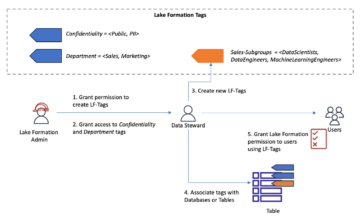
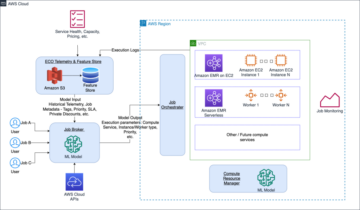
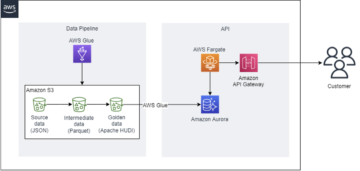
Det här är ett gästblogginlägg som skrivits tillsammans med SangSu Park och JaeHong Ahn från SOCAR.
När företag fortsätter att utöka sitt digitala fotavtryck kan vikten av databearbetning och analys i realtid inte överskattas. Förmågan att snabbt mäta och dra insikter från data är avgörande i dagens affärslandskap, där snabbt beslutsfattande är nyckeln. Med denna förmåga kan företag ligga steget före och utveckla nya initiativ som driver framgång.
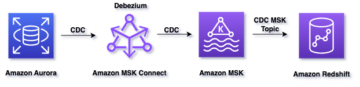
Detta inlägg är en fortsättning på Hur SOCAR byggde en strömmande datapipeline för att bearbeta IoT-data för realtidsanalys och kontroll. I det här inlägget ger vi en detaljerad översikt över strömmande meddelanden med Amazon Managed Streaming för Apache Kafka (Amazon MSK) och Amazon ElastiCache för Redis, som täcker tekniska aspekter och designöverväganden som är väsentliga för att uppnå optimala resultat.
SOCAR är det ledande koreanska mobilitetsföretaget med stark konkurrenskraft inom bildelning. SOCAR ville designa och bygga en lösning för ett nytt Fleet Management System (FMS). Detta system involverar insamling, bearbetning, lagring och analys av Internet of Things (IoT) strömmande data från olika fordonsenheter, såväl som historiska driftsdata som plats, hastighet, bränslenivå och komponentstatus.
Det här inlägget visar en lösning för SOCARs produktionsapplikation som låter dem ladda strömmande data från Amazon MSK till ElastiCache för Redis, vilket optimerar hastigheten och effektiviteten i deras databehandlingspipeline. Vi diskuterar också lösningens nyckelfunktioner, överväganden och design.
Bakgrund
SOCAR driver cirka 20,000 XNUMX bilar och planerar att inkludera andra stora fordonstyper som kommersiella fordon och budbilar. SOCAR har distribuerat enheter i bilen som fångar data med hjälp av AWS IoT Core. Dessa data lagrades sedan i Amazon Relational Databas Service (Amazon RDS). Utmaningen med detta tillvägagångssätt inkluderade ineffektiv prestanda och hög resursanvändning. Därför letade SOCAR efter specialbyggda databaser skräddarsydda för deras applikations- och användningsmönster samtidigt som de mötte de framtida kraven för SOCARs affärsmässiga och tekniska krav. Nyckelkraven för SOCAR inkluderade att uppnå maximal prestanda för dataanalys i realtid, vilket krävde lagring av data i ett datalager i minnet.
Efter noggrant övervägande valdes ElastiCache för Redis som den optimala lösningen på grund av dess förmåga att hantera komplexa regler för dataaggregering med lätthet. En av utmaningarna var att ladda data från Amazon MSK till databasen, eftersom det inte fanns någon inbyggd Kafka-kontakt och konsument tillgänglig för denna uppgift. Det här inlägget fokuserar på utvecklingen av en Kafka-konsumentapplikation som designades för att tackla denna utmaning genom att möjliggöra prestandaladdade data från Amazon MSK till Redis.
Lösningsöversikt
Att extrahera värdefulla insikter från strömmande data kan vara en utmaning för företag med olika användningsfall och arbetsbelastningar. Det är därför SOCAR byggde en lösning för att sömlöst överföra data från Amazon MSK till flera specialbyggda databaser, samtidigt som det ger användarna möjlighet att omvandla data efter behov. Med fullt hanterad Apache Kafka tillhandahåller Amazon MSK en pålitlig och effektiv plattform för att inta och bearbeta realtidsdata.
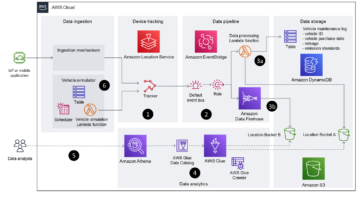
Följande figur visar ett exempel på dataflödet vid SOCAR.
Denna arkitektur består av tre komponenter:
- Strömmande data – Amazon MSK fungerar som en skalbar och pålitlig plattform för strömmande data, som kan ta emot och lagra meddelanden från en mängd olika källor, inklusive AWS IoT Core, med meddelanden organiserade i flera ämnen och partitioner
- Konsumentapplikation – Med en konsumentapplikation kan användare sömlöst överföra data från Amazon MSK till en måldatabas eller datalagring samtidigt som de definierar regler för datatransformation efter behov
- Måldatabaser – Med konsumentapplikationen kunde SOCAR-teamet ladda data från Amazon MSK till två separata databaser, som var och en betjänar en specifik arbetsbelastning
Även om det här inlägget fokuserar på ett specifikt användningsfall med ElastiCache för Redis som måldatabas och ett enda ämne som kallas gps, kan konsumentapplikationen vi beskriver hantera ytterligare ämnen och meddelanden, såväl som olika streamingkällor och måldatabaser som t.ex. Amazon DynamoDB. Vårt inlägg täcker de viktigaste aspekterna av konsumentapplikationen, inklusive dess funktioner och komponenter, designöverväganden och en detaljerad guide till kodimplementeringen.
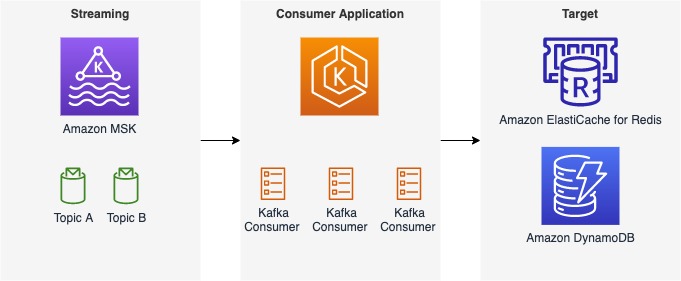
Komponenter i konsumentapplikationen
Konsumentapplikationen består av tre huvuddelar som arbetar tillsammans för att konsumera, transformera och ladda meddelanden från Amazon MSK till en måldatabas. Följande diagram visar ett exempel på datatransformationer i hanterarkomponenten.

Detaljerna för varje komponent är som följer:
- konsumenten – Detta förbrukar meddelanden från Amazon MSK och vidarebefordrar sedan meddelandena till en nedströmshanterare.
- Loader – Det är här användarna anger en måldatabas. Till exempel inkluderar SOCARs måldatabaser ElastiCache för Redis och DynamoDB.
- Handler – Det är här användare kan tillämpa regler för datatransformation på de inkommande meddelandena innan de laddas in i en måldatabas.
Funktioner i konsumentapplikationen
Denna anslutning har tre funktioner:
- skalbarhet – Den här lösningen är designad för att vara skalbar, vilket säkerställer att konsumentapplikationen kan hantera en ökande mängd data och rymma ytterligare applikationer i framtiden. Till exempel sökte SOCAR att utveckla en lösning som kan hantera inte bara aktuell data från cirka 20,000 XNUMX fordon utan också en större volym av meddelanden eftersom verksamheten och data fortsätter att växa snabbt.
- prestanda – Med denna konsumentapplikation kan användare uppnå konsekvent prestanda, även när mängden källmeddelanden och måldatabaser ökar. Applikationen stöder multithreading, vilket möjliggör samtidig databehandling och kan hantera oväntade toppar i datavolymen genom att enkelt öka beräkningsresurserna.
- Flexibilitet – Denna konsumentapplikation kan återanvändas för alla nya ämnen utan att behöva bygga hela konsumentapplikationen igen. Konsumentapplikationen kan användas för att mata in nya meddelanden med olika konfigurationsvärden i hanteraren. SOCAR distribuerade flera hanterare för att mata in många olika meddelanden. Dessutom tillåter denna konsumentapplikation användare att lägga till ytterligare målplatser. Till exempel utvecklade SOCAR initialt en lösning för ElastiCache för Redis och replikerade sedan konsumentapplikationen för DynamoDB.
Designöverväganden för konsumentapplikationen
Observera följande designöverväganden för konsumentapplikationen:
- Skala ut – En viktig designprincip för denna lösning är skalbarhet. För att uppnå detta körs konsumentapplikationen med Amazon Elastic Kubernetes-tjänst (Amazon EKS) eftersom det kan tillåta användare att öka och replikera konsumentapplikationer enkelt.
- Konsumtionsmönster – För att ta emot, lagra och konsumera data effektivt är det viktigt att utforma Kafka-ämnen beroende på budskap och konsumtionsmönster. Beroende på meddelanden som konsumeras i slutet, kan meddelanden tas emot i flera ämnen i olika scheman. Till exempel har SOCAR många olika ämnen som konsumeras av olika arbetsbelastningar.
- Specialbyggd databas – Konsumentapplikationen stöder laddning av data till flera målalternativ baserat på det specifika användningsfallet. Till exempel lagrade SOCAR IoT-data i realtid i ElastiCache för Redis för att driva instrumentpanelen och webbapplikationer i realtid, samtidigt som den senaste reseinformationen lagrades i DynamoDB som inte krävde realtidsbearbetning.
Walkthrough-översikt
Tillverkaren av denna lösning är AWS IoT Core, som skickar ut meddelanden till ett ämne som kallas gps. Måldatabasen för denna lösning är ElastiCache för Redis. ElastiCache for Red är en snabb minneslagring som tillhandahåller fördröjning på under millisekunder för att driva realtidsapplikationer i internetskala. Byggd på Redis med öppen källkod och kompatibel med Redis API:er, kombinerar ElastiCache for Redis hastigheten, enkelheten och mångsidigheten hos Redis med öppen källkod med hanterbarheten, säkerheten och skalbarheten från Amazon för att driva de mest krävande realtidsapplikationerna.
Målplatsen kan vara antingen en annan databas eller lagring beroende på användningsfall och arbetsbelastning. SOCAR använder Amazon EKS för att driva den containeriserade lösningen för att uppnå skalbarhet, prestanda och flexibilitet. Amazon EKS är en hanterad Kubernetes-tjänst för att köra Kubernetes i AWS-molnet. Amazon EKS hanterar automatiskt tillgängligheten och skalbarheten för Kubernetes kontrollplansnoder som ansvarar för schemaläggning av containrar, hantering av applikationstillgänglighet, lagring av klusterdata och andra nyckeluppgifter.
För programmeringsspråket bestämde sig SOCAR-teamet för att använda programmeringsspråket Go och använda både AWS SDK för Go och en Goroutine, en lättviktig logisk eller virtuell tråd som hanteras av Go runtime, vilket gör det enkelt att hantera flera trådar. AWS SDK för Go förenklar användningen av AWS-tjänster genom att tillhandahålla en uppsättning bibliotek som är konsekventa och bekanta för Go-utvecklare.
I följande avsnitt går vi igenom stegen för att implementera lösningen:
- Skapa en konsument.
- Skapa en lastare.
- Skapa en hanterare.
- Bygg en konsumentapplikation med konsumenten, lastaren och hanteraren.
- Implementera konsumentapplikationen.
Förutsättningar
För denna genomgång bör du ha följande:
Skapa en konsument
I det här exemplet använder vi ett ämne som heter gps, och konsumenten inkluderar en Kafka-klient som tar emot meddelanden från ämnet. SOCAR skapade en struktur och byggde en konsument (kallad NewConsumer i koden) för att göra den förlängningsbar. Med detta tillvägagångssätt kan alla ytterligare parametrar och regler enkelt läggas till.
För att autentisera med Amazon MSK använder SOCAR IAM. Eftersom SOCAR redan använder IAM för att autentisera andra resurser, som Amazon EKS, använder den samma IAM-roll (aws_msk_iam_v2) för att autentisera klienter för både Amazon MSK- och Apache Kafka-åtgärder.
Följande kod skapar konsumenten:
Skapa en lastare
Lastarfunktionen, representerad av Loader struct, är ansvarig för att ladda meddelanden till målplatsen, som i det här fallet är ElastiCache för Redis. De NewLoader funktionen initierar en ny instans av Loader struct med en logger och en Redis-klusterklient, som används för att kommunicera med ElastiCache-klustret. De redis.NewClusterClient objekt initieras med hjälp av NewRedisClient funktion, som använder IAM för att autentisera klienten för Redis-åtgärder. Detta säkerställer säker och auktoriserad åtkomst till ElastiCache-klustret. Loader-strukturen innehåller också Close-metoden för att stänga Kafka-läsaren och frigöra resurser.
Följande kod skapar en loader:
Skapa en hanterare
En hanterare används för att inkludera affärsregler och datatransformationslogik som förbereder data innan den laddas in på målplatsen. Den fungerar som en brygga mellan en konsument och en lastare. I det här exemplet är ämnesnamnet cars.gps.json, och meddelandet innehåller två nycklar, lng och lat, med datatyp Float64. Affärslogiken kan definieras i en funktion som handlerFuncGpsToRedis och tillämpade sedan enligt följande:
Bygg en konsumentapplikation med konsumenten, lastaren och hanteraren
Nu har du skapat konsumenten, lastaren och hanteraren. Nästa steg är att bygga en konsumentapplikation med hjälp av dem. I en konsumentapplikation läser du meddelanden från din stream med en konsument, omvandlar dem med en hanterare och laddar sedan omvandlade meddelanden till en målplats med en lastare. Dessa tre komponenter parametreras i en konsumentapplikationsfunktion som den som visas i följande kod:
Implementera konsumentapplikationen
För att uppnå maximal parallellitet, containeriserar SOCAR konsumentapplikationen och distribuerar den i flera pods på Amazon EKS. Varje konsumentapplikation innehåller en unik konsument, lastare och hanterare. Om du till exempel behöver ta emot meddelanden från ett enda ämne med fem partitioner, kan du distribuera fem identiska konsumentapplikationer, som var och en körs i sin egen pod. På samma sätt, om du har två ämnen med tre partitioner var, bör du distribuera två konsumentapplikationer, vilket resulterar i totalt sex poddar. Det är en bästa praxis att köra en konsumentapplikation per ämne, och antalet poddar bör matcha antalet partitioner för att möjliggöra samtidig meddelandebehandling. Podnumret kan anges i Kubernetes-distributionskonfigurationen
Det finns två steg i Dockerfilen. Det första steget är byggare, som installerar byggverktyg och beroenden, och bygger applikationen. Det andra steget är runner, som använder en mindre basbild (Alpine) och kopierar endast nödvändiga filer från byggarstadiet. Den ställer också in lämpliga användarbehörigheter och kör applikationen. Det är också värt att notera att byggarscenen använder en specifik version av Golang-bilden, medan löparscenen använder en specifik version av den alpina bilden, som båda anses vara lätta och säkra bilder.
Följande kod är ett exempel på Dockerfilen:
Slutsats
I det här inlägget diskuterade vi SOCARs tillvägagångssätt för att bygga en konsumentapplikation som möjliggör IoT-strömning i realtid från Amazon MSK för att rikta in sig på platser som ElastiCache för Redis. Vi hoppas att du tyckte att det här inlägget var informativt och användbart. Tack för att du läste!
Om författarna
 SangSu Park är chef för operationsgruppen på SOCAR. Hans passion är att fortsätta lära sig, anamma utmaningar och sträva efter ömsesidig tillväxt genom kommunikation. Han älskar att resa på jakt efter nya städer och platser.
SangSu Park är chef för operationsgruppen på SOCAR. Hans passion är att fortsätta lära sig, anamma utmaningar och sträva efter ömsesidig tillväxt genom kommunikation. Han älskar att resa på jakt efter nya städer och platser.
 JaeHong Ahn är en DevOps-ingenjör i SOCARs molninfrastrukturteam. Han är dedikerad till att främja samarbete mellan utvecklare och operatörer. Han tycker om att skapa DevOps-verktyg och är engagerad i att använda sina kodningsförmåga för att hjälpa till att bygga en bättre värld. Han älskar att laga läckra måltider som privat kock åt sin fru.
JaeHong Ahn är en DevOps-ingenjör i SOCARs molninfrastrukturteam. Han är dedikerad till att främja samarbete mellan utvecklare och operatörer. Han tycker om att skapa DevOps-verktyg och är engagerad i att använda sina kodningsförmåga för att hjälpa till att bygga en bättre värld. Han älskar att laga läckra måltider som privat kock åt sin fru.
 Younggu Yun arbetar på AWS Data Lab i Korea. Hans roll innebär att hjälpa kunder över hela APAC-regionen att nå sina affärsmål och övervinna tekniska utmaningar genom att tillhandahålla föreskrivande arkitektonisk vägledning, dela bästa praxis och bygga innovativa lösningar tillsammans.
Younggu Yun arbetar på AWS Data Lab i Korea. Hans roll innebär att hjälpa kunder över hela APAC-regionen att nå sina affärsmål och övervinna tekniska utmaningar genom att tillhandahålla föreskrivande arkitektonisk vägledning, dela bästa praxis och bygga innovativa lösningar tillsammans.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/how-socar-handles-large-iot-data-with-amazon-msk-and-amazon-elasticache-for-redis/
- : har
- :är
- :inte
- :var
- $UPP
- 000
- 1
- 10
- 100
- 15%
- 20
- 22
- 26
- 28
- 39
- a
- förmågor
- förmåga
- Able
- Om Oss
- tillgång
- rymma
- Uppnå
- uppnå
- tvärs
- åtgärder
- handlingar
- lägga till
- lagt till
- Annat
- igen
- aggregation
- framåt
- tillåter
- tillåta
- tillåter
- redan
- också
- amason
- Amazon RDS
- an
- analys
- analytics
- och
- Annan
- vilken som helst
- APAC
- Apache
- Apache Kafka
- API: er
- app
- Ansökan
- tillämpningar
- tillämpas
- Ansök
- tillvägagångssätt
- lämpligt
- cirka
- arkitektoniska
- arkitektur
- ÄR
- AS
- aspekter
- At
- autentisera
- tillstånd
- automatiskt
- tillgänglighet
- tillgänglig
- AWS
- bas
- baserat
- BE
- därför att
- innan
- BÄST
- bästa praxis
- Bättre
- mellan
- Blogg
- båda
- Ha sönder
- BRO
- föra
- mäklare
- SLUTRESULTAT
- byggare
- Byggnad
- bygger
- byggt
- inbyggd
- företag
- företag
- men
- by
- kallas
- KAN
- avbokad
- kan inte
- kapabel
- fånga
- noggrann
- bilar
- Vid
- fall
- utmanar
- utmaningar
- Städer
- klient
- klienter
- Stäng
- stängt
- cloud
- molninfrastruktur
- kluster
- koda
- Kodning
- samverkan
- samling
- kombinerar
- kommersiella
- engagerad
- kommunicera
- Kommunikation
- Företag
- företag
- kompatibel
- konkurrenskraft
- komplex
- komponent
- komponenter
- innefattar
- Compute
- konkurrent
- konfiguration
- anslutning
- övervägande
- överväganden
- anses
- konsekvent
- konsumera
- konsumeras
- Konsumenten
- konsumtion
- Behållare
- innehåller
- sammanhang
- fortsättning
- fortsätta
- kontroll
- Kärna
- beläggning
- omfattar
- skapas
- skapar
- Skapa
- kritisk
- Aktuella
- kurva
- Kunder
- instrumentbräda
- datum
- Data Analytics
- databehandling
- datalagring
- Databas
- databaser
- beslutade
- Beslutsfattande
- dedicerad
- definierade
- definierande
- krävande
- demonstrerar
- beroende
- distribuera
- utplacerade
- utplacering
- vecklas ut
- beskriva
- Designa
- utformade
- detaljerad
- detaljer
- utveckla
- utvecklade
- utvecklare
- Utveckling
- enheter
- DevOps
- olika
- digital
- diskutera
- diskuteras
- flera
- ladda ner
- dra
- driv
- grund
- varje
- lätta
- lätt
- lätt
- effektivitet
- effektiv
- effektivt
- antingen
- omfamna
- ge
- möjliggöra
- möjliggör
- möjliggör
- änden
- ingenjör
- säkerställer
- säkerställa
- Hela
- fel
- fel
- väsentlig
- Eter (ETH)
- Även
- exempel
- existerar
- Bygga ut
- inför
- Misslyckades
- bekant
- SNABB
- Funktioner
- Figur
- Filer
- hitta
- Förnamn
- FLOTTA
- flottahantering
- Flexibilitet
- flöda
- fokuserar
- efter
- följer
- Fotavtryck
- För
- hittade
- Fri
- från
- Bränsle
- fullständigt
- fungera
- framtida
- Go
- gps
- Grupp
- Väx
- Tillväxt
- Gäst
- Gästblogg
- vägleda
- styra
- hantera
- Handtag
- Arbetsmiljö
- Har
- har
- he
- huvud
- hjälpa
- hjälpa
- Hög
- hans
- historisk
- hoppas
- Hur ser din drömresa ut
- http
- HTTPS
- IAM
- identiska
- if
- bild
- bilder
- genomföra
- genomförande
- vikt
- med Esport
- in
- innefattar
- ingår
- innefattar
- Inklusive
- Inkommande
- Öka
- Ökar
- ökande
- ineffektiv
- informationen
- informativ
- Infrastruktur
- initialt
- initiativ
- innovativa
- insikter
- exempel
- Internet
- sakernas Internet
- in
- innebär
- iot
- IT
- DESS
- jpg
- json
- kafka
- Ha kvar
- Nyckel
- nycklar
- korea
- koreanska
- Kubernetes
- lab
- liggande
- språk
- Large
- större
- Latens
- ledande
- inlärning
- Nivå
- bibliotek
- lättvikt
- tycka om
- lng
- läsa in
- Lastaren
- läser in
- läge
- platser
- Logiken
- logisk
- såg
- Huvudsida
- göra
- GÖR
- hantera
- förvaltade
- ledning
- ledningssystem
- förvaltar
- hantera
- många
- karta
- Match
- maximal
- måltider
- mäta
- Möt
- möte
- meddelande
- meddelanden
- metod
- minut
- mobilitet
- mest
- multipel
- ömsesidigt
- namn
- nödvändigt för
- Behöver
- behövs
- behov
- Nya
- Nästa
- Nej
- noder
- antal
- objektet
- mål
- of
- on
- ONE
- endast
- öppen källkod
- driva
- fungerar
- drift
- operativa
- operatörer
- optimala
- optimera
- Tillbehör
- or
- Organiserad
- Övriga
- vår
- ut
- Övervinna
- Översikt
- egen
- parametrar
- Park
- reservdelar till din klassiker
- brinner
- Lösenord
- mönster
- prestanda
- behörigheter
- rörledning
- platser
- planering
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- pods
- Pong
- Inlägg
- kraft
- praktiken
- praxis
- Förbered
- förbereder
- Principen
- privat
- process
- bearbetning
- producent
- Produktion
- Programmering
- främja
- ge
- ger
- tillhandahålla
- snabbt
- snabb
- snabbt
- Raw
- rådata
- Läsa
- Läsare
- realtid
- data i realtid
- motta
- mottagna
- erhåller
- mottagande
- senaste
- region
- pålitlig
- replikeras
- representerade
- kräver
- Obligatorisk
- Krav
- resurs
- Resurser
- ansvarig
- resulterande
- Resultat
- avkastning
- Roll
- regler
- Körning
- runner
- rinnande
- kör
- Samma
- skalbarhet
- skalbar
- schemaläggning
- sDK
- sömlöst
- Sök
- Andra
- sektioner
- säkra
- säkerhet
- vald
- sänder
- separat
- serverar
- service
- Tjänster
- portion
- in
- uppsättningar
- delning
- skall
- visas
- Visar
- Liknande
- enkelhet
- enda
- SEX
- mindre
- lösning
- Lösningar
- Källa
- Källor
- specifik
- specificerade
- fart
- spikar
- Etapp
- stadier
- status
- bo
- Steg
- Steg
- förvaring
- lagra
- lagras
- ström
- streaming
- Sträng
- strävar
- stark
- framgång
- sådana
- Stöder
- system
- skräddarsydd
- Målet
- uppgift
- uppgifter
- grupp
- Teknisk
- den där
- Smakämnen
- Framtiden
- deras
- Dem
- sedan
- Där.
- därför
- Dessa
- saker
- detta
- tre
- Genom
- tid
- TLS
- till
- dagens
- tillsammans
- token
- verktyg
- ämne
- ämnen
- Totalt
- Förvandla
- Transformation
- transformationer
- transformerad
- färdas
- tur
- lastbilar
- sann
- två
- Typ
- typer
- Oväntat
- unika
- Användning
- användning
- användningsfall
- Begagnade
- Användare
- Användarnamn
- användare
- med hjälp av
- Använda
- Värdefulla
- värde
- Värden
- mängd
- olika
- vehikel
- fordon
- verifiera
- version
- Virtuell
- volym
- genomgång
- ville
- var
- we
- webb
- webbapplikationer
- VÄL
- som
- medan
- varför
- fru
- med
- utan
- Arbete
- jobba tillsammans
- fungerar
- världen
- värt
- dig
- Din
- zephyrnet