Bild av författare
Ett av de områden som ligger till grund för datavetenskap är maskininlärning. Så om du vill komma in i datavetenskap är förståelse av maskininlärning ett av de första stegen du måste ta.
Men var börjar man? Du börjar med att förstå skillnaden mellan de två huvudtyperna av maskininlärningsalgoritmer. Först efter det kan vi prata om individuella algoritmer som borde finnas på din prioriteringslista för att lära sig som nybörjare.
Den huvudsakliga skillnaden mellan algoritmerna är baserad på hur de lär sig.

Bild av författare
Övervakade inlärningsalgoritmer är utbildade på a märkt dataset. Denna datauppsättning fungerar som en övervakning (därav namnet) för inlärning eftersom vissa data som den innehåller redan är märkta som ett korrekt svar. Baserat på denna inmatning kan algoritmen lära sig och tillämpa den inlärningen på resten av data.
Å andra sidan, oövervakade inlärningsalgoritmer lära sig på en omärkt dataset, vilket betyder att de engagerar sig i att hitta mönster i data utan att människor ger anvisningar.
Du kan läsa mer i detalj om maskininlärningsalgoritmer och typer av lärande.
Det finns även vissa andra typer av maskininlärning, men inte för nybörjare.
Algoritmer används för att lösa två huvudsakliga distinkta problem inom varje typ av maskininlärning.
Återigen, det finns några fler uppgifter, men de är inte för nybörjare.
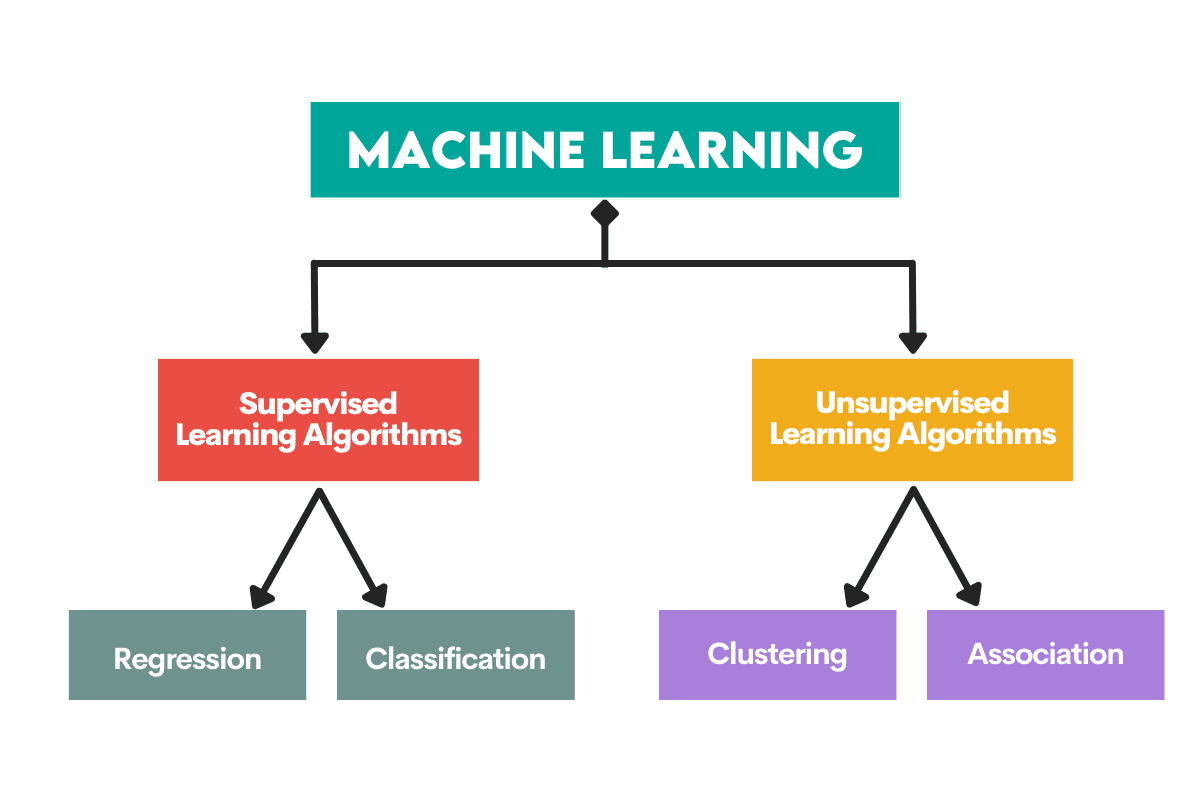
Bild av författare
Övervakade inlärningsuppgifter
Regression är uppgiften att förutsäga en numeriskt värde, Som kallas kontinuerlig utfallsvariabel eller beroende variabel. Förutsägelsen baseras på prediktorvariabeln(erna) eller oberoende variabel(er).
Tänk på att förutsäga oljepriser eller lufttemperatur.
Klassificering används för att förutsäga kategori (klass) av ingångsdata. De resultatvariabel här är kategorisk eller diskret.
Tänk på att förutsäga om posten är spam eller inte spam eller om patienten kommer att få en viss sjukdom eller inte.
Oövervakade inlärningsuppgifter
Kluster betyder dela upp data i delmängder eller kluster. Målet är att gruppera data så naturligt som möjligt. Det betyder att datapunkter inom samma kluster är mer lika varandra än datapunkter från andra kluster.
Dimensionalitetsminskning hänvisar till att minska antalet indatavariabler i en datauppsättning. Det betyder i princip reducera datasetet till väldigt få variabler samtidigt som det fångar dess väsen.
Här är en översikt över de algoritmer jag kommer att ta upp.
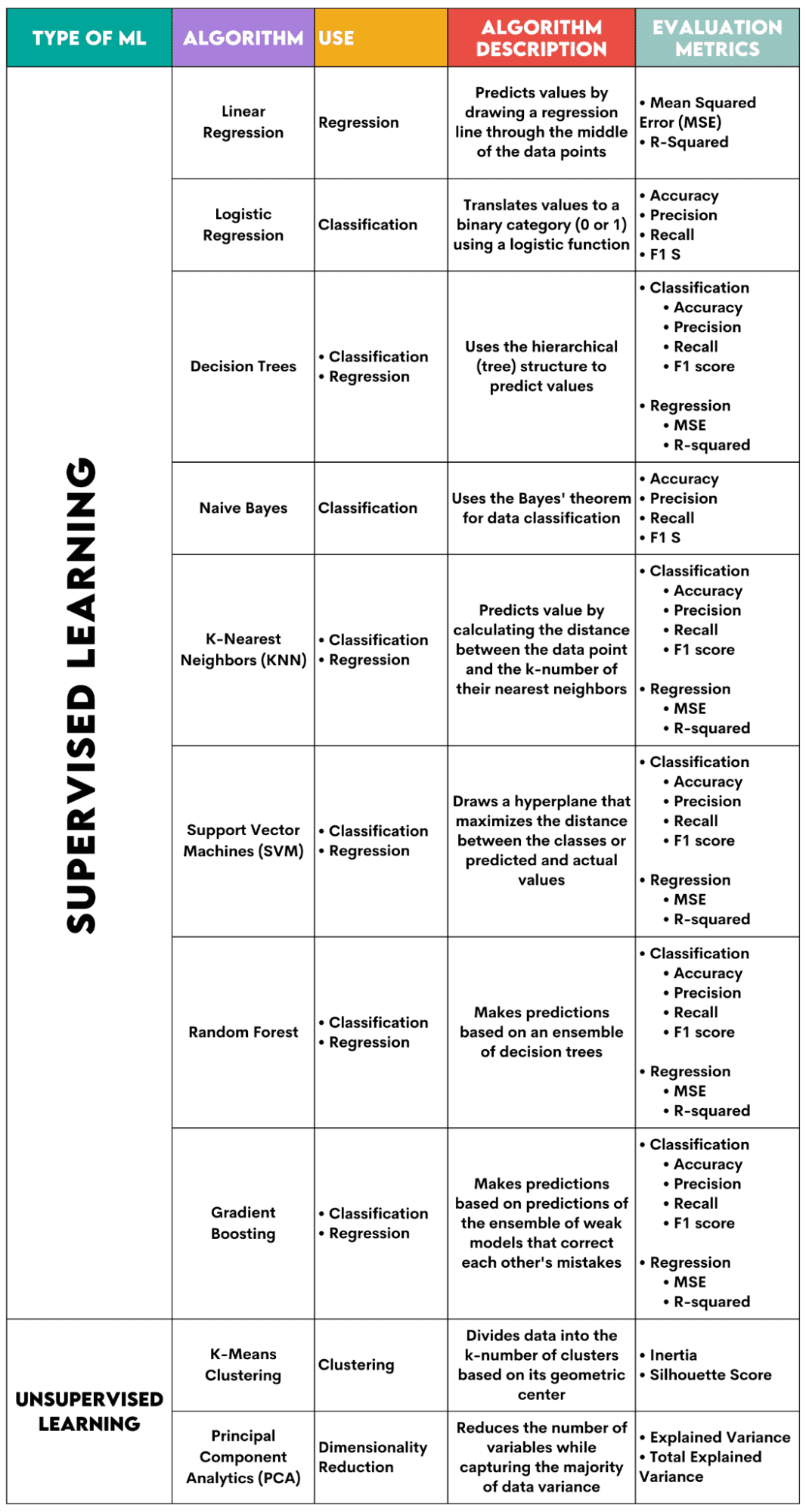
Bild av författare
Övervakade inlärningsalgoritmer
När du väljer algoritm för ditt problem är det viktigt att veta vilken uppgift algoritmen används för.
Som dataforskare kommer du förmodligen att tillämpa dessa algoritmer i Python med hjälp av scikit-learn-biblioteket. Även om det gör (nästan) allt för dig, är det tillrådligt att du åtminstone känner till de allmänna principerna för varje algoritms inre funktion.
Slutligen, efter att algoritmen har tränats, bör du utvärdera hur bra den fungerar. För det har varje algoritm några standardmått.
1. Linjär regression
Används för: Regression
Beskrivning: Linjär regression ritar en rak linje kallas en regressionslinje mellan variablerna. Denna linje går ungefär genom mitten av datapunkterna, vilket minimerar uppskattningsfelet. Den visar det förutsagda värdet av den beroende variabeln baserat på värdet av de oberoende variablerna.
Utvärderingsstatistik:
- Mean Squared Error (MSE): Representerar medelvärdet av det kvadratiska felet, varvid felet är skillnaden mellan faktiska och förutsagda värden. Ju lägre värde, desto bättre prestanda för algoritmen.
- R-kvadrat: Representerar variansprocenten för den beroende variabeln som kan förutsägas av den oberoende variabeln. För denna åtgärd bör du sträva efter att komma till 1 så nära som möjligt.
2. Logistisk regression
Används för: Klassificering
Beskrivning: Den använder a logistisk funktion för att översätta datavärdena till en binär kategori, dvs 0 eller 1. Detta görs med hjälp av tröskeln, vanligtvis satt till 0.5. Det binära resultatet gör den här algoritmen perfekt för att förutsäga binära utfall, som JA/NEJ, SANT/FALKT eller 0/1.
Utvärderingsstatistik:
- Noggrannhet: Förhållandet mellan korrekta och totala förutsägelser. Ju närmare 1, desto bättre.
- Precision: Måttet på modellnoggrannhet i positiva förutsägelser; visas som förhållandet mellan korrekta positiva förutsägelser och totala förväntade positiva utfall. Ju närmare 1, desto bättre.
- Minns: Den mäter också modellens noggrannhet i positiva förutsägelser. Det uttrycks som ett förhållande mellan korrekta positiva förutsägelser och totala observationer gjorda i klassen. Läs mer om dessa mätvärden här..
- F1-poäng: Det harmoniska medelvärdet av modellens återkallande och precision. Ju närmare 1, desto bättre.
3. Beslutsträd
Används för: Regression & Klassificering
Beskrivning: Besluts träd är algoritmer som använder den hierarkiska strukturen eller trädstrukturen för att förutsäga värde eller en klass. Rotnoden representerar hela datasetet, som sedan förgrenas till beslutsnoder, grenar och blad baserat på variabelvärdena.
Utvärderingsstatistik:
- Noggrannhet, precision, återkallelse och F1-poäng -> för klassificering
- MSE, R-kvadrat -> för regression
4. Naiva Bayes
Används för: Klassificering
Beskrivning: Detta är en familj av klassificeringsalgoritmer som använder Bayes sats, vilket betyder att de antar oberoendet mellan funktioner inom en klass.
Utvärderingsstatistik:
- Noggrannhet
- Precision
- Recall
- F1-poäng
5. K-Nearest Neighbors (KNN)
Används för: Regression & Klassificering
Beskrivning: Den beräknar avståndet mellan testdata och k-nummer för de närmaste datapunkterna från träningsdata. Testdatan tillhör en klass med ett högre antal "grannar". När det gäller regressionen är det förutsagda värdet medelvärdet av de k valda träningspoängen.
Utvärderingsstatistik:
- Noggrannhet, precision, återkallelse och F1-poäng -> för klassificering
- MSE, R-kvadrat -> för regression
6. Support Vector Machines (SVM)
Används för: Regression & Klassificering
Beskrivning: Denna algoritm ritar en hyperplan att separera olika klasser av data. Den är placerad på det största avståndet från de närmaste punkterna i varje klass. Ju högre avstånd datapunkten har från hyperplanet, desto mer tillhör den sin klass. För regression är principen liknande: hyperplan maximerar avståndet mellan de förutsagda och faktiska värdena.
Utvärderingsstatistik:
- Noggrannhet, precision, återkallelse och F1-poäng -> för klassificering
- MSE, R-kvadrat -> för regression
7. Random Forest
Används för: Regression & Klassificering
Beskrivning: Den slumpmässiga skogsalgoritmen använder en ensemble av beslutsträd, som sedan gör en beslutsskog. Algoritmens förutsägelse är baserad på förutsägelsen av många beslutsträd. Data kommer att tilldelas en klass som får flest röster. För regression är det predikterade värdet ett medelvärde av alla trädens predikterade värden.
Utvärderingsstatistik:
- Noggrannhet, precision, återkallelse och F1-poäng -> för klassificering
- MSE, R-kvadrat -> för regression
8. Gradient Boosting
Används för: Regression & Klassificering
Beskrivning: Dessa algoritmer använd en ensemble av svaga modeller, där varje efterföljande modell känner igen och korrigerar den tidigare modellens fel. Denna process upprepas tills felet (förlustfunktionen) minimeras.
Utvärderingsstatistik:
- Noggrannhet, precision, återkallelse och F1-poäng -> för klassificering
- MSE, R-kvadrat -> för regression
Oövervakade inlärningsalgoritmer
9. K-Means Clustering
Används för: Kluster
Beskrivning: Algoritmen delar upp datasetet i k-nummerkluster, vart och ett representerat av sitt tyngdpunkt eller geometriskt centrum. Genom den iterativa processen att dela upp data i ett k-antal kluster är målet att minimera avståndet mellan datapunkterna och deras klusters tyngdpunkt. Å andra sidan försöker den också maximera avståndet mellan dessa datapunkter från de andra klustrens tyngdpunkt. Enkelt uttryckt bör data som tillhör samma kluster vara så lika som möjligt och så olika som data från andra kluster.
Utvärderingsstatistik:
- Tröghet: Summan av det kvadratiska avståndet för varje datapunkts avstånd från närmaste klustercentrum. Ju lägre tröghetsvärde, desto kompaktare är klustret.
- Silhouette Score: Den mäter sammanhållningen (datas likhet inom sitt eget kluster) och separation (datas skillnad från andra kluster) av klustren. Värdet på denna poäng varierar från -1 till +1. Ju högre värde, desto mer är data väl anpassad till dess kluster, och desto sämre matchas den till andra kluster.
10. Principal Component Analytics (PCA)
Används för: Dimensionalitetsminskning
Beskrivning: Algoritmen minskar antalet variabler som används genom att konstruera nya variabler (huvudkomponenter) samtidigt som man försöker maximera den infångade variansen av datan. Med andra ord, det begränsar data till dess vanligaste komponenter utan att förlora essensen av datan.
Utvärderingsstatistik:
- Explained Variance: Procentandelen av variansen som täcks av varje huvudkomponent.
- Total Explained Variance: Procentandelen av avvikelsen som täcks av alla huvudkomponenter.
Maskininlärning är en viktig del av datavetenskap. Med dessa tio algoritmer kommer du att täcka de vanligaste uppgifterna inom maskininlärning. Naturligtvis ger denna översikt dig bara en allmän uppfattning om hur varje algoritm fungerar. Så det här är bara en början.
Nu måste du lära dig hur du implementerar dessa algoritmer i Python och löser verkliga problem. I det rekommenderar jag att du använder scikit-learn. Inte bara för att det är ett relativt lättanvänt ML-bibliotek utan också på grund av dess omfattande material på ML-algoritmer.
Nate Rosidi är datavetare och inom produktstrategi. Han är också adjungerad professor som undervisar i analys och är grundaren av StrataScratch, en plattform som hjälper datavetare att förbereda sig för sina intervjuer med riktiga intervjufrågor från toppföretag. Nate skriver om de senaste trenderna på karriärmarknaden, ger intervjuråd, delar datavetenskapliga projekt och täcker allt SQL.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/a-beginner-guide-to-the-top-10-machine-learning-algorithms?utm_source=rss&utm_medium=rss&utm_campaign=a-beginners-guide-to-the-top-10-machine-learning-algorithms
- : har
- :är
- :inte
- :var
- 1
- 10
- 5
- a
- Om oss
- noggrannhet
- faktiska
- tillägg
- rådgivning
- tillrådligt
- Efter
- LUFT
- algoritm
- algoritmer
- Alla
- nästan
- redan
- också
- Även
- an
- analytics
- och
- svara
- Ansök
- cirka
- ÄR
- AS
- delad
- utgå ifrån
- At
- försök
- genomsnitt
- baserat
- I grund och botten
- BE
- därför att
- Nybörjare
- Nybörjare
- Där vi får lov att vara utan att konstant prestera,
- som tillhör
- tillhör
- Bättre
- mellan
- binär
- grenar
- men
- by
- beräknar
- kallas
- KAN
- fångas
- Fångande
- Karriär
- Kategori
- vissa
- välja
- valda
- klass
- klasser
- klassificering
- Stäng
- närmare
- närmast
- kluster
- sammanhållning
- Gemensam
- kompakt
- Företag
- komponent
- komponenter
- konstruera
- innehåller
- korrekt
- Naturligtvis
- täcka
- omfattas
- omfattar
- datum
- datapunkter
- datavetenskap
- datavetare
- Beslutet
- beroende
- detalj
- Skillnaden
- olika
- riktningar
- Sjukdom
- avstånd
- distinkt
- skillnad
- delar upp
- skilje
- do
- gör
- gjort
- drar
- e
- varje
- LÄTTANVÄND
- anställd
- engagera
- fel
- fel
- huvudsak
- väsentlig
- Eter (ETH)
- utvärdera
- Varje
- allt
- förväntat
- förklarade
- uttryckt
- f1
- familj
- Funktioner
- få
- Fält
- finna
- Förnamn
- första stegen
- För
- skog
- grundare
- från
- fungera
- Allmänt
- skaffa sig
- ger
- Ge
- Målet
- Går
- Grupp
- styra
- sidan
- he
- hjälpa
- därav
- här.
- högre
- Hur ser din drömresa ut
- How To
- html
- HTTPS
- Människa
- i
- SJUK
- Tanken
- if
- genomföra
- med Esport
- in
- I andra
- oberoende
- oberoende
- individuellt
- tröghet
- inre
- ingång
- Intervju
- intervjufrågor
- Intervjuer
- in
- IT
- DESS
- bara
- KDnuggets
- Vet
- största
- senaste
- LÄRA SIG
- inlärning
- t minst
- lämnar
- Bibliotek
- gränser
- linje
- linjär
- Lista
- förlora
- förlust
- lägre
- Maskinen
- maskininlärning
- Maskiner
- gjord
- Huvudsida
- göra
- GÖR
- många
- marknad
- matchas
- Maximera
- maximerar
- betyda
- betyder
- betyder
- mäta
- åtgärder
- Metrics
- Mitten
- minimera
- minimerande
- ML
- ML-algoritmer
- modell
- modeller
- mer
- mest
- naiv
- namn
- naturligt
- Behöver
- grannar
- Nya
- nod
- noder
- antal
- observationer
- of
- Olja
- on
- ONE
- endast
- or
- Övriga
- Resultat
- utfall
- Översikt
- egen
- del
- Patienten
- mönster
- procentuell
- perfekt
- prestanda
- utför
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- poäng
- placerad
- positiv
- möjlig
- Precision
- förutse
- förutsagda
- förutsäga
- förutsägelse
- Förutsägelser
- Predictor
- Förbered
- föregående
- Priser
- Principal
- Principen
- Principerna
- prioritet
- förmodligen
- Problem
- problem
- process
- Produkt
- Professor
- projekt
- sätta
- Python
- frågor
- slumpmässig
- intervall
- ratio
- Läsa
- verklig
- erhåller
- känna igen
- rekommenderar
- minskar
- reducerande
- hänvisar
- om
- regression
- relativt
- upprepade
- representerade
- representerar
- REST
- rot
- s
- Samma
- Vetenskap
- Forskare
- vetenskapsmän
- scikit lära
- göra
- separat
- serverar
- in
- aktier
- skall
- visas
- Visar
- liknande
- helt enkelt
- So
- LÖSA
- några
- skräppost
- SQL
- squared
- standard
- starta
- Steg
- Fortfarande
- rakt
- Strategi
- strävar
- struktur
- senare
- sådana
- summan
- övervakning
- stödja
- SVG
- Ta
- Diskussion
- uppgift
- uppgifter
- Undervisning
- tio
- testa
- än
- den där
- Smakämnen
- deras
- sedan
- Där.
- Dessa
- de
- detta
- tröskelvärde
- Genom
- Således
- till
- alltför
- topp
- Top 10
- Totalt
- tränad
- Utbildning
- Översätt
- träd
- Träd
- Trender
- försök
- turing
- två
- Typ
- typer
- förståelse
- tills
- användning
- Begagnade
- användningar
- med hjälp av
- vanligen
- värde
- Värden
- variabel
- variabler
- vektor
- mycket
- avgivna
- vill
- we
- VÄL
- Vad
- som
- medan
- Hela
- wikipedia
- kommer
- med
- inom
- utan
- ord
- fungerar
- fungerar
- sämre
- dig
- Din
- zephyrnet