Настройка модели — это экспериментальный процесс поиска оптимальных параметров и конфигураций для модели машинного обучения (ML), которые приводят к наилучшему желаемому результату с набором данных проверки. Одноцелевая оптимизация с метрикой производительности — наиболее распространенный подход к настройке моделей машинного обучения. Однако в дополнение к прогностическим характеристикам может быть несколько целей, которые необходимо учитывать для определенных приложений. Например,
- Справедливость. Цель здесь состоит в том, чтобы побудить модели смягчить предвзятость в результатах моделей между определенными подгруппами в данных, особенно когда люди зависят от алгоритмических решений. Например, заявка на получение кредита должна быть не только точной, но и непредвзятой по отношению к различным подгруппам населения.
- Время вывода. Целью здесь является сокращение времени вывода во время вызова модели. Например, система распознавания речи должна не только точно понимать разные диалекты одного и того же языка, но и работать в течение определенного времени, приемлемого для бизнес-процесса.
- Энергоэффективность. Целью здесь является обучение небольших энергоэффективных моделей. Например, модели нейронных сетей сжимаются для использования на мобильных устройствах и, таким образом, естественным образом снижают их энергопотребление за счет уменьшения количества FLOPS, необходимого для прохода по сети.
Методы многокритериальной оптимизации представляют различные компромиссы между желаемыми показателями. Это может включать в себя поиск глобального минимума целевой функции при условии одновременного выполнения набора ограничений на разные показатели.
Автоматическая настройка моделей Amazon SageMaker (AMT) находит наилучшую версию модели, запуская множество обучающих заданий SageMaker в вашем наборе данных, используя алгоритм и диапазоны гиперпараметров. Затем он выбирает значения гиперпараметров, которые приводят к модели, которая работает лучше всего, как измеряется метрикой (например, точность, auc, полнота), которую вы определяете. Благодаря автоматической настройке модели Amazon SageMaker вы можете найти наилучшую версию своей модели, запустив обучающие задания в своем наборе данных с помощью несколько стратегий поиска, такие как байесовский, случайный поиск, поиск по сетке и гипердиапазон.
Amazon SageMaker Уточнить может обнаруживать потенциальное смещение во время подготовки данных, после обучения модели и в вашей развернутой модели. В настоящее время он предлагает 21 различную метрику на выбор. Эти метрики также находятся в открытом доступе смпрояснить пакет python и репозиторий github здесь. Подробнее об измерении предвзятости с помощью метрик Amazon SageMaker Clarify можно узнать на странице Узнайте, как Amazon SageMaker Clarify помогает выявлять предвзятость.
В этом блоге мы покажем вам, как автоматически настроить модель машинного обучения с помощью Amazon SageMaker AMT для целей точности и справедливости путем создания единой комбинированной метрики. Мы демонстрируем вариант использования финансовых услуг для прогнозирования кредитного риска с показателем точности Площадь под кривой (AUC) для измерения производительности и метрики смещения Разница в положительных пропорциях предсказанных меток (DPPL) от SageMaker Clarify для измерения дисбаланса в прогнозах модели для разных демографических групп. Код для этого примера доступен на GitHub.
Справедливость в прогнозировании кредитного риска
Индустрия кредитования в значительной степени зависит от кредитных рейтингов для обработки заявок на кредит. Как правило, кредитные баллы отражают историю заимствования и выплаты денег заявителем, и кредиторы ссылаются на них при определении кредитоспособности человека. Платежные фирмы и банки заинтересованы в создании систем, которые могут помочь определить риск, связанный с конкретным приложением, и предоставить конкурентоспособные кредитные продукты. Модели машинного обучения (МО) можно использовать для создания такой системы, которая обрабатывает исторические данные о заявителях и прогнозирует профиль кредитного риска. Данные могут включать финансовую и трудовую историю заявителя, его демографические данные и новый контекст кредита / займа. В любой модели, предсказывающей, не объявит ли тот или иной заявитель дефолт в будущем, всегда присутствует некоторая статистическая неопределенность. Системы должны обеспечивать компромисс между отклонением приложений, которые со временем могут выйти из строя, и принятием приложений, которые в конечном итоге будут кредитоспособными.
Владельцам бизнеса такой системы необходимо обеспечить достоверность и качество моделей в соответствии с существующими и будущими нормативными требованиями. Они обязаны относиться к клиентам справедливо и обеспечивать прозрачность в принятии решений. Они могут захотеть убедиться, что положительные прогнозы модели не несбалансированы по разным группам (например, по полу, расе, этнической принадлежности, иммиграционному статусу и другим). После того, как необходимые данные собраны, обучение модели ML обычно оптимизирует производительность прогнозирования в качестве основной цели с такой метрикой, как точность классификации или показатель AUC. В качестве альтернативы модель с заданной целью производительности может быть ограничена метрикой справедливости, чтобы гарантировать соблюдение определенных требований. Одним из таких методов ограничения модели является настройка гиперпараметров с учетом справедливости. Применяя эти стратегии, лучшая модель-кандидат может иметь меньшее смещение, чем неограниченная модель, сохраняя при этом высокую прогностическую эффективность.

В сценарии, изображенном на этой схеме,
- Модель машинного обучения построена на основе исторических данных о кредитоспособности клиентов. Процесс обучения модели и настройки гиперпараметров обеспечивает максимальное достижение нескольких целей, включая точность и справедливость классификации. Модель развертывается в существующем бизнес-процессе в производственной системе.
- Кредитный профиль нового клиента оценивается на предмет кредитного риска. Если риск низкий, он может пройти автоматизированный процесс. Приложения с высоким риском могут включать проверку человеком перед принятием окончательного решения о принятии или отклонении.
Решения и показатели, собранные во время проектирования и разработки, развертывания и эксплуатации, можно документировать с помощью Карты моделей SageMaker и поделился с заинтересованными сторонами.
Этот пример использования демонстрирует, как уменьшить смещение модели по отношению к определенной группе путем точной настройки гиперпараметров для комбинированной объективной метрики точности и достоверности с помощью автоматической настройки модели SageMaker. Мы используем набор данных South German Credit (Набор кредитных данных Южной Германии).
Данные заявителя можно разделить на следующие категории:
- демографический
- Финансовые данные
- Трудовой стаж
- Цель кредита
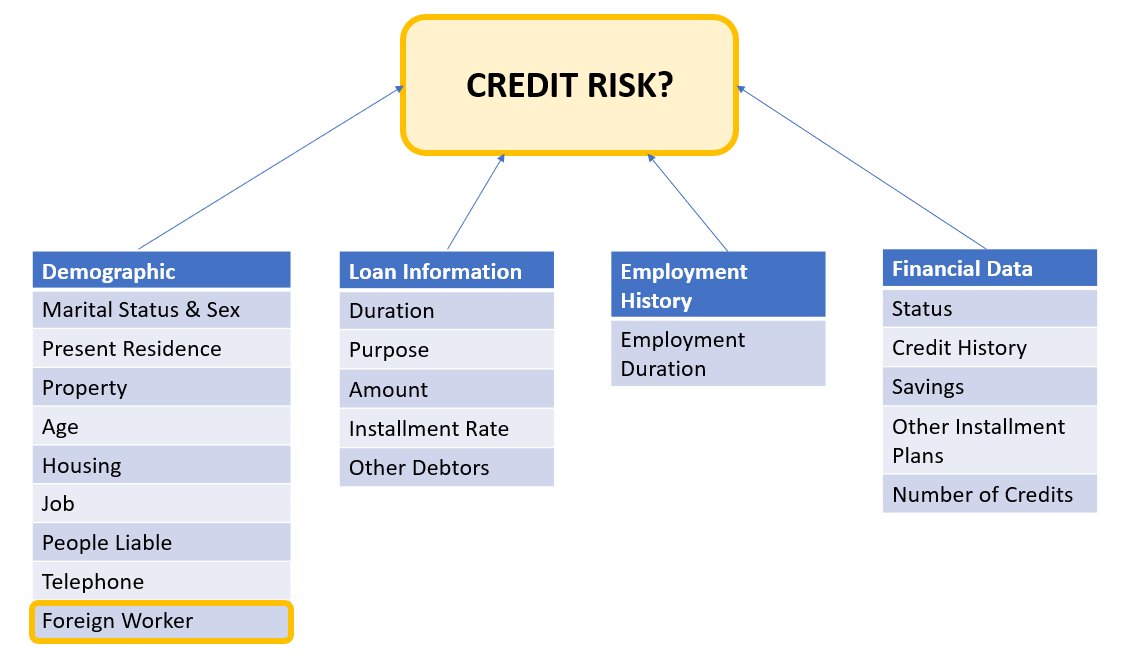
В этом примере мы специально смотрим на демографические данные «иностранных рабочих» и настраиваем модель, которая предсказывает решения о кредитных заявках с высокой точностью и низким уровнем предвзятости в отношении этой конкретной подгруппы.
Есть различные метрики смещения которые можно использовать для оценки справедливости системы по отношению к конкретным подгруппам данных. Здесь мы используем абсолютное значение разницы положительных пропорций в предсказанных метках (ДППЛ) от SageMaker Clarify. Проще говоря, DPPL измеряет разницу в присвоении положительного класса (хороший кредит) между неиностранными рабочими и иностранными рабочими.
Например, если модель присваивает 4.5% всех иностранных работников положительный ярлык, а 13.7% всех неиностранных работников присваивается положительный ярлык, то DPPL = 0.137 – 0.045 = 0.092.
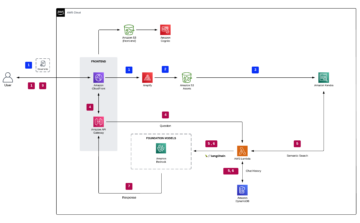
Архитектура решения
На рисунке ниже представлен общий обзор архитектуры задания автоматической настройки модели с помощью XGBoost в Amazon SageMaker.
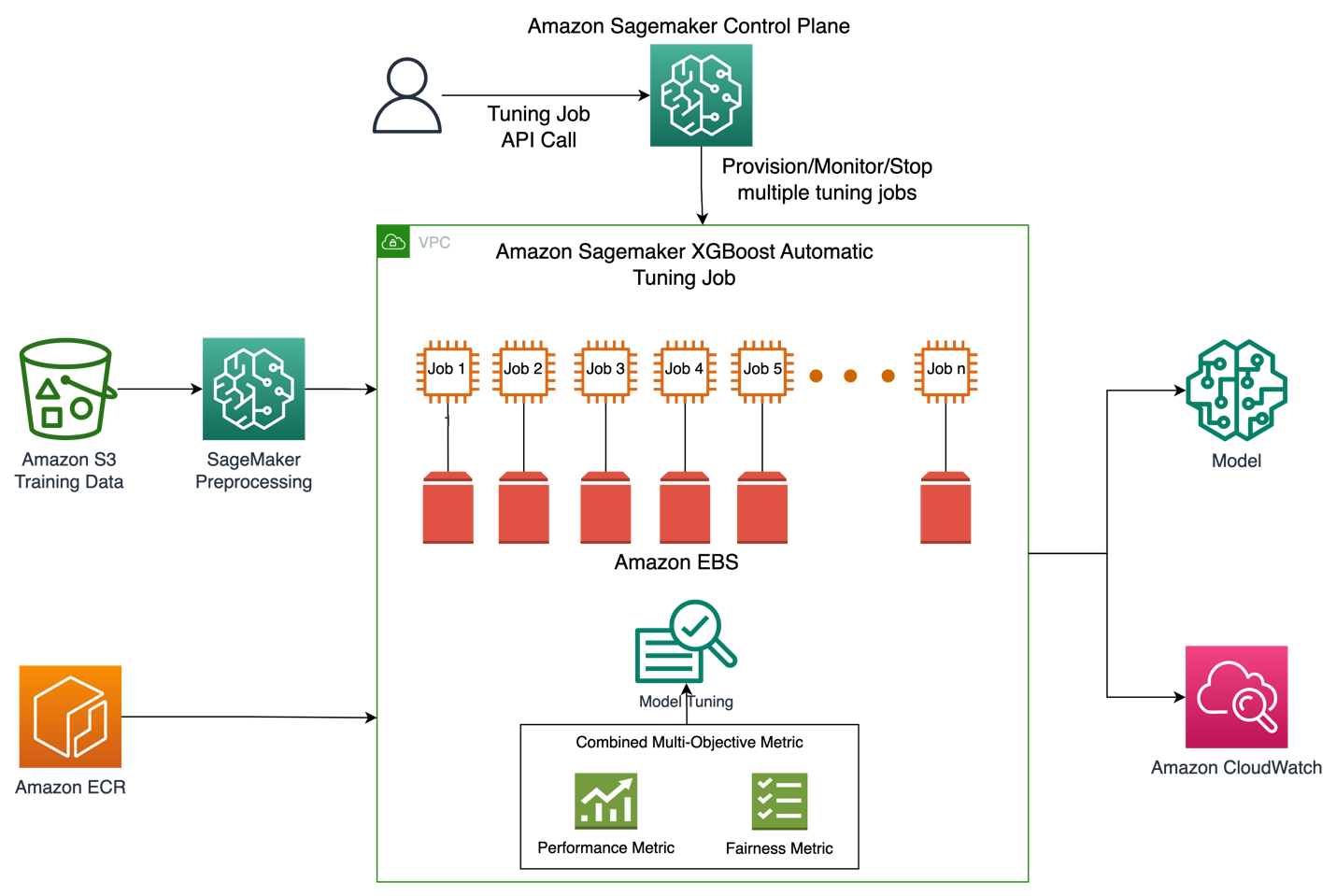
В решении SageMaker Processing выполняет предварительную обработку обучающего набора данных из Amazon S3. Автоматическая настройка Amazon SageMaker создает несколько учебных заданий SageMaker со связанными с ними инстансами EC2 и томами EBS. Контейнер для алгоритма (XGBoost) загружается из Amazon ECR в каждом задании. SageMaker AMT находит наилучшую версию модели, выполняя множество обучающих заданий на предварительно обработанном наборе данных с использованием указанного сценария алгоритма и диапазона гиперпараметров. Выходные метрики регистрируются в Amazon CloudWatch для мониторинга.
Гиперпараметры, которые мы настраиваем в этом случае использования, следующие:
- ОП – Уменьшение размера шага, используемое в обновлениях для предотвращения переобучения.
- min_child_weight – Минимальная сумма веса экземпляра (гессен), необходимая в дочернем элементе.
- гамма – Минимальное снижение потерь, необходимое для создания дальнейшего раздела на листовом узле дерева.
- Максимальная глубина – Максимальная глубина дерева.
Определение этих и других гиперпараметров, доступных в SageMaker AMT, можно найти здесь.
Во-первых, мы демонстрируем базовый сценарий одной целевой метрики производительности для настройки гиперпараметров с помощью автоматической настройки модели. Затем мы демонстрируем оптимизированный сценарий многоцелевой метрики, заданной как комбинация метрики производительности и метрики справедливости.
Настройка одного метрического гиперпараметра (базовый уровень)
Для задания настройки можно выбрать несколько показателей для оценки отдельных заданий обучения. В соответствии с приведенным ниже фрагментом кода мы указываем единственную целевую метрику как objective_metric_name. Задание настройки гиперпараметров возвращает задание обучения, которое дало наилучшее значение для выбранной целевой метрики.
В этом базовом сценарии мы настраиваем площадь под кривой (AUC), как показано ниже. Важно отметить, что мы оптимизируем только AUC, а не другие показатели, такие как справедливость.
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner hyperparameter_ranges = {'eta': ContinuousParameter(0, 1), 'min_child_weight': IntegerParameter(1, 10), 'gamma': IntegerParameter(1, 5), 'max_depth': IntegerParameter(1, 10)} objective_metric_name = 'validation:auc' tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10,
) tuning_job_name = "xgb-tuner-{}".format(strftime("%d-%H-%M-%S", gmtime()))
inputs = {'train': train_data_path, 'validation': val_data_path}
tuner.fit(inputs, job_name=tuning_job_name)
tuner.wait()
tuner_metrics = sagemaker.HyperparameterTuningJobAnalytics(tuning_job_name)В данном контексте max jobs позволяет нам указать, сколько раз одно задание на обучение будет настроено, и найти наилучшее задание на обучение.
Многоцелевая настройка гиперпараметров (оптимизированная честность)
Мы хотим оптимизировать несколько целевых показателей с настройкой гиперпараметров, как описано в этом бумаги. Однако SageMaker AMT по-прежнему принимает в качестве входных данных только одну метрику.
Чтобы решить эту проблему, мы выражаем несколько метрик в виде одной метрической функции и оптимизируем эту метрику:
- максМ(у1, у2, θ)
- y1, y2 — разные метрики. Например, оценка AUC и DPPL.
- M(⋅,⋅,θ) является скаляризационной функцией и параметризуется фиксированным параметром
Более высокий вес благоприятствует этой конкретной цели настройки модели. Веса могут варьироваться от случая к случаю, и вам может потребоваться попробовать разные веса для вашего варианта использования. В этом примере веса для AUC и DPPL были установлены эвристически. Давайте рассмотрим, как это будет выглядеть в коде. Вы можете видеть, как задание обучения возвращает одну метрику на основе комбинированной функции оценки AUC для производительности и DPPL для справедливости. Диапазоны оптимизации гиперпараметров для нескольких целей такие же, как и для одной цели. Мы передаем метрику проверки как «auc», но за кулисами мы возвращаем результаты комбинированной метрической функции, как описано последним в списке функций ниже:
Вот функция многоцелевой оптимизации:
objective_metric_name = 'validation:auc'
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10
)Вот функция для вычисления оценки AUC:
def eval_auc_score(predt, dtrain):
fY = [1 if p > 0.5 else 0 for p in predt]
y = dtrain.get_label()
auc_score = roc_auc_score(y, fY)
return auc_scoreВот функция для вычисления оценки DPPL:
def eval_dppl(predt, dtrain):
dtrain_np = dmatrix_to_numpy(dtrain)
# groups: an np array containing 1 or 2
groups = dtrain_np[:, -1]
# sensitive_facet_index: boolean column indicating sensitive group
sensitive_facet_index = pd.Series(groups - 1, dtype=bool)
# positive_predicted_label_index: boolean column indicating positive predicted labels
positive_label_index = pd.Series(predt > 0.5)
return abs(DPPL(predt, sensitive_facet_index, positive_label_index))Вот функция для комбинированной метрики:
def eval_combined_metric(predt, dtrain):
auc_score = eval_auc_score(predt, dtrain)
DPPL = eval_dppl(predt, dtrain)
# Assign weight of 3 to AUC and 1 to DPPL
# Maximize (1-DPPL) for the purpose of minimizing DPPL combined_metric = ((3*auc_score)+(1-DPPL))/4 print("DPPL, AUC Score, Combined Metric: ", DPPL, auc_score, combined_metric)
return "auc", combined_metricЭксперименты и результаты
Генерация синтетических данных для набора данных смещения
Исходный набор данных South German Credit содержал 1000 записей, и мы создали еще 100 записей синтетическим путем, чтобы создать набор данных, в котором систематическая ошибка в прогнозах модели неблагоприятна для иностранных рабочих. Это делается для имитации предвзятости, которая может проявляться в реальном мире. Новые данные об иностранных работниках, помеченных как заявители с плохой кредитной историей, были экстраполированы на существующие иностранные работники с таким же ярлыком.
Существует множество библиотек/методов для создания синтетических данных, и мы используем Синтетическое хранилище данных (ДППЛВ).
Из следующего фрагмента кода видно, как синтетические данные генерируются с помощью DPPLV с набором кредитных данных Южной Германии:
# Parameters for generated data
# How many rows of synthetic data
num_rows = 100 # Select all foreign workers who were accepted (foreign_worker value 1 credit_risk 1)
ForeignWorkerData = training_data.loc[(training_data['foreign_worker'] == 1) & (training_data['credit_risk'] == 1)] # Fit Foreign Worker data to SDV model
model = GaussianCopula()
model.fit(ForeignWorkerData) # Generate Synthetic foreign worker data based on rows stated
SynthForeignWorkers = model.sample(Rows)Мы создали 100 новых синтетических записей об иностранных рабочих на основе иностранных рабочих, которые были приняты в исходном наборе данных. Теперь мы возьмем эти записи и преобразуем метку «credit_risk» в 0 (плохой кредит). Это несправедливо пометит этих иностранных рабочих как плохую кредитную историю, что внесет предвзятость в наш набор данных.
SynthForeignWorkers.loc[SynthForeignWorkers['credit_risk'] == 1, 'credit_risk'] = 0Мы исследуем систематическую ошибку в наборе данных с помощью графиков ниже.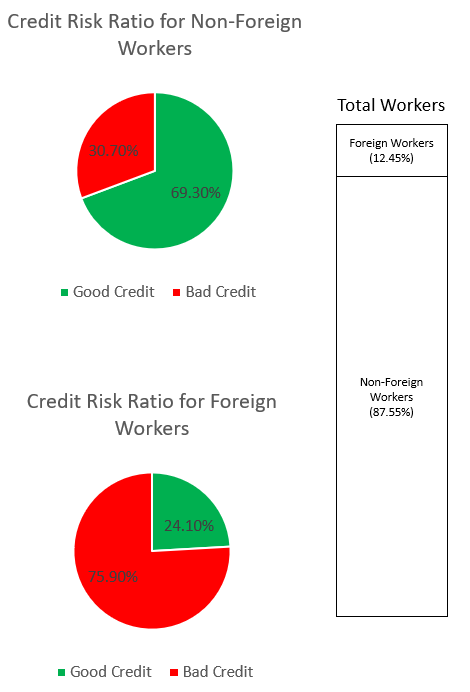
Круговая диаграмма вверху показывает процент неиностранных рабочих с хорошей или плохой кредитной историей, а нижняя круговая диаграмма показывает то же самое для иностранных рабочих. Процент иностранных рабочих, отмеченных как «плохой кредит», составляет 75.90% и намного превышает 30.70% неиностранных рабочих, отмеченных таким же образом. Панель стека отображает почти одинаковую процентную разбивку общего числа работников по категориям иностранных и неиностранных работников.
Мы хотим, чтобы модель машинного обучения не узнала о сильном предвзятом отношении к иностранным рабочим либо через явные, либо неявные прокси-функции в данных. С дополнительной целью справедливости мы направляем модель ML, чтобы смягчить предвзятость более низкой кредитоспособности в отношении иностранных рабочих.
Производительность модели после настройки как для производительности, так и для справедливости
На этой диаграмме показан график плотности до 100 заданий по настройке, выполняемых SageMaker AMT, и соответствующие им объединенные значения целевых показателей. Хотя мы установили max jobs до 100, изменяется по усмотрению пользователя. Комбинированная метрика представляла собой комбинацию AUC и DPPL с функцией: (3*AUC + (1-DPPL)) / 4. Причина, по которой мы используем (1-DPPL) вместо (DPPL), заключается в том, что мы хотели бы максимизировать совокупную цель для минимально возможного DPPL (более низкий DPPL означает меньшую предвзятость в отношении иностранных рабочих). На графике показано, как AMT помогает определить наилучшие гиперпараметры для модели XGBoost, которая возвращает максимальное значение комбинированной метрики оценки, равное 0.68.
Производительность модели с комбинированной метрикой
Ниже мы рассмотрим переднюю диаграмму парето для отдельных показателей AUC и DPPL. Здесь используется передняя диаграмма Парето для визуального представления компромиссов между несколькими целями, в данном случае двумя значениями показателей (AUC и DPPL). Точки на фронте кривой считаются одинаково хорошими, и нельзя улучшить одну метрику, не ухудшив другую. Диаграмма Парето позволяет нам увидеть, как разные работы выполняются по сравнению с базовым уровнем (красный кружок) с точки зрения обеих метрик. Он также показывает нам наиболее оптимальную работу (зеленый треугольник). Положение красного круга и зеленого треугольника важно, потому что оно позволяет нам понять, действительно ли наша объединенная метрика работает так, как ожидалось, и действительно ли оптимизируется для обеих метрик. Код для создания передней диаграммы Парето включен в записную книжку в GitHub.

В этом сценарии более желательно более низкое значение DPPL (меньшее смещение), а более высокое значение AUC лучше (повышенная производительность).
Здесь базовый уровень (красный кружок) представляет сценарий, в котором объективной метрикой является только AUC. Другими словами, базовый уровень вообще не учитывает DPPL и оптимизируется только для AUC (без тонкой настройки для справедливости). Мы видим, что базовый уровень имеет хороший показатель AUC, равный 0.74, но не очень хорош в отношении честности с показателем DPPL, равным 0.75.
Оптимизированная модель (зеленый треугольник) представляет собой лучшую модель-кандидата при точной настройке для комбинированной метрики с соотношением весов 3:1 для AUC:DPPL. Мы видим, что оптимизированная модель имеет хороший показатель AUC, равный 0.72, а также низкий показатель DPPL, равный 0.43 (низкое смещение). Это задание по настройке обнаружило конфигурацию модели, в которой DPPL может быть значительно ниже базового уровня без значительного падения AUC. Модели с еще более низкими показателями DPPL можно определить, переместив зеленый треугольник дальше влево вдоль фронта Парето. Таким образом, мы достигли общей цели: хорошо работающая модель со справедливостью для подгрупп иностранных рабочих.
На приведенной ниже диаграмме мы можем видеть результаты прогнозов базовой модели и оптимизированной модели. Оптимизированная модель с комбинированной целью производительности и справедливости предсказывает положительный результат для 30.6% иностранных рабочих по сравнению с 13.9% из базовой модели. Таким образом, оптимизированная модель уменьшает предвзятость модели по отношению к этой подгруппе.

Заключение
В блоге показано, как реализовать многоцелевую оптимизацию с помощью SageMaker Automatic Model Tuning для реальных приложений. Во многих случаях собранные данные в реальном мире могут быть предвзятыми в отношении определенных подгрупп. Многоцелевая оптимизация с использованием автоматической настройки модели позволяет клиентам легко создавать модели машинного обучения, оптимизирующие справедливость в дополнение к точности. Мы демонстрируем пример прогнозирования кредитного риска и уделяем особое внимание справедливости для иностранных работников. Мы показываем, что можно максимизировать другую метрику, такую как справедливость, продолжая обучать модели с высокой производительностью. Если то, что вы прочитали, вызвало у вас интерес, вы можете попробовать пример кода, размещенный на Github. здесь.
Об авторах
 Муниш Дабра является старшим архитектором решений в Amazon Web Services (AWS). В настоящее время он занимается такими направлениями, как AI/ML, аналитика данных и наблюдаемость. У него большой опыт проектирования и создания масштабируемых распределенных систем. Ему нравится помогать клиентам внедрять инновации и преобразовывать свой бизнес в AWS. Линкедин: /мдабра
Муниш Дабра является старшим архитектором решений в Amazon Web Services (AWS). В настоящее время он занимается такими направлениями, как AI/ML, аналитика данных и наблюдаемость. У него большой опыт проектирования и создания масштабируемых распределенных систем. Ему нравится помогать клиентам внедрять инновации и преобразовывать свой бизнес в AWS. Линкедин: /мдабра
 Хасан Пунавала Хасан является старшим специалистом по архитектуре решений AI/ML в AWS. Он помогает клиентам разрабатывать и развертывать приложения машинного обучения в рабочей среде на AWS. Он имеет более чем 12-летний опыт работы в качестве специалиста по данным, специалиста по машинному обучению и разработчика программного обеспечения. В свободное время Хасан любит исследовать природу и проводить время с друзьями и семьей.
Хасан Пунавала Хасан является старшим специалистом по архитектуре решений AI/ML в AWS. Он помогает клиентам разрабатывать и развертывать приложения машинного обучения в рабочей среде на AWS. Он имеет более чем 12-летний опыт работы в качестве специалиста по данным, специалиста по машинному обучению и разработчика программного обеспечения. В свободное время Хасан любит исследовать природу и проводить время с друзьями и семьей.
 Мохаммад (Мох) Тахсин является младшим специалистом по архитектуре решений AI/ML для AWS. У Моха есть опыт преподавания студентам ответственных концепций искусственного интеллекта, и он увлечен передачей этих концепций через облачные архитектуры. В свободное время он любит поднимать тяжести, играть в игры и исследовать природу.
Мохаммад (Мох) Тахсин является младшим специалистом по архитектуре решений AI/ML для AWS. У Моха есть опыт преподавания студентам ответственных концепций искусственного интеллекта, и он увлечен передачей этих концепций через облачные архитектуры. В свободное время он любит поднимать тяжести, играть в игры и исследовать природу.
 Синчен Ма является прикладным ученым в AWS. Он работает в сервисной группе для автоматической настройки моделей SageMaker.
Синчен Ма является прикладным ученым в AWS. Он работает в сервисной группе для автоматической настройки моделей SageMaker.
 Рахул Сурека работает архитектором корпоративных решений в AWS из Индии. Рахул имеет более чем 22-летний опыт разработки и руководства программами трансформации крупного бизнеса в различных отраслевых сегментах. Его области интересов — данные и аналитика, потоковая передача и приложения AI/ML.
Рахул Сурека работает архитектором корпоративных решений в AWS из Индии. Рахул имеет более чем 22-летний опыт разработки и руководства программами трансформации крупного бизнеса в различных отраслевых сегментах. Его области интересов — данные и аналитика, потоковая передача и приложения AI/ML.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/tune-ml-models-for-additional-objectives-like-fairness-with-sagemaker-automatic-model-tuning/
- 1
- 10
- 100
- 28
- a
- О нас
- Absolute
- приемлемый
- принятие
- принятый
- принимающий
- Принимает
- точность
- точный
- точно
- достигнутый
- через
- на самом деле
- дополнение
- дополнительный
- адрес
- После
- против
- AI
- AI / ML
- алгоритм
- алгоритмический
- Все
- позволяет
- в одиночестве
- Несмотря на то, что
- всегда
- Amazon
- Создатель мудреца Амазонки
- Amazon Web Services
- Веб-службы Amazon (AWS)
- аналитика
- и
- Другой
- Применение
- Приложения
- прикладной
- Применение
- подхода
- архитектура
- ПЛОЩАДЬ
- области
- массив
- назначенный
- Юрист
- связанный
- Автоматизированный
- Автоматический
- автоматически
- доступен
- избежать
- AWS
- назад
- фон
- Плохой
- Банки
- бар
- основанный
- Базовая линия
- байесовский
- , так как:
- до
- за
- за кулисами
- не являетесь
- ниже
- ЛУЧШЕЕ
- Лучшая
- между
- смещение
- Блог
- Заимствование
- Дно
- Breakdown
- строить
- Строительство
- построенный
- бизнес
- Бизнес-процесс
- Трансформация бизнеса
- кандидат
- не могу
- случаев
- категории
- Категории
- определенный
- вызов
- График
- ребенок
- выбор
- Выберите
- выбранный
- Circle
- класс
- классификация
- облако
- код
- Column
- сочетание
- сочетании
- Общий
- конкурентоспособный
- Соответствие закону
- вычисление
- понятия
- Конфигурация
- Конфигурации
- Рассматривать
- считается
- ограничения
- потребление
- Container
- контекст
- продолжающийся
- конвертировать
- соответствующий
- может
- Создайте
- Создающий
- кредит
- кредитоспособность
- Текущий
- В настоящее время
- кривая
- клиент
- Клиенты
- данным
- Анализ данных
- Подготовка данных
- ученый данных
- набор данных
- решение
- Принятие решений
- решения
- По умолчанию
- демографический
- Демографическая
- демонстрировать
- демонстрирует
- плотность
- развертывание
- развернуть
- развертывание
- глубина
- описано
- Проект
- проектирование
- определения
- Застройщик
- Развитие
- Устройства
- разница
- различный
- усмотрение
- дисплеев
- распределенный
- распределенные системы
- Падение
- в течение
- каждый
- легко
- EBS
- затрат
- или
- занятость
- позволяет
- поощрять
- энергетика
- Энергопотребление
- обеспечивать
- Предприятие
- одинаково
- особенно
- Эфир (ETH)
- оценивать
- оценивается
- оценка
- Даже
- со временем
- пример
- существующий
- ожидаемый
- опыт
- Больше
- экспресс
- достаточно
- справедливость
- семья
- далеко
- милостей
- Особенности
- фигура
- окончательный
- финансовый
- финансовые услуги
- Найдите
- обнаружение
- находит
- конец
- Компаний
- соответствовать
- фиксированной
- Фокус
- после
- следующим образом
- иностранный
- найденный
- друзья
- от
- передний
- функция
- Функции
- далее
- будущее
- Игры
- пол
- в общем
- порождать
- генерируется
- поколение
- Немецкий
- GitHub
- данный
- Глобальный
- Go
- хорошо
- график
- Графики
- Зелёная
- сетка
- группы
- Группы
- инструкция
- сильно
- помощь
- помощь
- помогает
- здесь
- High
- высший
- наивысший
- исторический
- история
- состоялся
- Как
- How To
- Однако
- HTML
- HTTPS
- человек
- Людей
- Оптимизация гиперпараметра
- Настройка гиперпараметра
- ICS
- идентифицированный
- определения
- дисбаланс
- иммиграция
- осуществлять
- Импортировать
- важную
- улучшенный
- in
- В других
- включают
- включены
- В том числе
- расширились
- Индия
- individual
- промышленность
- обновлять
- вход
- пример
- вместо
- интерес
- заинтересованный
- интересы
- включать в себя
- IT
- саму трезвость
- работа
- Джобс
- этикетка
- Этикетки
- язык
- большой
- Фамилия
- ведущий
- УЧИТЬСЯ
- изучение
- кредиторы
- кредитование
- уровень
- ОГРАНИЧЕНИЯ
- Список
- варианты
- посмотреть
- выглядит как
- от
- Низкий
- машина
- обучение с помощью машины
- сделать
- Создание
- многих
- отметка
- Максимизировать
- максимизирует
- максимальный
- означает
- проводить измерение
- меры
- измерение
- методы
- метрический
- Метрика
- может быть
- минимизация
- минимальный
- смягчать
- ML
- Мобильный телефон
- мобильных устройств
- модель
- Модели
- деньги
- Мониторинг
- БОЛЕЕ
- самых
- перемещение
- много
- с разными
- естественно
- природа
- Необходимость
- необходимый
- сеть
- нервный
- нейронной сети
- Новые
- узел
- ноутбук
- номер
- цель
- целей
- Предложения
- ONE
- работать
- Операционный отдел
- против
- оптимальный
- оптимизация
- Оптимизировать
- оптимизированный
- оптимизирует
- оптимизирующий
- оригинал
- Другое
- Другое
- Результат
- перевешивать
- обзор
- Владельцы
- пакет
- параметры
- особый
- Прохождение
- страстный
- платить
- оплата
- процент
- выполнять
- производительность
- выполнения
- выполняет
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Играть
- пунктов
- население
- должность
- положительный
- возможное
- потенциал
- предсказанный
- прогноз
- Predictions
- предсказывает
- предотвращать
- первичный
- процесс
- Процессы
- обработка
- Производство
- Продукция
- Профиль
- Программы
- обеспечивать
- полномочие
- цель
- Питон
- Гонки
- случайный
- ассортимент
- соотношение
- Читать
- реальные
- реальный мир
- причина
- признание
- учет
- Red
- уменьшить
- снижает
- снижение
- отражать
- регуляторы
- Соответствие нормативным требованиям
- хранилище
- представлять
- представляет
- обязательный
- Требования
- ответственный
- результат
- Итоги
- возвращают
- возвращение
- Возвращает
- обзоре
- Снижение
- Run
- Бег
- sagemaker
- Автоматическая настройка модели SageMaker
- то же
- довольный
- масштабируемые
- сценарий
- Сцены
- Ученый
- Поиск
- сегментами
- старший
- чувствительный
- обслуживание
- Услуги
- набор
- общие
- должен
- показывать
- Шоу
- значительный
- существенно
- аналогичный
- просто
- одновременно
- одинарной
- Размер
- меньше
- Software
- Решение
- Решения
- некоторые
- Южная
- специалист
- конкретный
- конкретно
- указанный
- речь
- Распознавание речи
- тратить
- раскол
- стек
- заинтересованных сторон
- заявил
- статистический
- Статус:
- Шаг
- По-прежнему
- стратегий
- потоковый
- сильный
- Структура
- Студенты
- предмет
- такие
- синтетический
- синтетические данные
- синтетически
- система
- системы
- взять
- Обучение
- команда
- terms
- Ассоциация
- Будущее
- их
- Через
- время
- раз
- в
- топ
- Всего
- к
- Train
- Обучение
- Transform
- трансформация
- Прозрачность
- лечить
- типично
- Неопределенность
- под
- понимать
- Предстоящие
- Updates
- us
- Применение
- использование
- прецедент
- Информация о пользователе
- Проверка
- период действия
- ценностное
- Наши ценности
- различный
- версия
- тома
- Web
- веб-сервисы
- вес
- Что
- будь то
- который
- в то время как
- КТО
- будете
- в
- без
- слова
- Работа
- работник
- рабочие
- работает
- Мир
- бы
- XGBoost
- лет
- ВАШЕ
- зефирнет