В мире искусственного интеллекта (ИИ) и машинного обучения (МО) наблюдается смена парадигмы с появлением генеративных моделей ИИ, которые могут создавать человекоподобный текст, изображения, код и аудио. По сравнению с классическими моделями машинного обучения генеративные модели ИИ значительно больше и сложнее. Однако их растущая сложность также сопряжена с высокими затратами на логические выводы и растущей потребностью в мощных вычислительных ресурсах. Высокая стоимость логического вывода для генеративных моделей ИИ может стать препятствием для входа на рынок для предприятий и исследователей с ограниченными ресурсами, что требует более эффективных и экономичных решений. Кроме того, большинство вариантов использования генеративного ИИ связаны с взаимодействием с человеком или реальными сценариями, что требует оборудования, способного обеспечить производительность с низкой задержкой. AWS внедряет инновации со специализированными чипами для удовлетворения растущей потребности в мощном, эффективном и экономичном вычислительном оборудовании.
Сегодня мы рады сообщить, что Создатель мудреца Амазонки поддерживает AWS Инферентия2 (мл.inf2) и AWS Трениум (ml.trn1) на основе экземпляров SageMaker для размещения генеративных моделей ИИ для вывода в реальном времени и асинхронного вывода. Экземпляры ml.inf2 доступны для развертывания модели в SageMaker на востоке США (Огайо) и экземпляры ml.trn1 на востоке США (Северная Вирджиния).
Вы можете использовать эти экземпляры в SageMaker для достижения высокой производительности при низких затратах для генеративных моделей ИИ, включая большие языковые модели (LLM), Stable Diffusion и преобразователи зрения. Кроме того, вы можете использовать Рекомендатор выводов Amazon SageMaker чтобы помочь вам запустить нагрузочные тесты и оценить преимущества соотношения цены и качества при развертывании вашей модели на этих экземплярах.
Вы можете использовать экземпляры ml.inf2 и ml.trn1 для запуска приложений машинного обучения в SageMaker для суммирования текста, генерации кода, создания видео и изображений, распознавания речи, персонализации, обнаружения мошенничества и многого другого. Вы можете легко начать работу, указав экземпляры ml.trn1 или ml.inf2 при настройке конечной точки SageMaker. Вы можете использовать совместимые с ml.trn1 и ml.inf2 контейнеры AWS Deep Learning Containers (DLC) для PyTorch, TensorFlow, Hugging Face и вывода больших моделей (LMI), чтобы легко приступить к работе. Полный список с версиями см. Доступные образы контейнеров глубокого обучения.
В этом посте мы показываем процесс развертывания большой языковой модели на AWS Inferentia2 с помощью SageMaker, не требуя дополнительного кодирования, используя преимущества контейнера LMI. Мы используем GPT4ALL-J, доработанная модель GPT-J 7B, обеспечивающая взаимодействие в стиле чат-бота.
Обзор экземпляров ml.trn1 и ml.inf2
Инстансы ml.trn1 работают на базе ускорителя Trainium, специально созданного для высокопроизводительного глубокого обучения генеративных моделей ИИ, включая LLM. Однако эти экземпляры также поддерживают рабочие нагрузки логического вывода для моделей, которые даже больше, чем умещается в Inf2. Самый большой размер инстанса, trn1.32xlarge, содержит 16 Ускорители Trainium с 512 ГБ памяти ускорителя в одном экземпляре, обеспечивающем до 3.4 петафлопс вычислительной мощности FP16/BF16. 16 ускорителей Trainium подключены к сверхскоростному каналу NeuronLinkv2 для оптимизации коллективных коммуникаций.
Экземпляры ml.Inf2 питаются от Ускоритель AWS Inferentia2, специально созданный ускоритель для логических выводов. Он обеспечивает в три раза более высокую производительность вычислений, до четырех раз более высокую пропускную способность и до 10 раз более низкую задержку по сравнению с AWS Inferentia первого поколения. Инстанс самого большого размера, Inf2.48xlarge, включает 12 ускорителей AWS Inferentia2 с 384 ГБ памяти ускорителя в одном инстансе, что обеспечивает общую вычислительную мощность 2.3 петафлопс для BF16/FP16. Он позволяет развертывать до 175 миллиардов параметров модели в одном экземпляре. Inf2 — единственный инстанс, оптимизированный для логического вывода, предлагающий это межсоединение, функция, доступная только в более дорогих инстансах для обучения. Для сверхбольших моделей, которые не помещаются в один ускоритель, данные передаются напрямую между ускорителями с помощью NeuronLink, полностью минуя центральный процессор. С помощью NeuronLink Inf2 поддерживает более быстрый распределенный логический вывод и улучшает пропускную способность и задержку.
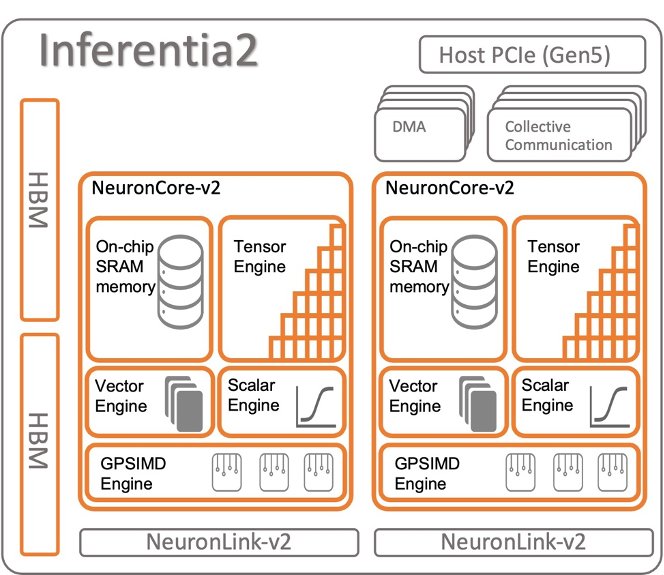
Ускорители AWS Inferentia2 и Trainium имеют два NeuronCores-v2, стеки памяти HBM объемом 32 ГБ и выделенные механизмы коллективных вычислений, которые автоматически оптимизируют время выполнения за счет перекрытия вычислений и обмена данными при выполнении логического вывода с несколькими ускорителями. Для получения более подробной информации об архитектуре см. Устройства Trainium и Inferentia.
На следующей диаграмме показан пример архитектуры с использованием AWS Inferentia2.
Нейрон SDK для AWS
АВС Нейрон — это SDK, используемый для запуска рабочих нагрузок глубокого обучения на экземплярах на базе AWS Inferentia и Trainium. AWS Neuron включает в себя компилятор глубокого обучения, среду выполнения и инструменты, изначально интегрированные в TensorFlow и PyTorch. С помощью Neuron вы можете разрабатывать, профилировать и развертывать высокопроизводительные рабочие нагрузки машинного обучения на файлах ml.trn1 и ml.inf2.
Ассоциация Компилятор нейронов принимает модели машинного обучения в различных форматах (TensorFlow, PyTorch, XLA HLO) и оптимизирует их для работы на устройствах Neuron. Компилятор Neuron вызывается в рамках платформы ML, где модели ML отправляются компилятору подключаемым модулем платформы Neuron. Полученный артефакт компилятора называется файлом NEFF (формат исполняемого файла Neuron), который, в свою очередь, загружается средой выполнения Neuron на устройство Neuron.
Ассоциация Нейронная среда выполнения состоит из драйвера ядра и библиотек C/C++, которые предоставляют API для доступа к устройствам AWS Inferentia и Trainium Neuron. Плагины платформ Neuron ML для TensorFlow и PyTorch используют среду выполнения Neuron для загрузки и запуска моделей в NeuronCores. Среда выполнения Neuron загружает скомпилированные модели глубокого обучения (NEFF) на устройства Neuron и оптимизирована для обеспечения высокой пропускной способности и низкой задержки.
Размещение моделей NLP с использованием экземпляров SageMaker ml.inf2
Прежде чем мы углубимся в обслуживание LLM с трансформеры-нейронкс, которая является библиотекой с открытым исходным кодом для разбиения матриц больших весов модели на несколько модулей NeuronCore, давайте кратко рассмотрим типичный процесс развертывания модели, которая может поместиться в один модуль NeuronCore.
Проверить список поддерживаемых моделей чтобы убедиться, что модель поддерживается на AWS Inferentia2. Затем модель должна быть предварительно скомпилирована компилятором Neuron. Вы можете использовать блокнот SageMaker или Эластичное вычислительное облако Amazon (Amazon EC2) для компиляции модели. Вы можете использовать SageMaker Python SDK для развертывания моделей с использованием популярных платформ глубокого обучения, таких как PyTorch, как показано в следующем коде. Вы можете развернуть свою модель в службах хостинга SageMaker и получить конечную точку, которую можно использовать для логического вывода. Эти конечные точки полностью управляемы и поддерживают автоматическое масштабирование.
Обратитесь к Потоки разработчиков для получения более подробной информации о типичных процессах разработки Inf2 в SageMaker с примерами сценариев.
Размещение LLM с использованием экземпляров SageMaker ml.inf2
Большие языковые модели с миллиардами параметров часто слишком велики для одного ускорителя. Это требует использования методов параллелизма моделей для размещения LLM на нескольких ускорителях. Еще одним важным требованием для размещения LLM является реализация высокопроизводительного решения для обслуживания моделей. Это решение должно эффективно загружать модель, управлять секционированием и беспрепятственно обслуживать запросы через конечные точки HTTP.
SageMaker включает в себя специализированные контейнеры глубокого обучения (DLC), библиотеки и инструменты для параллелизма моделей и вывода больших моделей. Ресурсы для начала работы с LMI в SageMaker см. Параллелизм моделей и вывод больших моделей. SageMaker поддерживает DLC с популярными библиотеками с открытым исходным кодом для размещения больших моделей, таких как GPT, T5, OPT, BLOOM и Stable Diffusion, в инфраструктуре AWS. Эти специализированные DLC называются контейнерами SageMaker LMI.
Контейнеры SageMaker LMI используйте DJLServing, модельный сервер, который интегрирован с библиотекой transforms-neuronx для поддержки тензорного параллелизма в NeuronCores. Чтобы узнать больше о том, как работает DJLServing, см. Развертывание больших моделей в Amazon SageMaker с использованием параллельного вывода моделей DJLServing и DeepSpeed.. Сервер модели DJL и библиотека transforms-neuronx служат основными компонентами контейнера, который также включает в себя Neuron SDK. Эта настройка упрощает загрузку моделей в ускорители AWS Inferentia2, распараллеливает модель между несколькими нейронными ядрами и позволяет обслуживать через конечные точки HTTP.
Контейнер LMI поддерживает загрузку моделей из Простой сервис хранения Amazon (Amazon S3) или Hugging Face Hub. Сценарий обработчика по умолчанию загружает модель, компилирует и преобразует ее в формат, оптимизированный для нейронов, и загружает ее. Чтобы использовать контейнер LMI для размещения LLM, у нас есть два варианта:
- Без кода (предпочтительно) – Это самый простой способ развернуть LLM с помощью контейнера LMI. В этом методе вы можете использовать предоставленный обработчик по умолчанию и просто передайте название модели и параметры, необходимые в
serving.propertiesфайл для загрузки и размещения модели. Чтобы использовать обработчик по умолчанию, мы предоставляемentryPointпараметр какdjl_python.transformers-neuronx. - Принесите свой сценарий – При таком подходе у вас есть возможность создать собственный файл model.py, содержащий код, необходимый для загрузки и обслуживания модели. Этот файл действует как посредник между
DJLServingAPI иtransformers-neuronxAPI. Чтобы настроить процесс загрузки модели, вы можете предоставитьserving.propertiesс настраиваемыми параметрами. Полный список доступных настраиваемых параметров см. Все варианты конфигурации DJL. Вот пример модель.py .
Архитектура времени выполнения
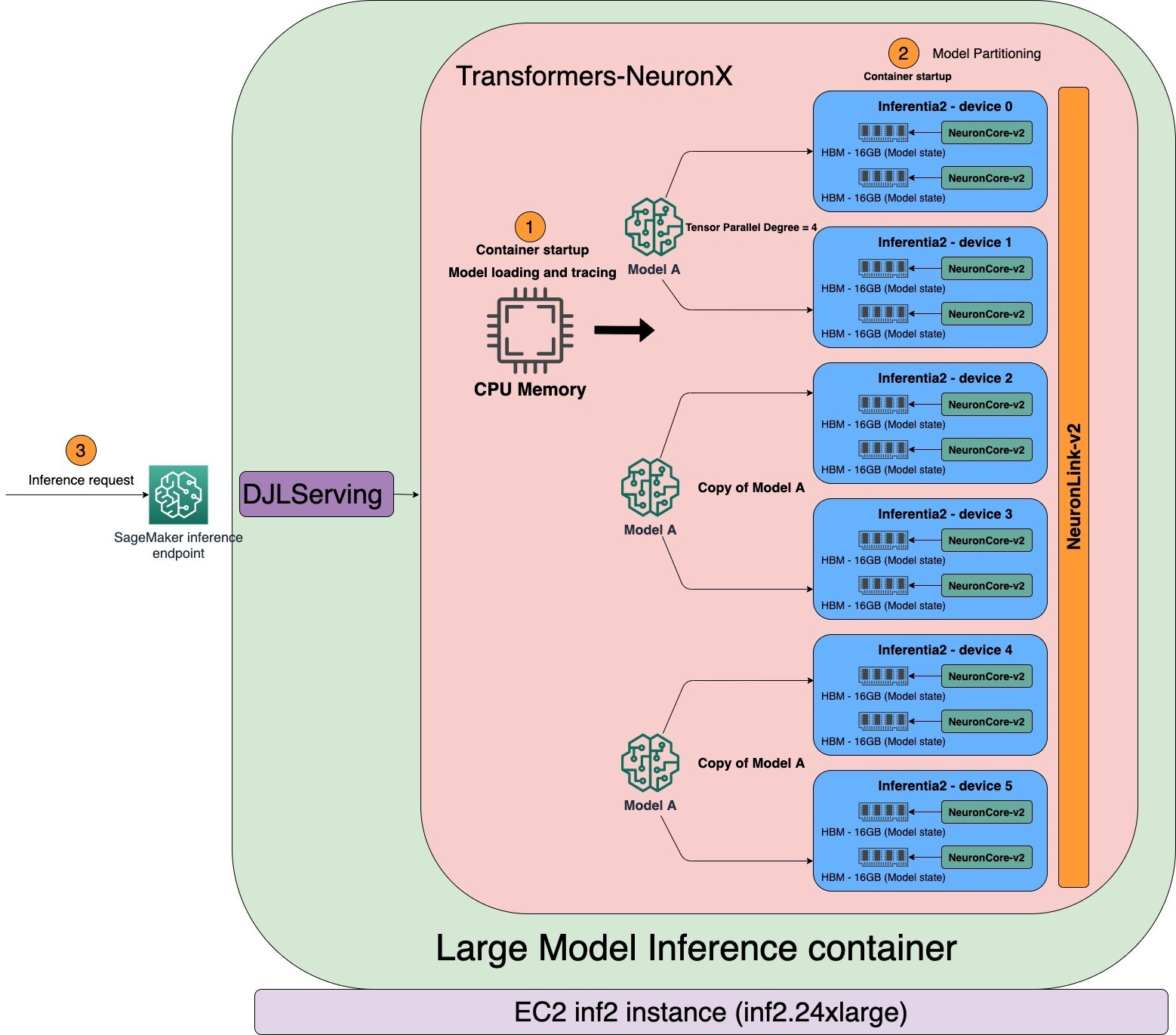
Ассоциация tensor_parallel_degree значение свойства определяет распределение тензорных параллельных модулей по нескольким нейронным ядрам. Например, inf2.24xlarge имеет шесть ускорителей AWS Inferentia2. Каждый ускоритель AWS Inferentia2 имеет два ядра NeuronCore. Каждый NeuronCore имеет выделенную память с высокой пропускной способностью (HBM) объемом 16 ГБ для хранения тензорных параллельных модулей. При степени параллельности тензора 4 LMI выделяет три копии одной и той же модели, каждая из которых использует четыре нейронных ядра. Как показано на следующей диаграмме, при запуске контейнера LMI модель будет загружена и трассирована первой в адресуемой памяти ЦП. Когда трассировка завершена, модель разбивается по ядрам NeuronCores на основе степени параллелизма тензора.
LMI использует DJLServing в качестве модели стека обслуживания. После прохождения проверки работоспособности контейнера в SageMaker контейнер готов к обслуживанию запроса на вывод. DJLServing запускает несколько процессов Python, эквивалентных TOTAL NUMBER OF NEURON CORES/TENSOR_PARALLEL_DEGREE. Каждый процесс Python содержит потоки в C++, эквивалентные TENSOR_PARALLEL_DEGREE. Каждый поток C++ содержит один фрагмент модели на одном NeuronCore.
Многие практики (процесс Python) склонны выполнять вывод последовательно, когда сервер вызывается с несколькими независимыми запросами. Хотя его проще настроить, обычно не рекомендуется использовать вычислительную мощность ускорителя. Чтобы решить эту проблему, DJLServing предлагает встроенную оптимизацию динамической пакетной обработки для объединения этих независимых запросов на вывод на стороне сервера для динамического формирования более крупного пакета для увеличения пропускной способности. Все запросы сначала достигают динамического дозатора, а затем попадают в фактические очереди заданий для ожидания вывода. Вы можете установить предпочтительные размеры пакетов для динамического пакетирования, используя batch_size Настройки в serving.properties. Вы также можете настроить max_batch_delay чтобы указать максимальное время задержки в дозаторе для ожидания других запросов на присоединение к пакету в соответствии с вашими требованиями к задержке. Пропускная способность также зависит от количества копий модели и групп процессов Python, запущенных в контейнере. Как показано на следующей диаграмме, при степени параллелизма тензора, равной 4, контейнер LMI запускает три группы процессов Python, каждая из которых содержит полную копию модели. Это позволяет увеличить размер партии и повысить производительность.
Блокнот SageMaker для развертывания LLM
В этом разделе мы представляем пошаговое руководство по развертыванию GPT4All-J, модели с 6 миллиардами параметров, занимающей 24 ГБ в FP32. GPT4All-J — популярный чат-бот, обученный работе с разнообразным интерактивным контентом, таким как текстовые задачи, диалоги, код, стихи, песни и рассказы. GPT4all-J — это точно настроенная модель GPT-J, которая генерирует ответы, подобные человеческому взаимодействию.
Полный блокнот для этого примера приведен на GitHub. Мы можем использовать SageMaker Python SDK для развертывания модели в экземпляре Inf2. Мы используем предоставленный обработчик по умолчанию загрузить модель. При этом нам просто нужно предоставить порции.свойства файл. Этот файл содержит необходимые конфигурации для сервера моделей DJL для загрузки и размещения модели. Мы можем указать имя модели Hugging Face, используя model_id для загрузки модели непосредственно из репозитория Hugging Face. Кроме того, вы можете загрузить модель с Amazon S3, предоставив s3url параметр. В entryPoint Параметр настроен так, чтобы он указывал на библиотеку для загрузки модели. Для получения более подробной информации о djl_python.fastertransformerобратитесь к Код GitHub.
Ассоциация tensor_parallel_degree значение свойства определяет распределение тензорных параллельных модулей по нескольким устройствам. Например, имея 12 нейронных ядер и степень параллелизма тензора 4, LMI выделит три копии модели, каждая из которых будет использовать четыре нейронных ядра. Вы также можете определить тип точности, используя свойство dtype. n_position Параметр определяет сумму максимальной длины входной и выходной последовательности для модели. См. следующий код:
Построить tarball содержащие serving.properties и загрузите его в корзину S3. Хотя в этом примере используется обработчик по умолчанию, вы можете разработать model.py файл для настройки процесса загрузки и обслуживания. Если есть какие-либо пакеты, требующие установки, включите их в requirements.txt файл. См. следующий код:
Получите образ контейнера DJL и создайте модель SageMaker:
Затем мы создаем конечную точку SageMaker с определенной ранее конфигурацией модели. Контейнер загружает модель в /tmp пространство, потому что SageMaker отображает /tmp в Магазин эластичных блоков Amazon (Амазон ЭБС). Нам нужно добавить volume_size параметр для обеспечения /tmp в каталоге достаточно места для загрузки и компиляции модели. Мы устанавливаем container_startup_health_check_timeout до 3,600 секунд, чтобы убедиться, что проверка работоспособности начинается после того, как модель будет готова. Мы используем экземпляр ml.inf2.8xlarge. См. следующий код:
После создания конечной точки SageMaker мы можем делать прогнозы в реальном времени относительно конечных точек SageMaker, используя Predictor объект:
Убирать
Удалите конечные точки, чтобы сократить расходы после завершения тестов:
Заключение
В этом посте мы продемонстрировали недавно запущенную возможность SageMaker, которая теперь поддерживает экземпляры ml.inf2 и ml.trn1 для размещения генеративных моделей ИИ. Мы продемонстрировали, как развернуть генеративную модель ИИ GPT4ALL-J на AWS Inferentia2 с помощью SageMaker и контейнера LMI без написания кода. Мы также продемонстрировали, как вы можете использовать DJLServing и transformers-neuronx загрузить модель, разбить ее и обслуживать.
Инстансы Inf2 — это наиболее экономичный способ запуска генеративных моделей ИИ на AWS. Подробнее о производительности см. Inf2 Производительность.
Попробуйте GitHub репо для примера ноутбука. Попробуйте и дайте нам знать, если у вас есть какие-либо вопросы!
Об авторах
 Вивек Гангасани является старшим архитектором решений для машинного обучения в Amazon Web Services. Он работает со стартапами машинного обучения над созданием и развертыванием приложений AI/ML на AWS. В настоящее время он сосредоточен на предоставлении решений для MLOps, ML Inference и low-code ML. Он работал над проектами в различных областях, включая обработку естественного языка и компьютерное зрение.
Вивек Гангасани является старшим архитектором решений для машинного обучения в Amazon Web Services. Он работает со стартапами машинного обучения над созданием и развертыванием приложений AI/ML на AWS. В настоящее время он сосредоточен на предоставлении решений для MLOps, ML Inference и low-code ML. Он работал над проектами в различных областях, включая обработку естественного языка и компьютерное зрение.
 Хироси Токойо работает архитектором решений в AWS Annapurna Labs. Находясь в Японии, он присоединился к Annapurna Labs еще до того, как ее приобрела AWS, и постоянно помогал клиентам с технологиями Annapurna Labs. В последнее время он занимается решениями для машинного обучения на базе специализированного кремния, AWS Inferentia и Trainium.
Хироси Токойо работает архитектором решений в AWS Annapurna Labs. Находясь в Японии, он присоединился к Annapurna Labs еще до того, как ее приобрела AWS, и постоянно помогал клиентам с технологиями Annapurna Labs. В последнее время он занимается решениями для машинного обучения на базе специализированного кремния, AWS Inferentia и Trainium.
 Дхавал Патель является главным архитектором машинного обучения в AWS. Он работал с организациями, начиная от крупных предприятий и заканчивая стартапами среднего размера, над проблемами, связанными с распределенными вычислениями и искусственным интеллектом. Он специализируется на глубоком обучении, включая домены NLP и Computer Vision. Он помогает клиентам добиться высокопроизводительного логического вывода модели в SageMaker.
Дхавал Патель является главным архитектором машинного обучения в AWS. Он работал с организациями, начиная от крупных предприятий и заканчивая стартапами среднего размера, над проблемами, связанными с распределенными вычислениями и искусственным интеллектом. Он специализируется на глубоком обучении, включая домены NLP и Computer Vision. Он помогает клиентам добиться высокопроизводительного логического вывода модели в SageMaker.
 Цин Лан является инженером-разработчиком программного обеспечения в AWS. Он работал над несколькими сложными продуктами в Amazon, включая высокопроизводительные решения для логического вывода машинного обучения и высокопроизводительную систему ведения журналов. Команда Цин успешно запустила первую модель с миллиардом параметров в Amazon Advertising с очень низкой задержкой. Цин обладает глубокими знаниями по оптимизации инфраструктуры и ускорению глубокого обучения.
Цин Лан является инженером-разработчиком программного обеспечения в AWS. Он работал над несколькими сложными продуктами в Amazon, включая высокопроизводительные решения для логического вывода машинного обучения и высокопроизводительную систему ведения журналов. Команда Цин успешно запустила первую модель с миллиардом параметров в Amazon Advertising с очень низкой задержкой. Цин обладает глубокими знаниями по оптимизации инфраструктуры и ускорению глубокого обучения.
 Цинвэй Ли является специалистом по машинному обучению в Amazon Web Services. Он получил докторскую степень. в исследованиях операций после того, как он нарушил счет своего советника на исследовательский грант и не смог вручить обещанную Нобелевскую премию. В настоящее время он помогает клиентам в сфере финансовых услуг и страхования создавать решения для машинного обучения на AWS. В свободное время любит читать и преподавать.
Цинвэй Ли является специалистом по машинному обучению в Amazon Web Services. Он получил докторскую степень. в исследованиях операций после того, как он нарушил счет своего советника на исследовательский грант и не смог вручить обещанную Нобелевскую премию. В настоящее время он помогает клиентам в сфере финансовых услуг и страхования создавать решения для машинного обучения на AWS. В свободное время любит читать и преподавать.
 Алан Тан является старшим менеджером по продуктам в SageMaker, возглавляющим работу по выводу больших моделей. Он увлечен применением машинного обучения в области аналитики. Вне работы он любит проводить время на свежем воздухе.
Алан Тан является старшим менеджером по продуктам в SageMaker, возглавляющим работу по выводу больших моделей. Он увлечен применением машинного обучения в области аналитики. Вне работы он любит проводить время на свежем воздухе.
 Варун Сиал — инженер-разработчик программного обеспечения в AWS Sagemaker, работающий над важными для клиентов функциями платформы ML Inference. Он увлечен работой в области распределенных систем и искусственного интеллекта. В свободное время любит читать и заниматься садоводством.
Варун Сиал — инженер-разработчик программного обеспечения в AWS Sagemaker, работающий над важными для клиентов функциями платформы ML Inference. Он увлечен работой в области распределенных систем и искусственного интеллекта. В свободное время любит читать и заниматься садоводством.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- ПлатонАйСтрим. Анализ данных Web3. Расширение знаний. Доступ здесь.
- Чеканка будущего с Эдриенн Эшли. Доступ здесь.
- Покупайте и продавайте акции компаний PREIPO® с помощью PREIPO®. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/achieve-high-performance-with-lowest-cost-for-generative-ai-inference-using-aws-inferentia2-and-aws-trainium-on-amazon-sagemaker/
- :имеет
- :является
- :нет
- :куда
- $UP
- 10
- 100
- 12
- 13
- 14
- 15%
- 22
- 24
- 8
- 9
- a
- О нас
- ускорение
- ускоритель
- ускорители
- Принимает
- доступ
- Учетная запись
- Достигать
- приобретение
- через
- акты
- Добавить
- дополнение
- адрес
- адресуемый
- плюс
- Реклама
- После
- против
- AI
- варианты использования ИИ
- AI / ML
- Все
- позволяет
- причислены
- Несмотря на то, что
- Amazon
- Amazon EC2
- Создатель мудреца Амазонки
- Amazon Web Services
- an
- аналитика
- и
- анонсировать
- Другой
- любой
- API
- Приложения
- Применение
- подхода
- архитектура
- МЫ
- ПЛОЩАДЬ
- искусственный
- искусственный интеллект
- Искусственный интеллект (AI)
- AS
- At
- аудио
- автоматический
- автоматически
- доступен
- AWS
- Вывод AWS
- мяч
- Пропускная способность
- барьер
- основанный
- BE
- , так как:
- было
- до
- Преимущества
- ЛУЧШЕЕ
- между
- большой
- больший
- миллиарды
- Заблокировать
- Блог
- Цвести
- кратко
- Сломался
- строить
- построенный
- встроенный
- бизнес
- by
- C + +
- под названием
- CAN
- случаев
- сложные
- Chatbot
- проверка
- чипсы
- код
- Кодирование
- собирательный
- объединять
- сочетании
- выходит
- Связь
- Связь
- сравненный
- совместим
- полный
- полностью
- комплекс
- сложность
- компоненты
- комплексный
- вычисление
- Вычисление
- компьютер
- Компьютерное зрение
- вычисление
- Конфигурация
- Конфигурации
- подключенный
- Container
- Контейнеры
- содержит
- содержание
- Основные
- Цена
- рентабельным
- Расходы
- ЦП
- Создайте
- создали
- критической
- решающее значение
- В настоящее время
- клиент
- Клиенты
- настроить
- данным
- преданный
- глубоко
- глубокое обучение
- По умолчанию
- определенный
- Определяет
- Степень
- задерживать
- доставить
- доставки
- обеспечивает
- убивают
- зависит
- развертывание
- развертывание
- развертывание
- подробнее
- обнаружение
- определяет
- развивать
- Развитие
- устройство
- Устройства
- различный
- Вещание
- непосредственно
- распределенный
- распределенных вычислений
- распределенные системы
- распределение
- дело
- доменов
- Dont
- скачать
- загрузок
- водитель
- динамический
- динамично
- каждый
- Ранее
- легче
- Простейший
- легко
- восток
- EBS
- эффективный
- эффективно
- усилия
- позволяет
- конец
- Конечная точка
- инженер
- Двигатели
- достаточно
- обеспечивать
- предприятий
- запись
- Эквивалент
- Эфир (ETH)
- оценивать
- Даже
- пример
- возбужденный
- дорогим
- дополнительно
- Face
- облегчает
- всего лишь пяти граммов героина
- Oшибка
- быстрее
- Особенность
- Особенности
- Файл
- финансовый
- финансовая служба
- окончание
- Во-первых,
- соответствовать
- поток
- Потоки
- Фокус
- внимание
- фокусируется
- после
- Что касается
- форма
- формат
- 4
- Рамки
- каркасы
- мошенничество
- обнаружение мошенничества
- от
- полный
- полностью
- Более того
- генерирует
- поколение
- генеративный
- Генеративный ИИ
- получить
- Go
- предоставлять
- Группы
- Рост
- Аппаратные средства
- Есть
- he
- Медицина
- помощь
- помог
- помогает
- здесь
- High
- высокая производительность
- высший
- его
- проведение
- имеет
- кашель
- хостинг
- Вилла / Бунгало
- Как
- How To
- Однако
- HTML
- HTTP
- HTTPS
- хаб
- человек
- if
- изображение
- генерация изображения
- изображений
- реализация
- Импортировать
- улучшается
- in
- углубленный
- включают
- включает в себя
- В том числе
- Увеличение
- повышение
- независимые
- промышленность
- Инфраструктура
- инновации
- вход
- затраты
- установка
- пример
- страхование
- страховая индустрия
- интегрированный
- Интеллекта
- взаимодействие
- взаимодействие
- посредник
- в
- вызывается
- включать в себя
- IT
- ЕГО
- Япония
- работа
- присоединиться
- присоединился
- JPG
- JSON
- всего
- Знать
- знания
- Labs
- язык
- большой
- Крупные предприятия
- больше
- крупнейших
- Задержка
- запустили
- запускает
- ведущий
- УЧИТЬСЯ
- изучение
- Длина
- библиотеки
- Библиотека
- такое как
- Ограниченный
- Список
- загрузка
- погрузка
- грузы
- каротаж
- Низкий
- низший
- машина
- обучение с помощью машины
- в основном
- поддерживает
- Большинство
- сделать
- управлять
- управляемого
- менеджер
- Карты
- Макс
- максимальный
- Память
- метод
- ML
- млн операций в секунду
- модель
- Модели
- Модули
- БОЛЕЕ
- более эффективным
- самых
- с разными
- имя
- натуральный
- Естественный язык
- Обработка естественного языка
- необходимо
- Необходимость
- потребности
- Новые
- New York
- следующий
- НЛП
- нобелевская торговая точка
- ноутбук
- сейчас
- номер
- объект
- of
- предлагают
- Предложения
- .
- Огайо
- on
- ONE
- только
- с открытым исходным кодом
- Операционный отдел
- оптимизация
- Оптимизировать
- оптимизированный
- оптимизирует
- Опция
- Опции
- or
- организации
- Другое
- наши
- внешний
- на открытом воздухе
- выходной
- внешнюю
- собственный
- пакеты
- парадигма
- Параллельные
- параметр
- параметры
- pass
- проходит
- страстный
- производительность
- воплощение
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- плагин
- плагины
- Точка
- Популярное
- После
- мощностью
- Питание
- мощный
- практика
- Точность
- Predictions
- Predictor
- привилегированный
- Основной
- приз
- проблемам
- процесс
- Процессы
- обработка
- Продукт
- Менеджер по продукции
- Продукция
- Профиль
- проектов
- обещанный
- свойства
- собственность
- обеспечивать
- при условии
- приводит
- обеспечение
- цель
- Питон
- pytorch
- ранжирование
- достигать
- Reading
- готовый
- реальный мир
- реального времени
- получила
- последний
- признание
- назвало
- Связанный
- запросить
- Запросы
- обязательный
- требование
- Требования
- исследованиям
- исследователи
- Полезные ресурсы
- ответы
- в результате
- Рост
- Run
- sagemaker
- Вывод SageMaker
- то же
- Сохранить
- масштабирование
- Сценарии
- скрипты
- SDK
- легко
- секунды
- Раздел
- посмотреть
- старший
- Последовательность
- служить
- обслуживание
- Услуги
- выступающей
- набор
- настройки
- установка
- несколько
- сдвиг
- должен
- показывать
- продемонстрированы
- показанный
- Шоу
- сторона
- существенно
- кремний
- аналогичный
- просто
- одинарной
- ШЕСТЬ
- Размер
- Размеры
- So
- Software
- разработка программного обеспечения
- Решение
- Решения
- Space
- специалист
- специализированный
- речь
- Распознавание речи
- стабильный
- стек
- Стеки
- Начало
- и политические лидеры
- начинается
- Стартапы
- диск
- Истории
- обтекаемый
- стиль
- Успешно
- такие
- поддержка
- Поддержанный
- Поддержка
- система
- системы
- с
- Обучение
- команда
- снижения вреда
- Технологии
- tensorflow
- тестов
- чем
- который
- Ассоциация
- Местоположение
- их
- Их
- Там.
- Эти
- этой
- три
- Через
- пропускная способность
- время
- раз
- в
- слишком
- инструменты
- трассировка
- специалистов
- Обучение
- трансформеры
- ОЧЕРЕДЬ
- два
- напишите
- типичный
- загружено
- us
- использование
- используемый
- через
- обычно
- использовать
- Использующий
- ценностное
- разнообразие
- различный
- Огромная
- очень
- с помощью
- Видео
- Виргиния
- видение
- ждать
- прохождение
- Путь..
- we
- Web
- веб-сервисы
- вес
- Что
- когда
- , которые
- будете
- в
- без
- свидетели
- Word
- Работа
- работавший
- работает
- работает
- Мир
- записывать
- письмо
- йорк
- являетесь
- ВАШЕ
- зефирнет