Kunder förväntar sig snabb och effektiv service från företag i dagens snabba värld. Men att tillhandahålla utmärkt kundservice kan vara avsevärt utmanande när mängden förfrågningar överstiger de mänskliga resurserna som används för att ta itu med dem. Men företag kan möta denna utmaning samtidigt som de tillhandahåller personlig och effektiv kundservice med framstegen inom generativ artificiell intelligens (generativ AI) som drivs av stora språkmodeller (LLM).
Generativa AI-chatbotar har blivit kända för sin förmåga att imitera mänskligt intellekt. Men till skillnad från uppgiftsorienterade bots använder dessa bots LLM:er för textanalys och innehållsgenerering. LLM är baserade på Transformatorarkitektur, ett neuralt nätverk för djupinlärning som introducerades i juni 2017 som kan tränas på en enorm samling omärkt text. Detta tillvägagångssätt skapar en mer mänsklig konversationsupplevelse och rymmer flera ämnen.
När detta skrivs vill företag av alla storlekar använda den här tekniken men behöver hjälp med att lista ut var de ska börja. Om du vill komma igång med generativ AI och användningen av LLM i konversations-AI, är det här inlägget för dig. Vi har inkluderat ett exempelprojekt för att snabbt implementera ett Amazon Lex bot som använder en förutbildad öppen källkod LLM. Koden inkluderar också startpunkten för att implementera en anpassad minneshanterare. Denna mekanism gör att en LLM kan återkalla tidigare interaktioner för att hålla konversationens sammanhang och takt. Slutligen är det viktigt att betona vikten av att experimentera med finjusterande uppmaningar och LLM-slumpmässighet och determinismparametrar för att få konsekventa resultat.
Lösningsöversikt
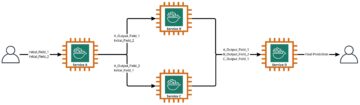
Lösningen integrerar en Amazon Lex-bot med en populär öppen källkod LLM från Amazon SageMaker JumpStart, tillgänglig via en Amazon SageMaker slutpunkt. Vi använder också LangChain, ett populärt ramverk som förenklar LLM-drivna applikationer. Slutligen använder vi en QnABot för att tillhandahålla ett användargränssnitt för vår chatbot.
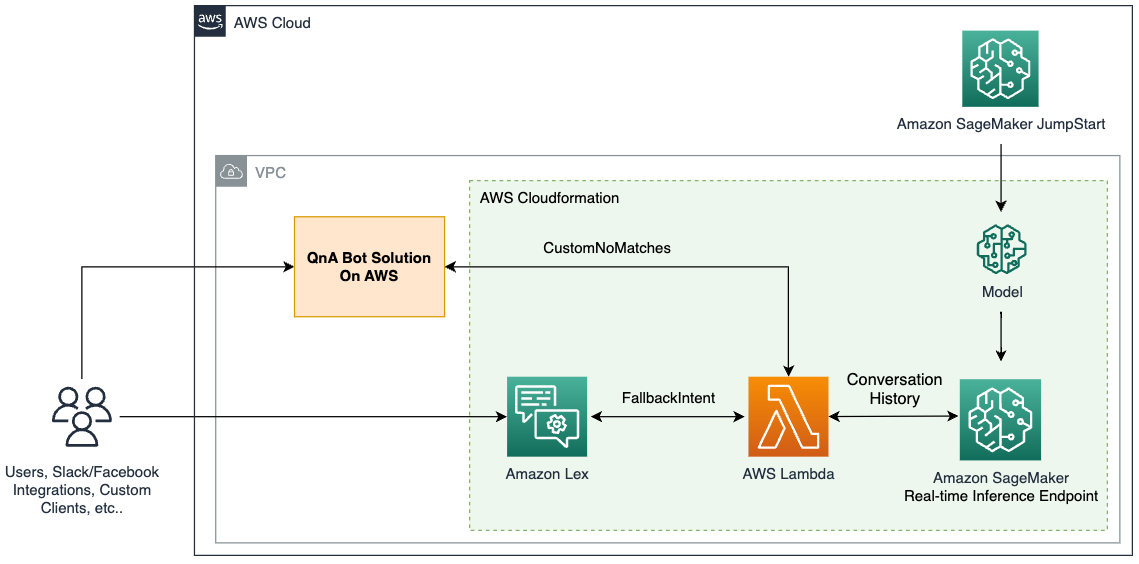
Först börjar vi med att beskriva varje komponent i föregående diagram:
- JumpStart erbjuder förutbildade modeller med öppen källkod för olika problemtyper. Detta gör att du snabbt kan börja med maskininlärning (ML). Det inkluderar FLAN-T5-XL modell, en LLM utplacerad i en behållare för djupinlärning. Den fungerar bra på olika NLP-uppgifter (natural language processing), inklusive textgenerering.
- A SageMaker slutpunkt i realtid möjliggör snabb, skalbar distribution av ML-modeller för att förutsäga händelser. Med möjligheten att integrera med Lambda-funktioner möjliggör endpointen att bygga anpassade applikationer.
- Smakämnen AWS Lambda funktionen använder förfrågningar från Amazon Lex-boten eller QnABot för att förbereda nyttolasten för att anropa SageMaker-slutpunkten med hjälp av Langkedja. LangChain är ett ramverk som låter utvecklare skapa applikationer som drivs av LLM.
- Amazon Lex V2-boten har den inbyggda
AMAZON.FallbackIntentavsiktstyp. Den utlöses när en användares input inte matchar några avsikter i boten. - QnABot är en AWS-lösning med öppen källkod för att tillhandahålla ett användargränssnitt till Amazon Lex-bots. Vi konfigurerade den med en Lambdakrok funktion för en
CustomNoMatchesobjekt, och det utlöser Lambda-funktionen när QnABot inte kan hitta ett svar. Vi antar att du redan har distribuerat det och inkluderat stegen för att konfigurera det i följande avsnitt.
Lösningen beskrivs på hög nivå i följande sekvensdiagram.
Stora uppgifter utförda av lösningen
I det här avsnittet tittar vi på de viktigaste uppgifterna som utförs i vår lösning. Hela denna lösnings projektkällkod finns tillgänglig för din referens i denna GitHub repository.
Hantera fallbacks för chatbot
Lambdafunktionen hanterar "vet ej"-svaren via AMAZON.FallbackIntent i Amazon Lex V2 och CustomNoMatches objekt i QnABot. När den utlöses tittar den här funktionen på begäran om en session och reservavsikten. Om det finns en matchning lämnar den begäran till en Lex V2-avsändare; annars använder QnABot-avsändaren begäran. Se följande kod:
Ger minne till vår LLM
För att bevara LLM-minnet i en konversation med flera svängar inkluderar Lambdafunktionen en LangChain anpassad minnesklass mekanism som använder Amazon Lex V2 Sessions API för att hålla reda på sessionsattributen med de pågående konversationsmeddelandena med flera svängar och för att ge konversationsmodellen sammanhang via tidigare interaktioner. Se följande kod:
Följande är exempelkoden vi skapade för att introducera den anpassade minnesklassen i en LangChain ConversationChain:
Snabb definition
En uppmaning till en LLM är en fråga eller ett uttalande som sätter tonen för det genererade svaret. Uppmaningar fungerar som en form av sammanhang som hjälper till att styra modellen mot att generera relevanta svar. Se följande kod:
Använder en Amazon Lex V2-session för LLM-minnesstöd
Amazon Lex V2 initierar en session när en användare interagerar med en bot. En session kvarstår över tiden såvida den inte stoppas manuellt eller tar timeout. En session lagrar metadata och applikationsspecifik data som kallas sessionsattribut. Amazon Lex uppdaterar klientapplikationer när Lambda-funktionen lägger till eller ändrar sessionsattribut. QnABot inkluderar ett gränssnitt för att ställa in och få sessionsattribut ovanpå Amazon Lex V2.
I vår kod använde vi den här mekanismen för att bygga en anpassad minnesklass i LangChain för att hålla reda på konversationshistoriken och göra det möjligt för LLM att återkalla kortsiktiga och långvariga interaktioner. Se följande kod:
Förutsättningar
För att komma igång med implementeringen måste du uppfylla följande förutsättningar:
Distribuera lösningen
Fortsätt med följande steg för att distribuera lösningen:
- Välja Starta stack för att lansera lösningen i
us-east-1Region:
- För Stapla namn, ange ett unikt stacknamn.
- För HF-modell, vi använder
Hugging Face Flan-T5-XLmodell tillgänglig på JumpStart. - För HFTask, stiga på
text2text. - Ha kvar S3BucketName i befintligt skick.
Dessa används för att hitta Amazon enkel lagringstjänst (Amazon S3) tillgångar som behövs för att distribuera lösningen och kan ändras när uppdateringar av det här inlägget publiceras.

- Erkänn förmågorna.
- Välja Skapa stack.
Det bör finnas fyra framgångsrikt skapade stackar.

Konfigurera Amazon Lex V2-boten
Det finns inget att göra med Amazon Lex V2-boten. Vår CloudFormation-mall gjorde redan det tunga lyftet.
Konfigurera QnABot
Vi antar att du redan har en befintlig QnABot utplacerad i din miljö. Men om du behöver hjälp, följ tdessa instruktioner att distribuera den.
- På AWS CloudFormation-konsolen navigerar du till huvudstacken som du distribuerade.
- På Utgångarna flik, anteckna
LambdaHookFunctionArneftersom du behöver infoga den i QnABot senare.

- Logga in på QnABot Designer User Interface (UI) som administratör.
- I Frågor UI, lägg till en ny fråga.

- Ange följande värden:
- ID -
CustomNoMatches - Fråga -
no_hits - Svar – Alla standardsvar för "vet inte"
- ID -
- Välja Advanced Open water och gå till Lambdakrok sektion.
- Ange Amazon Resource Name (ARN) för Lambda-funktionen du noterade tidigare.

- Rulla ner till botten av avsnittet och välj Skapa.
Du får ett fönster med ett framgångsmeddelande.

Din fråga är nu synlig på frågor sida.

Testa lösningen
Låt oss fortsätta med att testa lösningen. Först är det värt att nämna att vi distribuerade FLAN-T5-XL-modellen från JumpStart utan någon finjustering. Detta kan ha en viss oförutsägbarhet, vilket resulterar i små variationer i svaren.
Testa med en Amazon Lex V2-bot
Det här avsnittet hjälper dig att testa Amazon Lex V2-botintegreringen med Lambda-funktionen som anropar LLM som distribueras i SageMaker-slutpunkten.
- På Amazon Lex-konsolen, navigera till boten med titeln
Sagemaker-Jumpstart-Flan-LLM-Fallback-Bot.
Denna bot har konfigurerats för att anropa Lambda-funktionen som anropar SageMaker-slutpunkten som är värd för LLM som en reservuppsåt när inga andra avsikter matchas. - Välja Avsikter i navigeringsfönstret.

Längst upp till höger står ett meddelande: "Engelska (USA) har inte byggt ändringar."
- Välja Bygga.
- Vänta tills det är klart.
Slutligen får du ett framgångsmeddelande, som visas i följande skärmdump.

- Välja Testa.
Ett chattfönster visas där du kan interagera med modellen.

Vi rekommenderar att du utforskar det inbyggda integrationer mellan Amazon Lex bots och Amazon Connect. Och även meddelandeplattformar (Facebook, Slack, Twilio SMS) eller kontaktcenter från tredje part som använder Amazon Chime SDK och Genesys Cloud, till exempel.
Testa med en QnABot-instans
Det här avsnittet testar QnABot på AWS-integrering med Lambda-funktionen som anropar LLM som distribueras i SageMaker-slutpunkten.
- Öppna verktygsmenyn i det övre vänstra hörnet.

- Välja QnABot-klient.

- Välja Logga in som admin.

- Ange en fråga i användargränssnittet.
- Utvärdera svaret.

Städa upp
För att undvika framtida avgifter, radera resurserna som skapats av vår lösning genom att följa dessa steg:
- På AWS CloudFormation-konsolen väljer du stacken som heter
SagemakerFlanLLMStack(eller det anpassade namnet du ställt in på stacken). - Välja Radera.
- Om du distribuerade QnABot-instansen för dina tester, välj QnABot-stacken.
- Välja Radera.
Slutsats
I det här inlägget utforskade vi tillägget av öppna domänfunktioner till en uppgiftsorienterad bot som dirigerar användarens förfrågningar till en stor språkmodell med öppen källkod.
Vi uppmuntrar dig att:
- Spara konversationshistoriken till en extern beständighetsmekanism. Du kan till exempel spara konversationshistoriken till Amazon DynamoDB eller en S3-skopa och hämta den i Lambda-funktionskroken. På så sätt behöver du inte förlita dig på den interna, icke-beständiga sessionsattributhanteringen som erbjuds av Amazon Lex.
- Experimentera med sammanfattning – I flervarvskonversationer är det bra att skapa en sammanfattning som du kan använda i dina meddelanden för att lägga till sammanhang och begränsa användningen av konversationshistorik. Detta hjälper till att beskära botsessionens storlek och hålla lambdafunktionens minnesförbrukning låg.
- Experimentera med snabba variationer – Ändra den ursprungliga promptbeskrivningen som matchar dina experimentändamål.
- Anpassa språkmodellen för optimala resultat – Du kan göra detta genom att finjustera de avancerade LLM-parametrarna som slumpmässighet (
temperature) och determinism (top_p) enligt dina applikationer. Vi demonstrerade en provintegration med hjälp av en förtränad modell med exempelvärden, men har kul med att justera värdena för dina användningsfall.
I vårt nästa inlägg planerar vi att hjälpa dig att upptäcka hur du finjusterar förtränade LLM-drivna chatbots med din egen data.
Experimenterar du med LLM chatbots på AWS? Berätta mer i kommentarerna!
Resurser och referenser
Om författarna
 Marcelo silva är en erfaren tekniker som utmärker sig i att designa, utveckla och implementera banbrytande produkter. Marcelo började sin karriär på Cisco och arbetade med olika högprofilerade projekt, inklusive implementeringar av det första routingsystemet för operatörer någonsin och den framgångsrika lanseringen av ASR9000. Hans expertis sträcker sig till molnteknik, analys och produkthantering, efter att ha varit senior manager för flera företag som Cisco, Cape Networks och AWS innan han började med GenAI. Arbetar för närvarande som Conversational AI/GenAI Product Manager, Marcelo fortsätter att utmärka sig i att leverera innovativa lösningar inom olika branscher.
Marcelo silva är en erfaren tekniker som utmärker sig i att designa, utveckla och implementera banbrytande produkter. Marcelo började sin karriär på Cisco och arbetade med olika högprofilerade projekt, inklusive implementeringar av det första routingsystemet för operatörer någonsin och den framgångsrika lanseringen av ASR9000. Hans expertis sträcker sig till molnteknik, analys och produkthantering, efter att ha varit senior manager för flera företag som Cisco, Cape Networks och AWS innan han började med GenAI. Arbetar för närvarande som Conversational AI/GenAI Product Manager, Marcelo fortsätter att utmärka sig i att leverera innovativa lösningar inom olika branscher.
 Victor Red är en mycket erfaren teknolog som brinner för det senaste inom AI, ML och mjukvaruutveckling. Med sin expertis spelade han en avgörande roll i att föra Amazon Alexa till marknaderna i USA och Mexiko samtidigt som han ledde den framgångsrika lanseringen av Amazon Textract och AWS Contact Center Intelligence (CCI) till AWS Partners. Som nuvarande främsta tekniska ledare för programmet Conversational AI Competency Partners är Victor engagerad i att driva innovation och ta fram banbrytande lösningar för att möta branschens föränderliga behov.
Victor Red är en mycket erfaren teknolog som brinner för det senaste inom AI, ML och mjukvaruutveckling. Med sin expertis spelade han en avgörande roll i att föra Amazon Alexa till marknaderna i USA och Mexiko samtidigt som han ledde den framgångsrika lanseringen av Amazon Textract och AWS Contact Center Intelligence (CCI) till AWS Partners. Som nuvarande främsta tekniska ledare för programmet Conversational AI Competency Partners är Victor engagerad i att driva innovation och ta fram banbrytande lösningar för att möta branschens föränderliga behov.
 Justin Leto är Sr. Solutions Architect på Amazon Web Services med specialisering på maskininlärning. Hans passion är att hjälpa kunder att utnyttja kraften i maskininlärning och AI för att driva affärstillväxt. Justin har presenterat vid globala AI-konferenser, inklusive AWS Summits, och föreläst vid universitet. Han leder maskininlärnings- och AI-mötet i NYC. På fritiden tycker han om att segla till havs och att spela jazz. Han bor i New York City med sin fru och sin lilla dotter.
Justin Leto är Sr. Solutions Architect på Amazon Web Services med specialisering på maskininlärning. Hans passion är att hjälpa kunder att utnyttja kraften i maskininlärning och AI för att driva affärstillväxt. Justin har presenterat vid globala AI-konferenser, inklusive AWS Summits, och föreläst vid universitet. Han leder maskininlärnings- och AI-mötet i NYC. På fritiden tycker han om att segla till havs och att spela jazz. Han bor i New York City med sin fru och sin lilla dotter.
 Ryan Gomes är en data- och ML-ingenjör med AWS Professional Services Intelligence Practice. Han brinner för att hjälpa kunder att uppnå bättre resultat genom analys och maskininlärningslösningar i molnet. Utanför jobbet tycker han om att träna, laga mat och att spendera kvalitetstid med vänner och familj.
Ryan Gomes är en data- och ML-ingenjör med AWS Professional Services Intelligence Practice. Han brinner för att hjälpa kunder att uppnå bättre resultat genom analys och maskininlärningslösningar i molnet. Utanför jobbet tycker han om att träna, laga mat och att spendera kvalitetstid med vänner och familj.
 Mahesh Birardar är Sr. Solutions Architect på Amazon Web Services med specialisering på DevOps och observerbarhet. Han tycker om att hjälpa kunder att implementera kostnadseffektiva arkitekturer som skalas. Utanför jobbet tycker han om att titta på film och vandra.
Mahesh Birardar är Sr. Solutions Architect på Amazon Web Services med specialisering på DevOps och observerbarhet. Han tycker om att hjälpa kunder att implementera kostnadseffektiva arkitekturer som skalas. Utanför jobbet tycker han om att titta på film och vandra.
 Kanjana Chandren är en lösningsarkitekt på Amazon Web Services (AWS) som brinner för maskininlärning. Hon hjälper kunder att designa, implementera och hantera deras AWS-arbetsbelastningar. Utanför jobbet älskar hon att resa, läsa och umgås med familj och vänner.
Kanjana Chandren är en lösningsarkitekt på Amazon Web Services (AWS) som brinner för maskininlärning. Hon hjälper kunder att designa, implementera och hantera deras AWS-arbetsbelastningar. Utanför jobbet älskar hon att resa, läsa och umgås med familj och vänner.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- EVM Finans. Unified Interface for Decentralized Finance. Tillgång här.
- Quantum Media Group. IR/PR förstärkt. Tillgång här.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/exploring-generative-ai-in-conversational-experiences-an-introduction-with-amazon-lex-langchain-and-sagemaker-jumpstart/
- : har
- :är
- :inte
- :var
- 100
- 11
- 12
- 13
- 14
- 17
- 2017
- 27
- 8
- 9
- a
- förmåga
- Om oss
- tillgänglig
- Enligt
- Uppnå
- tvärs
- handlingar
- lägga till
- tillsats
- Dessutom
- adress
- Lägger
- avancerat
- framsteg
- Efter
- AI
- alexa
- Alla
- tillåter
- redan
- också
- amason
- amazon alexa
- Amazon Chime
- Amazon Lex
- amazontext
- Amazon Web Services
- Amazon Web Services (AWS)
- an
- analys
- analytics
- och
- svara
- svar
- vilken som helst
- api
- tillämpningar
- tillvägagångssätt
- ÄR
- konstgjord
- artificiell intelligens
- AS
- Tillgångar
- At
- attribut
- tillgänglig
- undvika
- AWS
- AWS molnformation
- AWS professionella tjänster
- Bebis
- baserat
- BE
- därför att
- varit
- innan
- börja
- Bättre
- mellan
- Bot
- botar
- Botten
- Föra
- SLUTRESULTAT
- Byggnad
- byggt
- inbyggd
- företag
- företag
- men
- by
- Ring
- Samtal
- KAN
- kapacitet
- Karriär
- fall
- Centrum
- Centers
- kedja
- utmanar
- utmanande
- byta
- Förändringar
- avgifter
- chatbot
- chatbots
- Klämta
- Välja
- Cisco
- Stad
- klass
- klar
- klient
- cloud
- MOLNTEKNIK
- koda
- engagerad
- Företag
- fullborda
- komponent
- konferenser
- konfiguration
- konsekvent
- Konsol
- konsumtion
- kontakta
- kontaktcenter
- Behållare
- innehåll
- sammanhang
- fortsätter
- Konversation
- konversera
- konversations AI
- konversationer
- kokning
- Corner
- kostnadseffektiv
- skapa
- skapas
- skapar
- Aktuella
- För närvarande
- beställnings
- kund
- Kundservice
- Kunder
- allra senaste
- datum
- djup
- djupt lärande
- Standard
- leverera
- demonstreras
- distribuera
- utplacerade
- utplacering
- distributioner
- beskriven
- beskrivning
- designer
- design
- detaljer
- utvecklare
- utveckla
- Utveckling
- DevOps
- DICT
- DID
- rikta
- Upptäck
- do
- dokumenterat
- gör
- inte
- donation
- inte
- ner
- driv
- drivande
- varje
- effektiv
- annars
- anställd
- möjliggöra
- möjliggör
- uppmuntra
- Slutpunkt
- ingenjör
- ange
- Hela
- enheter
- med titeln
- Miljö
- väsentlig
- Eter (ETH)
- händelse
- händelser
- NÅGONSIN
- utvecklas
- exempel
- excel
- utmärkt
- befintliga
- förvänta
- erfarenhet
- erfaren
- Erfarenheter
- expertis
- utforskas
- Utforska
- sträcker
- extern
- Ansikte
- familj
- SNABB
- snabb
- Slutligen
- hitta
- Förnamn
- fitness
- följer
- efter
- För
- formen
- format
- fyra
- Ramverk
- vänliga
- vänner
- från
- Uppfylla
- kul
- fungera
- funktioner
- framtida
- vunnits
- generera
- genereras
- generera
- generering
- generativ
- Generativ AI
- skaffa sig
- Välgörenhet
- Go
- Tillväxt
- Handtag
- händer
- sele
- Har
- har
- he
- tung
- tunga lyft
- hjälpa
- hjälp
- hjälpa
- hjälper
- här.
- Hög
- hög profil
- Markera
- höggradigt
- vandring
- hans
- historisk
- historia
- värd
- värd
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- humant
- Human Resources
- if
- genomföra
- genomföra
- vikt
- in
- ingår
- innefattar
- Inklusive
- industrier
- industrin
- informationen
- initierar
- Innovation
- innovativa
- ingång
- ingångar
- förfrågningar
- exempel
- integrera
- integrerar
- integrering
- Intelligens
- uppsåt
- interagera
- interaktion
- interaktioner
- interagerar
- Gränssnitt
- inre
- in
- introducerade
- införa
- Beskrivning
- anropar
- IT
- DESS
- sammanfogning
- jpg
- json
- juni
- Justin
- Ha kvar
- Nyckel
- nycklar
- Vet
- känd
- språk
- Large
- senare
- senaste
- lansera
- ledare
- Leads
- inlärning
- vänster
- Lets
- Nivå
- lyft
- tycka om
- BEGRÄNSA
- LINK
- Lista
- Bor
- läsa in
- lång sikt
- se
- du letar
- UTSEENDE
- älskar
- Låg
- Maskinen
- maskininlärning
- Huvudsida
- större
- göra
- hantera
- ledning
- chef
- hantera
- manuellt
- Marknader
- massiv
- Match
- matchas
- Maj..
- mekanism
- Möt
- Meetup
- Minne
- nämner
- Meny
- meddelande
- meddelanden
- meddelandehantering
- metadata
- Mexico
- ML
- modell
- modeller
- modifiera
- mer
- Filmer
- namn
- Som heter
- Natural
- Naturligt språk
- Naturlig språkbehandling
- Navigera
- Navigering
- Behöver
- behövs
- behov
- nät
- nätverk
- neural
- neurala nätverk
- Nya
- New York
- new york city
- Nästa
- nlp
- Nej
- Notera
- noterade
- inget
- nu
- NYC
- objektet
- få
- of
- sänkt
- erbjuds
- Erbjudanden
- on
- pågående
- öppen källkod
- öppning
- optimala
- or
- ursprungliga
- Övriga
- annat
- vår
- ut
- utfall
- utanför
- över
- egen
- Fred
- sida
- panelen
- parametrar
- partner
- brinner
- brinner
- Tidigare
- utfört
- utför
- persistens
- kvarstår
- personlig
- svängbara
- Oformatterad text
- Planen
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- spelat
- i
- Punkt
- Populära
- Inlägg
- kraft
- maskinens kraft
- drivs
- praktiken
- förutsäga
- Förbered
- förutsättningar
- presenteras
- föregående
- tidigare
- Principal
- Problem
- bearbetning
- Produkt
- produktledning
- produktchef
- Produkter
- professionell
- Program
- projektet
- projekt
- ge
- förutsatt
- ger
- tillhandahålla
- publicerade
- syfte
- Python
- QnABot
- kvalitet
- fråga
- frågor
- Snabbt
- snabbt
- slumpmässighet
- Läsning
- realtid
- rekommenderar
- region
- relevanta
- förlita
- begära
- förfrågningar
- resurs
- Resurser
- respons
- svar
- resulterande
- Resultat
- avkastning
- återgår
- höger
- Roll
- rulla ut
- rutter
- routing
- s
- sagemaker
- segling
- Save
- säger
- skalbar
- Skala
- sDK
- §
- sektioner
- se
- Val
- SJÄLV
- senior
- Sekvens
- serverar
- service
- Tjänster
- session
- sessioner
- in
- uppsättningar
- flera
- hon
- kortsiktigt
- skall
- visas
- signera
- signifikant
- Enkelt
- Storlek
- storlekar
- slak
- SMS
- Mjukvara
- mjukvaruutveckling
- lösning
- Lösningar
- några
- Källa
- källkod
- spetsen
- specifik
- Spendera
- stapel
- Stacks
- starta
- igång
- Starta
- .
- Steg
- slutade
- förvaring
- lagrar
- framgång
- framgångsrik
- Framgångsrikt
- sådana
- SAMMANFATTNING
- Toppmöten
- system
- uppgifter
- tech
- teknolog
- Teknologi
- tala
- mall
- testa
- Testning
- tester
- textgenerering
- den där
- Smakämnen
- deras
- Dem
- Där.
- Dessa
- tredje part
- detta
- Genom
- tid
- Timed
- till
- dagens
- TON
- verktyg
- topp
- ämnen
- mot
- spår
- tränad
- triggas
- Twilio
- Typ
- typer
- ui
- unika
- Universitet
- till skillnad från
- Uppdateringar
- us
- Användning
- användning
- Begagnade
- Användare
- Användargränssnitt
- användningar
- med hjälp av
- Värden
- variabler
- olika
- via
- synlig
- volym
- vill
- tittar
- Sätt..
- we
- webb
- webbservice
- VÄL
- när
- medan
- VEM
- fru
- med
- utan
- Arbete
- arbetade
- arbetssätt
- världen
- värt
- skrivning
- york
- dig
- Din
- zephyrnet