Этот пост написан совместно с Ривлином Перейрой и Вайбхавом Панди из Tanzu CloudHealth (VMware от Broadcom).
VMware Tanzu CloudHealth — это платформа управления затратами на облако, которую выбирают более 20,000 2.0 организаций по всему миру, которые полагаются на нее для оптимизации и управления своими крупнейшими и наиболее сложными мультиоблачными средами. В этом посте мы обсудим, как команда DevOps VMware Tanzu CloudHealth перенесла свои самоуправляемые рабочие нагрузки Apache Kafka (под управлением версии XNUMX) на Amazon Managed Streaming для Apache Kafka (Amazon MSK) под управлением версии 2.6.2. Мы обсуждаем системные архитектуры, конвейеры развертывания, создание тем, наблюдаемость, контроль доступа, миграцию тем и все проблемы, с которыми мы столкнулись в существующей инфраструктуре, а также то, как и почему мы перешли на новую настройку Kafka, и некоторые извлеченные уроки.
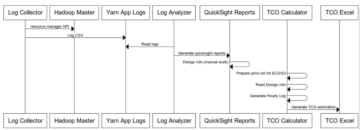
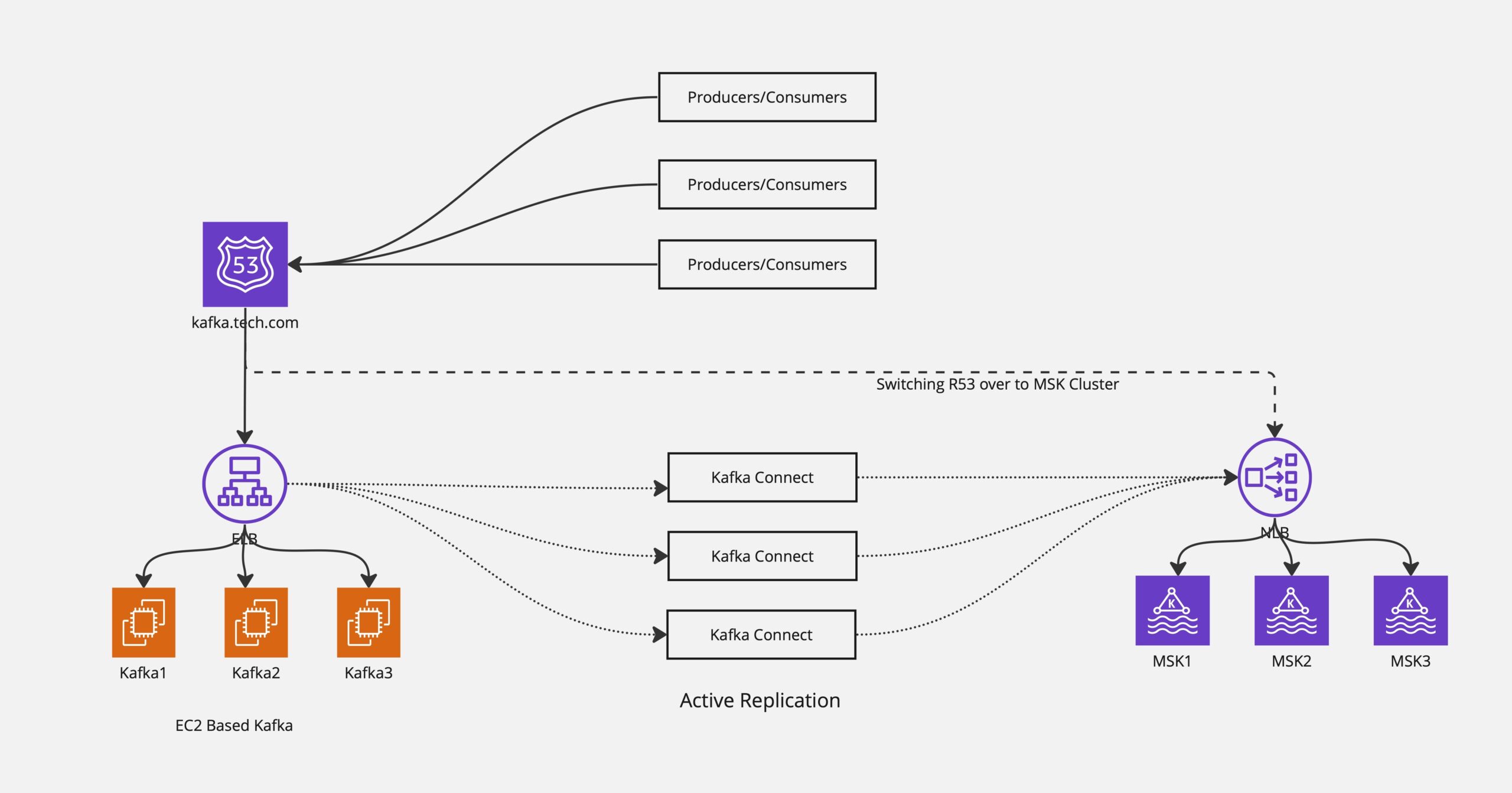
Обзор кластера Kafka
В быстро развивающейся среде распределенных систем платформа микросервисов нового поколения VMware Tanzu CloudHealth опирается на Kafka в качестве основы для обмена сообщениями. По нашему мнению, высокопроизводительная система распределенного журналирования Kafka превосходно справляется с огромными потоками данных, что делает ее незаменимой для бесперебойной связи. Выступая в качестве распределенной системы журналов, Kafka эффективно собирает и хранит разнообразные журналы, от журналов доступа к HTTP-серверу до журналов аудита событий безопасности.
Универсальность Kafka проявляется в поддержке ключевых шаблонов обмена сообщениями, обработке сообщений как базовых журналов или структурированных хранилищ «ключ-значение». Динамическое секционирование и последовательный порядок обеспечивают эффективную организацию сообщений. Непоколебимая надежность Kafka сочетается с нашей приверженностью обеспечению целостности данных.
Интеграция сервисов Ruby с Kafka упрощается с помощью библиотеки Karafka, действующей как оболочка более высокого уровня. Другие наши службы языкового стека используют аналогичные оболочки. Надежные функции отладки и административные команды Kafka играют ключевую роль в обеспечении бесперебойной работы и работоспособности инфраструктуры.
Кафка как архитектурный столп
В платформе микросервисов нового поколения VMware Tanzu CloudHealth Kafka выступает в качестве важнейшей архитектурной опоры. Его способность обрабатывать высокие скорости передачи данных, поддерживать разнообразные шаблоны обмена сообщениями и гарантировать доставку сообщений полностью соответствует нашим оперативным потребностям. Поскольку мы продолжаем внедрять инновации и масштабироваться, Kafka остается верным спутником, позволяя нам создавать отказоустойчивую и эффективную инфраструктуру.
Почему мы перешли на Amazon MSK
Для нас переход на Amazon MSK сводился к трем ключевым моментам принятия решения:
- Упрощенные технические операции – Запуск Kafka в самоуправляемой инфраструктуре был для нас операционными накладными расходами. Мы какое-то время не обновляли Kafka версии 2.0.0, а работа брокеров Kafka прекращалась, что приводило к проблемам с отключением тем. Нам также пришлось вручную запускать скрипты для увеличения коэффициентов репликации и ребалансировки лидеров, что требовало дополнительных усилий вручную.
- Устаревшие устаревшие конвейеры и упрощенные разрешения – Мы хотели отойти от существующих конвейеров, написанных на анзибль для создания тем Kafka в кластере. У нас также был громоздкий процесс предоставления членам команды доступа к машинам Kafka на этапе подготовки и производства, и мы хотели его упростить.
- Стоимость, исправления и поддержка - Так как Зоопарк апачей полностью управляется и исправляется AWS, переход на Amazon MSK позволит нам сэкономить время и деньги. Кроме того, мы обнаружили, что использование Amazon MSK с брокерами того же типа на Эластичное вычислительное облако Amazon (Amazon EC2) было дешевле запускать на Amazon MSK. Учитывая тот факт, что мы получаем исправления безопасности, применяемые к брокерам от AWS, переход на Amazon MSK оказался простым решением. Это также означало, что команда освободилась для работы над другими важными вещами. Наконец, получение корпоративной поддержки от AWS также сыграло решающую роль в нашем окончательном решении о переходе на управляемое решение.
Как мы мигрировали на Amazon MSK
Определив ключевые факторы, мы приступили к разработке предложенного проекта по миграции существующей Kafka с самоуправлением на Amazon MSK. Перед фактической реализацией мы выполнили следующие шаги перед миграцией:
- Оценка:
- Проведена тщательная оценка существующего кластера EC2 Kafka, понимание его конфигураций и зависимостей.
- Проверенная совместимость версии Kafka с Amazon MSK.
- Настройка Amazon MSK с помощью Terraform
- Конфигурация сети:
- Обеспечено бесперебойное сетевое соединение между кластерами EC2 Kafka и MSK, точная настройка групп безопасности и настроек брандмауэра.
После предварительных этапов миграции мы реализовали в новом дизайне следующее:
- Автоматизированные конвейеры развертывания, обновления и создания тем для кластеров MSK:
- В новой настройке мы хотели обеспечить повторяемое автоматическое развертывание и обновление кластеров MSK с использованием инструмента IaC. Поэтому мы создали специальные модули Terraform для развертывания и обновления кластера MSK. Эти модули вызывались из Дженкинс конвейер для автоматического развертывания и обновления кластеров MSK. Для создания тем Kafka мы использовали собственный конвейер на базе Ansible, который не был стабильным и вызывал множество жалоб со стороны команд разработчиков. В результате мы оценили варианты развертывания для Kubernetes кластеры и использовали Оператор темы Стримзи для создания тем по кластерам MSK. Создание тем было автоматизировано с использованием конвейеров Jenkins, которые команды разработчиков могли обслуживать самостоятельно.
- Лучшая наблюдаемость кластеров:
- Старые кластеры Кафки не имели хорошей наблюдаемости. У нас были оповещения только о размере диска брокера Kafka. Благодаря Amazon MSK мы воспользовались преимуществами открытый мониторинг через Прометей. Мы установили автономный сервер Prometheus, который собирал метрики из кластеров MSK и отправлял их в наш внутренний инструмент наблюдения. В результате улучшения наблюдения мы смогли настроить надежные оповещения для Amazon MSK, что было невозможно при нашей старой настройке.
- Улучшенная COGS и улучшенная вычислительная инфраструктура:
- В нашей старой инфраструктуре Kafka нам приходилось платить за управление экземплярами Kafka, Zookeeper, а также любые дополнительные затраты на хранение данных у брокера и затраты на передачу данных. Поскольку при переходе на Amazon MSK Zookeeper полностью управляется AWS, нам придется платить только за узлы Kafka, хранилище брокера и затраты на передачу данных. В результате при окончательной настройке Amazon MSK для производства мы сэкономили не только на затратах на инфраструктуру, но и на эксплуатационных расходах.
- Упрощенные операции и повышенная безопасность:
- После перехода на Amazon MSK нам не пришлось управлять экземплярами Zookeeper. AWS также позаботилась за нас об обновлении безопасности брокера.
- Обновление кластера стало проще с переходом на Amazon MSK; это простой процесс, который можно запустить с консоли Amazon MSK.
- Благодаря Amazon MSK у нас появился брокер автоматическое масштабирование из коробки. В результате нам не пришлось беспокоиться о том, что у брокеров закончится дисковое пространство, что привело к дополнительной стабильности кластера MSK.
- Мы также получили дополнительную безопасность для кластера, поскольку Amazon MSK по умолчанию поддерживает шифрование при хранении, а также доступны различные варианты шифрования при передаче. Для получения дополнительной информации см. Защита данных в Amazon Managed Streaming для Apache Kafka.
На этапе подготовки к миграции мы проверили настройку в промежуточной среде, прежде чем приступить к работе.
Стратегия миграции тем Kafka
Завершив настройку кластера MSK, мы выполнили миграцию данных тем Kafka из старого кластера, работающего на Amazon EC2, в новый кластер MSK. Для достижения этой цели мы выполнили следующие шаги:
- Настройте MirrorMaker с помощью Terraform – Мы использовали Terraform для организации развертывания ЗеркалоМастер кластер, состоящий из 15 узлов. Это продемонстрировало масштабируемость и гибкость за счет регулировки количества узлов в зависимости от потребностей одновременной репликации миграции.
- Внедрение стратегии одновременной репликации. Мы реализовали стратегию одновременной репликации с 15 узлами MirrorMaker, чтобы ускорить процесс миграции. Наш подход, основанный на Terraform, способствовал оптимизации затрат за счет эффективного управления ресурсами во время миграции и обеспечил надежность и согласованность кластеров MSK и MirrorMaker. Также было продемонстрировано, как выбранная установка ускоряет передачу данных, оптимизируя время и ресурсы.
- Перенести данные – Мы успешно перенесли 2 ТБ данных в удивительно короткие сроки, минимизировав время простоя и продемонстрировав эффективность стратегии параллельной репликации.
- Настройка мониторинга после миграции – Мы внедрили надежный мониторинг и оповещение во время миграции, способствуя плавному процессу за счет быстрого выявления и устранения проблем.
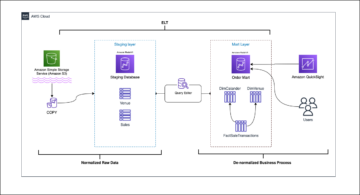
На следующей диаграмме показана архитектура после завершения миграции темы.
Проблемы и извлеченные уроки
Переход к миграции, особенно с большими наборами данных, часто сопровождается непредвиденными проблемами. В этом разделе мы подробно рассмотрим проблемы, возникшие при миграции тем из EC2 Kafka в Amazon MSK с помощью MirrorMaker, и поделимся ценной информацией и решениями, которые повлияли на успех нашей миграции.
Проблема 1: Расхождения в смещениях
Одной из проблем, с которыми мы столкнулись, было несоответствие смещений тем между исходным и целевым кластерами даже при включенной синхронизации смещений в MirrorMaker. Урок, извлеченный здесь, заключался в том, что значения смещения не обязательно должны быть идентичными, если включена синхронизация смещения, которая гарантирует, что темы имеют правильную позицию для чтения данных.
Мы решили эту проблему, используя специальный инструмент для запуска тестов на группах потребителей, подтвердив, что преобразованные смещения были либо меньшими, либо совпадающими, что указывает на синхронизацию согласно MirrorMaker.
Проблема 2: Медленная миграция данных
Процесс миграции столкнулся с узким местом — передача данных была медленнее, чем ожидалось, особенно с существенным набором данных объемом 2 ТБ. Несмотря на кластер MirrorMaker из 20 узлов, скорость была недостаточной.
Чтобы преодолеть эту проблему, команда стратегически сгруппировала узлы MirrorMaker на основе уникальных номеров портов. Кластеры из пяти узлов MirrorMaker, каждый из которых имеет отдельный порт, значительно увеличили пропускную способность, позволяя нам переносить данные в течение нескольких часов, а не дней.
Проблема 3: Отсутствие подробной технологической документации
Исследование неизведанной территории миграции больших наборов данных с помощью MirrorMaker выявило отсутствие подробной документации для таких сценариев.
Методом проб и ошибок команда создала модуль IaC с использованием Terraform. Этот модуль упростил весь процесс создания кластера с помощью оптимизированных настроек, что позволило плавно начать миграцию за считанные минуты.
Окончательная настройка и следующие шаги
В результате перехода на Amazon MSK наша окончательная настройка после миграции темы выглядела так, как показано на следующей диаграмме.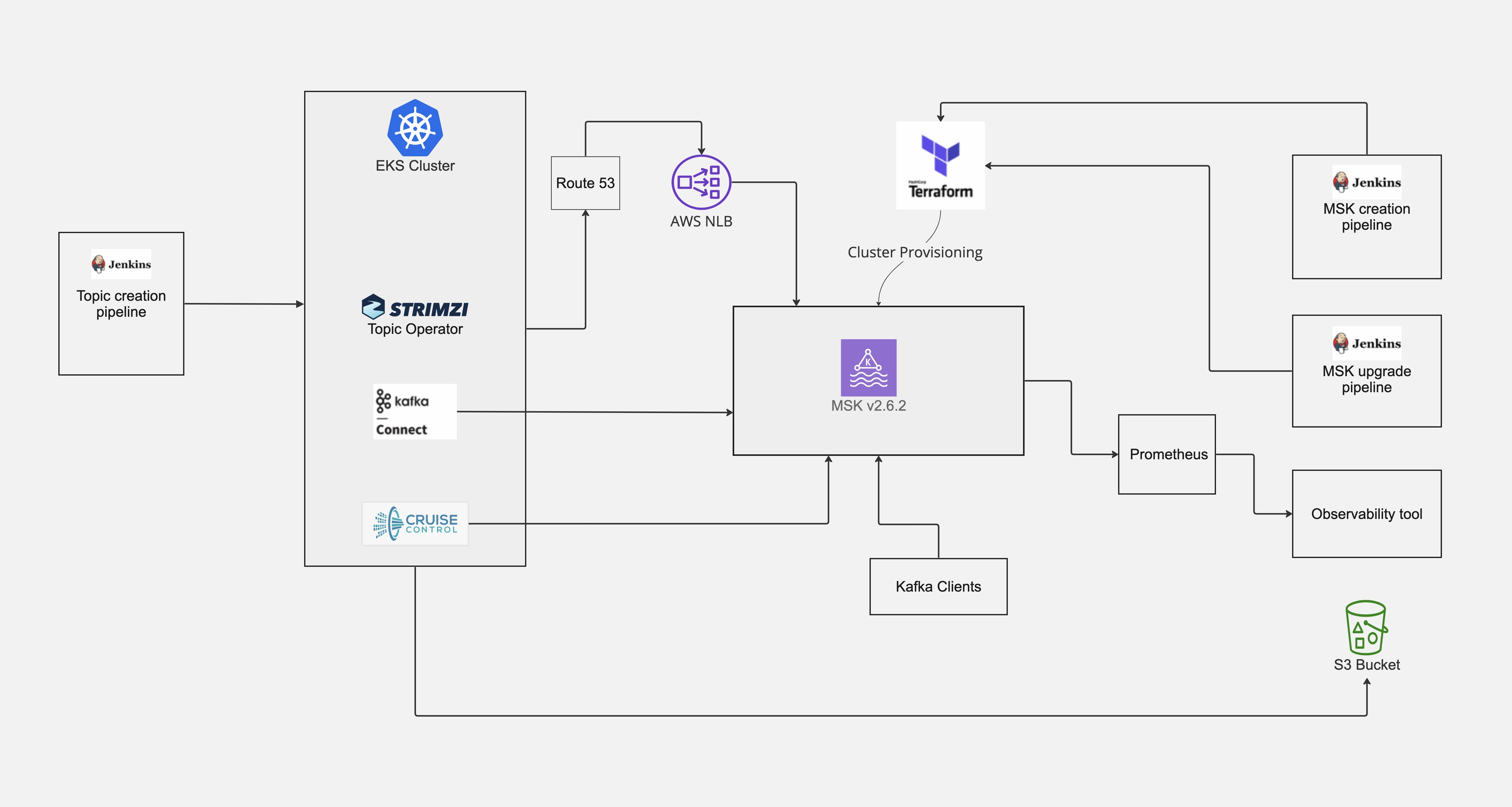
Мы рассматриваем следующие будущие улучшения:
ЗАКЛЮЧЕНИЕ.
В этом посте мы обсудили, как VMware Tanzu CloudHealth перенесла существующую инфраструктуру Kafka на базе Amazon EC2 в Amazon MSK. Мы рассказали вам о новой архитектуре, конвейерах развертывания и создания тем, улучшениях в области наблюдения и контроля доступа, проблемах миграции тем и проблемах, с которыми мы столкнулись в существующей инфраструктуре, а также о том, как и почему мы перешли на новую настройку Amazon MSK. Мы также рассказали обо всех преимуществах, которые дал нам Amazon MSK, об окончательной архитектуре, которую мы получили в результате этой миграции, и об извлеченных уроках.
Для нас взаимодействие смещенной синхронизации, стратегической группировки узлов и IaC оказалось решающим в преодолении препятствий и обеспечении успешного перехода с Amazon EC2 Kafka на Amazon MSK. Этот пост служит свидетельством силы адаптивности и инноваций в решении миграционных проблем, предлагая ценную информацию для других, идущих по аналогичному пути.
Если вы используете Kafka с самоуправляемым управлением на AWS, мы рекомендуем вам попробовать управляемое предложение Kafka. Амазон МСК.
Об авторах
 Ривлин Перейра — штатный инженер DevOps в подразделении VMware Tanzu. Он очень увлечен Kubernetes и работает над платформой CloudHealth, создавая и эксплуатируя облачные решения, которые являются масштабируемыми, надежными и экономически эффективными.
Ривлин Перейра — штатный инженер DevOps в подразделении VMware Tanzu. Он очень увлечен Kubernetes и работает над платформой CloudHealth, создавая и эксплуатируя облачные решения, которые являются масштабируемыми, надежными и экономически эффективными.
 Вайбхав Пандей, штатный инженер-программист в Broadcom, вносит ключевой вклад в разработку решений для облачных вычислений. Специализируясь на проектировании и проектировании уровней хранения данных, он увлечен созданием и масштабированием SaaS-приложений для достижения оптимальной производительности.
Вайбхав Пандей, штатный инженер-программист в Broadcom, вносит ключевой вклад в разработку решений для облачных вычислений. Специализируясь на проектировании и проектировании уровней хранения данных, он увлечен созданием и масштабированием SaaS-приложений для достижения оптимальной производительности.
 Радж Рамасуббу — старший специалист по аналитике, архитектор решений, специализирующийся на больших данных и аналитике, а также на искусственном интеллекте и машинном обучении с помощью Amazon Web Services. Он помогает клиентам проектировать и создавать высокомасштабируемые, производительные и безопасные облачные решения на AWS. До прихода в AWS Радж предоставлял технические знания и руководил разработкой решений для обработки данных, аналитики больших данных, бизнес-аналитики и обработки данных более 18 лет. Он помогал клиентам в различных отраслевых вертикалях, таких как здравоохранение, медицинское оборудование, медико-биологические науки, розничная торговля, управление активами, страхование автомобилей, жилые REIT, сельское хозяйство, титульное страхование, цепочка поставок, управление документами и недвижимость.
Радж Рамасуббу — старший специалист по аналитике, архитектор решений, специализирующийся на больших данных и аналитике, а также на искусственном интеллекте и машинном обучении с помощью Amazon Web Services. Он помогает клиентам проектировать и создавать высокомасштабируемые, производительные и безопасные облачные решения на AWS. До прихода в AWS Радж предоставлял технические знания и руководил разработкой решений для обработки данных, аналитики больших данных, бизнес-аналитики и обработки данных более 18 лет. Он помогал клиентам в различных отраслевых вертикалях, таких как здравоохранение, медицинское оборудование, медико-биологические науки, розничная торговля, управление активами, страхование автомобилей, жилые REIT, сельское хозяйство, титульное страхование, цепочка поставок, управление документами и недвижимость.
 Тодд МакГрат — специалист по потоковой передаче данных в Amazon Web Services, где он консультирует клиентов по стратегиям потоковой передачи, интеграции, архитектуре и решениям. Что касается личной жизни, ему нравится наблюдать за своими тремя подростками и поддерживать их в их любимых занятиях, а также заниматься своими собственными занятиями, такими как рыбалка, пиклбол, хоккей с шайбой и счастливые часы с друзьями и семьей на понтонных лодках. Свяжитесь с ним в LinkedIn.
Тодд МакГрат — специалист по потоковой передаче данных в Amazon Web Services, где он консультирует клиентов по стратегиям потоковой передачи, интеграции, архитектуре и решениям. Что касается личной жизни, ему нравится наблюдать за своими тремя подростками и поддерживать их в их любимых занятиях, а также заниматься своими собственными занятиями, такими как рыбалка, пиклбол, хоккей с шайбой и счастливые часы с друзьями и семьей на понтонных лодках. Свяжитесь с ним в LinkedIn.
 Сатья Паттанаик — старший архитектор решений в AWS. Он помогает независимым поставщикам программного обеспечения создавать масштабируемые и отказоустойчивые приложения в облаке AWS. До прихода в AWS он играл значительную роль в развитии и успехе корпоративных сегментов. Вне работы он проводит время, изучая, «как приготовить ароматное барбекю», и пробуя новые рецепты.
Сатья Паттанаик — старший архитектор решений в AWS. Он помогает независимым поставщикам программного обеспечения создавать масштабируемые и отказоустойчивые приложения в облаке AWS. До прихода в AWS он играл значительную роль в развитии и успехе корпоративных сегментов. Вне работы он проводит время, изучая, «как приготовить ароматное барбекю», и пробуя новые рецепты.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/how-vmware-tanzu-cloudhealth-migrated-from-self-managed-kafka-to-amazon-msk/
- :имеет
- :является
- :нет
- :куда
- $UP
- 000
- 1
- 100
- 102
- 15%
- 2%
- 20
- 6
- a
- способность
- в состоянии
- О нас
- отсутствие
- ускоряет
- доступ
- в сопровождении
- Достигать
- достигнутый
- действующий
- Действие
- активно
- фактического соединения
- адаптируемость
- дополнение
- дополнительный
- адресованный
- адресация
- регулировка
- административный
- плюс
- Преимущества
- После
- сельское хозяйство
- впереди
- AI / ML
- Оповещения
- Выравнивает
- Все
- Позволяющий
- вдоль
- причислены
- Amazon
- Amazon EC2
- Amazon Web Services
- an
- аналитика
- и
- и инфраструктура
- Ожидаемый
- любой
- апаш
- Апач Кафка
- Приложения
- прикладной
- подхода
- архитектурный
- архитектура
- архитектуры
- МЫ
- AS
- оценки;
- активы
- управление активами
- At
- аудит
- Автоматизированный
- доступен
- прочь
- AWS
- Позвоночник
- основанный
- основной
- BE
- стали
- , так как:
- было
- до
- Лучшая
- между
- большой
- Big Data
- Блог
- Повышенный
- изоферменты печени
- Коробка
- Broadcom
- брокер
- Брокеры
- строить
- Строительство
- бизнес
- бизнес-аналитика
- но
- by
- под названием
- пришел
- перехватывает
- автомобиль
- страхование автомобиля
- заботится
- пойманный
- Причинение
- цепь
- проблемы
- более дешевый
- выбор
- выбранный
- облако
- облачных вычислений
- Кластер
- сочетании
- обязательство
- Связь
- спутник
- совместимость
- жалобы
- полный
- полностью
- комплекс
- Вычисление
- вычисление
- параллельный
- проводятся
- Конфигурация
- Конфигурации
- подтверждающий
- Свяжитесь
- связь
- принимая во внимание
- согласованность
- последовательный
- Состоящий из
- Консоли
- потребитель
- продолжать
- способствовало
- содействие
- участник
- контроль
- исправить
- Цена
- Управление затратами
- Расходы
- может
- проработаны
- Создайте
- создали
- создание
- критической
- громоздкий
- изготовленный на заказ
- Клиенты
- данным
- Анализ данных
- наука о данных
- хранение данных
- Наборы данных
- Дней
- решение
- По умолчанию
- поставка
- копаться
- убивают
- развертывание
- развертывания
- Проект
- Несмотря на
- назначение
- подробный
- Дев
- Развитие
- Устройства
- DevOps
- диаграмма
- открытый
- обсуждать
- обсуждается
- отчетливый
- распределенный
- распределенные системы
- Разное
- Разделение
- документ
- управление документами
- документации
- Dont
- вниз
- время простоя
- драйверы
- в течение
- динамический
- каждый
- легко
- Эффективный
- затрат
- эффективный
- эффективно
- усилие
- или
- возникает
- включен
- позволяет
- поощрять
- шифрование
- инженер
- Проект и
- расширение
- обеспечивать
- обеспечивается
- обеспечение
- Предприятие
- Весь
- Окружающая среда
- средах
- ошибка
- особенно
- имущество
- Эфир (ETH)
- оценивается
- Даже
- События
- существующий
- ускорять
- опыта
- сталкиваются
- факт
- факторы
- семья
- Фэшн
- Особенности
- окончательный
- в заключение
- брандмауэр
- Рыбалка
- 5
- Трансформируемость
- внимание
- после
- Что касается
- друзья
- от
- будущее
- дал
- получить
- получающий
- Отдаете
- будет
- хорошо
- есть
- регламентировать
- Группы
- Рост
- гарантия
- было
- обрабатывать
- Управляемость
- счастливый
- Есть
- he
- Медицина
- здравоохранение
- помог
- помощь
- помогает
- здесь
- High
- высокая производительность
- Выделенные
- очень
- его
- его
- час
- ЧАСЫ
- Как
- HTML
- HTTP
- HTTPS
- МАК
- ICE
- идентичный
- идентифицированный
- идентифицирующий
- иллюстрирует
- реализация
- в XNUMX году
- важную
- улучшенный
- улучшение
- in
- повышение
- с указанием
- незаменимый
- промышленность
- информация
- Инфраструктура
- инициировать
- обновлять
- Инновации
- размышления
- случаев
- вместо
- недостаточное
- страхование
- интеграции.
- целостность
- Интеллекта
- в нашей внутренней среде,
- в
- вопросы
- IT
- ЕГО
- присоединение
- путешествие
- JPG
- Кафка
- Основные
- Kubernetes
- Отсутствие
- пейзаж
- язык
- большой
- крупнейших
- слоев
- Лидеры
- Наша команда
- ведущий
- узнали
- изучение
- привело
- Наследие
- урок
- Уроки
- Уроки, извлеченные
- Библиотека
- ЖИЗНЬЮ
- Наука о жизни
- такое как
- журнал
- Длинное
- смотрел
- искать
- серия
- Продукция
- ДЕЛАЕТ
- Создание
- управлять
- управляемого
- управление
- управления
- руководство
- вручную
- массивный
- означает,
- основным медицинским
- медицинские приборы
- Участники
- сообщение
- Сообщения
- обмен сообщениями
- дотошный
- Метрика
- microservices
- мигрировать
- мигрировали
- мигрирующий
- миграция
- минимизация
- минут
- несоответствие
- модуль
- Модули
- деньги
- Мониторинг
- БОЛЕЕ
- самых
- двигаться
- переехал
- перемещение
- навигационный
- обязательно
- Необходимость
- потребности
- сеть
- Новые
- следующий
- следующее поколение
- узел
- узлы
- номер
- номера
- препятствиями
- of
- предлагающий
- оффлайн
- смещение
- смещения
- .
- Старый
- on
- только
- операционный
- оперативный
- Операционный отдел
- оптимальный
- оптимизация
- Оптимизировать
- оптимизированный
- оптимизирующий
- Опции
- or
- заказ
- организация
- организации
- Другое
- Другое
- наши
- внешний
- внешнюю
- за
- Преодолеть
- преодоление
- накладные расходы
- собственный
- страстный
- Патчи
- Заделка
- путь
- паттеранами
- ОПЛАТИТЬ
- для
- производительность
- выполнены
- Разрешения
- личного
- мародерство
- трубопровод
- основной
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Играть
- играл
- плюс
- пунктов
- должность
- возможное
- После
- мощностью
- привилегированный
- Предварительный
- Проблема
- процесс
- Производство
- быстро
- предложило
- защиту
- доказанный
- при условии
- Стоимость
- Читать
- реальные
- недвижимость
- восстановление равновесия
- Рецепты
- относиться
- надежность
- складская
- полагается
- полагаться
- остатки
- повторяемый
- копирование
- жилой
- упругий
- Полезные ресурсы
- ОТДЫХ
- результат
- розничный
- надежный
- Роли
- Run
- Бег
- SaaS
- то же
- Сохранить
- сохраняются
- Масштабируемость
- масштабируемые
- Шкала
- масштабирование
- Сценарии
- Наука
- скрипты
- бесшовные
- легко
- Раздел
- безопасный
- безопасность
- сегментами
- Самообслуживание
- старший
- послать
- сервер
- служит
- Услуги
- выступающей
- набор
- настройки
- установка
- формы
- Поделиться
- блестит
- Короткое
- продемонстрированы
- Showcasing
- сторона
- значительный
- существенно
- аналогичный
- простой
- упрощенный
- упростить
- Размер
- медленной
- помедленнее
- меньше
- сгладить
- Software
- Инженер-программист
- Решение
- Решения
- некоторые
- Источник
- Space
- специалист
- специализация
- скорость
- проводит
- Стабильность
- стабильный
- стек
- Персонал
- инсценировка
- автономные
- Начало
- стойкий
- Шаги
- стоял
- диск
- магазины
- простой
- Стратегический
- Стратегически
- стратегий
- Стратегия
- потоковый
- обтекаемый
- потоки
- структурированный
- существенный
- успех
- успешный
- Успешно
- такие
- поставка
- цепочками поставок
- поддержка
- поддержки
- Поддержка
- Убедитесь
- синхронизации.
- синхронизация
- система
- системы
- приняты
- говорили
- команда
- Члены команды
- команды
- Технический
- подростков
- Terraform
- территория
- воли
- тестов
- чем
- который
- Ассоциация
- Источник
- их
- Их
- тем самым
- следовательно
- Эти
- вещи
- этой
- три
- Через
- пропускная способность
- время
- сроки
- Название
- в
- приняли
- инструментом
- тема
- Темы
- перевод
- транзит
- переведенный
- лечения
- суд
- стараться
- пытается
- напишите
- не отмеченный на карте
- понимание
- непредвиденный
- созданного
- недрогнувший
- обновление
- модернизация
- обновления
- us
- использование
- используемый
- через
- подтверждено
- ценный
- Наши ценности
- различный
- многосторонность
- версия
- вертикалей
- очень
- VMware
- ходил
- стремятся
- законопроект
- наблюдение
- we
- Web
- веб-сервисы
- ЧТО Ж
- были
- который
- в то время как
- КТО
- зачем
- в
- Работа
- работает
- по всему миру
- беспокоиться
- письменный
- YAML
- лет
- являетесь
- зефирнет