Введение
Мг Операции) интегрирует рабочие процессы машинного обучения (ML) с процессами разработки и эксплуатации программного обеспечения. Он включает в себя использование инструментов и методологий для автоматизации и оптимизации создания, тестирования, развертывания и мониторинга моделей машинного обучения в производственной среде. Объединяя опыт специалистов по данным, инженеров и специалистов по эксплуатации, MLOps позволяет организациям быстро и эффективно разрабатывать, развертывать и поддерживать модели машинного обучения в масштабе, а также обеспечивать их качество и производительность. MLOps направлен на повышение скорости, эффективности и качества разработки и развертывания моделей машинного обучения, а также на достижение бизнес-результатов.
Цели обучения
- Знакомство с MLOps и его отличиями от DevOps, AIOps и ModelOps.
- Как создать инфраструктуру и конвейеры CI/CD — две наиболее важные концепции в MLOps.
- Различные подходы к моделированию и оценке разработки в MLOps
- Проблемы, с которыми можно столкнуться при развертывании модели в конвейере
- Понимание MLOps sp того, что концепции, полученные из этого, могут быть использованы для ответов на аналогичные вопросы во время Добавлено. интервью
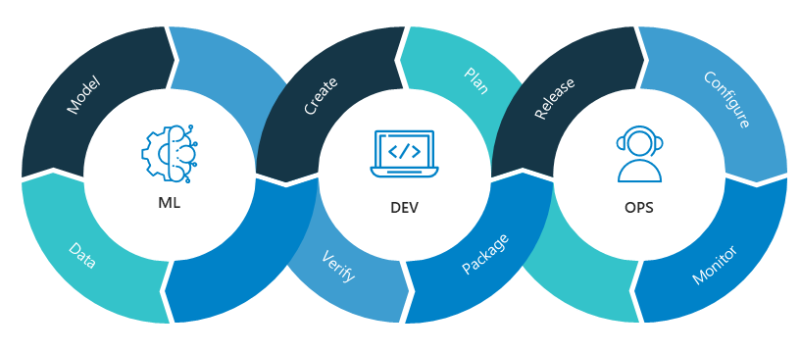
Эта статья была опубликована в рамках Блогатон по Data Science.
Содержание
- Почему вы должны изучать MLOps?
- Вопрос на собеседовании
2.1 В чем разница между MLOps, ModelOps и AIOps?
2.2. В чем разница между MLOps и DevOps?
2.3. Как вы создаете инфраструктуру в MLOps?
2.4. Как создать конвейеры CI/CD для машинного обучения?
2.5. Что такое дрейф модели или концепции?
2.6. Чем мониторинг отличается от логирования?
2.7. Какое тестирование следует провести перед развертыванием модели машинного обучения в рабочей среде?
2.8. Что такое подход разделения A/B к оценке модели?
2.9. В чем важность использования контроля версий для MLOps?
2.10. В чем разница между развертыванием модели A/B-тестирования и Multi-Arm Bandit?
2.11. В чем разница между канареечной и сине-зеленой стратегиями развертывания?
2.12. Почему вы должны отслеживать атрибуцию функций, а не их распространение?
2.13. Каковы способы упаковки моделей ML?
2.14. Что такое концепция «неизменяемой инфраструктуры»?
2.15. Укажите некоторые распространенные проблемы, связанные с развертыванием модели машинного обучения. - Заключение
- Повышенная эффективность: MLOps позволяет автоматизировать и оптимизировать разработку и развертывание модели машинного обучения, что может значительно увеличить скорость и эффективность процесса.
- Улучшенное качество: MLOps предоставляет платформу для тестирования, мониторинга и поддержки моделей машинного обучения в производственной среде, что помогает обеспечить их качество и производительность.
- Масштабируемость: MLOps позволяет организациям развертывать и поддерживать модели машинного обучения в масштабе, что становится все более важным, поскольку использование машинного обучения продолжает расти.
- Лучшее сотрудничество: MLOps объединяет специалистов по данным, инженеров и специалистов по эксплуатации для совместной работы и работы над достижением общей цели, улучшая общий процесс разработки машинного обучения.
- Лучшие результаты для бизнеса: Благодаря более эффективным, масштабируемым и высококачественным моделям машинного обучения организации могут добиться лучших результатов в бизнесе и получить конкурентное преимущество.
- Больше возможностей для работы: С ростом использования машинного обучения в промышленности и организациях растет спрос на специалистов с навыками MLOps.
Изучение MLOps может помочь улучшить разработку и развертывание моделей машинного обучения, что в конечном итоге приведет к улучшению бизнес-результатов и предоставит больше возможностей для трудоустройства.
Таким образом, вы, должно быть, поняли, что MLOps постепенно занимает центральное место в области AI / ML, и в ближайшие годы это будет один из обязательных навыков для каждого инженера данных и ML. Так что в следующий раз, когда вы будете претендовать на свою первую или новую работу, вы можете быть уверены, что знание лакомых кусочков MLOps послужит вам преимуществом.
Здесь вы найдете некоторые из основных понятий, которые часто задают на собеседованиях. Для подготовки к интервью вы можете просмотреть их напрямую, не углубляясь в изображения.
Интервью Вопросы
Q1. В чем разница между MLOps, ModelOps и AIOps?
MLOps, ModelOps и AIOps связаны с интеграцией машинного обучения (ML) с процессами разработки программного обеспечения и эксплуатации, но они имеют несколько разные области применения.
- млн операций в секунду (Machine Learning Operations) объединяет рабочие процессы машинного обучения с процессами разработки и эксплуатации программного обеспечения. Он включает в себя использование инструментов и методологий для автоматизации и оптимизации создания, тестирования, развертывания и мониторинга моделей машинного обучения в производственной среде.
- Модельные операции (Model Operations) — это подмножество MLOps, которое фокусируется на операционализации и управлении моделями ML в производстве. Он включает в себя управление версиями моделей, мониторинг, обновление и управление жизненным циклом моделей.
- AIOps (Операции искусственного интеллекта) — это более широкая концепция, охватывающая MLOps и ModelOps и использующая ИИ и машинное обучение в ИТ-операциях и управлении ИТ-услугами. Он включает в себя использование искусственного интеллекта и машинного обучения для анализа и осмысления больших объемов данных из ИТ-систем и автоматизации таких задач, как обнаружение и устранение инцидентов.
Q2. В чем разница между MLOps и DevOps?
MLOps (операции машинного обучения) и DevOps (операции разработки) — это практики, направленные на интеграцию процессов разработки и эксплуатации программного обеспечения, но они имеют разные области применения.
- DevOps представляет собой набор методов, направленных на автоматизацию и оптимизацию разработки и развертывания программного обеспечения. Он включает в себя сотрудничество между командами разработки и эксплуатации для повышения скорости, эффективности и качества разработки и развертывания программного обеспечения.
- млн операций в секунду, с другой стороны, ориентирован на интеграцию рабочих процессов машинного обучения (ML) с процессами разработки и эксплуатации программного обеспечения. Он включает в себя использование инструментов и методологий для автоматизации и оптимизации создания, тестирования, развертывания и мониторинга моделей машинного обучения в производственной среде.
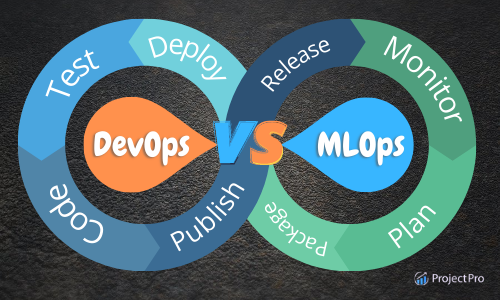
Источник: Projectpro.io
Q3. Как вы создаете инфраструктуру в MLOps?
Создание инфраструктуры для MLOps включает в себя несколько шагов:
- Определите требования: определите конкретные требования к вашей инфраструктуре машинного обучения, такие как требования к хранилищу, вычислениям и сети. Это поможет вам определить подходящие инфраструктурные решения и технологии.
- Выберите подходящего облачного провайдера: выберите тот, который лучше всего соответствует вашим требованиям. Популярные варианты включают Amazon Web Services (AWS), Microsoft Azure и Google Cloud Platform (GCP).
- Создайте конвейер данных: Создайте конвейер данных для автоматизации процесса сбора, очистки и подготовки данных. Это гарантирует, что ваши данные готовы к обучению и развертыванию модели.
- Настроить систему контроля версий: настройте систему контроля версий, например Git, чтобы отслеживать изменения в вашем коде и моделях. Это поможет вам вернуться к предыдущим версиям, если это необходимо.
- Создайте модельную среду обучения: настройте среду обучения моделей с помощью таких инструментов, как Jupyter Notebook или Google Colab. Это позволит вам обучать, тестировать и развертывать модели в согласованной среде.
- Автоматизируйте развертывание модели: автоматизируйте процесс развертывания модели с помощью таких инструментов, как Kubernetes или Docker. Это поможет вам быстро развертывать модели в различных средах и масштабировать их по мере необходимости.
- Контролировать и поддерживать инфраструктуру: регулярно контролировать и поддерживать инфраструктуру, чтобы обеспечить ее бесперебойную и быструю работу для решения любых возникающих проблем.
Q4. Как создать конвейеры CI/CD для машинного обучения?
CI — это аббревиатура от Continuous Integration, а CD — от Continuous Development. Это помогает автоматизировать процесс разработки программного обеспечения. конвейер CI/CD Основная функция гарантирует, что инженеры машинного обучения и разработчики программного обеспечения смогут создавать и развертывать безошибочный код как можно быстрее.
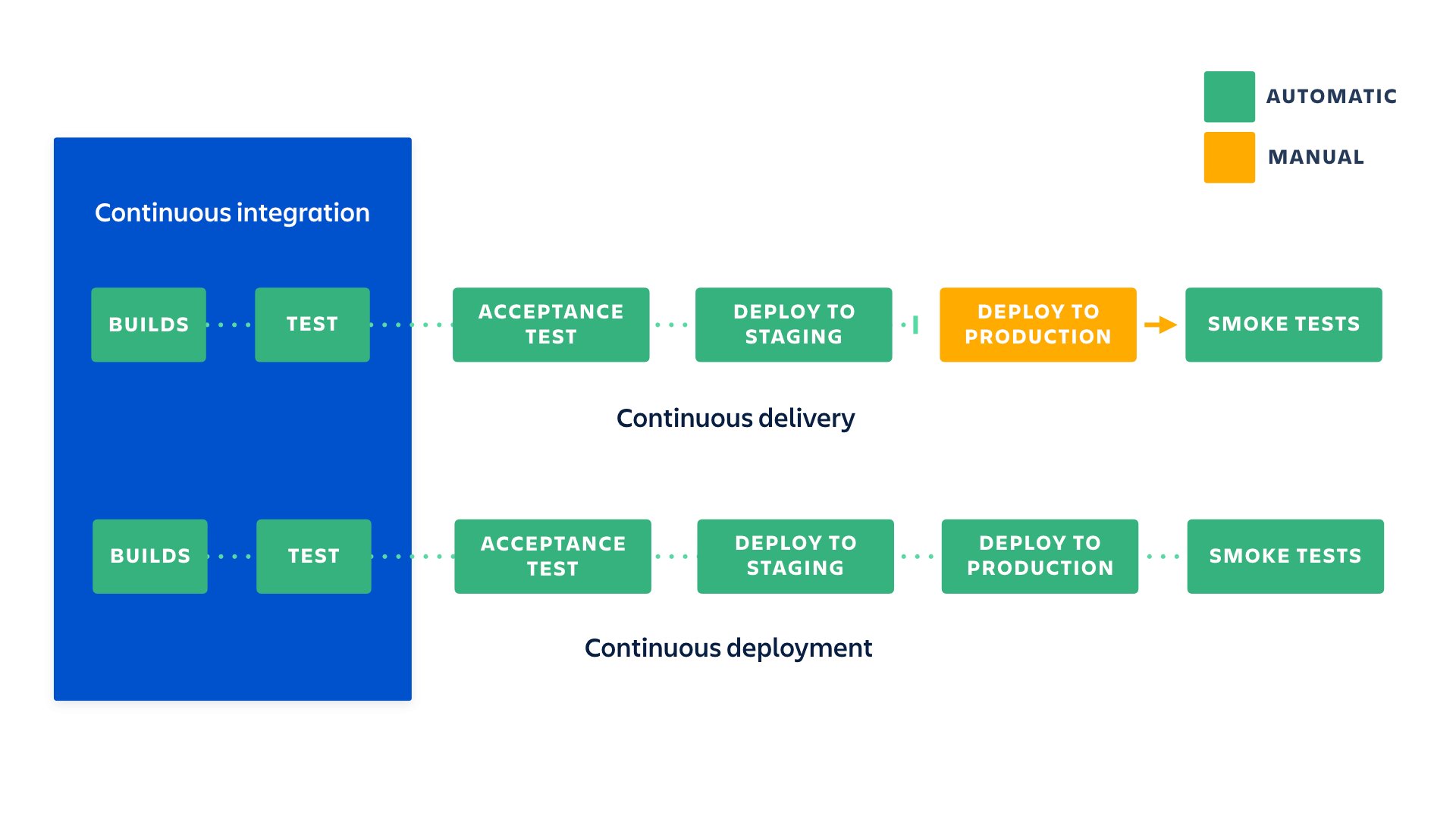
Создание конвейеров CI/CD (непрерывная интеграция/непрерывное развертывание) для машинного обучения (ML) включает несколько шагов:
- Настройте систему контроля версий: настройте систему контроля версий, например Git, чтобы отслеживать изменения в вашем коде и моделях. Это поможет вам вернуться к предыдущим версиям, если это необходимо.
- Автоматизируйте процесс обучения модели: автоматизируйте мод, такой как Jenkins или Travis CI. Это позволит вам регулярно обучать модели и обеспечивать их актуальность с учетом последних данных.
- Создайте среду тестирования: настройте среду тестирования с помощью таких инструментов, как py-тест или модульный тест, чтобы проверить производительность моделей после обучения. Это поможет убедиться, что модели работают должным образом.
- Автоматизируйте развертывание модели: автоматизируйте процесс развертывания модели с помощью таких инструментов, как Kubernetes или Docker. Это поможет вам быстро развертывать модели в различных средах и масштабировать их по мере необходимости.
- Настройте мониторинг и ведение журнала: настройте мониторинг и ведение журнала, чтобы отслеживать производительность моделей в рабочей среде. Это поможет вам быстро выявить и устранить любые возникающие проблемы.
- Создайте стратегию отката: создайте стратегию отката в случае проблем с недавно развернутой моделью или вернитесь к предыдущей версии.
- Протестируйте сквозной конвейер. Протестируйте сквозной конвейер, выполнив полный цикл интеграции, тестирования и развертывания, чтобы убедиться, что все работает должным образом.
Следуя этим шагам, вы можете создать надежный конвейер CI/CD для машинного обучения, который будет последовательно и эффективно обучать, тестировать и развертывать модели и поможет вам быстро реагировать на любые возникающие проблемы.
Q5. Что такое дрейф модели или концепции?
Дрейф концепции или модели — это изменение основного распределения вероятностей входных данных, которое может привести к тому, что обученная модель со временем станет менее точной. В основном это происходит, когда производительность модели на этапе вывода ухудшается по сравнению с ее версией на этапе обучения. Это также называется перекосом обучения/обслуживания, поскольку производительность модели искажается по сравнению с этапами обучения или обслуживания.

Причин тому может быть много:
- Базовое распределение данных изменилось
- Могут возникнуть непредвиденные сценарии. Модели, обученные на данных до пандемии COVID-19, вероятно, будут работать еще хуже с данными во время пандемии COVID-19.
- Обучение проводилось в ограниченных категориях, но недавно произошло изменение среды, добавление еще одного класса.
- Данные содержат гораздо больше токенов для задач НЛП, чем обучающие данные.
Непрерывный мониторинг производительности модели всегда необходим для обнаружения дрейфа модели. Если производительность модели постоянно низкая, необходимо выяснить причину и применить соответствующее лечение. Это почти всегда требует переобучения модели.
Q6. Чем мониторинг отличается от логирования?
Мониторинг относится к наблюдению за производительностью системы для выявления проблем и тенденций. Напротив, ведение журнала, с другой стороны, относится к регистрации информации о системе в файле журнала. Таким образом, мониторинг имеет преимущество перед регистрацией в том, что он может выявлять проблемы, которые могут быть неочевидны в файле журнала. Кроме того, анализ тенденции помогает предсказать будущие проблемы.
Q7. Какое тестирование следует провести перед развертыванием модели машинного обучения в рабочей среде?
Перед развертыванием модели машинного обучения в рабочей среде необходимо выполнить различные типы тестирования.
- Единичное тестирование: Чтобы убедиться, что отдельные компоненты модели, такие как код предварительной обработки данных и извлечения признаков, работают должным образом.
- Интеграционное тестирование: Это проверяет, как различные компоненты модели работают вместе.
- Тестирование производительности: Это проверяет, как модель работает в различных условиях, используя такие метрики, как точность, достоверность, полнота и F1-оценка на протянутом тестовом наборе данных.
- Тестирование A / B: Сравните производительность модели с базовой моделью или предыдущей версией модели.
- Нагрузочное тестирование: Оцените производительность модели в экстремальных условиях, таких как обработка больших объемов данных или работа с пограничными случаями.
- Приемочное тестирование пользователей: Получите обратную связь от реальных пользователей, чтобы убедиться, что модель соответствует их потребностям и дает точные результаты.
- Проверка безопасности и конфиденциальности: Оцените функции безопасности и конфиденциальности модели, такие как шифрование данных, аутентификация и контроль доступа, чтобы обеспечить защиту конфиденциальных данных.
Q8. Что такое подход разделения A/B к оценке модели?
Разделение А/Б — это метод оценки модели, при котором две группы данных, группа A и группа B, выбираются случайным образом из большего набора данных. Одна группа (группа A) используется для обучения модели, а другая группа (группа B) используется для проверки производительности модели. Этот подход позволяет более точно оценить производительность модели, поскольку она тестируется на невидимых данных. Кроме того, случайное разбиение данных помогает избежать любых потенциальных систематических ошибок, которые могут присутствовать в данных.

Q9. В чем важность использования контроля версий для MLOps?
Контроль версий важен для MLOps, поскольку он позволяет отслеживать и управлять кодами, а также изменениями в кодах и данных. Это помогает поддерживать воспроизводимость данных и отслеживать, что было опробовано в прошлом. Кроме того, это помогает предотвратить потерю данных и делает совместную работу над проектами более доступной.
Q10. В чем разница между развертыванием модели A/B-тестирования и Multi-Arm Bandit?
A/B-тестирование и Multi-Arm Bandit (MAB) — это методы развертывания модели, которые включают сравнение нескольких версий модели. Однако они используются для разных целей и имеют некоторые ключевые отличия.
A/B-тестирование сравнивает две или более версии модели, чтобы определить, какая из них работает лучше. Обычно он используется для оптимизации определенного показателя, например конверсии или рейтинга кликов. При A/B-тестировании различные версии модели развертываются для фиксированного процента пользователей, а производительность каждой версии оценивается в течение фиксированного периода времени.
Multi-Arm Bandit (MAB) — это онлайн-метод экспериментов, который адаптируется к производительности различных версий модели по мере их развертывания. Он используется, чтобы сбалансировать компромисс между исследованием (испытание различных версий модели, чтобы найти лучшую) и эксплуатацией (использование наиболее эффективной версии модели для максимизации определенной метрики). Алгоритм MAB использует стратегию, которая присваивает разные вероятности разным версиям модели, чтобы решить, какую из них развертывать следующей. Затем он корректирует вероятности на основе результатов предыдущих развертываний.
Q11. В чем разница между канареечной и сине-зеленой стратегиями развертывания?
Канареечное и сине-зеленое развертывание — это стратегии, используемые для развертывания новых версий программного приложения без нарушения работы существующей службы. Однако работают они немного по-разному.
Canary-развертывание — это метод, при котором новая версия приложения развертывается на небольшом подмножестве пользователей или серверов. Это позволяет протестировать новую версию приложения в реальной среде с реальными пользователями, прежде чем она будет развернута для всей пользовательской базы. Любые проблемы с новой версией приложения будут выявлены и решены до того, как новая версия будет развернута для всей пользовательской базы.
С другой стороны, сине-зеленое развертывание предполагает поддержку двух идентичных сред: одной для текущей версии приложения (синяя) и одной для новой версии (зеленая). Новая версия развертывается в зеленой среде, когда новое приложение готово. Затем эта новая версия тестируется, чтобы убедиться, что она работает должным образом. Как только подтверждается, что новая версия работает правильно, трафик перенаправляется в зеленую среду, а синяя среда отключается.
Q12. Почему вы должны отслеживать атрибуцию функций, а не их распространение?
Мониторинг атрибуции функций, а не распределения функций, может быть полезен в определенных ситуациях, поскольку он предоставляет больше информации о том, как конкретные функции модели влияют на ее общую производительность.
Атрибуция функций относится к определению важности или вклада каждой функции в выходные данные модели. Его можно использовать для определения того, какие функции наиболее важны для прогнозирования и насколько каждая функция влияет на окончательное решение. Эта информация может помочь понять поведение модели, выявить потенциальные проблемы или предубеждения и решить, как улучшить модель.
С другой стороны, распределение признаков относится к распределению значений для определенного признака в наборе данных. Хотя полезно понимать распределение функций в данных, сам по себе мониторинг распределения функций может не дать достаточно информации о том, как модель использует эти функции для прогнозирования.
Таким образом, мониторинг атрибуции функций, а не распределения функций, может быть полезен, поскольку он предоставляет больше информации о том, как конкретные функции модели влияют на ее общую производительность, что может помочь понять поведение модели, выявить потенциальные проблемы или отклонения и принять решения о том, как для улучшения модели.
Q13. Каковы способы упаковки моделей ML?
Существуют различные способы упаковки модели машинного обучения для развертывания, включая создание автономного исполняемого файла, использование контейнеров, развертывание в бессерверной архитектуре, использование облачных сервисов и создание API-интерфейсов для модели.
- Автономный исполняемый файл: Автономный исполняемый файл — это автономный пакет, включающий модель машинного обучения и ее зависимости. Это может быть развернуто на различных платформах и не требует установки дополнительного программного обеспечения.
- Контейнеры: Контейнеры — это способ упаковки и развертывания программных приложений, включая модели машинного обучения. Они обеспечивают согласованную среду выполнения и упрощают развертывание модели в различных средах. Популярные технологии контейнеризации включают Docker и Kubernetes.
- Бессерверный: Бессерверное развертывание — это способ запуска кода без выделения серверов или управления ими. Модели машинного обучения могут быть развернуты как функция как услуга (FaaS) и активированы определенными событиями. Это обеспечивает экономичное развертывание и масштабирование.
- Облако основе: поставщики облачных услуг, такие как Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure, предлагают различные услуги для развертывания моделей машинного обучения. Эти услуги включают готовые контейнеры, бессерверные варианты и облачные платформы машинного обучения.
- API-интерфейсы: Модели машинного обучения могут быть представлены в виде API (интерфейс прикладного программирования), который позволяет другим приложениям запрашивать модель и получать прогнозы в ответ. Это можно реализовать с помощью веб-фреймворка, такого как Flask или Django.

Источник: dataaiku.com
Q14. Что такое концепция «неизменяемой инфраструктуры»?
Неизменная инфраструктура относится к тому факту, что ваша инфраструктура должна рассматриваться как неизменяемая или неизменяемая. Это означает, что после того, как вы развернули свою инфраструктуру, вы не должны пытаться изменить ее. И если изменение необходимо, вы должны развернуть новую версию инфраструктуры. Эта стратегия помогает предотвратить дрейф концепций и эффективно поддерживает инфраструктуру.
Q15. Укажите некоторые распространенные проблемы, связанные с развертыванием модели машинного обучения.
Ниже приведены некоторые распространенные проблемы, которые необходимо учитывать при развертывании моделей машинного обучения..
- Проверка работоспособности модели в продакшене
- Управление версиями модели и зависимостями
- Автоматизация обучения и развертывания моделей
- Мониторинг производительности модели в продакшене
- Борьба с дрейфом данных
Заключение
Если вы смогли ответить на все вопросы, то браво! Если нет, то не о чем унывать. Настоящая ценность этого блога заключается в том, чтобы понять эти вопросы и иметь возможность обобщить их, когда вы столкнетесь с похожими вопросами в своем следующем интервью по машинному обучению! Если вы боролись с этими вопросами, не волнуйтесь! Настало время сесть и подготовить эти концепции.
Ваши основные выводы из этой статьи:
- Конкретное понимание MLOps, ModelOps и AIOps и того, чем они отличаются от DevOps.
- Как создать инфраструктуру и конвейеры CI/CD в MLOps
- Концепция дрейфа модели
- Различные тесты, которые необходимо выполнить перед развертыванием модели машинного обучения в производственном конвейере.
- Разница между A/B-тестированием и методами развертывания модели Multi-Arm Bandit
- Важность контроля версий в MLop и различных методов упаковки моделей ML
- Концепция неизменяемой инфраструктуры и некоторые распространенные проблемы, возникающие при развертывании модели машинного обучения.
Если вы тщательно изучите их, я могу гарантировать, что вы прошли всю длину и ширину MLOps. В следующий раз, когда вы столкнетесь с подобными вопросами, вы можете с уверенностью ответить на них! Я надеюсь, что вы нашли этот блог полезным и что я успешно добавил ценность вашим знаниям. Удачи в подготовке к собеседованию и в дальнейших начинаниях!
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2023/02/15-must-read-interview-questions-on-mlops-for-2023/
- 1
- 10
- 11
- 2023
- 7
- 9
- a
- в состоянии
- О нас
- принятие
- доступ
- доступной
- точность
- точный
- через
- адаптируются
- добавленный
- дополнительный
- Дополнительно
- адрес
- плюс
- После
- против
- AI
- AI / ML
- Стремясь
- Цель
- AIOps
- алгоритм
- Все
- позволяет
- в одиночестве
- всегда
- Amazon
- Amazon Web Services
- Веб-службы Amazon (AWS)
- суммы
- аналитика
- Аналитика Видхья
- анализировать
- анализ
- и
- Другой
- ответ
- API
- API
- Применение
- Приложения
- прикладной
- подхода
- подходы
- соответствующий
- архитектура
- области
- гайд
- искусственный
- искусственный интеллект
- оценки;
- Аутентификация
- автоматизировать
- автоматизация
- избежать
- AWS
- Лазурный
- назад
- Баланс
- Бандит
- Использование темпера с изогнутым основанием
- основанный
- Базовая линия
- , так как:
- становиться
- становление
- до
- полезный
- ЛУЧШЕЕ
- Лучшая
- между
- Блог
- Синии
- ширина
- Приносит
- шире
- Строительство
- бизнес
- заботится
- случаев
- случаев
- категории
- Вызывать
- CD
- Центр
- определенный
- изменение
- изменения
- выбор
- класс
- Уборка
- облако
- Облачная платформа
- код
- сотрудничать
- сотрудничество
- сотрудничество
- лыжных шлемов
- комбинируя
- приход
- Общий
- сравнить
- сравненный
- сравнив
- конкурентоспособный
- полный
- компоненты
- вычисление
- сама концепция
- понятия
- Условия
- уверенно
- ПОДТВЕРЖДЕНО
- последовательный
- Контейнеры
- содержит
- продолжается
- (CIJ)
- контраст
- способствовать
- содействие
- вклад
- контроль
- Конверсия
- может
- покрытый
- Covid-19.
- COVID-19 пандемия
- Создайте
- Создающий
- Текущий
- цикл
- данным
- Потеря данных
- занимавшийся
- решение
- решения
- Спрос
- развертывание
- развернуть
- развертывание
- развертывание
- развертывания
- Глубины
- Производный
- обнаружение
- Определять
- определения
- развивать
- застройщиков
- Развитие
- DevOps
- отличаться
- разница
- Различия
- различный
- непосредственно
- усмотрение
- распределение
- Django
- Docker
- вниз
- управлять
- вождение
- в течение
- каждый
- Edge
- затрат
- эффективный
- эффективно
- позволяет
- охватывая
- шифрование
- впритык
- инженер
- Инженеры
- достаточно
- обеспечивать
- обеспечивает
- обеспечение
- Весь
- Окружающая среда
- средах
- существенный
- оценивать
- оценивается
- оценка
- Даже
- События
- Каждая
- многое
- существующий
- ожидаемый
- опыта
- эксплуатация
- исследование
- подвергаться
- добыча
- экстремальный
- Face
- сталкиваются
- Особенность
- Особенности
- Обратная связь
- поле
- Файл
- окончательный
- Найдите
- First
- фиксированной
- Фокус
- внимание
- фокусируется
- после
- найденный
- Рамки
- часто
- от
- фундаментальный
- будущее
- Gain
- получение
- GCP
- получить
- идти
- Go
- цель
- будет
- хорошо
- Google Cloud
- Виртуальная платформа Google
- Зелёная
- группы
- Группы
- Расти
- Управляемость
- имеющий
- помощь
- полезный
- помогает
- High
- высококачественный
- надежды
- Как
- How To
- Однако
- HTTPS
- идентичный
- идентифицированный
- определения
- изображений
- неизменный
- в XNUMX году
- значение
- важную
- улучшать
- улучшение
- in
- инцидент
- включают
- включает в себя
- В том числе
- Увеличение
- повышение
- все больше и больше
- individual
- промышленность
- информация
- Инфраструктура
- вход
- установлен
- интегрировать
- Интегрируется
- Интегрируя
- интеграции.
- Интеллекта
- Интерфейс
- Интервью
- вопросы интервью
- Интервью
- включать в себя
- вовлеченный
- включает в себя
- вопросы
- IT
- ИТ сервис
- работа
- Предложения работы
- Jupyter Notebook
- Сохранить
- Основные
- знание
- знания
- Kubernetes
- большой
- больше
- последний
- УЧИТЬСЯ
- изучение
- Длина
- Вероятно
- Ограниченный
- от
- удачи
- машина
- обучение с помощью машины
- поддерживать
- поддерживает
- сделать
- ДЕЛАЕТ
- Создание
- управлять
- управление
- управления
- многих
- Максимизировать
- означает
- Медиа
- Соответствует
- метод
- методологии
- методы
- метрический
- Метрика
- Microsoft
- Microsoft Azure
- может быть
- ML
- млн операций в секунду
- модель
- моделирование
- Модели
- монитор
- Мониторинг
- БОЛЕЕ
- более эффективным
- самых
- с разными
- Должен прочитать
- Должен иметь
- необходимо
- Необходимость
- необходимый
- потребности
- сетей
- Новые
- следующий
- НЛП
- ноутбук
- Nvidia
- предлагают
- оффлайн
- ONE
- онлайн
- Операционный отдел
- Возможности
- Оптимизировать
- Опции
- организации
- Другое
- общий
- принадлежащих
- пакет
- коробок
- пандемия
- часть
- мимо
- процент
- выполнять
- производительность
- выполняет
- период
- настойчиво
- фаза
- трубопровод
- Платформа
- Платформы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- состояния потока
- Популярное
- возможное
- потенциал
- практиками
- Точность
- предсказывать
- прогноз
- Predictions
- Подготовить
- представить
- предотвращать
- предыдущий
- политикой конфиденциальности.
- вероятность
- проблемам
- процесс
- Процессы
- Производство
- профессионалы
- Программирование
- проектов
- защищенный
- обеспечивать
- поставщики
- приводит
- обеспечение
- обеспечение
- опубликованный
- целей
- Вопросы
- быстро
- Обменный курс
- Читать
- готовый
- реальные
- реальная стоимость
- реальный мир
- реализованный
- причины
- Получать
- недавно
- назвало
- понимается
- регулярно
- Связанный
- запросить
- требовать
- Требования
- требуется
- Постановления
- решен
- Реагируйте
- ответ
- Итоги
- переквалификация
- возвращаться
- надежный
- Катить
- Run
- Бег
- масштабируемые
- Шкала
- масштабирование
- Сценарии
- Наука
- Ученые
- безопасность
- выбранный
- смысл
- чувствительный
- служить
- Serverless
- обслуживание
- Услуги
- выступающей
- набор
- несколько
- должен
- показанный
- существенно
- аналогичный
- Сэр
- обстоятельства
- скос
- навыки
- немного отличается
- Медленно
- небольшой
- плавно
- So
- Software
- Разработчики программного обеспечения
- разработка программного обеспечения
- Решения
- некоторые
- конкретный
- скорость
- раскол
- Этап
- автономные
- стоит
- Шаги
- диск
- стратегий
- Стратегия
- упорядочить
- упорядочение
- Успешно
- такие
- система
- системы
- Takeaways
- задачи
- команды
- технологии
- тестXNUMX
- Тестирование
- тестов
- Ассоциация
- их
- тщательно
- Через
- время
- в
- вместе
- Лексемы
- инструменты
- к
- трек
- Отслеживание
- трафик
- Train
- специалистов
- Обучение
- лечение
- тенденция
- Тенденции
- срабатывает
- Типы
- типично
- В конечном счете
- под
- лежащий в основе
- понимать
- понимание
- Ед. изм
- новейший
- обновление
- использование
- Информация о пользователе
- пользователей
- использовать
- VALIDATE
- ценностное
- Наши ценности
- различный
- проверить
- версия
- контроль версий
- способы
- Web
- веб-сервисы
- Что
- Что такое
- который
- в то время как
- будете
- без
- Работа
- работать вместе
- Рабочие процессы
- работает
- бы
- лет
- ВАШЕ
- зефирнет