
Principalele aspecte ale proiectului includ:
- Orchestrarea unei pipeline ML cu Prefect implică gestionarea pașilor, de la asimilarea datelor, preprocesare, dezvoltarea modelului, evaluare și monitorizare.
- Urmărirea experimentelor în CometML pentru a vizualiza valorile modelului, cum ar fi scorurile RMSE și R2 în timp, pentru comparație.
- Monitorizarea execuțiilor fluxului de lucru în Prefect Cloud arătând duratele sarcinilor.
În general, această prezentare implementează cele mai bune practici în domeniul științei datelor de automatizare, reproductibilitate și monitorizare într-un flux de lucru structurat esențial pentru sistemele ML din lumea reală. Extinderea și operaționalizarea la producție poate spori și mai mult scalabilitatea Prefect în gestionarea fluxurilor la scară mare în infrastructura distribuită.
Intrebari cu cheie
Câteva concluzii cheie din acest tutorial MLOps end-to-end includ:
- Implementarea MLOps îmbunătățește oamenii de știință de date și colaborarea IT cu practicile de automatizare și DevOps.
- Prefect permite crearea de conducte de date robuste și fluxuri de lucru pentru a ingera, procesa, antrena și evalua modele.
- CometML oferă o modalitate ușoară de a urmări experimentele ML cu înregistrare și vizualizare.
- Orchestrarea ciclului de viață ML de la capăt la capăt asigură ca modelele să rămână relevante pe măsură ce apar date noi.
- Monitorizarea execuțiilor fluxului de lucru ajută la identificarea și depanarea rapidă a defecțiunilor.
- MLOps deblochează experimentarea mai rapidă prin simplificarea recalificării și implementarea modelelor actualizate.
Întrebări Frecvente
Ans. MLOps pentru învățarea automată este un set de practici care urmărește eficientizarea și automatizarea ciclului de viață de învățare automată end-to-end, inclusiv dezvoltarea modelului, implementarea și întreținerea, pentru a îmbunătăți colaborarea și eficiența în echipele de știință a datelor și operațiuni.
Ans. Prefect este o bibliotecă Python open-source pentru gestionarea fluxului de lucru. Permite crearea, programarea și orchestrarea fluxurilor de lucru și a sarcinilor de date utilizate în mod obișnuit în știința datelor și conductele de automatizare. Simplifică fluxurile de lucru complexe, concentrându-se pe flexibilitate, fiabilitate și monitorizare.
Ans. CometML este o platformă pentru experimentarea și colaborarea învățării automate. Oferă instrumente pentru urmărirea, compararea și optimizarea experimentelor de învățare automată, permițând echipelor să înregistreze și să partajeze detaliile experimentului, valorile și vizualizările pentru a îmbunătăți dezvoltarea modelului și colaborarea.
Ans. Prefect este folosit pentru gestionarea fluxului de lucru în știința datelor și automatizare. Ajută la eficientizarea și la orchestrarea fluxurilor de lucru complexe de date, facilitând proiectarea, programarea și monitorizarea coerentă a sarcinilor. Prefect este folosit în mod obișnuit pentru procesarea datelor, formarea modelelor de învățare automată și alte operațiuni centrate pe date, oferind un cadru pentru construirea, rularea și gestionarea eficientă a fluxurilor de lucru.
Ans. MLflow este o platformă open-source pentru gestionarea ciclului de viață de învățare automată de la capăt la capăt, inclusiv urmărirea experimentelor, împachetarea codului în execuții reproductibile și partajarea și implementarea modelelor. Comet este o platformă pentru experimentarea și colaborarea învățării automate, concentrându-se pe urmărirea experimentelor, vizualizări și funcții de colaborare. Acesta oferă un hub centralizat pentru ca echipele să analizeze și să partajeze rezultatele. În timp ce ambele acceptă urmărirea experimentelor, MLflow oferă funcții suplimentare de ambalare și implementare a modelului, în timp ce Comet pune accent pe capacitățile de colaborare și vizualizare.
Media prezentată în acest articol nu este deținută de Analytics Vidhya și este utilizată la discreția Autorului.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.analyticsvidhya.com/blog/2024/03/prefect-and-cometml-for-bulldozer-sales-price-prediction/
- :are
- :este
- :nu
- :Unde
- $UP
- 1
- 11
- 13
- 14
- 2%
- 31
- 4
- 5
- 52
- 9
- a
- Despre Noi
- mai sus
- Cont
- peste
- Activarea
- aciclic
- adăuga
- adăugat
- Suplimentar
- isi propune
- alinia
- TOATE
- de asemenea
- an
- Google Analytics
- Analize Vidhya
- analiza
- și
- O alta
- api
- Aplicarea
- SUNT
- articol
- AS
- a întrebat
- At
- automatizarea
- Automata
- automate
- automatizarea
- Automatizare
- Avatar
- evita
- Backend
- bazat
- de bază
- BE
- deoarece
- Începător
- CEL MAI BUN
- Cele mai bune practici
- între
- binar
- blogathon
- atât
- browser-ul
- construi
- Clădire
- afaceri
- dar
- buton
- by
- cache
- cache
- calcul
- CAN
- Poate obține
- capacități
- cu grijă
- caz
- categorii
- Categorii
- central
- centralizat
- clasă
- curat
- Curățenie
- cli
- clic
- Cloud
- Platforma Cloud
- Grup
- cod
- colaborare
- Coloană
- Coloane
- vine
- în mod obișnuit
- Comunicare
- compararea
- comparație
- Completă
- complex
- calcul
- calculator
- Concepte
- efectuat
- Configuraţie
- conflict
- Conectați
- conținând
- conţinut
- converti
- coordonatori
- copiaţi
- Colț
- crea
- a creat
- creaţie
- critic
- Curent
- ciclu
- DAG
- tablou de bord
- tablouri de bord
- de date
- de prelucrare a datelor
- știința datelor
- datetime
- zi
- adânc
- învățare profundă
- Def
- defini
- definit
- demonstrat
- dependențe
- implementa
- Implementarea
- desfășurarea
- proiect
- detalii
- Dezvoltare
- DevOps
- diferenţă
- dirijat
- director
- discreție
- discuta
- afișat
- distribuite
- diviziunilor
- do
- Descarca
- durate
- e
- mai ușor
- uşor
- eficiență
- eficient
- electric
- vehicul electric
- altfel
- subliniază
- angajat
- permite
- permițând
- un capăt la altul
- încheiat
- spori
- asigura
- asigură
- Mediu inconjurator
- medii
- eroare
- Eter (ETH)
- evalua
- evaluare
- exemplu
- exemple
- Cu excepția
- excepție
- execuție
- experienţă
- experiment
- experimente
- expirare
- explorare
- extindere
- extracţie
- FAIL
- eşecuri
- mai repede
- cel mai rapid
- DESCRIERE
- Fișier
- umple
- umplut
- final
- În cele din urmă
- Găsi
- terminat
- First
- Flexibilitate
- pluti
- debit
- fluxurilor
- Concentra
- concentrându-se
- urmează
- Pentru
- Cadru
- Gratuit
- din
- funcţie
- funcționalitate
- fundamental
- mai mult
- obține
- merge
- GitHub
- grafic
- Mânere
- Manipularea
- Avea
- ajutor
- ajută
- aici
- Înalt
- highlights-uri
- istorie
- gazdă
- oră
- Cum
- Cum Pentru a
- Totuși
- HTTPS
- Butuc
- i
- identifica
- if
- punerea în aplicare a
- ustensile
- import
- îmbunătăţi
- îmbunătăţeşte
- in
- include
- Inclusiv
- Creșteri
- individ
- Infrastructură
- intrare
- în interiorul
- instala
- instalare
- instalat
- interesant
- în
- implică
- IT
- ESTE
- jpg
- doar
- Cheie
- tipurile
- Cunoaște
- Etichetă
- pe scară largă
- în cele din urmă
- mai tarziu
- AFLAȚI
- învăţare
- Permite
- Pârghie
- biblioteci
- Bibliotecă
- Viaţă
- ciclu de viață
- ca
- Limitele
- liniar
- local
- la nivel local
- log
- autentificat
- logare
- Uite
- maşină
- masina de învățare
- întreținere
- face
- Efectuarea
- administra
- administrare
- gestionează
- de conducere
- multe
- max-width
- Mai..
- însemna
- Mass-media
- menționa
- Metode
- Metrici
- ar putea
- dispărut
- ML
- MLOps
- model
- Modele
- monitor
- Monitorizarea
- Lună
- mai mult
- trebuie sa
- my
- nume
- Numit
- Nevoie
- au nevoie
- nevoilor
- Nou
- următor
- Nici unul
- nota
- caiet
- notificări
- acum
- numere
- observa
- of
- promoții
- on
- ONE
- deschide
- open-source
- operaţie
- operațional
- Operațiuni
- optimă
- optimizarea
- or
- orchestrație
- organizații
- Altele
- al nostru
- peste
- propriu
- deţinute
- ambalaje
- panda
- parametrii
- parte
- cale
- efectuată
- efectuează
- conducte
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- intrigă
- Punct
- posibil
- puternic
- practicile
- prezice
- estimarea
- prezicere
- preţ
- Predicția prețurilor
- proces
- prelucrare
- producere
- profesioniști
- proiect
- Proiecte
- prevăzut
- furnizează
- furnizarea
- publicat
- Piton
- calitate
- întrebare
- repede
- r2
- ridica
- game
- variind
- gata
- lumea reală
- regres
- autoritățile de reglementare
- încredere
- se bazează
- rămâne
- repetabil
- depozit
- reprezentând
- reprezintă
- Cerinţe
- REZULTATE
- reconversie profesională
- reveni
- Returnează
- dreapta
- robust
- rădăcină
- RÂND
- Alerga
- funcţionare
- ruleaza
- de vânzări
- Economisiți
- scalabilitate
- Scară
- programa
- programare
- Ştiinţă
- oamenii de stiinta
- scor
- scorurile
- vedea
- SELF
- serie
- serverul
- serverless
- serviciu
- set
- instalare
- setări
- câteva
- superficial
- Distribuie
- partajarea
- să
- prezenta
- arătând
- indicat
- semna
- semnare
- simplu
- Simplifică
- simplificarea
- întrucât
- So
- soluţii
- uneori
- Sursă
- specificată
- Squared
- Începe
- început
- Pornire
- Pas
- paşi
- Strategie
- simplifica
- structura
- structurat
- a sustine
- Suportat
- sisteme
- Lua
- Takeaways
- Ţintă
- Sarcină
- sarcini
- echipe
- spune
- test
- Testarea
- decât
- acea
- Lor
- apoi
- Acolo.
- Acestea
- lucru
- Gândire
- acest
- aceste
- Prin
- timp
- la
- Unelte
- top
- urmări
- Urmărire
- Tren
- dresat
- Pregătire
- Transformare
- transformări
- încerca
- ÎNTORCĂ
- tutorial
- Tipuri
- unitate
- deblochează
- actualizat
- us
- utilizare
- utilizat
- util
- folosind
- Valori
- variabil
- vehicul
- Virtual
- vizualizare
- imagina
- a fost
- Ceas
- Cale..
- we
- web
- BINE
- Ce
- Ce este
- cand
- care
- în timp ce
- de ce
- voi
- fereastră
- ferestre
- cu
- fără
- cuvinte
- Apartamente
- flux de lucru
- fluxuri de lucru
- de lucru
- X
- an
- tu
- Ta
- zephyrnet