Группы специалистов по обработке и обработке данных тратят значительную часть своего времени на этапе подготовки данных жизненного цикла машинного обучения (ML), выполняя этапы выбора, очистки и преобразования данных. Это необходимый и важный этап любого рабочего процесса машинного обучения для получения осмысленных выводов и прогнозов, поскольку плохие или некачественные данные значительно снижают актуальность полученных выводов.
Группы инженеров данных традиционно отвечают за получение, консолидацию и преобразование необработанных данных для дальнейшего использования. Специалистам по данным часто требуется дополнительная обработка данных для конкретных случаев использования машинного обучения, таких как естественный язык и временные ряды. Например, некоторые алгоритмы машинного обучения могут быть чувствительны к отсутствующим значениям, разреженным функциям или выбросам и требуют особого внимания. Даже в тех случаях, когда набор данных находится в хорошем состоянии, специалисты по данным могут захотеть преобразовать распределения признаков или создать новые признаки, чтобы максимизировать понимание, полученное из моделей. Для достижения этих целей специалисты по обработке и анализу данных должны полагаться на группы специалистов по обработке данных для внесения запрошенных изменений, что приводит к зависимости и задержке в процессе разработки модели. В качестве альтернативы группы специалистов по данным могут выбрать внутреннюю подготовку данных и разработку функций с использованием различных парадигм программирования. Однако это требует затрат времени и усилий на установку и настройку библиотек и фреймворков, что не идеально, поскольку это время лучше потратить на оптимизацию производительности модели.
Обработчик данных Amazon SageMaker упрощает подготовку данных и процесс проектирования функций, сокращая время, необходимое для агрегирования и подготовки данных для машинного обучения, с недель до минут, предоставляя специалистам по данным единый визуальный интерфейс для выбора, очистки и изучения своих наборов данных. Data Wrangler предлагает более 300 встроенных преобразований данных, которые помогают нормализовать, преобразовывать и комбинировать функции без написания кода. Вы можете импортировать данные из нескольких источников данных, таких как Amazon Simple Storage Service (Amazon S3), Амазонка Афина, Амазонка Redshiftи Снежинка. Теперь вы также можете использовать Databricks в качестве источника данных в Data Wrangler, чтобы легко подготовить данные для машинного обучения.
Платформа Databricks Lakehouse сочетает в себе лучшие элементы озер и хранилищ данных, обеспечивая надежность, строгое управление и производительность хранилищ данных с открытостью, гибкостью и поддержкой машинного обучения озер данных. Используя Databricks в качестве источника данных для Data Wrangler, теперь вы можете быстро и легко подключаться к Databricks, интерактивно запрашивать данные, хранящиеся в Databricks, с помощью SQL и предварительно просматривать данные перед импортом. Кроме того, вы можете объединить свои данные в Databricks с данными, хранящимися в Amazon S3, и данными, полученными через Amazon Athena, Amazon Redshift и Snowflake, чтобы создать набор данных, подходящий для вашего варианта использования машинного обучения.
В этом посте мы преобразовываем набор данных Lending Club Loan с помощью Amazon SageMaker Data Wrangler для использования в обучении модели машинного обучения.
Обзор решения
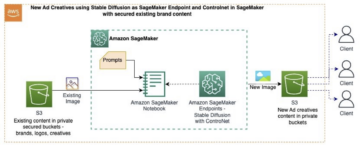
На следующей диаграмме показана архитектура нашего решения.
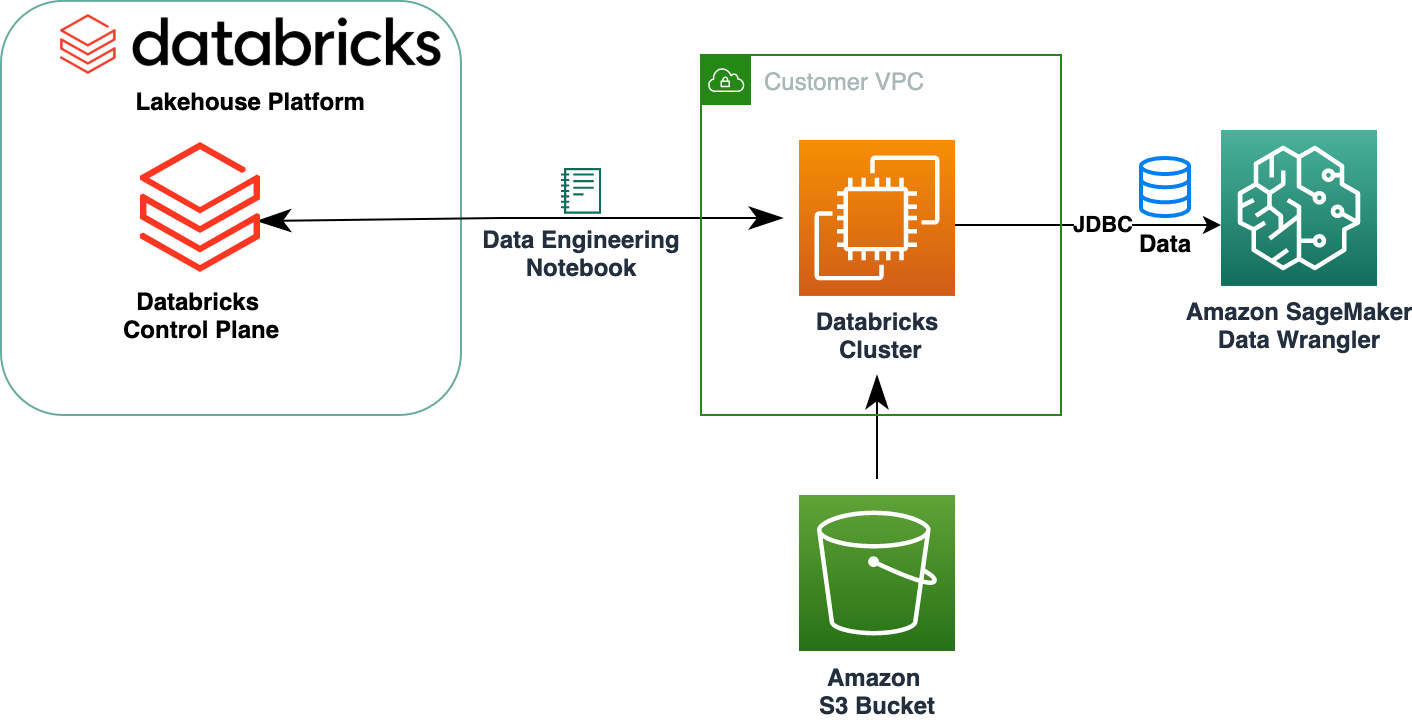
Набор данных Lending Club Loan содержит полные данные по всем кредитам, выданным в период с 2007 по 2011 год, включая текущий статус кредита и информацию о последних платежах. Он имеет 39,717 22 строк, 3 столбца функций и XNUMX целевые метки.
Чтобы преобразовать наши данные с помощью Data Wrangler, мы выполняем следующие высокоуровневые шаги:
- Загрузите и разделите набор данных.
- Создайте поток обработчика данных.
- Импортируйте данные из Databricks в Data Wrangler.
- Импорт данных из Amazon S3 в Data Wrangler.
- Присоединяйтесь к данным.
- Применение преобразований.
- Экспорт набора данных.
Предпосылки
В сообщении предполагается, что у вас есть работающий кластер Databricks. Если ваш кластер работает на AWS, убедитесь, что у вас настроено следующее:
Настройка блоков данных
- An профиль экземпляра с необходимыми разрешениями для доступа к корзине S3
- A политика ведра с необходимыми разрешениями для целевого сегмента S3
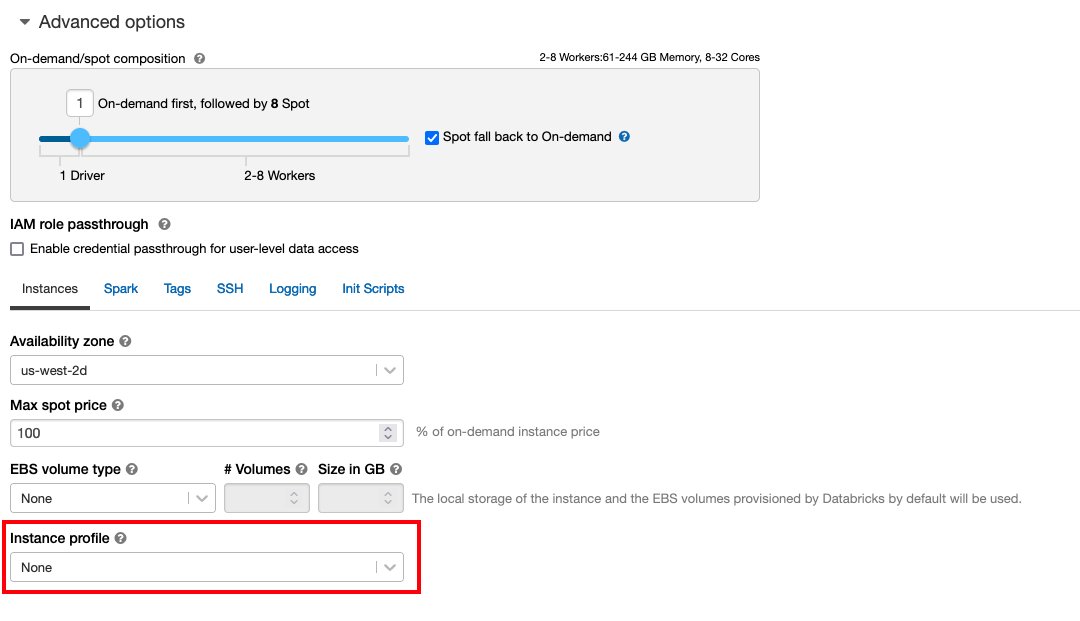
Подписаться Безопасный доступ к корзинам S3 с помощью профилей экземпляров для необходимого Управление идентификацией и доступом AWS (IAM), политику корзины S3 и конфигурацию кластера Databricks. Убедитесь, что кластер Databricks настроен правильно. Instance Profile, выбранный в дополнительных параметрах, для доступа к нужному сегменту S3.
После запуска и запуска кластера Databricks с необходимым доступом к Amazon S3 вы можете получить JDBC URL из вашего кластера Databricks, который будет использоваться Data Wrangler для подключения к нему.
Получить URL-адрес JDBC
Чтобы получить URL-адрес JDBC, выполните следующие шаги:
- В Databricks перейдите к пользовательскому интерфейсу кластеров.
- Выберите свой кластер.
- На Конфигурация , выберите Дополнительные параметры.
- Под Дополнительные параметры, выбрать JDBC/ODBC меню.
- Скопируйте URL-адрес JDBC.
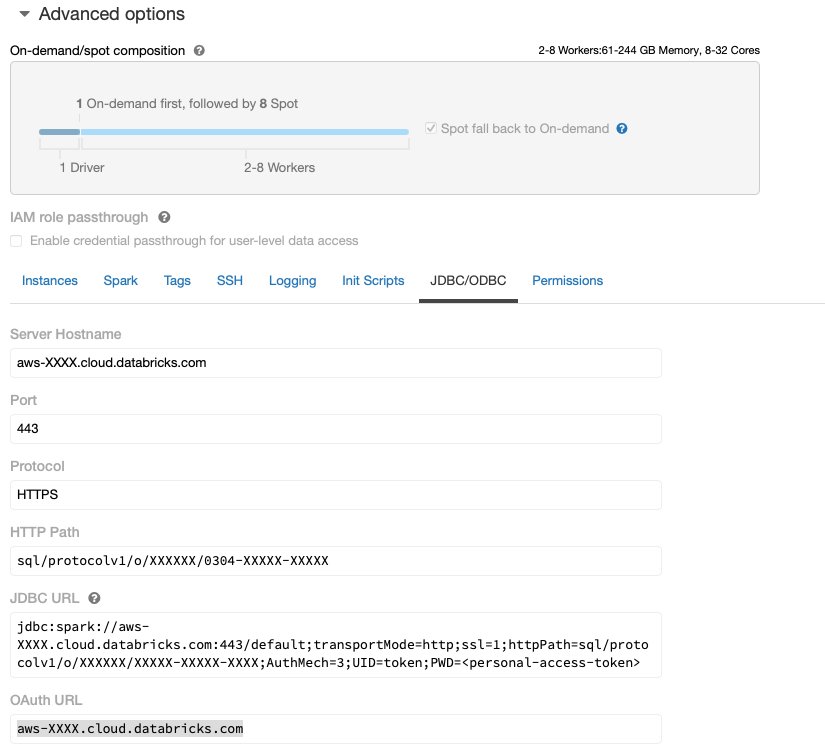
Обязательно замените свой личный доступ знак в URL.
Настройка обработчика данных
Этот шаг предполагает, что у вас есть доступ к Amazon SageMaker, экземпляру Студия Amazon SageMakerи пользователь Studio.
Чтобы разрешить доступ к соединению JDBC Databricks из Data Wrangler, пользователю Studio требуется следующее разрешение:
secretsmanager:PutResourcePolicy
Выполните следующие шаги, чтобы обновить роль выполнения IAM, назначенную пользователю Studio с вышеуказанным разрешением, в качестве пользователя-администратора IAM.
- На консоли IAM выберите роли в навигационной панели.
- Выберите роль, назначенную вашему пользователю Studio.
- Выберите Добавить разрешения.
- Выберите Создать встроенную политику.
- Для обслуживания выберите Секретный менеджер.
- On Действия, выберите Уровень доступа.
- Выберите Управление разрешениями.
- Выберите ПутьРесурсПолици.
- Что касается Полезные ресурсы, выберите Конкретный и Любой в этом аккаунте.

Загрузите и разделите набор данных
Вы можете начать с скачивание набора данных. В демонстрационных целях мы разделили набор данных, скопировав столбцы функций. id, emp_title, emp_length, home_ownerи annual_inc создать второй кредиты_2.csv файл. Мы удаляем вышеупомянутые столбцы из исходного файла займов, кроме id столбец и переименуйте исходный файл в кредиты_1.csv. Загрузить кредиты_1.csv файл в Databricks создать таблицу loans_1 и кредиты_2.csv в ведре S3.
Создание потока обработчика данных
Сведения о предварительных требованиях Data Wrangler см. Начать работу с Data Wrangler.
Начнем с создания нового потока данных.
- На консоли Studio на Файл Меню, выберите Новые.
- Выберите Поток обработки данных.
- Переименуйте поток по желанию.
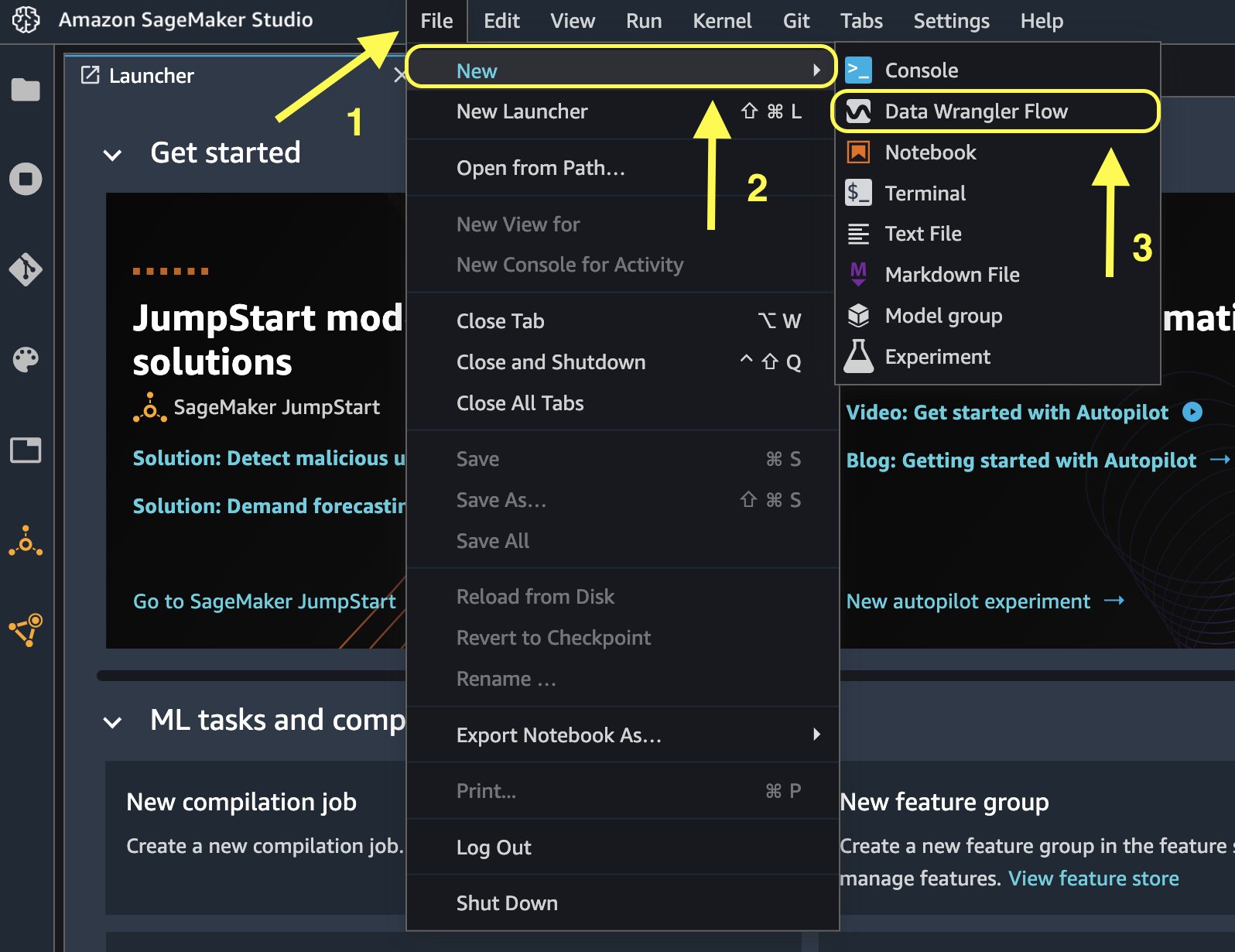
Кроме того, вы можете создать новый поток данных из Launcher.
- На консоли Studio выберите Студия Amazon SageMaker в навигационной панели.
- Выберите Новый поток данных.

Создание нового потока может занять несколько минут. После создания потока вы увидите Даты импорта стр.
Импорт данных из Databricks в Data Wrangler
Затем мы настраиваем Databricks (JDBC) в качестве источника данных в Data Wrangler. Чтобы импортировать данные из Databricks, нам сначала нужно добавить Databricks в качестве источника данных.
- На Даты импорта вкладку вашего потока Data Wrangler, выберите Добавить источник данных.
- В раскрывающемся меню выберите Блоки данных (JDBC).
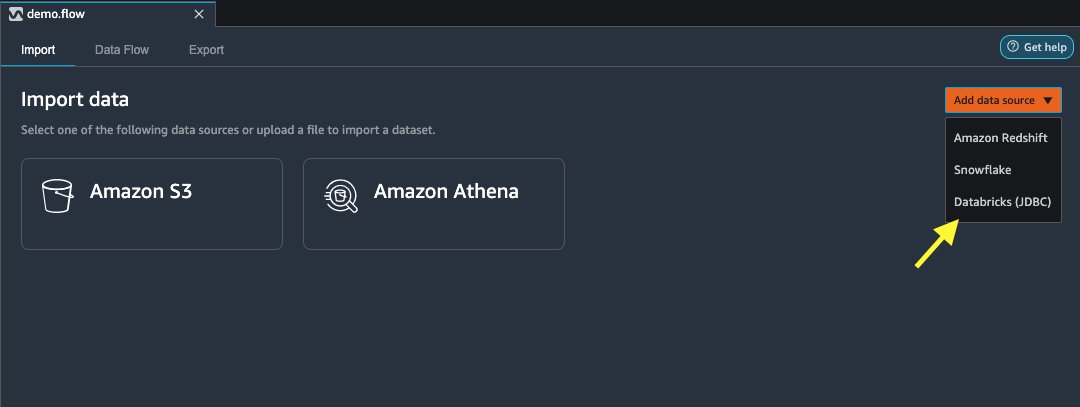
На Импорт данных из Databricks на странице вы вводите данные своего кластера.
- Что касается Имя набора данных, введите имя, которое вы хотите использовать в файле потока.
- Что касается Драйвер, выберите драйвер
com.simba.spark.jdbc.Driver. - Что касается URL-адрес JDBC, введите URL-адрес своего кластера Databricks, полученный ранее.
URL-адрес должен иметь следующий формат jdbc:spark://<serve- hostname>:443/default;transportMode=http;ssl=1;httpPath=<http- path>;AuthMech=3;UID=token;PWD=<personal-access-token>.
- В редакторе запросов SQL укажите следующую инструкцию SQL SELECT:
Если вы выбрали другое имя таблицы при загрузке данных в Databricks, замените кредиты_1 в приведенном выше SQL-запросе соответствующим образом.
В Запрос SQL раздел в Data Wrangler, вы можете запросить любую таблицу, подключенную к базе данных JDBC Databricks. Предварительно выбранный Включить выборку Параметр по умолчанию извлекает первые 50,000 XNUMX строк вашего набора данных. В зависимости от размера набора данных отмена выбора Включить выборку может привести к увеличению времени импорта.
- Выберите Run.
Выполнение запроса обеспечивает предварительный просмотр набора данных Databricks непосредственно в Data Wrangler.

- Выберите Импортировать.

Data Wrangler обеспечивает гибкость настройки нескольких одновременных подключений к одному кластеру Databricks или к нескольким кластерам, если это необходимо, что позволяет проводить анализ и подготовку объединенных наборов данных.
Импортируйте данные из Amazon S3 в Data Wrangler.
Далее импортируем loan_2.csv файл с Amazon S3.
- На вкладке Импорт выберите Amazon S3 в качестве источника данных.

- Перейдите к корзине S3 для
loan_2.csv.
Когда вы выбираете файл CSV, вы можете просмотреть данные.
- В Подробнее панель, выберите Расширенная конфигурация Чтобы убедиться Включить выборку выбран и ЗАПЯТАЯ выбран для Разделитель.
- Выберите Импортировать.

После loans_2.csv набор данных успешно импортирован, в интерфейсе потока данных отображаются источники данных Databricks JDBC и Amazon S3.

Присоединяйтесь к данным
Теперь, когда мы импортировали данные из Databricks и Amazon S3, давайте объединим наборы данных, используя общий столбец уникальных идентификаторов.
- На Поток данных вкладка, для Типы данных, выберите знак плюс для
loans_1. - Выберите Присоединиться.
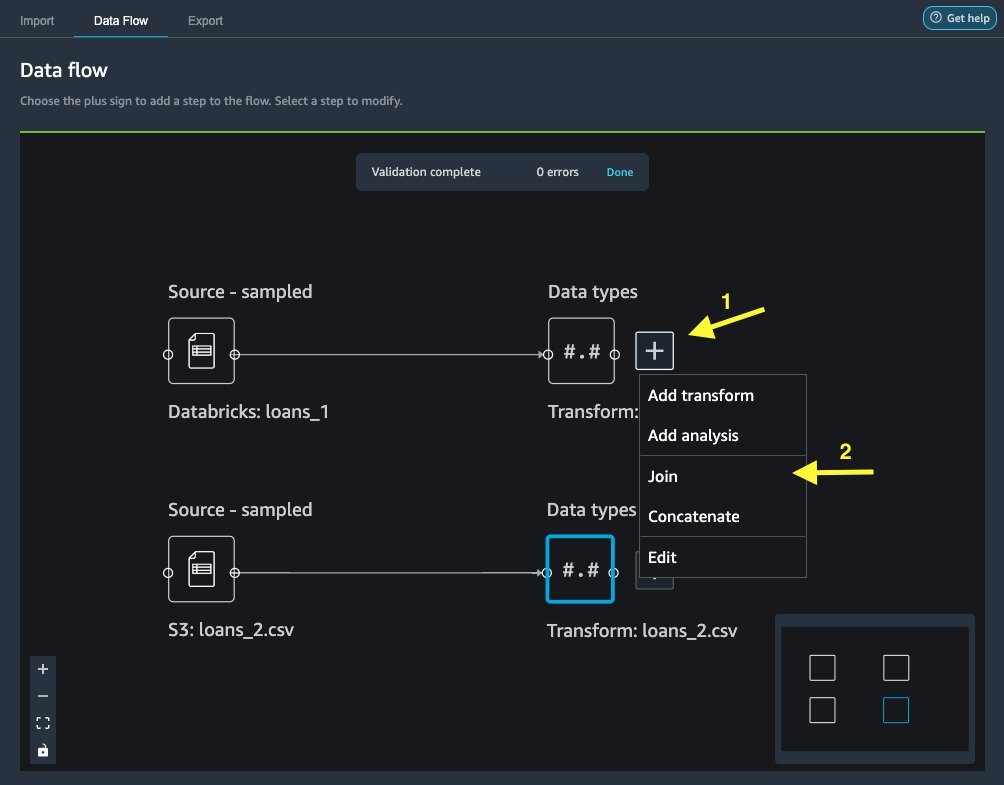
- Выберите
loans_2.csvфайл как Правильно набор данных. - Выберите Настроить чтобы настроить критерии соединения.
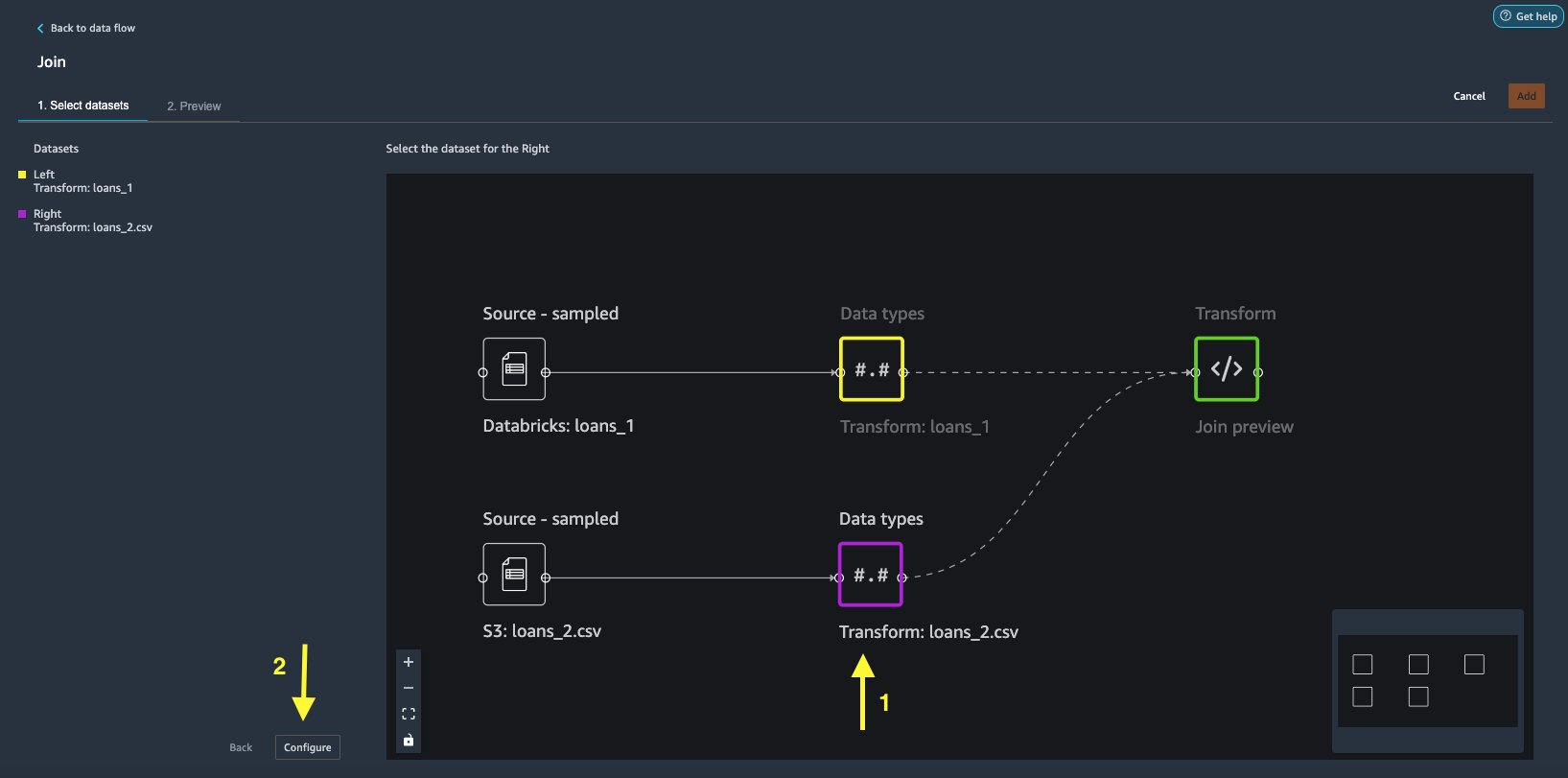
- Что касается Имя, введите имя для объединения.
- Что касается Тип соединения, выберите Внутренний для этого поста.
- Выберите
idколонка, к которой нужно присоединиться. - Выберите Применить для предварительного просмотра объединенного набора данных.
- Выберите Добавить чтобы добавить его в поток данных.

Применить преобразования
Data Wrangler поставляется с более чем 300 встроенными преобразованиями, которые не требуют программирования. Давайте воспользуемся встроенными преобразованиями для подготовки набора данных.
Удалить столбец
Сначала мы удаляем избыточный столбец ID.
- На соединенном узле выберите знак плюс.
- Выберите Добавить преобразование.

- Под Превращает, укажите + Добавить шаг.
- Выберите Управление столбцами.
- Что касается Transform, выберите Удалить столбец.
- Что касается Столбцы для удаления, выберите столбец
id_0. - Выберите предварительный просмотр.
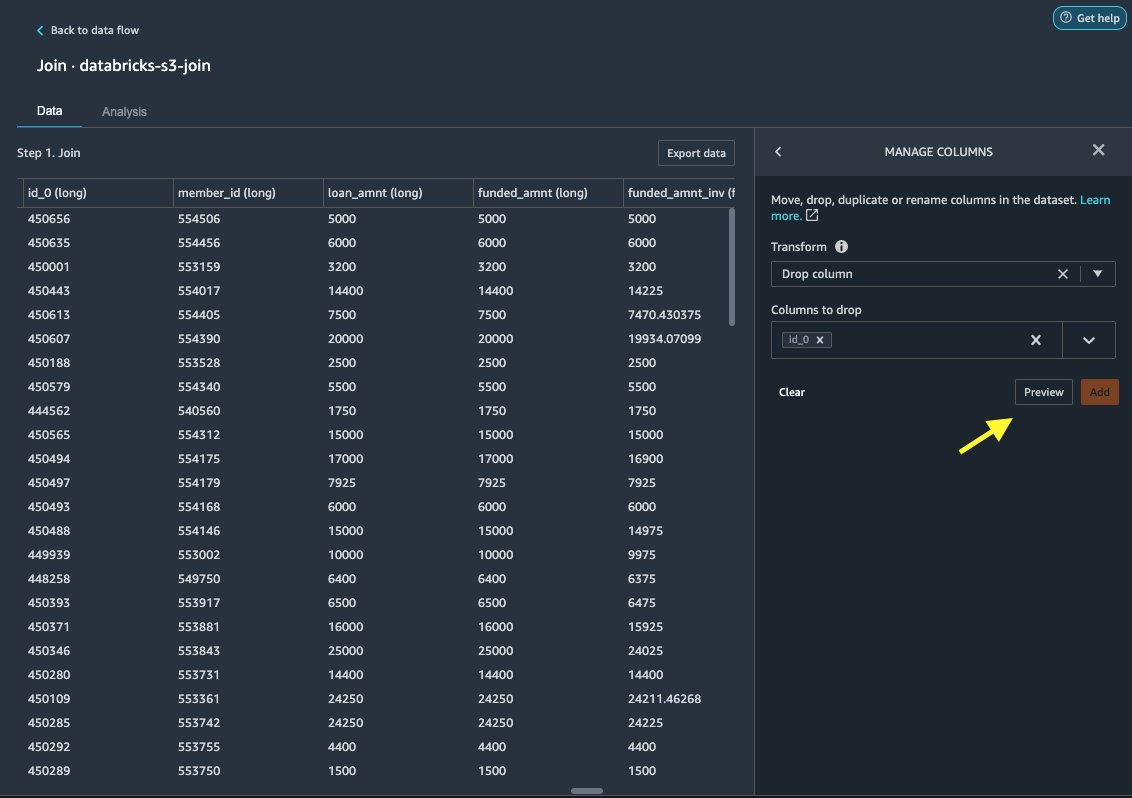
- Выберите Добавить.
Строка формата
Давайте применим форматирование строки, чтобы удалить символ процента из int_rate и revol_util колонны.
- На Данные вкладка под Трансформации, выберите + Добавить шаг.

- Выберите Строка формата.
- Что касается Transform, выберите Удалить символы справа.
Data Wrangler позволяет применять выбранное преобразование одновременно к нескольким столбцам.
- Что касается Входные столбцы, выберите
int_rateиrevol_util. - Что касается Персонажи для удаления, войти
%. - Выберите предварительный просмотр.

- Выберите Добавить.
Добавить текст
Давайте теперь векторизовать verification_status, столбец текстовых функций. Мы преобразуем текстовый столбец в вектор термина «частота — обратная частота документа» (TF-IDF), применяя векторизатор счета и стандартный токенизатор, как описано ниже. Data Wrangler также предоставляет возможность использовать собственный токенизатор, если это необходимо.
- Под Трансформаторы, выберите + Добавить шаг.
- Выберите Добавить текст.
- Что касается Transform, выберите Векторизовать.
- Что касается Входные столбцы, выберите
verification_status. - Выберите предварительный просмотр.

- Выберите Добавить.
Экспорт набора данных
После применения нескольких преобразований к разным типам столбцов, включая текстовые, категориальные и числовые, мы готовы использовать преобразованный набор данных для обучения модели машинного обучения. Последний шаг — экспорт преобразованного набора данных в Amazon S3. В Data Wrangler у вас есть несколько вариантов для последующего использования преобразований:
- Выберите Шаг экспорта для автоматического создания блокнота Jupyter с кодом обработки SageMaker для обработки и экспорта преобразованного набора данных в корзину S3. Для получения дополнительной информации см. Запускайте задания обработки несколькими щелчками мыши с помощью Amazon SageMaker Data Wrangler..
- Экспортируйте записную книжку Studio, которая создает Конвейер SageMaker с вашим потоком данных или записной книжкой, которая создает Магазин функций Amazon SageMaker группу функций и добавляет функции в автономный или онлайн-магазин функций.
- Выберите Экспорт данных экспортировать напрямую в Amazon S3.
В этом посте мы воспользуемся Экспорт данных вариант в Transform view, чтобы экспортировать преобразованный набор данных непосредственно в Amazon S3.
- Выберите Экспорт данных.

- Что касается S3 местоположение, выберите ЛИСТАТЬ СПИСКИ и выберите корзину S3.
- Выберите Экспорт данных.
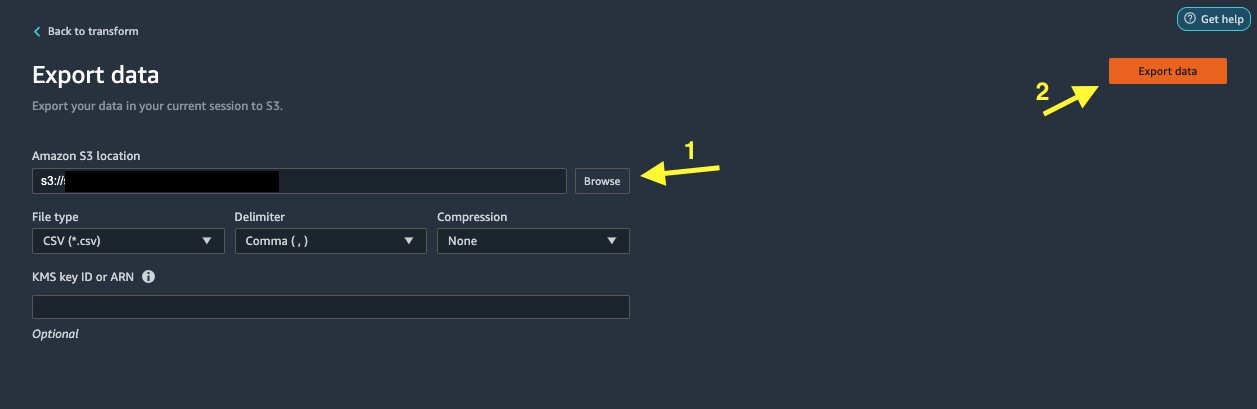
Убирать
Если ваша работа с Data Wrangler завершена, выключите свой экземпляр Data Wrangler чтобы избежать дополнительных сборов.
Заключение
В этом посте мы рассмотрели, как можно быстро и легко настроить и подключить блоки данных в качестве источника данных в Data Wrangler, интерактивно запрашивать данные, хранящиеся в блоках данных, с помощью SQL и предварительно просматривать данные перед импортом. Кроме того, мы рассмотрели, как можно объединить данные в Databricks с данными, хранящимися в Amazon S3. Затем мы применили преобразование данных к комбинированному набору данных, чтобы создать конвейер подготовки данных. Чтобы узнать больше о возможностях анализа Data Wrangler, в том числе о целевых утечках и генерации отчетов о предвзятости, см. следующую запись в блоге. Ускорьте подготовку данных с помощью Amazon SageMaker Data Wrangler для прогнозирования повторной госпитализации пациентов с диабетом.
Чтобы начать работу с Data Wrangler, см. Подготовка данных машинного обучения с помощью Amazon SageMaker Data Wranglerи просмотрите последнюю информацию о Data Wrangler странице продукта.
Об авторах
 Руп Бейнс работает архитектором решений в AWS, специализируясь на AI/ML. Он увлечен тем, что помогает клиентам внедрять инновации и достигать своих бизнес-целей с помощью искусственного интеллекта и машинного обучения. В свободное время Руп любит читать и ходить в походы.
Руп Бейнс работает архитектором решений в AWS, специализируясь на AI/ML. Он увлечен тем, что помогает клиентам внедрять инновации и достигать своих бизнес-целей с помощью искусственного интеллекта и машинного обучения. В свободное время Руп любит читать и ходить в походы.
 Игорь Алексеев — архитектор партнерских решений в AWS в области данных и аналитики. Игорь работает со стратегическими партнерами, помогая им создавать сложные архитектуры, оптимизированные для AWS. До прихода в AWS в качестве архитектора данных/решений он реализовал множество проектов в области больших данных, в том числе несколько озер данных в экосистеме Hadoop. В качестве инженера по обработке данных он занимался применением ИИ/МО для обнаружения мошенничества и автоматизации делопроизводства. Проекты Игоря были в различных отраслях, включая связь, финансы, общественную безопасность, производство и здравоохранение. Ранее Игорь работал full stack инженером/техлидом.
Игорь Алексеев — архитектор партнерских решений в AWS в области данных и аналитики. Игорь работает со стратегическими партнерами, помогая им создавать сложные архитектуры, оптимизированные для AWS. До прихода в AWS в качестве архитектора данных/решений он реализовал множество проектов в области больших данных, в том числе несколько озер данных в экосистеме Hadoop. В качестве инженера по обработке данных он занимался применением ИИ/МО для обнаружения мошенничества и автоматизации делопроизводства. Проекты Игоря были в различных отраслях, включая связь, финансы, общественную безопасность, производство и здравоохранение. Ранее Игорь работал full stack инженером/техлидом.
 Хуонг Нгуен является старшим менеджером по продукту в AWS. Она руководит пользовательским интерфейсом SageMaker Studio. Она имеет 13-летний опыт создания ориентированных на клиентов и данных продуктов как для корпоративных, так и для потребительских сфер. В свободное время она любит читать, находиться на природе и проводить время с семьей.
Хуонг Нгуен является старшим менеджером по продукту в AWS. Она руководит пользовательским интерфейсом SageMaker Studio. Она имеет 13-летний опыт создания ориентированных на клиентов и данных продуктов как для корпоративных, так и для потребительских сфер. В свободное время она любит читать, находиться на природе и проводить время с семьей.
 Генри Ванг является инженером-разработчиком программного обеспечения в AWS. Недавно он присоединился к команде Data Wrangler после окончания Калифорнийского университета в Дэвисе. Он интересуется наукой о данных и машинным обучением и занимается 3D-печатью в качестве хобби.
Генри Ванг является инженером-разработчиком программного обеспечения в AWS. Недавно он присоединился к команде Data Wrangler после окончания Калифорнийского университета в Дэвисе. Он интересуется наукой о данных и машинным обучением и занимается 3D-печатью в качестве хобби.
- Коинсмарт. Лучшая в Европе биржа биткойнов и криптовалют.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. БЕСПЛАТНЫЙ ДОСТУП.
- КриптоХок. Альткоин Радар. Бесплатная пробная версия.
- Источник: https://aws.amazon.com/blogs/machine-learning/prepare-data-from-databricks-for-machine-learning-using-amazon-sagemaker-data-wrangler/
- "
- 000
- 100
- 39
- 3d
- О нас
- доступ
- вмещать
- дополнительный
- продвинутый
- плюс
- алгоритмы
- Все
- Amazon
- анализ
- аналитика
- Применение
- архитектура
- искусственный
- искусственный интеллект
- Искусственный интеллект и машинное обучение
- назначенный
- автоматизация
- AWS
- не являетесь
- ЛУЧШЕЕ
- Big Data
- Блог
- граница
- строить
- встроенный
- бизнес
- возможности
- случаев
- Выберите
- Уборка
- клуб
- код
- Кодирование
- Column
- сочетании
- Общий
- Связь
- комплекс
- Конфигурация
- подключенный
- связи
- Коммутация
- рассмотрение
- Консоли
- консолидация
- потребитель
- потребление
- содержит
- создали
- создает
- Создающий
- Текущий
- Клиенты
- данным
- наука о данных
- База данных
- задерживать
- в зависимости
- обнаружение
- Развитие
- различный
- непосредственно
- дисплеев
- вниз
- водитель
- Падение
- легко
- экосистема
- редактор
- включить
- позволяет
- инженер
- Проект и
- Enter
- Предприятие
- пример
- Кроме
- выполнение
- опыт
- Больше
- семья
- Особенность
- Особенности
- Сборы
- финансы
- Во-первых,
- Трансформируемость
- поток
- после
- формат
- мошенничество
- полный
- порождать
- поколение
- хорошо
- управление
- группы
- здравоохранение
- помощь
- Как
- HTTPS
- Личность
- в XNUMX году
- важную
- импортирующий
- В том числе
- промышленности
- информация
- размышления
- Интеллекта
- интерес
- Интерфейс
- инвестиций
- вовлеченный
- IT
- Джобс
- присоединиться
- присоединился
- Этикетки
- язык
- последний
- вести
- ведущий
- изучение
- кредитование
- Кредиты
- смотрел
- машина
- обучение с помощью машины
- менеджер
- производство
- ML
- модель
- Модели
- БОЛЕЕ
- с разными
- натуральный
- природа
- Навигация
- Новые функции
- ноутбук
- Предложения
- оффлайн
- онлайн
- Опция
- Опции
- заказ
- собственный
- партнер
- партнеры
- страстный
- оплата
- процент
- производительность
- личного
- фаза
- Платформа
- политика
- Predictions
- предварительный просмотр
- процесс
- Продукт
- Продукция
- Программирование
- проектов
- приводит
- обеспечение
- что такое варган?
- целей
- быстро
- Сырье
- Reading
- снижение
- отчету
- требовать
- обязательный
- ответственный
- Бег
- Сохранность
- Наука
- Ученые
- выбранный
- Серии
- обслуживание
- набор
- установка
- значительный
- просто
- Размер
- Software
- разработка программного обеспечения
- Решение
- Решения
- пространства
- тратить
- Расходы
- раскол
- стек
- стандарт
- Начало
- и политические лидеры
- заявление
- Статус:
- диск
- магазин
- Стратегический
- сильный
- студия
- Успешно
- поддержка
- цель
- команда
- Через
- время
- Обучение
- Transform
- трансформация
- ui
- созданного
- Обновление ПО
- использование
- разнообразие
- различный
- в то время как
- без
- Работа
- работавший
- работает
- письмо