บทนำ
อัตราการคลิกผ่าน (CTR) เป็นตัวชี้วัดสำคัญที่แสดงเปอร์เซ็นต์ของผู้เข้าชมที่คลิกโฆษณา โดยให้ข้อมูลเชิงลึกเกี่ยวกับประสิทธิภาพของโฆษณา ธุรกิจอาจได้รับประโยชน์อย่างมากจากการศึกษาอัตราการคลิกผ่านเมื่อพัฒนากลยุทธ์การโฆษณา ด้วยการวิเคราะห์สถิติ CTR บริษัทต่างๆ อาจพิจารณาว่าโฆษณาโดนใจกลุ่มประชากรเป้าหมายและสร้างการมีส่วนร่วมมากขึ้นหรือไม่ ด้วยการจัดสรรเงินให้กับการโฆษณาที่มีประสิทธิภาพสูงสุดและปรับเปลี่ยนกลยุทธ์การตลาดเพื่อเพิ่ม CTR พวกเขาจึงสามารถเพิ่มประสิทธิภาพแคมเปญโฆษณาของตนผ่านตัวแยกประเภทฟอเรสต์แบบสุ่ม วัตถุประสงค์หลักของการคาดการณ์ CTR โฆษณาคือ:
- เพิ่มประสิทธิภาพแคมเปญโฆษณาโดยระบุว่าโฆษณาใดน่าจะส่งผลให้อัตราการคลิกผ่านสูงขึ้น
- เพิ่มรายได้จากโฆษณาให้สูงสุดโดยการวางโฆษณาที่มีประสิทธิภาพสูงในตำแหน่งสำคัญอย่างมีกลยุทธ์
- ประสิทธิภาพโฆษณาอาจได้รับการปรับปรุงโดยการระบุโฆษณาที่มีประสิทธิภาพต่ำและดำเนินการตามขั้นตอนที่เหมาะสมเพื่อปรับปรุงโฆษณา
ตามเป้าหมายเหล่านี้ เราจะใช้ Random Forest เพื่อพัฒนาแบบจำลองที่สามารถประมาณได้อย่างแม่นยำว่าผู้ใช้จะคลิกโฆษณาโดยพิจารณาจากอายุของผู้ใช้ เวลาในแต่ละวันที่ใช้บนไซต์ การใช้อินเทอร์เน็ตรายวัน และเพศ บทความนี้จะแนะนำคุณในการคาดเดาว่าผู้ใช้จะคลิกโฆษณาโดยใช้ Random Forest Classifier หรือไม่ ตอนนี้เรามาทำนายตามขั้นตอนในบทความกันดีกว่า
บทความนี้เผยแพร่โดยเป็นส่วนหนึ่งของไฟล์ Blogathon วิทยาศาสตร์ข้อมูล.
สารบัญ
ขั้นตอนที่ 1: นำเข้าไลบรารี
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import plotly.graph_objects as go
import plotly.express as px
import plotly.io as pio
pio.templates.default = "plotly_white"เรานำเข้าไลบรารี 'plotly' เพื่อความสะดวก การสร้างภาพข้อมูล. โมดูล 'graph_objects' ใช้เพื่อสร้างการแสดงภาพเชิงโต้ตอบและปรับแต่งได้ รวมถึงแปลง แผนภูมิ และกราฟ โมดูล 'ด่วน' มอบอินเทอร์เฟซระดับสูงเพื่อสร้างการแสดงภาพข้อมูลโดยใช้โค้ดน้อยลงและอินเทอร์เฟซที่เรียบง่ายยิ่งขึ้น โมดูล 'io' ใช้เพื่อกำหนดการตั้งค่าต่างๆ ที่เกี่ยวข้องกับการแสดงภาพ เช่น เทมเพลต ธีม และตัวเลือกการเรนเดอร์ เราเรียก 'RandomForestClassifier' เพื่อสร้างแบบจำลองและคาดการณ์ CTR โฆษณา และบรรทัดสุดท้ายของโค้ดจะตั้งค่าเทมเพลตเริ่มต้นสำหรับการแสดงภาพ Plotly ให้เป็น "plotly_white" ซึ่งเป็นโทนสีอ่อนหรือพื้นหลังสีขาวที่กำหนดไว้ล่วงหน้า
ขั้นตอนที่ 2: อ่านข้อมูล
ความพร้อมใช้งานของข้อมูลเป็นสิ่งสำคัญสำหรับงานวิเคราะห์ข้อมูล ชุดข้อมูลที่มีลักษณะและตัวแปรทั้งหมดที่จำเป็นสำหรับงานนั้นเป็นสิ่งสำคัญ ชุดข้อมูลที่ Gaurav Dutta อัปโหลด Kaggle เหมาะสมในกรณีนี้โดยเฉพาะ อย่างไรก็ตาม ฉันใส่มันลงใน GitHub ของฉันเพื่อทำให้กระบวนการวิเคราะห์ง่ายขึ้น
url = "https://raw.githubusercontent.com/ataislucky/Data-Science/main/dataset/ad_ctr.csv"
data = pd.read_csv(url)
print(data.head())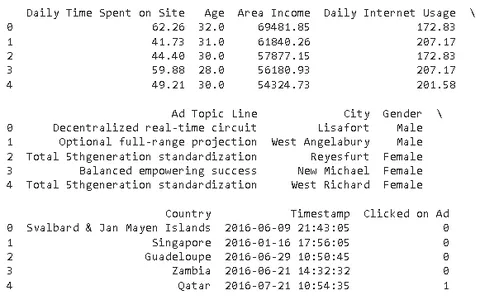
ชุดข้อมูล ov
ด้านล่างนี้คือคุณสมบัติทั้งหมดในชุดข้อมูล:
- เวลารายวันที่ใช้บนเว็บไซต์ หมายถึงช่วงเวลารายวันของผู้ใช้บนเว็บไซต์
- อายุ หมายถึงอายุของผู้ใช้
- รายได้พื้นที่ หมายถึงรายได้เฉลี่ยในพื้นที่ของผู้ใช้
- การใช้อินเทอร์เน็ตรายวัน หมายถึงการใช้งานอินเทอร์เน็ตในแต่ละวันของผู้ใช้
- บรรทัดหัวข้อโฆษณา หมายถึงชื่อโฆษณา
- เมือง หมายถึงเมืองของผู้ใช้บริการ
- เพศ หมายถึง เพศของผู้ใช้
- ประเทศ หมายถึงประเทศของผู้ใช้
- timestamp หมายถึงเวลาที่ผู้ใช้เยี่ยมชมเว็บไซต์
- คลิกที่โฆษณา หมายถึง 1 หากผู้ใช้คลิกโฆษณา ไม่เช่นนั้น 0
data["Clicked on Ad"] = data["Clicked on Ad"].map({0: "No", 1: "Yes"})โค้ดด้านบนใช้สำหรับแปลงเนื้อหาของคอลัมน์ "คลิกบนโฆษณา" โดยที่ 0=ไม่ใช่ และ 1=ใช่
ขั้นตอนที่ 3: การวิเคราะห์อัตราการคลิกผ่าน
ขั้นแรก เราทำการวิเคราะห์เพื่อดูว่ากิจกรรมของผู้ใช้ส่งผลต่อ CTR หรือไม่
fig = px.box(data, x="Daily Time Spent on Site", color="Clicked on Ad", title="Click Through Rate based on Time Spent on Site", color_discrete_map={'Yes':'blue', 'No':'red'})
fig.update_traces(quartilemethod="exclusive")
fig.show()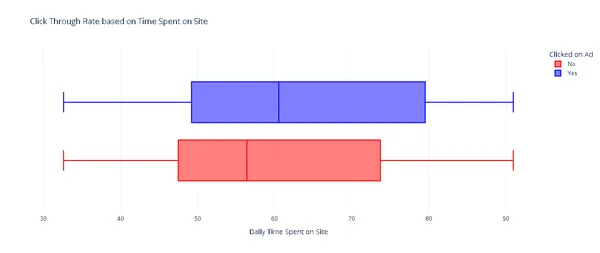
CTR เทียบกับเวลาที่ใช้
ดูเหมือนว่าผู้คนมีแนวโน้มที่จะคลิกโฆษณามากขึ้นเมื่ออยู่บนหน้าอินเทอร์เน็ตนานขึ้น ประการที่สอง เราทำการวิเคราะห์เพื่อดูว่าการใช้งานอินเทอร์เน็ตรายวันของผู้ใช้ส่งผลต่อ CTR หรือไม่
fig = px.box(data, x="Daily Internet Usage", color="Clicked on Ad", title="Click Through Rate based on Daily Internet Usage", color_discrete_map={'Yes':'blue', 'No':'red'})
fig.update_traces(quartilemethod="exclusive")
fig.show()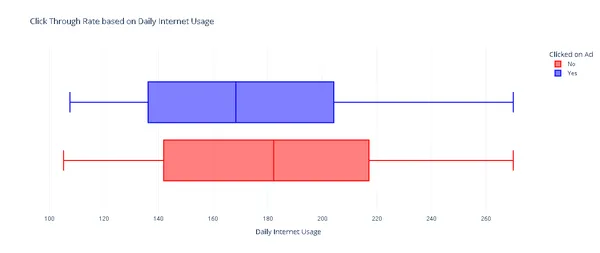
CTR เทียบกับการใช้อินเทอร์เน็ตรายวัน
จากกราฟ ผู้ใช้อินเทอร์เน็ตรายวันจะคลิกโฆษณาบ่อยขึ้น ต่อไป เราจะวิเคราะห์ว่าอายุของผู้ใช้ส่งผลต่ออัตราการคลิกผ่านหรือไม่
fig = px.box(data, x="Age", color="Clicked on Ad", title="Click Through Rate based on Age", color_discrete_map={'Yes':'blue', 'No':'red'})
fig.update_traces(quartilemethod="exclusive")
fig.show()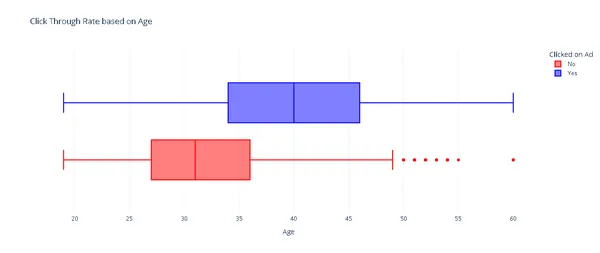
CTR เทียบกับอายุ
จากกราฟด้านบน ผู้ใช้ที่มีอายุประมาณ 40 ปีจะเป็นผู้กำหนดความถี่ในการคลิกโฆษณา ต่อไป เราจะทดสอบว่ารายได้ของผู้ใช้มีผลกระทบต่ออัตราการคลิกผ่านหรือไม่
fig = px.box(data, x="Area Income", color="Clicked on Ad", title="Click Through Rate based on Income", color_discrete_map={'Yes':'blue', 'No':'red'})
fig.update_traces(quartilemethod="exclusive")
fig.show()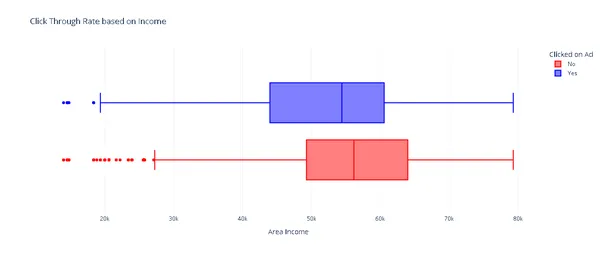
CTR เทียบกับรายได้
ผู้บริโภคที่มีรายได้สูงมีแนวโน้มน้อยที่จะคลิกโฆษณา แม้ว่าแทบจะไม่มีความแตกต่างที่มีนัยสำคัญทางสถิติก็ตาม จากนั้นจึงคำนวณอัตราการคลิกผ่านโดยรวมสำหรับโฆษณา ที่นี่ เราต้องกำหนดสัดส่วนของผู้ใช้ที่ทิ้งการแสดงผลโฆษณาไว้กับผู้ที่คลิกโฆษณา เรามาตรวจสอบการกระจายผู้ใช้กันดีกว่า
data["Clicked on Ad"].value_counts()
ผู้ใช้คลิก
ดังนั้น 4917 คนจาก 10,000 คนคลิกโฆษณา เรามากำหนด CTR กันดีกว่า
click_through_rate = 4917 / 10000 * 100
print(click_through_rate)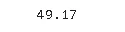
คะแนน CTR
ดังนั้น CTR คือ 49.17
ขั้นตอนที่ 4: สร้างแบบจำลองป่าสุ่มและทำการคาดการณ์
ต่อไปเรามาสร้างก โมเดลการเรียนรู้ของเครื่อง ที่สามารถคาดการณ์อัตราการคลิกผ่านได้ ชุดข้อมูลจะแบ่งออกเป็นชุดการฝึกอบรมและการทดสอบก่อน ก่อนหน้านี้ ค่าของคอลัมน์ "เพศ" จะต้องแปลงเป็นตัวเลข ด้วยการแทนที่ "ชาย" ด้วย "1" และ "หญิง" ด้วย "0" จะเป็นการเข้ารหัสตัวแปรหมวดหมู่ "เพศ" ให้อยู่ในรูปแบบไบนารี่เพื่อการวิเคราะห์ที่รวดเร็วยิ่งขึ้น นอกจากนี้ ควรลบคอลัมน์ “บรรทัดหัวข้อโฆษณา” และ “เมือง” จากดาต้าเฟรม “x” เนื่องจากไม่ได้ทำหน้าที่เป็นตัวแปรอินพุตสำหรับโมเดลแมชชีนเลิร์นนิง
data["Gender"] = data["Gender"].map({"Male": 1,"Female": 0}) x=data.iloc[:,0:7]
x=x.drop(['Ad Topic Line','City'],axis=1)
y=data.iloc[:,9] xtrain,xtest,ytrain,ytest=train_test_split(x,y,test_size=0.2,random_state=33)ตอนนี้เรามาปรับใช้ แบบจำลองการจำแนกการพยากรณ์แบบสุ่ม เพื่อฝึกอบรมข้อมูล
model = RandomForestClassifier()
model.fit(x, y)ต่อไป เรามาคำนวณความแม่นยำของแบบจำลองกัน
y_pred = model.predict(xtest)
print(accuracy_score(ytest,y_pred))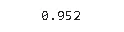
คะแนนความแม่นยำ
ปรากฎว่าคะแนนความแม่นยำดีมากเท่ากับ 95.2%
ในที่สุด เราก็มาถึงขั้นตอนการทดสอบโมเดลด้วยการคาดการณ์ตามคุณลักษณะที่มีอยู่
import warnings
warnings.filterwarnings("ignore") print("Ads Click Through Rate Prediction : ")
a = float(input("Daily Time Spent on Site: "))
b = float(input("Age: "))
c = float(input("Area Income: "))
d = float(input("Daily Internet Usage: "))
e = input("Gender (Male = 1, Female = 0) : ") features = np.array([[a, b, c, d, e]])
print("Will the user click on ad = ", model.predict(features))
การทดสอบแบบจำลอง
ตัวแปร a, b, c, d และ e เป็นคุณสมบัติที่ผู้ใช้ป้อน ในขณะที่ผลการคาดการณ์แสดงว่า "ใช่" ซึ่งบ่งชี้ว่าหากเวลารายวันที่ใช้ในไซต์คือ 61.2 อายุคือ 35 ปี พื้นที่รายได้คือ 5800 ปริมาณการใช้อินเทอร์เน็ตรายวันคือ 115.21 เป็นเพศเป็นชาย ผลการทำนายคือ “ใช่”
สรุป
บทความนี้เริ่มต้นด้วยการวิเคราะห์อัตราการคลิกผ่านโดยอิงตามเวลารายวันที่ใช้บนเว็บไซต์ อายุของผู้ใช้ รายได้ในพื้นที่ การใช้อินเทอร์เน็ตรายวัน และการสำรวจผู้ใช้ จากนั้น จะคำนวณคะแนน CTR ตามผลรวมของผู้ใช้ ก่อนที่จะคาดการณ์อัตราการคลิกผ่านโฆษณาโดยใช้ Random Forest Classifier พูดอย่างกว้างๆ ในโพสต์นี้ เราได้พูดคุยเรื่องต่อไปนี้:
- จะค้นหาคุณสมบัติที่ส่งผลต่อการคาดการณ์อัตราการคลิกผ่านโฆษณาได้อย่างไร
- คุณจะคำนวณคะแนน CTR ตามจำนวนผู้ใช้ที่คลิกโฆษณาได้อย่างไร
- จะใช้โมเดล Random Forest Classifier เพื่อทำนายอัตราการคลิกผ่านโฆษณาได้อย่างไร
โดยรวมแล้ว บทความนี้ให้คำแนะนำที่ครอบคลุมเกี่ยวกับการคาดการณ์อัตราการคลิกผ่านโฆษณาโดยใช้ตัวแยกประเภทฟอเรสต์แบบสุ่ม หลาม. หากคุณมีคำถามหรือความคิดเห็นใด ๆ โปรดทิ้งไว้ด้านล่าง รหัสที่สมบูรณ์คือ ที่นี่
สื่อที่แสดงในบทความนี้ไม่ได้เป็นของ Analytics Vidhya และถูกใช้ตามดุลยพินิจของผู้เขียน
ที่เกี่ยวข้อง
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://www.analyticsvidhya.com/blog/2023/04/predicting-ad-click-through-rate-with-random-forest/
- :มี
- :เป็น
- :ไม่
- 000
- 1
- 10
- 100
- 2%
- 7
- 9
- a
- สามารถ
- ข้างบน
- ความถูกต้อง
- แม่นยำ
- อยากทำกิจกรรม
- Ad
- โฆษณา
- โฆษณา
- การโฆษณา
- มีผลต่อ
- ทั้งหมด
- แม้ว่า
- an
- การวิเคราะห์
- การวิเคราะห์
- การวิเคราะห์ วิทยา
- วิเคราะห์
- วิเคราะห์
- และ
- ใด
- เหมาะสม
- เป็น
- AREA
- รอบ
- บทความ
- AS
- At
- ความพร้อมใช้งาน
- เฉลี่ย
- พื้นหลัง
- ตาม
- BE
- ก่อน
- ด้านล่าง
- ประโยชน์
- สีน้ำเงิน
- แต้
- สร้าง
- ธุรกิจ
- by
- คำนวณ
- คำนวณ
- คำนวณ
- โทรศัพท์
- แคมเปญ
- CAN
- หมวดหมู่
- ลักษณะ
- ชาร์ต
- เมือง
- การจัดหมวดหมู่
- คลิก
- รหัส
- สี
- คอลัมน์
- คอลัมน์
- อย่างไร
- ความคิดเห็น
- บริษัท
- สมบูรณ์
- ครอบคลุม
- ข้อสรุป
- ดำเนินการ
- อย่างมาก
- ผู้บริโภค
- เนื้อหา
- ประเทศ
- สร้าง
- วิกฤติ
- สำคัญมาก
- ปรับแต่งได้
- ประจำวัน
- ข้อมูล
- การวิเคราะห์ข้อมูล
- ค่าเริ่มต้น
- ประชากรศาสตร์
- ปรับใช้
- กำหนด
- พัฒนา
- ที่กำลังพัฒนา
- DID
- ความแตกต่าง
- ดุลพินิจ
- กล่าวถึง
- การกระจาย
- แบ่งออก
- ครอบงำ
- e
- ง่าย
- ผล
- มีประสิทธิภาพ
- มีประสิทธิภาพ
- ประสิทธิผล
- ทั้ง
- มีส่วนร่วม
- ประมาณการ
- อีเธอร์ (ETH)
- พิเศษ
- ที่มีอยู่
- ด่วน
- คุณสมบัติ
- หญิง
- มะเดื่อ
- หา
- ชื่อจริง
- ดังต่อไปนี้
- สำหรับ
- พยากรณ์
- ป่า
- ฟอร์ม
- ราคาเริ่มต้นที่
- เพศ
- สร้าง
- GitHub
- Go
- เป้าหมาย
- ดี
- กราฟ
- กราฟ
- ให้คำแนะนำ
- มี
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- ระดับสูง
- ที่มีประสิทธิภาพสูง
- สูงกว่า
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- อย่างไรก็ตาม
- HTTPS
- i
- ระบุ
- นำเข้า
- การปรับปรุง
- in
- ความโน้มเอียง
- รวมทั้ง
- เงินได้
- เพิ่ม
- บ่งชี้ว่า
- อินพุต
- ข้อมูลเชิงลึก
- ตัวอย่าง
- การโต้ตอบ
- อินเตอร์เฟซ
- อินเทอร์เน็ต
- เข้าไป
- บทนำ
- IT
- คีย์
- ชื่อสกุล
- การเรียนรู้
- ทิ้ง
- ห้องสมุด
- เบา
- น่าจะ
- Line
- อีกต่อไป
- เครื่อง
- เรียนรู้เครื่อง
- หลัก
- ทำ
- การทำ
- การตลาด
- อาจ..
- วิธี
- ภาพบรรยากาศ
- เมตริก
- ตัวชี้วัด
- อาจ
- แบบ
- การทดสอบแบบจำลอง
- โมดูล
- เงิน
- ข้อมูลเพิ่มเติม
- ยิ่งไปกว่านั้น
- มากที่สุด
- nav
- จำเป็น
- ถัดไป
- ตอนนี้
- จำนวน
- ตัวเลข
- มึน
- วัตถุประสงค์
- of
- on
- เพิ่มประสิทธิภาพ
- Options
- or
- มิฉะนั้น
- ทั้งหมด
- เป็นเจ้าของ
- หมีแพนด้า
- ส่วนหนึ่ง
- ในสิ่งที่สนใจ
- คน
- เปอร์เซ็นต์
- การปฏิบัติ
- การวาง
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- กรุณา
- ตำแหน่ง
- โพสต์
- คาดการณ์
- ทำนาย
- คำทำนาย
- การคาดการณ์
- กระบวนการ
- สัดส่วน
- ให้
- การให้
- การตีพิมพ์
- ใส่
- คำถาม
- ได้เร็วขึ้น
- สุ่ม
- คะแนน
- ราคา
- อ่าน
- สีแดง
- ที่เกี่ยวข้อง
- การแสดงผล
- ดังก้อง
- ผล
- ผลสอบ
- รายได้
- โครงการ
- วิทยาศาสตร์
- คะแนน
- ที่สอง
- ให้บริการ
- ชุดอุปกรณ์
- การตั้งค่า
- น่า
- โชว์
- แสดง
- แสดงให้เห็นว่า
- สำคัญ
- เว็บไซต์
- So
- การพูด
- โดยเฉพาะ
- การใช้จ่าย
- ระยะ
- เริ่มต้น
- สถิติ
- เข้าพัก
- ขั้นตอน
- กลยุทธ์
- กลยุทธ์
- การศึกษา
- อย่างเช่น
- กลยุทธ์
- การ
- เป้า
- งาน
- เทมเพลต
- แม่แบบ
- ทดสอบ
- การทดสอบ
- ที่
- พื้นที่
- พื้นที่
- กราฟ
- ของพวกเขา
- พวกเขา
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- เหล่านั้น
- ตลอด
- เวลา
- ชื่อหนังสือ
- ไปยัง
- หัวข้อ
- รถไฟ
- การฝึกอบรม
- เปลี่ยน
- การเปลี่ยนแปลง
- อัปโหลด
- URL
- การใช้
- ใช้
- มือสอง
- ผู้ใช้งาน
- ผู้ใช้
- การใช้
- ความคุ้มค่า
- ตัวแปร
- ต่างๆ
- กับ
- เข้าเยี่ยมชม
- ผู้เข้าชม
- การสร้างภาพ
- vs
- คือ
- we
- Website
- ว่า
- ที่
- ในขณะที่
- ขาว
- WHO
- จะ
- กับ
- X
- เธอ
- ลมทะเล