Foto: Natalija Vaitkevič
Federated Learning (FL) je pristop strojnega učenja, ki omogoča usposabljanje modela v več decentraliziranih napravah ali institucijah, ne da bi bilo treba podatke centralizirati na enem strežniku. Uporablja se v več panogah, od tipkovnic mobilnih naprav do avtonomnih vozil do naftnih ploščadi. Še posebej je uporaben v zdravstveni industriji, kjer gre za občutljive podatke bolnikov in je treba upoštevati stroge predpise za zaščito zasebnosti posameznikov. V tej objavi v spletnem dnevniku bomo razpravljali o nekaterih praktičnih korakih za izvajanje projekta združenega učenja s podatki o zdravstvenem varstvu.
Najprej je pomembno razumeti zahteve in omejitve vašega projekta. To vključuje razumevanje vrste podatkov, s katerimi boste delali, in predpisov, ki jih je treba upoštevati za zaščito zasebnosti posameznikov. Morda boste morali pridobiti tudi potrebne odobritve in dovoljenja za uporabo podatkov za vaš projekt, npr. odobritve Institucionalnega odbora za pregled (IRB).
Nato boste morali pripraviti svoje podatke. To vključuje pridobivanje podatkov iz različnih kliničnih sistemov, usklajevanje podatkov na različnih lokacijah (saj so lahko podatki različno kodirani, imajo različne formate in drugačno porazdelitev na vsaki lokaciji), označevanje podatkov (kar včasih zahteva, da zdravnik pregleda podatke in komentirati) in razdelitev podatkov na particije za usposabljanje, testiranje in validacijo. Za zagotovitev natančnih rezultatov je pomembno zagotoviti, da so podatki ustrezno uravnoteženi in reprezentativni za celotno populacijo.
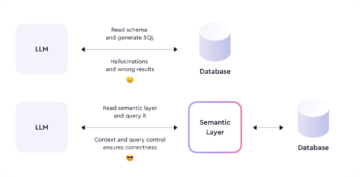
Ko so vaši podatki pripravljeni, boste morali izbrati ogrodje zveznega učenja, ki ga boste uporabljali. Na voljo je več možnosti, med drugim NVIDIA FLARE, TensorFlow Federated, PySyft, OpenFLin Flower. Vsako od teh ogrodij ima svoj nabor funkcij in zmožnosti, zato je pomembno, da izberete tisto, ki najbolje ustreza potrebam vašega projekta. Ugotovili smo, da NVIDIA FLARE zagotavlja robusten okvir, ki lahko deluje s katerim koli osnovnim okvirom ML (PyTorch, TensorFlow, sklearn itd.).
Nato boste morali vzpostaviti infrastrukturo za svoj projekt zveznega učenja. To vključuje izbiro strežnika v oblaku, na katerem boste gostili končni model in orkestrirali proces FL, ter nastavitev strežnikov na vsakem sodelujočem mestu, namestitev zahtevane programske opreme, omogočanje dostopa vašega lokalnega nabora podatkov temu strežniku in zagotavljanje, da lahko strežnik komunicira z vaš strežnik v oblaku. Odvisno od ogrodja FL, ki ste ga izbrali, boste morda morali vzpostaviti tudi varen komunikacijski kanal med lokalnimi strežniki na vsakem mestu in vašim strežnikom v oblaku, da zagotovite zasebnost in varnost podatkov.
Ko je infrastruktura postavljena, lahko začnete s procesom usposabljanja. To vključuje zagotavljanje arhitekture vašega modela strežniku v oblaku, ki bo orkestriral usposabljanje FL – pošiljanje modela sodelujočim napravam ali institucijam, kjer bodo lokalni podatki uporabljeni za usposabljanje lokalnega modela. Lokalni modeli se nato pošljejo nazaj na strežnik, kjer se združijo in uporabijo za posodobitev globalnega modela. Ta postopek se ponavlja, dokler globalni model ne konvergira na sprejemljivo raven natančnosti.
Nazadnje je pomembno oceniti delovanje modela in zagotoviti, da izpolnjuje zahteve vašega projekta. To vključuje testiranje modela na ločenem nizu podatkov ali njegovo uporabo za napovedovanje podatkov iz resničnega sveta. V mnogih primerih to vključuje tudi ponavljanje arhitekture modela, osnovnih podatkovnih nizov in/ali predprocesiranje, da se optimizira zmogljivost modela.
Ti koraki se morda zdijo zapleteni, a na srečo obstajajo podobne platforme FL Nosorogovo zdravje zaradi česar je celoten postopek preprost in brezhiben. Robustne platforme FL od konca do konca bodo poskrbele za zagotavljanje infrastrukture, zagotavljale močne varnostne zmogljivosti in podpirale vse korake zveznega projekta od predhodne obdelave podatkov prek usposabljanja modelov in analize rezultatov, z največjo prilagodljivostjo – omogočala podatkovnim znanstvenikom, da uporabljajo svoje orodja za analizo/obdelavo podatkov in okviri ML/FL po izbiri. Zaradi njih so zvezni projekti veliko bolj podobni projektom, ki uporabljajo centralizirane podatke.
Prihodnost inovacij v zdravstvu je odvisna od možnosti dostopa do velikih količin podatkov za analizo in usposabljanje modelov. Zvezno učenje je močno orodje za dostop do podatkov brez tveganja za zasebnost podatkov, zaradi česar je obetaven način za izboljšanje oskrbe pacientov in napredek na področju zdravstvene oskrbe. Če sledite tem korakom in upoštevate potrebne previdnostne ukrepe za zaščito zasebnosti bolnikov, lahko uspešno izvedete projekt združenega učenja in pozitivno vplivate na zdravstveno industrijo.
Yuval Baror je tehnični direktor in soustanovitelj Rhino Health. Ima skoraj 20 let izkušenj s programskim inženiringom, upravljanjem in startupi (vključno z ustanovitvijo startupa, ki je bil uspešno pridobljen). V zadnjem desetletju je delal na gradnji proizvodnih sistemov, ki temeljijo na AI, v treh različnih podjetjih. Uživam v globokih izzivih umetne inteligence, navdušenju nad gradnjo proizvodnih sistemov, ki imajo velik vpliv na stranke, in edinstvenem prerezu delovanja umetne inteligence v sistemih resničnega sveta.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://www.kdnuggets.com/2023/02/implement-federated-learning-project-healthcare-data.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-implement-a-federated-learning-project-with-healthcare-data
- 20 let
- a
- Sposobna
- sprejemljiv
- dostop
- dostopen
- Dostop
- natančnost
- natančna
- pridobljenih
- čez
- napredovanje
- AI
- vsi
- Dovoli
- omogoča
- zneski
- Analiza
- in
- pristop
- Arhitektura
- umetni
- Umetna inteligenca
- avtonomno
- avtonomna vozila
- Na voljo
- nazaj
- temeljijo
- počutje
- BEST
- med
- Blog
- svet
- Building
- Zmogljivosti
- ki
- primeri
- centralizirano
- izzivi
- Channel
- izbira
- Izberite
- izbiri
- klinični
- Cloud
- strežnik v oblaku
- So-ustanovitelj
- komunicirajo
- Komunikacija
- Podjetja
- kompleksna
- omejitve
- CTO
- Stranke, ki so
- datum
- zasebnost podatkov
- nabor podatkov
- desetletje
- Decentralizirano
- globoko
- Odvisno
- naprava
- naprave
- drugačen
- razpravlja
- Distribucije
- pogon
- vsak
- konec koncev
- Inženiring
- uživajte
- zagotovitev
- zagotoviti
- Celotna
- itd
- oceniti
- Vznemirjenje
- izkušnje
- Lastnosti
- Polje
- flare
- prilagodljivost
- sledili
- po
- je pokazala,
- ustanovitve
- Okvirni
- okviri
- iz
- Prihodnost
- Globalno
- Zdravje
- zdravstveno varstvo
- zdravstvena industrija
- gostitelj
- Kako
- Kako
- HTTPS
- vpliv
- izvajati
- izvajanja
- Pomembno
- izboljšanje
- in
- vključuje
- Vključno
- posamezniki
- industrij
- Industrija
- Infrastruktura
- Inovacije
- Namestitev
- Institucionalna
- Institucije
- Intelligence
- vključeni
- vključuje
- IT
- KDnuggets
- velika
- učenje
- Stopnja
- lokalna
- stroj
- strojno učenje
- Znamka
- Izdelava
- upravljanje
- več
- največja
- srečanja
- ustreza
- ML
- Mobilni
- Mobilna naprava
- Model
- modeli
- več
- več
- skoraj
- potrebno
- Nimate
- potrebe
- Nvidia
- Olje
- ONE
- Optimizirajte
- možnosti
- Da
- Splošni
- lastne
- sodelujejo
- zlasti
- preteklosti
- Bolnik
- skrb za bolnika
- podatki o bolniku
- performance
- Dovoljenja
- zdravnik
- Kraj
- Platforme
- platon
- Platonova podatkovna inteligenca
- PlatoData
- prebivalstvo
- pozitiven
- Prispevek
- močan
- Praktično
- Napovedi
- Pripravimo
- pripravljeni
- zasebnost
- Zasebnost in varnost
- Postopek
- proizvodnja
- Projekt
- projekti
- obetaven
- pravilno
- zaščito
- zagotavljajo
- zagotavlja
- zagotavljanje
- pitorha
- pravo
- resnični svet
- predpisi
- ponovi
- predstavnik
- obvezna
- Zahteve
- zahteva
- rezultat
- Rezultati
- pregleda
- tveganje
- robusten
- Znanstveniki
- brezšivne
- zavarovanje
- varnost
- izbran
- pošiljanja
- občutljiva
- ločena
- nastavite
- nastavitev
- več
- Podoben
- Enostavno
- saj
- sam
- spletna stran
- Spletna mesta
- So
- Software
- inženiring programske opreme
- nekaj
- zagon
- Ustanavljanjem
- Koraki
- strogo
- močna
- precejšen
- Uspešno
- podpora
- sistemi
- Bodite
- ob
- tensorflo
- Testiranje
- O
- njihove
- skozi
- do
- orodje
- orodja
- Vlak
- usposabljanje
- osnovni
- razumeli
- razumevanje
- edinstven
- Nadgradnja
- uporaba
- potrjevanje
- Vozila
- ki
- bo
- brez
- delo
- delal
- deluje
- svet
- let
- Vaša rutina za
- zefirnet