v prva objava serije smo opisali nekaj temeljnih konceptov določanja velikosti gruče Apache Kafka, najboljše prakse za optimizacijo zmogljivosti in stroške vaše delovne obremenitve Kafka.
Ta objava pojasnjuje, kako osnovna infrastruktura vpliva na delovanje Kafke, ko uporabljate Amazonovo pretakanje za Apache Kafka (Amazon MSK) večplastno shranjevanje. Poglobili smo se v temeljne komponente večplastnega shranjevanja Amazon MSK in obravnavali vprašanja, kot so: Kako delujeta branje in pisanje v večplastni gruči, ki podpira shranjevanje?
V naslednjem prispevku bomo razpravljali o vplivu zakasnitve, priporočenih metrikah za spremljanje in zaključili z navodili o ključnih premislekih v produkcijski večplastni gruči, ki podpira shranjevanje.
Kako deluje večplastna shramba Amazon MSK
Da bi razumeli notranjo arhitekturo večplastnega pomnilnika Amazon MSK, se najprej pogovorimo o nekaterih osnovah Kafkinih tem, particij in delovanja branja in pisanja.
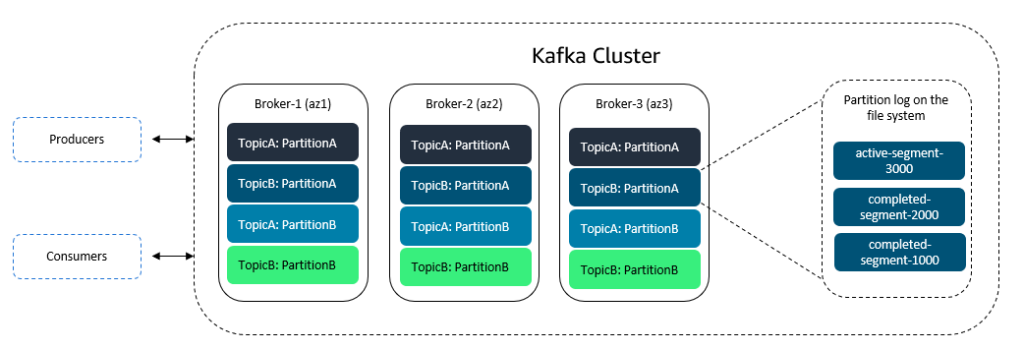
Logični tok podatkov v Kafki se imenuje a temo. Tema je razdeljena na rezultati, ki so fizične entitete, ki se uporabljajo za porazdelitev obremenitve med več primerki strežnika (posredniki), ki služijo branju in pisanju.
Particijo – označeno tudi kot particijo teme, saj je relativna na dano temo – je mogoče podvojiti, kar pomeni, da je v skupini posrednikov, ki tvorijo gručo, več kopij podatkov. Vsak izvod se imenuje a odgovori ali prijavi. Ena od teh replik, imenovana Vodja, služi kot referenca. Tam je vhodni promet sprejet za particijo teme.
Dnevnik je zaporedje segmentov dnevnika samo za dodajanje. Segmenti dnevnika vsebujejo zapise podatkov Kafka, ki se dodajo na konec dnevnika ali aktivnega segmenta.
Segmenti dnevnika so shranjeni kot navadne datoteke. V datotečnem sistemu Kafka identificira datoteko segmenta dnevnika tako, da v ime datoteke vnese odmik prvega podatkovnega zapisa, ki ga vsebuje. Odmik zapisa je preprosto monotoni indeks, ki ga je zapisu dodelil Kafka, ko je pripet v dnevnik. Datoteke segmentov dnevnika so shranjene v imeniku, namenjenem povezani particiji teme.
Ko Kafka bere podatke iz poljubnega odmika, najprej poišče segment, ki vsebuje ta odmik iz imena datoteke segmenta, nato pa specifično lokacijo zapisa v tej datoteki z uporabo indeksa odmika. Indeksi odmikov so materializirani v namenski datoteki, shranjeni skupaj z datotekami segmentov v imeniku particije teme. Je tudi timeindex iskati po časovnem žigu.
Za vsako particijo Kafka shrani tudi dnevnik sprememb vodstva v datoteko, imenovano leader-epoch-checkpoint. Ta datoteka vsebuje preslikavo vodilne epohe v startOffset epohe. Kadarkoli krmilnik Kafka izvoli novega vodjo za particijo, se ti podatki posodobijo in posredujejo vsem posrednikom. Vodilna epoha je 32-bitno, monotono naraščajoče število, ki predstavlja neprekinjeno obdobje vodstva ene particije. Označeno je na vseh Kafkovih ploščah. Naslednja koda je postavitev lokalnega pomnilnika tematskih avtomobilov in particije 0, ki vsebuje dva segmenta (0, 35):
Kafka upravlja življenjski cikel teh segmentnih datotek. Ustvari novega, ko je treba ustvariti nov segment, na primer, če trenutni segment doseže konfigurirano največjo velikost. Enega izbriše, ko je doseženo ciljno obdobje hrambe podatkov, ki jih vsebuje, ali dosežena skupna največja velikost dnevnika. Podatki so izbrisani iz repa dnevnikov in ustrezajo najstarejšim podatkom dnevnika samo za dodajanje particije teme.
KIP-405 ali večplastno shranjevanje v Apache Kafka
Zmožnost razvrščanja podatkov po stopnjah, z drugimi besedami, prenos podatkov (log, index, timeindexin leader-epoch-checkpoint) iz lokalnega datotečnega sistema v drug sistem za shranjevanje, ki temelji na pravilnikih hrambe, ki temeljijo na času in velikosti, je funkcija, zgrajena v Apache Kafka kot del KIP-405.
KIP-405 še ni v uradni različici Kafka. Amazon MSK je interno implementiral večplastno funkcijo shranjevanja poleg uradne različice Kafka 2.8.2. Amazon MSK izpostavlja to funkcijo posebej za AWS 2.8.2.stopenjski Kafkova različica. S to funkcijo lahko ločite nastavitve hrambe za lokalno in oddaljeno hrambo. Podatki na lokalni ravni se hranijo, dokler se podatki ne prekopirajo na oddaljeno raven, tudi po poteku lokalne hrambe. Podatki v oddaljeni ravni se hranijo, dokler oddaljena hramba ne poteče. KIP-405 predlaga arhitekturo, ki jo je mogoče priključiti, kar vam omogoča, da priključite oddaljeno shranjevanje po meri in ozadja za shranjevanje metapodatkov. Naslednji diagram prikazuje tri ključne komponente posrednika.

Sestavine so naslednje:
- RemoteLogManager (RLM) – Nova komponenta, ki ustreza LogManagerju za lokalno raven. Delegira kopiranje, pridobivanje in brisanje dokončanih in neaktivnih segmentov particije v vtični implementaciji RemoteStorageManager in vzdržuje ustrezne metapodatke oddaljenega segmenta dnevnika prek vtične implementacije RemoteLogMetadataManager.
- RemoteStorageManager (RSM) – Priključljiv vmesnik, ki zagotavlja življenjski cikel oddaljenih segmentov dnevnika.
- RemoteLogMetadataManager (RLMM) – Priključljiv vmesnik, ki zagotavlja življenjski cikel metapodatkov o oddaljenih segmentih dnevnika.
Kako se podatki premaknejo na oddaljeno raven za temo, ki omogoča večplastno shranjevanje
V temi s stopenjsko omogočeno shrambo vsak dokončan segment za particijo teme sproži vodjo particije, da kopira podatke v oddaljeno raven shranjevanja. Dokončani segment dnevnika je odstranjen z lokalnih diskov, ko Amazon MSK konča s premikanjem tega segmenta dnevnika na oddaljeno raven in ko izpolnjuje lokalno politiko hrambe. To sprosti lokalni prostor za shranjevanje.
Razmislimo o hipotetičnem scenariju: imate temo z eno particijo. Preden omogočite večplastno shranjevanje za to temo, obstajajo trije segmenti dnevnika. Eden od segmentov je aktiven in prejema podatke, druga dva segmenta pa sta dokončana.

Ko omogočite večplastno shranjevanje za to temo z dvodnevnim lokalnim hranjenjem in petimi dnevi celotnega hranjenja, Amazon MSK kopira segmenta dnevnika 1 in 2 v večplastno shranjevanje. Amazon MSK obdrži tudi kopijo primarnega pomnilnika segmentov 1 in 2. Aktivni segment 3 še ni primeren za kopiranje v večplastno shrambo. Na tej časovnici nobena od nastavitev hrambe še ni uporabljena za nobeno sporočilo v segmentu 1 in segmentu 2.

Po 2 dneh začnejo veljati nastavitve primarne hrambe za segment 1 in segment 2, ki ju je Amazon MSK kopiral v večplastno shrambo. Segmenta 1 in 2 zdaj potečeta iz lokalnega pomnilnika. Aktivni segment 3 še ni primeren za potek niti za kopiranje v večplastno shrambo, ker je aktiven segment.

Po 5 dneh stopijo v veljavo splošne nastavitve hrambe in Amazon MSK počisti segmenta dnevnika 1 in 2 iz večstopenjskega pomnilnika. Segment 3 še ni primeren za potek niti za kopiranje v večplastno shrambo, ker je aktiven.
Tako deluje življenjski cikel podatkov v večplastni gruči, ki omogoča shranjevanje.

Amazon MSK takoj začne premikati podatke v večplastno shrambo, takoj ko je segment zaprt. Lokalni diski se sprostijo, ko Amazon MSK konča s premikanjem tega segmenta dnevnika na oddaljeno raven in ko izpolnjuje lokalno politiko hrambe.
Kako deluje branje v temi, ki omogoča večplastno shranjevanje

Za vsako zahtevo za branje poskuša ReplicaManager obdelati zahtevo tako, da jo pošlje v ReadFromLocalLog. In če proces vrne izjemo zamik izven obsega, prenese klic branja na RemoteLogManager za branje iz večstopenjskega pomnilnika. Na poti branja RemoteStorageManager začne pridobivati podatke v kosih iz oddaljenega pomnilnika, kar pomeni, da prvih nekaj bajtov vaš uporabnik izkusi večjo zakasnitev, ko pa sistem začne lokalno medpomniti segment, vaš porabnik izkusi zakasnitev, podobno kot pri branju iz lokalno shranjevanje. Ena od prednosti tega pristopa je, da se podatki takoj postrežejo iz lokalnega medpomnilnika, če več porabnikov bere iz istega segmenta.
Če je vaš potrošnik konfiguriran za branje iz najbližje replike, lahko obstaja možnost, da potrošnik iz druge skupine potrošnikov bere isti oddaljeni segment z uporabo drugega posrednika. V tem primeru doživljajo enako zakasnitev, ki smo jo opisali prej.
zaključek
V tej objavi smo razpravljali o osnovnih komponentah funkcije večplastnega shranjevanja Amazon MSK in razložili, kako deluje življenjski cikel podatkov v gruči, ki ima omogočeno večplastno shranjevanje. Ostanite z nami za našo prihajajočo objavo, v kateri se poglobimo v najboljše prakse za določanje velikosti in izvajanje večplastne gruče, ki podpira shranjevanje, v proizvodnji.
Radi bi slišali, kako danes gradite svoje aplikacije za pretakanje podatkov v realnem času. Če šele začenjate uporabljati večplastno shranjevanje Amazon MSK, vam priporočamo, da se v praksi seznanite s smernicami, ki so na voljo v večplastno shranjevanje dokumentacije.
Če imate kakršna koli vprašanja ali povratne informacije, jih pustite v razdelku za komentarje.
O avtorjih
 Nagarjuna Koduru je glavni inženir v AWS, trenutno dela za AWS Managed Streaming For Kafka (MSK). Vodil je ekipe, ki so izdelale izdelke MSK Serverless in MSK Tiered Storage. Pred tem je vodil ekipo v Amazon JustWalkOut (JWO), ki je odgovorna za sledenje lokacijam kupcev v trgovini v realnem času. Imel je ključno vlogo pri povečanju infrastrukture za obdelavo tokov s stanjem za podporo večjim formatom shranjevanja in znižanju skupnih stroškov sistema. Zelo se zanima za obdelavo tokov, sporočanje in infrastrukturo za porazdeljeno shranjevanje.
Nagarjuna Koduru je glavni inženir v AWS, trenutno dela za AWS Managed Streaming For Kafka (MSK). Vodil je ekipe, ki so izdelale izdelke MSK Serverless in MSK Tiered Storage. Pred tem je vodil ekipo v Amazon JustWalkOut (JWO), ki je odgovorna za sledenje lokacijam kupcev v trgovini v realnem času. Imel je ključno vlogo pri povečanju infrastrukture za obdelavo tokov s stanjem za podporo večjim formatom shranjevanja in znižanju skupnih stroškov sistema. Zelo se zanima za obdelavo tokov, sporočanje in infrastrukturo za porazdeljeno shranjevanje.
 Masudur Rahaman Sayem je arhitekt pretočnih podatkov pri AWS. Sodeluje s strankami AWS po vsem svetu pri oblikovanju in izgradnji arhitektur za pretakanje podatkov za reševanje resničnih poslovnih problemov. Specializiran je za optimizacijo rešitev, ki uporabljajo pretočne podatkovne storitve in NoSQL. Sayem je zelo navdušen nad porazdeljenim računalništvom.
Masudur Rahaman Sayem je arhitekt pretočnih podatkov pri AWS. Sodeluje s strankami AWS po vsem svetu pri oblikovanju in izgradnji arhitektur za pretakanje podatkov za reševanje resničnih poslovnih problemov. Specializiran je za optimizacijo rešitev, ki uporabljajo pretočne podatkovne storitve in NoSQL. Sayem je zelo navdušen nad porazdeljenim računalništvom.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- EVM Finance. Poenoten vmesnik za decentralizirane finance. Dostopite tukaj.
- Quantum Media Group. IR/PR ojačan. Dostopite tukaj.
- PlatoAiStream. Podatkovna inteligenca Web3. Razširjeno znanje. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/deep-dive-on-amazon-msk-tiered-storage/
- :ima
- : je
- :kje
- $GOR
- 1
- 100
- 8
- 9
- a
- sposobnost
- O meni
- sprejeta
- čez
- aktivna
- dodano
- Naslov
- Prednosti
- po
- vsi
- Dovoli
- Prav tako
- Amazon
- Amazon Web Services
- an
- in
- Še ena
- kaj
- Apache
- Apache Kafka
- aplikacije
- uporabna
- pristop
- Arhitektura
- SE
- AS
- dodeljena
- povezan
- At
- Na voljo
- AWS
- temeljijo
- BE
- ker
- BEST
- najboljše prakse
- Broken
- posrednik
- posredniki
- varovalni
- izgradnjo
- Building
- zgrajena
- poslovni
- vendar
- by
- klic
- se imenuje
- CAN
- avtomobili
- primeru
- Spremembe
- zaprto
- Grozd
- Koda
- komentarji
- dokončanje
- Končana
- komponenta
- deli
- računalništvo
- koncepti
- zaključuje
- konfigurirano
- Razmislite
- premislekov
- Potrošnik
- Potrošniki
- Vsebuje
- neprekinjeno
- krmilnik
- Core
- Ustrezno
- ustreza
- strošek
- ustvaril
- ustvari
- Trenutna
- Trenutno
- po meri
- Stranke, ki so
- datum
- Dnevi
- namenjen
- globoko
- globok potop
- dostop delegat
- opisano
- Oblikovanje
- imenovani
- drugačen
- razpravlja
- razpravljali
- distribuirati
- porazdeljena
- porazdeljeno računalništvo
- ne
- navzdol
- vsak
- učinek
- izvoljeni
- upravičeni
- omogočajo
- omogočena
- omogočanje
- konec
- inženir
- subjekti
- epoha
- Eter (ETH)
- Tudi
- Tudi vsak
- izjema
- izkušnje
- Doživetja
- potekel
- razložiti
- Pojasni
- Feature
- povratne informacije
- Nekaj
- file
- datoteke
- prva
- pet
- po
- sledi
- za
- iz
- funkcionalnost
- Osnove
- pridobivanje
- dana
- Globalno
- skupina
- Navodila
- Smernice
- hands-on
- Imajo
- he
- slišati
- več
- Kako
- HTML
- HTTPS
- identificira
- if
- ponazarja
- takoj
- vpliv
- Izvajanje
- izvajali
- in
- V drugi
- narašča
- Indeks
- indekse
- Infrastruktura
- primer
- takoj
- obresti
- vmesnik
- notranji
- interno
- v
- IT
- ITS
- Revija
- jpg
- samo
- kafka
- Keen
- Ključne
- večja
- Latenca
- postavitev
- Vodja
- Vodstvo
- pustite
- Led
- življenski krog
- obremenitev
- lokalna
- lokalno
- kraj aktivnosti
- Lokacije
- prijavi
- logično
- POGLEDI
- ljubezen
- vzdržuje
- upravlja
- upravlja
- kartiranje
- označeno
- max
- pomeni
- ustreza
- sporočil
- sporočanje
- metapodatki
- Meritve
- morda
- monitor
- premaknjeno
- premikanje
- več
- Ime
- potrebe
- Niti
- Novo
- niti
- zdaj
- Številka
- of
- Uradni
- odmik
- najstarejši
- on
- ONE
- optimizacijo
- or
- Ostalo
- naši
- ven
- več
- Splošni
- del
- strastno
- pot
- performance
- Obdobje
- fizično
- ključno
- platon
- Platonova podatkovna inteligenca
- PlatoData
- igral
- prosim
- vključiti
- politike
- politika
- možnost
- Prispevek
- vaje
- prej
- primarni
- , ravnateljica
- Predhodna
- Težave
- Postopek
- obravnavati
- proizvodnja
- Izdelki
- predlaga
- zagotavlja
- Dajanje
- vprašanja
- območje
- dosegel
- Doseže
- Preberi
- reading
- resnični svet
- v realnem času
- podatki v realnem času
- realtime
- prejema
- Priporočamo
- priporočeno
- zapis
- evidence
- zmanjšanje
- besedilu
- redni
- relativna
- daljinsko
- Odstranjeno
- odgovori
- podvojeno
- predstavlja
- zahteva
- tisti,
- odgovorna
- zadrževanje
- vrne
- vloga
- tek
- Enako
- skaliranje
- Scenarij
- Oddelek
- Seek
- Segment
- segmentih
- pošiljanja
- ločena
- Zaporedje
- Serija
- služijo
- Brez strežnika
- služi
- Storitve
- nastavitve
- več
- Podoben
- preprosto
- sam
- Velikosti
- rešitve
- SOLVE
- nekaj
- Kmalu
- Vesolje
- specializirano
- specifična
- začel
- začne
- bivanje
- shranjevanje
- trgovina
- shranjeni
- trgovine
- tok
- pretakanje
- kasneje
- taka
- podpora
- sistem
- Bodite
- ciljna
- skupina
- Skupine
- da
- O
- Njih
- POTEM
- Tukaj.
- te
- jih
- ta
- 3
- skozi
- živali
- čas
- časovnica
- Časovni žig
- do
- danes
- vrh
- temo
- Teme
- Skupaj za plačilo
- Sledenje
- Prometa
- prenos
- dva
- osnovni
- razumeli
- dokler
- prihajajoče
- posodobljeno
- uporaba
- Rabljeni
- uporabo
- različica
- zelo
- we
- web
- spletne storitve
- kdaj
- kadar koli
- ki
- z
- besede
- delo
- deluje
- deluje
- bi
- pisati
- še
- jo
- Vaša rutina za
- zefirnet