Beskrivning
En värld av revisionsdata kan vara komplex, med många utmaningar att övervinna. En av de största utmaningarna är att hantera kategoriska attribut när man hanterar datamängder. I den här artikeln kommer vi att fördjupa oss i världen av revisionsdata, avvikelsedetektering och inverkan av kodning av kategoriska attribut på modeller.
En av de största utmaningarna förknippade med anomalidetektering för granskning av data är att hantera kategoriska attribut. Det är obligatoriskt att koda kategoriska attribut eftersom modellerna inte kan tolka textinmatning. Vanligtvis görs detta med Label-kodning eller One Hot-kodning. Men i en stor datauppsättning kan One-hot-kodning leda till dålig modellprestanda på grund av dimensionalitetens förbannelse.
Inlärningsmål
-
Att förstå konceptet med revisionsdata och utmaningen
- För att utvärdera olika metoder för djup oövervakad anomalidetektering.
- För att förstå effekten av att koda kategoriska attribut på modeller som används för avvikelsedetektering i revisionsdata.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
- Vad är Auata?
- Vad är detektion av avvikelser?
- Stora utmaningar vid granskning av data
- Granskning av datauppsättningar för upptäckt av anomalier
- Kodning av kategoriattribut
- Kategoriska kodningar
- Oövervakade anomalidetekteringsmodeller
- Hur påverkar kodning av kategoriska attribut modellerna?
8.1 t-SNE-representation av datauppsättningen för bilförsäkring
8.2 t-SNE-representation av datauppsättningen för fordonsförsäkring
8.3 t-SNE-representation av datauppsättningen Vehicle Claims - Slutsats
vid är revisionsdata?
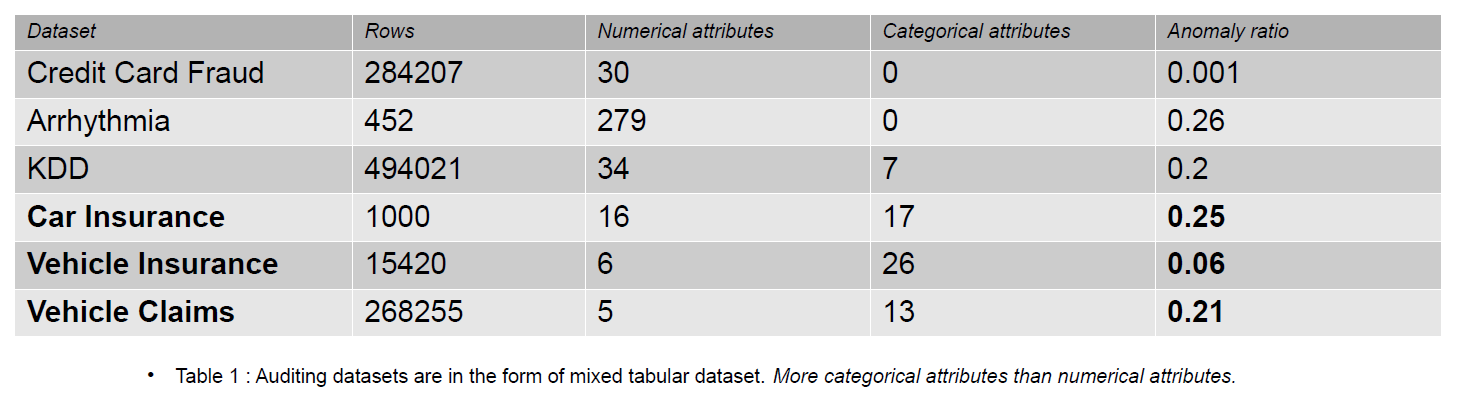
Revisionsdata kan inkludera journaler, försäkringskrav och intrångsdata för informationssystem; i den här artikeln är exemplen försäkringskrav för fordon. Försäkringsanspråk kan särskiljas från datauppsättningar för upptäckt av anomalier, t.ex. KDD, genom ett större antal kategoriska egenskaper.
Kategoriska funktioner är diskuta i vår data som kan vara antingen av typen heltal eller karaktär. Numeriska funktioner är kontinuerliga attribut i vår data som alltid är verkligt värderade. Datauppsättningar med numeriska funktioner är populära i anomalidetekteringsgemenskapen som kreditkortsbedrägeridata. De flesta av de allmänt tillgängliga datauppsättningarna innehåller färre kategoriska egenskaper än data om försäkringsskador. Kategoriska särdrag är fler än numeriska särdrag i datauppsättningarna för försäkringsskador.
Ett försäkringsanspråk inkluderar funktioner som modell, varumärke, inkomst, kostnad, emission, färg etc. Antalet kategoriska funktioner är högre i revisionsdata än i datauppsättningarna för kreditkort och KDD. Dessa datauppsättningar är riktmärken i oövervakade anomalidetekteringsmetoder. Som framgår av tabellen nedan har datauppsättningar för försäkringskrav mer kategoriska egenskaper, som är viktiga för att förstå beteendet hos bedrägliga data.
De revisionsdatauppsättningar som används för att utvärdera effekten av kategoriska kodningar är bilförsäkring, fordonsförsäkring och fordonskrav.
Vad är detektion av avvikelser?
En anomali är en observation som ligger långt bort från normala data i en datauppsättning med ett specifikt avstånd (Tröskel). När det gäller revisionsdata föredrar vi termen bedrägliga data. Anomalidetektering skiljer mellan normala och bedrägliga data med hjälp av maskininlärning eller djupinlärningsmodell. Olika metoder kan användas för avvikelsedetektering, som densitetsuppskattning, rekonstruktionsfel och klassificeringsmetoder.
- Densitetsuppskattning – Dessa metoder uppskattar normal datafördelning och klassificerar onormala data om de inte har tagits från den inlärda fördelningen.
- Rekonstruktionsfel – Rekonstruktionsfelbaserade metoder bygger på principen att normal data kan rekonstrueras med mindre förluster än avvikande data. Ju högre rekonstruktionsförlusten är ökar chansen att data är en anomali.
- Klassificeringsmetoder - Klassificeringsmetoder som Slumpmässig skog, Isolation Forest, One Class – Support Vector Machines och Local Outlier Factors kan användas för att detektera anomali. Klassificering i anomalidetektering innebär att en av klasserna identifieras som anomali. Ändå är klasserna indelade i två grupper (0 och 1) i multi-class scenariot, och klassen med färre data är den anomala klassen.
Resultatet av ovanstående metoder är anomalipoäng eller rekonstruktionsfel. Sedan måste vi besluta om en tröskel, enligt vilken vi klassificerar de onormala uppgifterna.
Stora utmaningar vid granskning av data
- Hantering av kategoriska attribut: Det är obligatoriskt att koda kategoriska attribut eftersom modellen inte kan tolka textinmatning. Så, värdena är kodade med Label-kodning eller One Hot-kodning. Men i en stor datauppsättning omvandlar One hot encoding data till ett högdimensionellt utrymme genom att öka antalet attribut. Modellen presterar dåligt pga dimensionens förbannelse.
- Välja tröskel för klassificering: Om data inte är märkt är det svårt att utvärdera modellens prestanda eftersom vi inte vet antalet anomalier som finns i datamängden. Förkunskaperna om datamängden gör det lättare att bestämma tröskeln. Låt oss säga att vi har 5 av 10 avvikande prover i vår data. Så vi kan välja tröskeln vid 50-percentilpoängen.
- Offentliga datamängder: De flesta revisionsdatauppsättningar är konfidentiella eftersom de tillhör företagsföretag och innehåller känslig och personlig information. Ett möjligt sätt att mildra sekretessproblem är att träna med syntetiska datauppsättningar (Vehicle Claims).
Granskning av datauppsättningar för upptäckt av anomalier
Försäkringskrav för fordon inkluderar information om fordonets egenskaper, som modell, märke, pris, år och bränsletyp. Den innehåller information om föraren, födelsedatum, kön och yrke. Dessutom kan kravet innehålla information om den totala kostnaden för reparation. Datauppsättningarna som används i den här artikeln är alla från en enda domän, men de varierar i antal attribut och antal instanser.
-
Datauppsättningen Vehicle Claims är stor, innehåller över 250,000 1171 rader, och dess kategoriska attribut har en kardinalitet på XNUMX. På grund av sin stora storlek lider denna datauppsättning av dimensionalitetens förbannelse.
- Vehicle Insurance datasetet är medelstort, med 15,420 151 rader och XNUMX unika kategorivärden. Detta gör det mindre benäget att lida av dimensionalitetens förbannelse.
- Datauppsättningen för bilförsäkring är liten, med etiketter och 25 % avvikande prover, och den innehåller ett liknande antal numeriska och kategoriska egenskaper. Med 169 unika kategorier lider den inte av dimensionalitetens förbannelse.
Kodning av kategoriska attribut
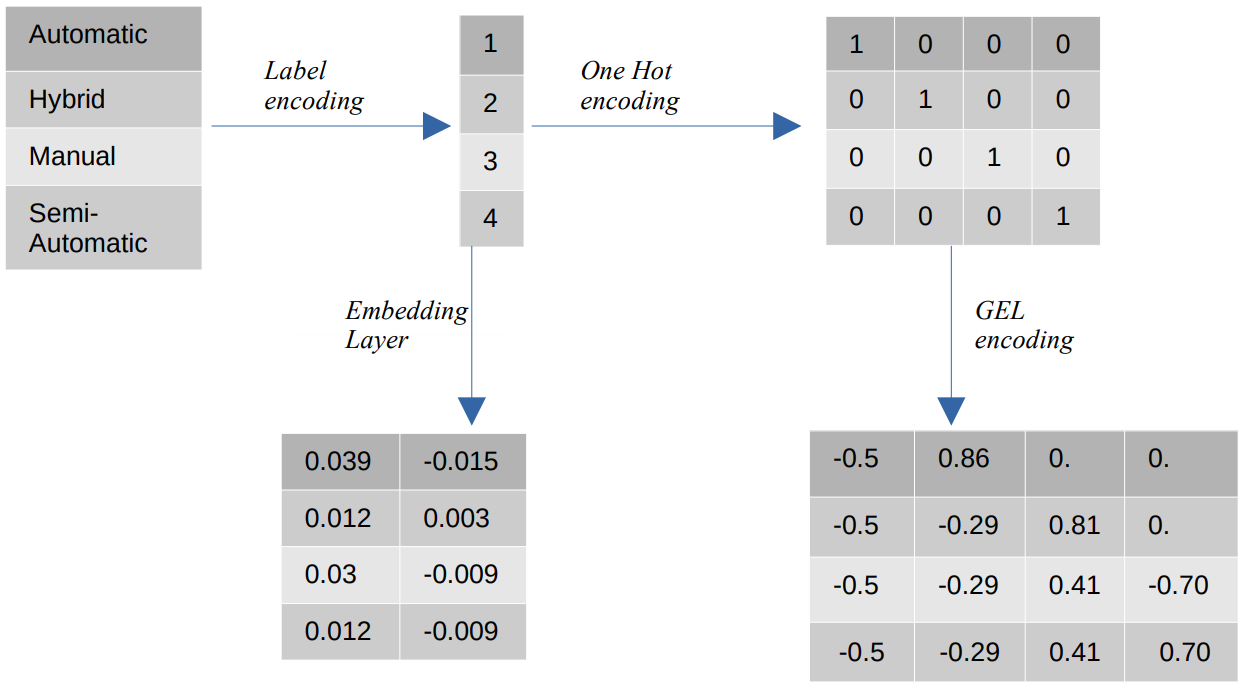
Olika kodningar av kategoriska värden
- Etikettkodning – Vid etikettkodning ersätts de kategoriska värdena med numeriska heltalsvärden mellan 1 och antalet kategorier. Etikettkodning representerar kategorierna på avsett sätt för ordningsvärden. Ändå, när egenskaperna är nominella, är representationen felaktig eftersom de kategoriska värdena inte överensstämmer med en specifik ordning.
Om vi till exempel har kategorier som Automatic, Hybrid, Manual och Semi-Automatic i en funktion, omvandlar etikettkodning dessa värden till {1: Automatic, 2: Hybrid, 3: Manual, 4:Semi-Automatic}. Den här representationen ger ingen information om de kategoriska värdena, men en representation som {0: Låg, 1: Medium, 2: Hög} ger en tydlig representation eftersom funktionsvariabeln Låg tilldelas ett lägre numeriskt värde. Därför är etikettkodning bättre för ordningsvärden men ofördelaktig för nominella värden. - En het kodning – One Hot-kodning används för att lösa problemet med nominella kodningsvärden, som omvandlar varje kategoriskt värde till en distinkt funktion i datamängden som består av binära värden. Till exempel, i fallet med fyra olika kategorier kodade som {1, 2, 3, 4}, skulle One Hot-kodning skapa nya funktioner som {Automatisk: [1,0,0,0], Hybrid: [0,1,0,0 ,0,0,1,0], Manuell: [0,0,0,1], Halvautomatisk: [XNUMX]}.
Datauppsättningens dimension beror då direkt på antalet kategorier som finns i datauppsättningen. Som ett resultat kan One Hot-kodning leda till dimensionalitetens förbannelse, vilket är en nackdel med denna kodningsmetod. - GEL-kodning – GEL-kodning är en inbäddningsteknik som kan användas i övervakade och oövervakade inlärningsmetoder. Den är baserad på principen om One Hot-kodning och kan användas för att minska dimensionaliteten av kategoriska funktioner som har kodats med One Hot-kodning.
- Inbädda lager - Ordinbäddningar ger ett sätt att använda en kompakt och tät representation där liknande ord har liknande kodningar. En inbäddning är en tät vektor av flyttalsvärden som är träningsbara parametrar. Ordinbäddningar kan variera från 8-dimensionella (för små datamängder) till 1024-dimensionella (för stora datamängder).
En högre dimensionell inbäddning kan fånga mer detaljerade relationer mellan ord, men det kräver mer data för att lära sig. Det inbäddade lagret är en uppslagstabell som konverterar varje ord som finns i matrisen till en vektor av en specifik storlek.
Oövervakade anomalidetekteringsmodeller
I den verkliga världen är data inte märkta i de flesta fall, och märkning av data är dyrt och tidskrävande. Därför kommer vi att använda oövervakade modeller för våra utvärderingar.
- SOM - The Self-Organizing Map (SOM) är en konkurrenskraftig inlärningsmetod där neuronernas vikter uppdateras konkurrenskraftigt snarare än att använda backpropagation learning. SOM består av en karta över neuroner, var och en med en viktvektor av samma storlek som ingångsvektorn. Viktvektorn initieras med slumpmässiga vikter innan träningen startar. Under träningen jämförs varje ingång med neuronerna på kartan baserat på ett avståndsmått (t.ex. euklidiskt avstånd) och mappas till Best Matching Unit (BMU), som är neuronen med minsta avstånd till ingångsvektorn.
BMU:ns vikter uppdateras med vikterna för ingångsvektorn, och de närliggande neuronerna uppdateras baserat på grannskapets radie (sigma). Eftersom neuronerna tävlar med varandra för att vara den bästa matchande enheten kallas denna process för kompetitivt lärande. I slutändan är nervcellerna för normala prover närmare än de anomala. Anomalipoäng definieras av kvantiseringsfelet, vilket är skillnaden mellan ingångsprovet och vikterna för den bäst matchande enheten. Ett högre kvantiseringsfel indikerar en högre sannolikhet för att provet är en anomali. - DAGMM – Deep Autoencoding Gaussian Mixture Model (DAGMM) är en densitetsuppskattningsmetod som antar att anomalier ligger i en region med låg sannolikhet. Nätverket är uppdelat i två delar: ett kompressionsnätverk, som används för att projicera data till lägre dimensioner med hjälp av en autokodare, och ett uppskattningsnätverk, som används för att uppskatta parametrarna för den Gaussiska blandningsmodellen. DAGMM uppskattar k antal gaussiska blandningar, där k kan vara vilket antal som helst från 1 till N (antalet datapunkter), och det antas att normala punkter ligger i en region med hög densitet, vilket innebär att sannolikheten för att provtas från en Gaussblandningen är högre för normala punkter än för anomala prover. Anomalipoäng definieras av provets uppskattade energi.
- RSRAE – Det robusta ytåterställningsskiktet för oövervakad anomalidetektering är en rekonstruktionsfelmetod som först projicerar data till en lägre dimension med hjälp av en autokodare. Den latenta representationen utsätts sedan för en ortogonal projektion på ett linjärt delrum som är robust mot extremvärden. Avkodaren rekonstruerar sedan utsignalen från det linjära delrummet. I denna metod indikerar ett högre rekonstruktionsfel en högre sannolikhet för att provet är en anomali.
- SOM-DAGMM- En självorganiserande karta (SOM) – Deep Autoencoding Gaussian Mixture Model (DAGMM) är också en densitetsuppskattningsmodell. Liksom DAGMM uppskattar den också sannolikhetsfördelningen för normala datapunkter och klassificerar en datapunkt som en anomali om den har låg sannolikhet att samplas från den inlärda fördelningen. Huvudskillnaden mellan SOM-DAGMM och DAGMM är att SOM-DAGMM inkluderar de normaliserade koordinaterna för SOM för ingångsprovet, vilket ger den saknade topologiska informationen i fallet med DAGMM till uppskattningsnätverket. Målet liknar också DAGMM genom att anomalipoäng definieras av den uppskattade energin i provet, och låg energi indikerar en högre sannolikhet för provet som en anomali.
Därefter kommer vi att ta itu med utmaningen att hantera kategoriska attribut.
Hur påverkar kodning av kategoriska attribut modellerna?
För att förstå effekten av olika kodningar på datauppsättningar kommer vi att använda t-SNE för att visualisera de lågdimensionella representationerna av data för olika kodningar. t-SNE projicerar högdimensionell data i ett lägre dimensionellt utrymme, vilket gör det lättare att visualisera. Genom att jämföra t-SNE-visualiseringarna och numeriska resultat av olika kodningar av samma datauppsättning, observeras skillnaden i de resulterande representationerna och förståelsen av inverkan av kodningen på datauppsättningen.
t-SNE representation av datauppsättningen bilförsäkring
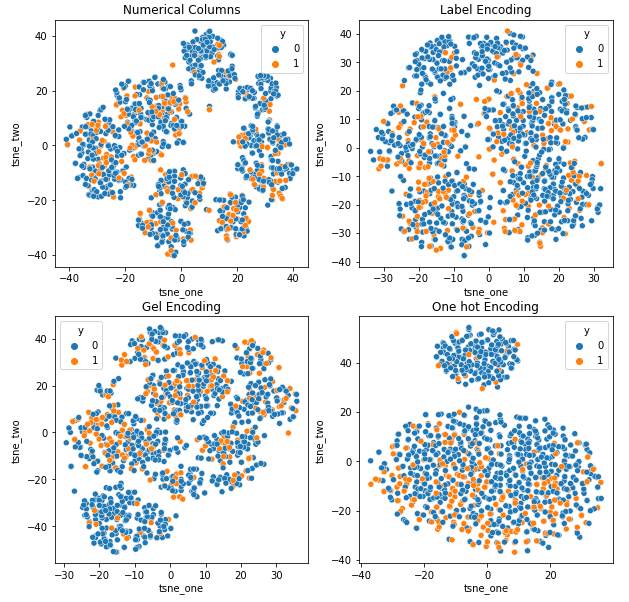
t-SNE-representation av datauppsättningen Vehicle Insurance
-
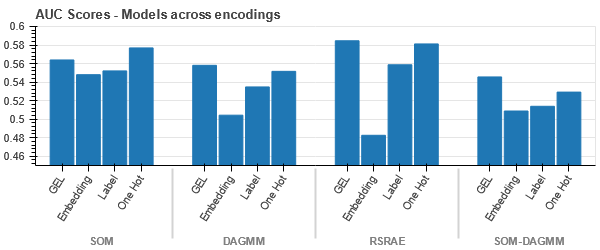
Uppgifterna ligger närmare varandra eftersom antalet rader är högre än i datauppsättningen Bilförsäkring. Det blir svårt att separera med ökad dimensionalitet i One Hot-kodning.
-
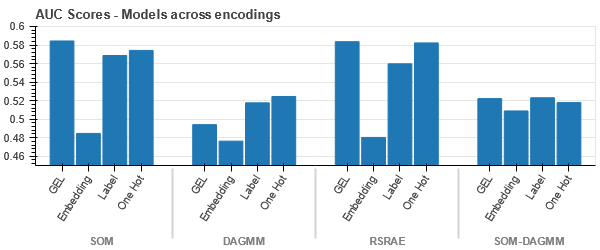
GEL-kodning är bättre än One Hot-kodning i alla fall utom DAGMM.
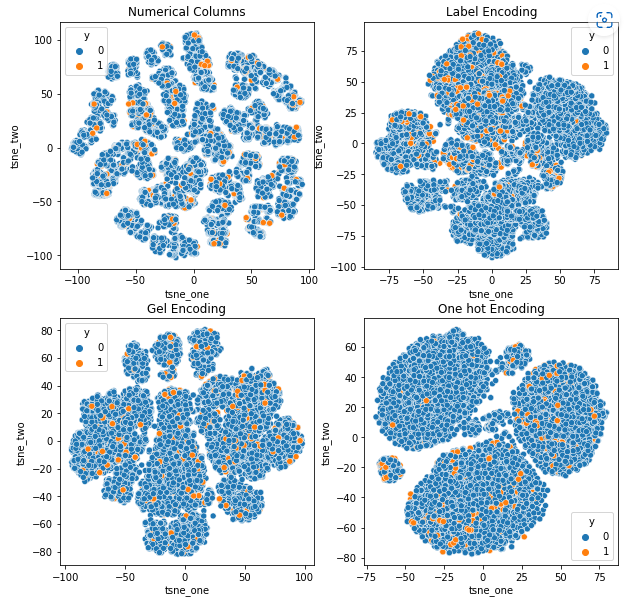
t-SNE-representation av datauppsättningen Vehicle Claims
-
Data är hårt bundna i alla fall, vilket gör det svårt att separera med ökad dimensionalitet. Detta är en av anledningarna till modellernas dåliga prestanda på grund av ökad dimensionalitet.
- SOM överträffar alla andra modeller för denna datauppsättning. Ändå är inbäddningsskiktet mer lämpligt i de flesta fall, vilket ger oss ett alternativ till kodning kategoriska attribut för upptäckt av anomalier.
Slutsats
Den här artikeln presenterar en kort översikt över granskningsdata, avvikelsedetektering och kategoriska kodningar. Det är viktigt att förstå att det är utmanande att hantera kategoriska attribut i revisionsdata. Genom att förstå effekten av att koda attributen på modeller kan vi förbättra noggrannheten för upptäckt av anomalier i datamängderna. De viktigaste tipsen från den här artikeln är:
- När datastorleken ökar är det viktigt att använda alternativa kodningsmetoder för kategoriska attribut, som GEL-kodning och inbäddningslager, eftersom One Hot-kodning är olämplig.
- En modell fungerar inte för alla datauppsättningar. För tabelluppsättningar är domänkunskap extremt viktigt.
- Valet av kodningsmetod beror på valet av modell.
Koden för utvärdering av modeller finns tillgänglig på GitHub.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- Om Oss
- ovan
- Enligt
- noggrannhet
- Dessutom
- adress
- Alla
- tillåter
- alternativ
- alltid
- analytics
- Analys Vidhya
- och
- avvikelse av anomali
- tillvägagångssätt
- Artikeln
- delad
- associerad
- antas
- attribut
- revision
- Automat
- tillgänglig
- baserat
- därför att
- blir
- innan
- Där vi får lov att vara utan att konstant prestera,
- nedan
- riktmärken
- BÄST
- Bättre
- mellan
- störst
- bunden
- varumärke
- kan inte
- fånga
- bil
- bilförsäkring
- kortet
- Vid
- fall
- kategorier
- utmanar
- utmaningar
- utmanande
- chanser
- karaktär
- val
- patentkrav
- hävdar
- klass
- klasser
- klassificering
- klassificera
- klar
- närmare
- koda
- färg
- vanligen
- samfundet
- Företag
- jämfört
- jämförande
- konkurrera
- konkurrenskraftig
- komplex
- begrepp
- konfidentialitet
- Bestående
- innehåller
- kontinuerlig
- Företag
- Pris
- skapa
- kredit
- kreditkort
- datum
- datapunkter
- datauppsättningar
- Datum
- som handlar om
- minskning
- djup
- djupt lärande
- beror
- detaljerad
- Detektering
- Bestämma
- Skillnaden
- olika
- svårt
- Dimensionera
- dimensioner
- direkt
- diskretion
- avstånd
- distinkt
- fördelning
- dividerat
- domän
- chaufför
- under
- varje
- lättare
- antingen
- energi
- fel
- fel
- uppskatta
- beräknad
- uppskattningar
- etc
- utvärdera
- utvärdering
- utvärderingar
- exempel
- exempel
- Utom
- dyra
- extremt
- inför
- faktorer
- Leverans
- Funktioner
- Förnamn
- skog
- bedrägeri
- bedräglig
- från
- Bränsle
- Kön
- Gruppens
- Arbetsmiljö
- Hög
- högre
- HET
- Men
- HTTPS
- Hybrid
- identifiera
- Inverkan
- med Esport
- förbättra
- in
- innefattar
- innefattar
- Inkomst
- ökat
- Ökar
- ökande
- pekar på
- informationen
- Informationssystem
- ingång
- försäkring
- isolering
- fråga
- problem
- IT
- Nyckel
- Vet
- kunskap
- känd
- etikett
- märkning
- Etiketter
- Large
- större
- lager
- skikt
- leda
- LÄRA SIG
- lärt
- inlärning
- lokal
- belägen
- slå upp
- förlust
- förluster
- Låg
- Maskinen
- maskininlärning
- Maskiner
- Huvudsida
- GÖR
- Framställning
- obligatoriskt
- manuell
- många
- karta
- matchande
- Matris
- betyder
- Media
- Medium
- metod
- metoder
- metriska
- minsta
- saknas
- Mildra
- blandning
- modell
- modeller
- mer
- mest
- nät
- nervceller
- Nya
- Nya funktioner
- normala
- antal
- mål
- ONE
- beställa
- Övriga
- utklassar
- Övervinna
- Översikt
- ägd
- parametrar
- del
- reservdelar till din klassiker
- prestanda
- utför
- personlig
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- poäng
- dålig
- Populära
- möjlig
- föredra
- presentera
- presenterar
- pris
- Principen
- Innan
- Sannolikheten
- Problem
- process
- yrke
- projektet
- projektdata
- Projektion
- projekt
- egenskaper
- ge
- förutsatt
- ger
- publicerade
- slumpmässig
- område
- verklig
- verkliga världen
- skäl
- återvinning
- region
- Förhållanden
- reparation
- ersättas
- representation
- representerar
- Kräver
- resultera
- resulterande
- Resultat
- robusta
- Samma
- Vetenskap
- känslig
- separat
- visas
- Sigma
- liknande
- eftersom
- enda
- Storlek
- Small
- mindre
- So
- Utrymme
- specifik
- startar
- Fortfarande
- sådana
- lider
- lämplig
- stödja
- yta
- syntetisk
- System
- bord
- takeaways
- villkor
- Smakämnen
- världen
- därför
- tröskelvärde
- tätt
- tidskrävande
- till
- Totalt
- Tåg
- Utbildning
- förstå
- förståelse
- unika
- enhet
- oövervakat lärande
- uppdaterad
- us
- användning
- värde
- Värden
- vehikel
- fordon
- vikt
- Vad
- Vad är
- som
- medan
- kommer
- ord
- ord
- Arbete
- världen
- skulle
- år
- zephyrnet