นับตั้งแต่การท่วมท้นของข้อมูลขนาดใหญ่เมื่อทศวรรษที่แล้ว องค์กรหลายแห่งได้เรียนรู้วิธีสร้างแอปพลิเคชันเพื่อประมวลผลและวิเคราะห์ข้อมูลขนาดเพตะไบต์ Data Lake ทำหน้าที่เป็นพื้นที่เก็บข้อมูลส่วนกลางในการจัดเก็บข้อมูลที่มีโครงสร้างและไม่มีโครงสร้างในทุกขนาดและในรูปแบบต่างๆ อย่างไรก็ตาม ในขณะที่โซลูชันการประมวลผลข้อมูลตามสเกลเติบโตขึ้น องค์กรต่างๆ จำเป็นต้องสร้างคุณลักษณะเพิ่มเติมขึ้นเรื่อยๆ ที่ด้านบนของดาต้าเลคของตน คุณสมบัติที่สำคัญประการหนึ่งคือการเรียกใช้เวิร์กโหลดต่างๆ เช่น ระบบธุรกิจอัจฉริยะ (BI) การเรียนรู้ของเครื่อง (ML) วิทยาศาสตร์ข้อมูลและการสำรวจข้อมูล และการเปลี่ยนแปลงการเก็บข้อมูล (CDC) ของข้อมูลธุรกรรม โดยไม่ต้องรักษาสำเนาข้อมูลหลายชุด นอกจากนี้ งานในการดูแลรักษาและจัดการไฟล์ในที่จัดเก็บข้อมูลดิบอาจเป็นเรื่องที่น่าเบื่อและซับซ้อนในบางครั้ง
รูปแบบตารางเช่น Apache Iceberg ช่วยแก้ไขปัญหาเหล่านี้ พวกเขาเปิดใช้งานธุรกรรมบน data lake และสามารถลดความซับซ้อนของการจัดเก็บ การจัดการ การส่งผ่าน และการประมวลผลข้อมูล ทะเลสาบข้อมูลธุรกรรมเหล่านี้รวมคุณลักษณะจากทั้งทะเลสาบข้อมูลและคลังข้อมูล คุณสามารถลดความซับซ้อนของกลยุทธ์ข้อมูลได้โดยการเรียกใช้ปริมาณงานและแอปพลิเคชันหลายรายการบนข้อมูลเดียวกันในตำแหน่งเดียวกัน อย่างไรก็ตาม การใช้รูปแบบเหล่านี้จำเป็นต้องสร้าง บำรุงรักษา และปรับขนาดโครงสร้างพื้นฐานและตัวเชื่อมต่อการรวมระบบซึ่งอาจใช้เวลานาน ท้าทาย และมีค่าใช้จ่ายสูง
ในโพสต์นี้ เราจะแสดงวิธีที่คุณสามารถสร้างที่เก็บข้อมูลการทำธุรกรรมแบบไร้เซิร์ฟเวอร์ด้วย Apache Iceberg บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) โดยใช้ Amazon EMR ไร้เซิร์ฟเวอร์ และ อเมซอน อาเธน่า. เรามีตัวอย่างสำหรับการย่อยข้อมูลและการสืบค้นโดยใช้ Data Lake การขายทางอีคอมเมิร์ซ
ภาพรวมภูเขาน้ำแข็งอาปาเช่
Iceberg เป็นรูปแบบตารางโอเพ่นซอร์สที่นำพลังของตาราง SQL มาสู่ไฟล์ข้อมูลขนาดใหญ่ เปิดใช้งานธุรกรรม ACID บนตาราง ทำให้สามารถนำเข้าข้อมูล อัปเดต และสืบค้นข้อมูลพร้อมกันได้ ในขณะที่ใช้ SQL ที่คุ้นเคย Iceberg ใช้การจัดการข้อมูลเมตาภายในที่ติดตามข้อมูลและเสริมศักยภาพชุดคุณสมบัติที่หลากหลายตามขนาด ช่วยให้คุณสามารถข้ามเวลาและย้อนกลับไปยังเวอร์ชันเก่าของธุรกรรมข้อมูลที่คอมมิต ควบคุมวิวัฒนาการของสคีมาของตาราง กระชับข้อมูลอย่างง่ายดาย และใช้การแบ่งพาร์ติชันที่ซ่อนอยู่เพื่อการสืบค้นที่รวดเร็ว
Iceberg จัดการไฟล์ในนามของผู้ใช้และปลดล็อกกรณีการใช้งาน เช่น:
- การนำเข้าและการสืบค้นข้อมูลพร้อมกัน รวมถึงการสตรีมและ CDC
- BI และการรายงานด้วย SQL อย่างง่ายที่แสดงออก
- เพิ่มขีดความสามารถของร้านค้าคุณลักษณะ ML และชุดการฝึกอบรม
- ปริมาณงานด้านการปฏิบัติตามกฎและข้อบังคับ เช่น GDPR ค้นหาและลืม
- การคืนสถานะข้อมูลที่มาถึงล่าช้า ซึ่งเป็นข้อมูลขนาดที่มาถึงช้ากว่าข้อมูลข้อเท็จจริง ตัวอย่างเช่น สาเหตุของความล่าช้าของเที่ยวบินอาจเกิดขึ้นได้หลังจากที่เที่ยวบินล่าช้า
- ติดตามการเปลี่ยนแปลงข้อมูลและการย้อนกลับ
สร้างที่จัดเก็บข้อมูลการทำธุรกรรมของคุณบน AWS
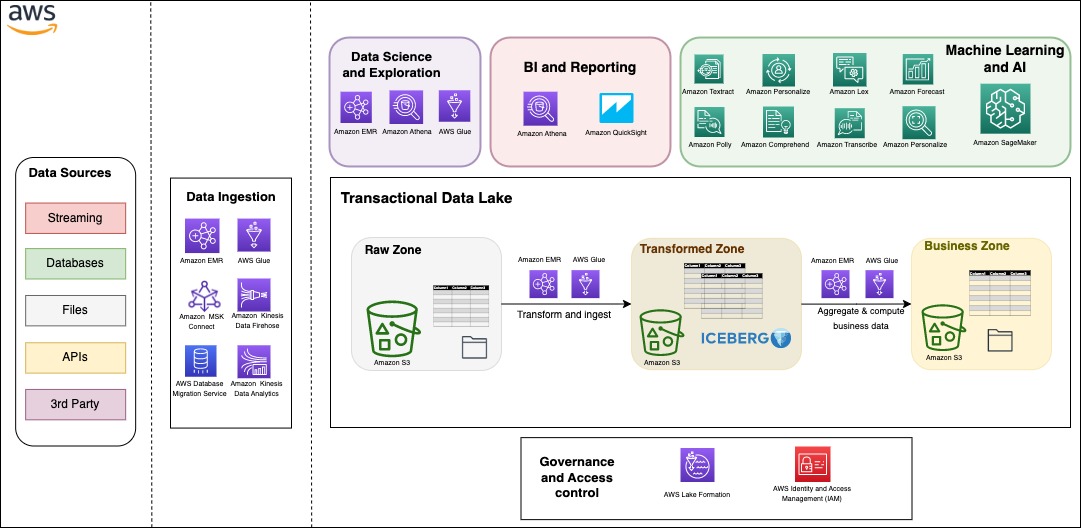
คุณสามารถสร้างสถาปัตยกรรมข้อมูลสมัยใหม่ของคุณด้วย Data Lake ที่ปรับขนาดได้ซึ่งผสานรวมอย่างลงตัวกับ อเมซอน Redshift คลังสินค้าระบบคลาวด์ขับเคลื่อน ยิ่งไปกว่านั้น ลูกค้าจำนวนมากกำลังมองหาสถาปัตยกรรมที่พวกเขาสามารถรวมประโยชน์ของ data lake และ data warehouse ไว้ในที่จัดเก็บเดียวกัน ในรูปต่อไปนี้ เราแสดงสถาปัตยกรรมที่ครอบคลุมซึ่งใช้กลยุทธ์สถาปัตยกรรมข้อมูลสมัยใหม่บน AWS เพื่อสร้างที่จัดเก็บข้อมูลการทำธุรกรรมที่มีคุณลักษณะครบถ้วน AWS มอบความยืดหยุ่นและคุณสมบัติที่หลากหลายในการรับข้อมูล สร้างแอปพลิเคชัน AI และ ML และเรียกใช้ปริมาณงานการวิเคราะห์โดยไม่ต้องมุ่งเน้นไปที่การยกน้ำหนักที่ไม่แตกต่างกัน
ข้อมูลสามารถแบ่งออกเป็นสามโซนที่แตกต่างกันดังแสดงในรูปต่อไปนี้ โซนแรกคือโซนดิบที่สามารถเก็บข้อมูลจากแหล่งที่มาตามที่เป็นอยู่ โซนการแปลงเป็นโซนทั่วทั้งองค์กรเพื่อโฮสต์ข้อมูลที่สะอาดและแปลงแล้วเพื่อรองรับหลายทีมและกรณีการใช้งาน Iceberg มีรูปแบบตารางที่ด้านบนของ Amazon S3 ในโซนนี้เพื่อให้ธุรกรรม ACID แต่ยังช่วยให้สามารถจัดการไฟล์ได้อย่างราบรื่นและให้ความสามารถในการเดินทางข้ามเวลาและการย้อนกลับ โซนธุรกิจจัดเก็บข้อมูลเฉพาะสำหรับกรณีธุรกิจและแอปพลิเคชันที่รวบรวมและคำนวณจากข้อมูลในโซนที่แปลงแล้ว
![]()
สิ่งสำคัญประการหนึ่งของกลยุทธ์ข้อมูลที่ประสบความสำเร็จสำหรับองค์กรใดๆ คือการกำกับดูแลข้อมูล บน AWS คุณสามารถใช้กลยุทธ์การกำกับดูแลอย่างละเอียดพร้อมการควบคุมการเข้าถึงแบบละเอียดไปยัง Data Lake ด้วย การก่อตัวของทะเลสาบ AWS.
ภาพรวมสถาปัตยกรรมไร้เซิร์ฟเวอร์
ในส่วนนี้ เราจะแสดงวิธีนำเข้าและสืบค้นข้อมูลในที่เก็บข้อมูลธุรกรรมของคุณในไม่กี่ขั้นตอน EMR Serverless เป็นตัวเลือกแบบไร้เซิร์ฟเวอร์ที่ทำให้นักวิเคราะห์ข้อมูลและวิศวกรเรียกใช้การวิเคราะห์ตาม Spark ได้ง่ายโดยไม่ต้องกำหนดค่า จัดการ และปรับขนาดคลัสเตอร์หรือเซิร์ฟเวอร์ คุณสามารถเรียกใช้แอปพลิเคชัน Spark ได้โดยไม่ต้องวางแผนความจุหรือจัดเตรียมโครงสร้างพื้นฐาน ในขณะที่จ่ายเฉพาะสำหรับการใช้งานของคุณ EMR Serverless รองรับ Iceberg เพื่อสร้างตารางและคิวรี ผสาน และแทรกข้อมูลด้วย Spark ในไดอะแกรมสถาปัตยกรรมต่อไปนี้ งานการแปลง Spark สามารถโหลดข้อมูลจากโซนดิบหรือแหล่งที่มา ใช้ตรรกะการทำความสะอาดและการแปลง และนำเข้าข้อมูลในโซนที่แปลงบนตาราง Iceberg โค้ด Spark สามารถทำงานทันทีบนแอปพลิเคชัน EMR Serverless ซึ่งเราจะสาธิตในโพสต์นี้ในภายหลัง
![]()
ตารางภูเขาน้ำแข็งซิงค์กับ AWS กาว แคตตาล็อกข้อมูล แค็ตตาล็อกข้อมูลเป็นตำแหน่งศูนย์กลางในการควบคุมและติดตามสคีมาและข้อมูลเมตา ด้วย Iceberg กระบวนการนำเข้า อัปเดต และสืบค้นจะได้รับประโยชน์จาก Atomicity การแยกสแน็ปช็อต และการจัดการการทำงานพร้อมกันเพื่อให้มุมมองข้อมูลที่สอดคล้องกัน
Athena เป็นบริการวิเคราะห์เชิงโต้ตอบแบบไร้เซิร์ฟเวอร์ที่สร้างขึ้นบนเฟรมเวิร์กโอเพ่นซอร์ส รองรับรูปแบบโอเพ่นเทเบิลและไฟล์ Athena มอบวิธีการที่เรียบง่ายและยืดหยุ่นในการวิเคราะห์ข้อมูลขนาดเพตะไบต์ในที่ที่มันอาศัยอยู่ เพื่อให้บริการ BI และการวิเคราะห์การรายงาน ช่วยให้คุณสร้างและเรียกใช้การสืบค้นบนตาราง Iceberg โดยกำเนิดและรวมเข้ากับเครื่องมือ BI ที่หลากหลาย
โมเดลข้อมูลการขาย
สตาร์สคีมา และตัวแปรของมันเป็นที่นิยมอย่างมากสำหรับการสร้างแบบจำลองข้อมูลในคลังข้อมูล พวกเขาใช้ตารางข้อเท็จจริงและตารางมิติอย่างน้อยหนึ่งตาราง ตารางข้อเท็จจริงเก็บข้อมูลการทำธุรกรรมหลักจากตรรกะทางธุรกิจด้วยคีย์ต่างประเทศไปยังตารางมิติ ตารางไดเมนชันมีข้อมูลประกอบเพิ่มเติมเพื่อเพิ่มความสมบูรณ์ให้กับตารางข้อเท็จจริง
ในโพสต์นี้ เรานำตัวอย่างข้อมูลการขายจาก เกณฑ์มาตรฐาน TPC-DS. เราขยายส่วนย่อยของสคีมาด้วย web_sales ตารางข้อเท็จจริงดังแสดงในรูปต่อไปนี้ โดยจะเก็บค่าตัวเลขเกี่ยวกับต้นทุนการขาย ต้นทุนการขนส่ง ภาษี และกำไรสุทธิ นอกจากนี้ยังมีคีย์นอกไปยังตารางมิติเช่น date_dim, time_dim, customerและ item. ตารางมิติเหล่านี้จัดเก็บเรกคอร์ดที่ให้รายละเอียดเพิ่มเติม ตัวอย่างเช่น คุณสามารถแสดงเมื่อมีการขายโดยลูกค้ารายใดสำหรับรายการใด
![]()
มีการใช้โมเดลตามมิติอย่างกว้างขวางในการสร้างคลังข้อมูล ในส่วนต่อไปนี้ เราจะแสดงวิธีนำโมเดลดังกล่าวไปใช้งานบน Iceberg จัดเตรียมฟีเจอร์คลังข้อมูลบน Data Lake ของคุณ และเรียกใช้ปริมาณงานต่างๆ ในตำแหน่งเดียวกัน เราให้ตัวอย่างที่สมบูรณ์ของการสร้างสถาปัตยกรรมแบบไร้เซิร์ฟเวอร์ด้วยการนำเข้าข้อมูลโดยใช้ EMR แบบไร้เซิร์ฟเวอร์และ Athena โดยใช้การสืบค้น TPC-DS
เบื้องต้น
สำหรับคำแนะนำนี้ คุณควรมีข้อกำหนดเบื้องต้นต่อไปนี้:
- An บัญชี AWS
- ความรู้พื้นฐานเกี่ยวกับการจัดการข้อมูลและ SQL
ปรับใช้ทรัพยากรโซลูชันด้วย AWS CloudFormation
เราให้บริการ การก่อตัวของ AWS Cloud เทมเพลตเพื่อปรับใช้ Data Lake Stack ด้วยทรัพยากรต่อไปนี้:
- ที่เก็บข้อมูล S3 สองที่: ที่เก็บข้อมูลหนึ่งสำหรับสคริปต์และผลการสืบค้น และอีกที่หนึ่งสำหรับพื้นที่เก็บข้อมูลในทะเลสาบข้อมูล
- เวิร์กกรุ๊ป Athena
- แอปพลิเคชัน EMR Serverless
- ฐานข้อมูล AWS Glue และตารางบนบัคเก็ต S3 สาธารณะภายนอกของข้อมูล TPC-DS
- ฐานข้อมูล AWS Glue สำหรับ Data Lake
- An AWS Identity และการจัดการการเข้าถึง (IAM) บทบาทและตำรวจ
ทำตามขั้นตอนต่อไปนี้เพื่อสร้างทรัพยากรของคุณ:
- เปิดกอง CloudFormation:
![]()
ซึ่งจะเปิดใช้งาน AWS CloudFormation ในบัญชี AWS ของคุณโดยอัตโนมัติด้วยเทมเพลต CloudFormation จะแจ้งให้คุณลงชื่อเข้าใช้ตามต้องการ
- รักษาการตั้งค่าเทมเพลตตามที่เป็นอยู่
- ตรวจสอบ ฉันรับทราบว่า AWS CloudFormation อาจสร้างทรัพยากร IAM กล่อง.
- Choose ส่ง
![]()
เมื่อสร้างสแต็กเสร็จแล้ว ให้ตรวจสอบ Outputs แท็บของสแต็กเพื่อตรวจสอบทรัพยากรที่สร้างขึ้น
![]()
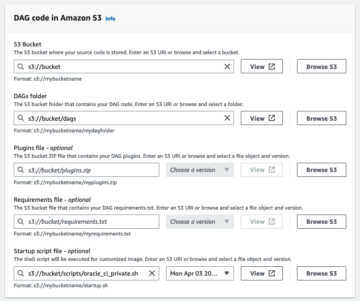
อัปโหลดสคริปต์ Spark ไปยัง Amazon S3
ทำตามขั้นตอนต่อไปนี้เพื่ออัปโหลดสคริปต์ Spark ของคุณ:
- ดาวน์โหลดสคริปต์ต่อไปนี้: นำเข้า-iceberg.py และ อัพเดท item.py.
- บนคอนโซล Amazon S3 ให้ไปที่
datalake-resources--us-east-1ที่เก็บข้อมูลที่คุณสร้างไว้ก่อนหน้านี้ - สร้างโฟลเดอร์ใหม่ชื่อ
scripts. - อัปโหลดสคริปต์ PySpark สองตัว:
ingest-iceberg.pyและupdate-item.py.
![]()
สร้างตาราง Iceberg และนำเข้าข้อมูล TPC-DS
หากต้องการสร้างตาราง Iceberg ของคุณและนำเข้าข้อมูล ให้ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล Amazon EMR ให้เลือก EMR ไร้เซิร์ฟเวอร์ ในบานหน้าต่างนำทาง
- Choose จัดการแอปพลิเคชัน.
- เลือกแอปพลิเคชัน
datalake-app.
![]()
- Choose เริ่มสมัคร.
เมื่อเริ่มต้นแล้ว จะจัดเตรียมความจุที่เตรียมใช้งานล่วงหน้าตามที่กำหนดค่าเมื่อสร้าง (ไดรเวอร์ Spark หนึ่งตัวและตัวดำเนินการ Spark สองตัว) ความจุที่เตรียมใช้งานล่วงหน้าคือทรัพยากรที่จะถูกจัดเตรียมเมื่อคุณเริ่มแอปพลิเคชันของคุณ ใช้งานได้ทันทีเมื่อคุณส่งงาน อย่างไรก็ตาม จะมีค่าใช้จ่ายแม้ว่าจะไม่ได้ใช้เมื่อแอปพลิเคชันอยู่ในสถานะเริ่มต้น ตามค่าเริ่มต้น แอปพลิเคชันจะถูกตั้งค่าให้หยุดเมื่อไม่ได้ใช้งานเป็นเวลา 15 นาที
เมื่อแอปพลิเคชัน EMR เริ่มต้นขึ้นแล้ว เราสามารถส่งการนำเข้า Spark ได้ job ingest-iceberg.py. งานสร้างตาราง Iceberg จากนั้นโหลดข้อมูลจากตาราง AWS Glue Data Catalog ที่สร้างไว้ก่อนหน้านี้บนข้อมูล TPC-DS ในบัคเก็ตภายนอก
- ไปที่
datalake-app. - เกี่ยวกับ งานวิ่ง เลือกแท็บ ส่งงาน.
![]()
- สำหรับ Nameป้อน
ingest-data. - สำหรับ บทบาทรันไทม์เลือกบทบาท IAM ที่สร้างโดย CloudFormation stack
- สำหรับ ตำแหน่งสคริปต์ป้อนเส้นทาง S3 สำหรับบัคเก็ตทรัพยากรของคุณ (
datalake-resource-<####>-us-east-1>scripts>ingest-iceberg.py).
![]()
- ภายใต้ คุณสมบัติของประกายไฟเลือก แก้ไขในข้อความ.
- ป้อนคุณสมบัติต่อไปนี้ แทนที่ ด้วยชื่อที่ฝากข้อมูลทะเลสาบข้อมูลของคุณ
datalake-<####>-us-east-1(ไม่ใช่ datalake-resources)
![]()
- ส่งงาน.
คุณสามารถติดตามความคืบหน้าของงาน ![]()
ค้นหาตารางภูเขาน้ำแข็ง
ในส่วนนี้ เรามีตัวอย่างการสืบค้นคลังข้อมูลจาก TPC-DS บนตาราง Iceberg
- บนคอนโซล Athena ให้เปิดตัวแก้ไขแบบสอบถาม
- สำหรับ กลุ่มงาน, สลับไปที่
DatalakeWorkgroup.
![]()
- Choose รับทราบ.
![]() แบบสอบถามใน
แบบสอบถามใน DatalakeWorkgroup จะทำงานบนเครื่องยนต์ Athena เวอร์ชัน 3
- เกี่ยวกับ ข้อความค้นหาที่บันทึกไว้ แท็บ เลือกแบบสอบถามที่จะเรียกใช้บนตาราง Iceberg ของคุณ
![]() แบบสอบถามต่อไปนี้แสดงอยู่:
แบบสอบถามต่อไปนี้แสดงอยู่:
- แบบสอบถาม 3 – รายงานราคาขายที่ขยายทั้งหมดต่อแบรนด์สินค้าของผู้ผลิตรายใดรายหนึ่งสำหรับยอดขายทั้งหมดในเดือนที่ระบุของปี
- แบบสอบถาม 45 – รายงานยอดขายเว็บทั้งหมดสำหรับลูกค้าในรหัสไปรษณีย์ เมือง เคาน์ตี หรือรัฐ หรือรายการเฉพาะสำหรับปีและไตรมาสที่กำหนด
- แบบสอบถาม 52 – รายงานผลรวมของราคาขายเพิ่มเติมสำหรับสินค้าทั้งหมดของแบรนด์ที่ระบุในปีและเดือนที่ระบุ
- แบบสอบถาม 6 – ระบุรัฐทั้งหมดที่มีลูกค้าอย่างน้อย 10 รายที่ซื้อสินค้าที่มีป้ายราคาสูงกว่าราคาเฉลี่ยของสินค้าในหมวดหมู่เดียวกันอย่างน้อย 20% ในเดือนนั้นๆ
- แบบสอบถาม 75 – ติดตามการขายสินค้าตามแบรนด์ คลาส และหมวดหมู่เป็นเวลา 2 ปีติดต่อกัน
- แบบสอบถาม86a – รวมยอดขายบนเว็บสำหรับปีที่กำหนดตามหมวดหมู่และระดับ และจัดอันดับยอดขายในหมู่เพื่อนในกลุ่มหลัก สำหรับแต่ละกลุ่ม ให้คำนวณผลรวมของยอดขายและสถานที่ตั้งด้วยลำดับชั้นและอันดับภายในกลุ่ม
แบบสอบถามเหล่านี้เป็นตัวอย่างของแบบสอบถามที่ใช้ในการตัดสินใจและการรายงานในองค์กร คุณสามารถเรียกใช้ตามลำดับที่คุณต้องการ สำหรับกระทู้นี้ขอเริ่มด้วย Query3.
- ก่อนที่คุณจะเรียกใช้แบบสอบถาม ให้ยืนยันว่า ฐานข้อมูล ถูกตั้งค่าเป็น
datalake.
![]()
- ตอนนี้คุณสามารถเรียกใช้แบบสอบถาม
![]()
- ทำซ้ำขั้นตอนเหล่านี้เพื่อเรียกใช้แบบสอบถามอื่นๆ
ปรับปรุงตารางรายการ
หลังจากดำเนินการค้นหาแล้ว เราจะเตรียมชุดการอัปเดตและการแทรกบันทึกลงใน item ตาราง
- ขั้นแรก เรียกใช้แบบสอบถามต่อไปนี้เพื่อนับจำนวนระเบียนใน
itemตารางภูเขาน้ำแข็ง:
สิ่งนี้ควรส่งคืนเรกคอร์ด 102,000 รายการ
- เลือกบันทึกรายการที่มีราคาสูงกว่า $90:
สิ่งนี้จะส่งคืนเรกคอร์ด 1,112 รายการ
พื้นที่ update-item.py งานใช้ 1,112 ระเบียนเหล่านี้ แก้ไข 11 ระเบียนเพื่อเปลี่ยนชื่อของแบรนด์เป็น Unknownและเปลี่ยนแปลงระเบียนที่เหลืออีก 1,101 รายการ' i_item_id กุญแจสำคัญในการตั้งค่าสถานะเป็นระเบียนใหม่ เป็นผลให้ชุดของการอัปเดต 11 รายการและส่วนแทรก 1,101 รายการถูกรวมเข้ากับ item_iceberg ตาราง
ระเบียน 11 รายการที่จะอัปเดตคือรายการที่มีราคาสูงกว่า $90 และชื่อแบรนด์จะขึ้นต้นด้วย corpnameless.
- เรียกใช้แบบสอบถามต่อไปนี้:
![]()
ผลลัพธ์คือ 11 รายการ เดอะ item_update.py งานแทนที่ชื่อแบรนด์ด้วย Unknown และรวมแบทช์เข้ากับตารางภูเขาน้ำแข็ง
ตอนนี้คุณสามารถกลับไปที่คอนโซล EMR Serverless และเรียกใช้งานบนแอปพลิเคชัน EMR Serverless
- ในหน้ารายละเอียดการสมัคร เลือก ส่งงาน.
- สำหรับ Nameป้อน
update-item-job. - สำหรับ บทบาทรันไทม์¸ ใช้บทบาทเดิมที่คุณใช้ก่อนหน้านี้
- สำหรับ S3 URIเข้าสู่
update-item.pyตำแหน่งสคริปต์
![]()
- ภายใต้ คุณสมบัติของประกายไฟเลือก แก้ไขในข้อความ.
- ป้อนคุณสมบัติต่อไปนี้ แทนที่ ด้วยตัวคุณเอง
datalake-<####>-us-east-1:
![]()
- แล้วส่งงาน.
![]()
- หลังจากงานเสร็จสิ้น ให้กลับไปที่คอนโซล Athena และเรียกใช้แบบสอบถามต่อไปนี้:
![]()
ผลลัพธ์ที่ได้คือ 103,101 = 102,000 + (1,112 – 11) รวมแบทช์สำเร็จแล้ว
เดินทางข้ามเวลา
เมื่อต้องการเรียกใช้แบบสอบถามการเดินทางข้ามเวลา ให้ทำตามขั้นตอนต่อไปนี้:
- รับการประทับเวลาของงานที่รันผ่านหน้ารายละเอียดแอปพลิเคชันบนคอนโซล EMR Serverless หรือ Spark UI บนเซิร์ฟเวอร์ประวัติ ดังที่แสดงในภาพหน้าจอต่อไปนี้
เวลานี้อาจใช้เวลาเพียงไม่กี่นาทีก่อนที่คุณจะเรียกใช้งานการอัปเดต Spark
![]()
- แปลงการประทับเวลาจากรูปแบบ
YYYY/MM/DD hh:mm:ss to YYYY-MM-DDThh:mm:ss.sTZDด้วยเขตเวลา ตัวอย่างเช่นจาก2023/02/20 14:40:41ไปยัง2023-02-20 14:40:41.000 UTC. - บนคอนโซล Athena เรียกใช้แบบสอบถามต่อไปนี้เพื่อนับ
itemบันทึกตารางในแต่ละครั้งก่อนงานอัพเดตแทนที่ ด้วยเวลาของคุณ:
![]()
แบบสอบถามจะให้ผลลัพธ์ 102,000 ซึ่งเป็นขนาดตารางที่คาดไว้ก่อนที่จะเรียกใช้งานการอัปเดต
- ตอนนี้คุณสามารถเรียกใช้คิวรีด้วยการประทับเวลาหลังจากรันงานอัปเดตสำเร็จแล้ว (ตัวอย่างเช่น
2023-02-20 15:06:00.000 UTC):
![]()
แบบสอบถามจะให้ 103,101 เป็นขนาดของตารางในขณะนั้น หลังจากที่งานอัปเดตเสร็จสิ้น
นอกจากนี้ คุณสามารถค้นหาใน Athena ตาม ID เวอร์ชันของสแน็ปช็อตใน Iceberg อย่างไรก็ตาม สำหรับกรณีการใช้งานขั้นสูง เช่น เพื่อย้อนกลับเป็นเวอร์ชันที่กำหนดหรือเพื่อค้นหา ID เวอร์ชัน คุณสามารถใช้ SDK หรือ Spark ของ Iceberg ใน Amazon EMR ได้
ทำความสะอาด
ทำตามขั้นตอนต่อไปนี้เพื่อล้างทรัพยากรของคุณ:
- บนคอนโซล Amazon S3 ให้ล้างบัคเก็ตของคุณ
- บนคอนโซล Athena ให้ลบเวิร์กกรุ๊ป
DatalakeWorkgroup. - บนคอนโซล EMR Studio ให้หยุดแอปพลิเคชัน
datalake-app. - บนคอนโซล AWS CloudFormation ให้ลบ CloudFormation stack
สรุป
ในโพสต์นี้ เราได้สร้างที่จัดเก็บข้อมูลการทำธุรกรรมแบบไร้เซิร์ฟเวอร์ด้วยตาราง Iceberg, EMR Serverless และ Athena เราใช้ข้อมูลการขาย TPC-DS กับข้อมูล 10 GB และมากกว่า 7 ล้านบันทึกในตารางข้อเท็จจริง เราได้แสดงให้เห็นว่าการพึ่งพา SQL และ Spark นั้นตรงไปตรงมาเพียงใดในการเรียกใช้งานแบบไร้เซิร์ฟเวอร์สำหรับการนำเข้าข้อมูลและการเติมข้อมูล นอกจากนี้ เราได้แสดงวิธีเรียกใช้การสืบค้น BI ที่ซับซ้อนโดยตรงบนตาราง Iceberg จาก Athena เพื่อการรายงาน
คุณสามารถเริ่มสร้างที่จัดเก็บข้อมูลการทำธุรกรรมแบบไร้เซิร์ฟเวอร์บน AWS ได้แล้ววันนี้ และเจาะลึกลงไปในคุณสมบัติและการเพิ่มประสิทธิภาพที่ Iceberg มีให้เพื่อสร้างแอปพลิเคชันการวิเคราะห์ได้ง่ายขึ้น ภูเขาน้ำแข็งยังสามารถช่วยคุณในอนาคตเพื่อปรับปรุงประสิทธิภาพและลดค่าใช้จ่าย
เกี่ยวกับผู้เขียน
![]()
แม่บ้าน เป็น Specialist Solutions Architect ที่ AWS โดยมุ่งเน้นที่การวิเคราะห์ เขาหลงใหลเกี่ยวกับข้อมูลและเทคโนโลยีที่เกิดขึ้นใหม่ในการวิเคราะห์ เขาจบปริญญาเอกด้านการจัดการข้อมูลในระบบคลาวด์ ก่อนเข้าร่วม AWS เขาทำงานในโครงการข้อมูลขนาดใหญ่หลายโครงการและเผยแพร่เอกสารการวิจัยหลายฉบับในการประชุมและสถานที่ระดับนานาชาติ
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/build-a-serverless-transactional-data-lake-with-apache-iceberg-amazon-emr-serverless-and-amazon-athena/
- :เป็น
- $ ขึ้น
- 000
- 1
- 10
- 100
- 102
- 107
- 11
- 7
- 8
- a
- เกี่ยวกับเรา
- เข้า
- ลงชื่อเข้าใช้
- รับทราบ
- เพิ่มเติม
- นอกจากนี้
- สูง
- หลังจาก
- AI
- ทั้งหมด
- การอนุญาต
- ช่วยให้
- อเมซอน
- อเมซอน อาเธน่า
- อเมซอน EMR
- ในหมู่
- การวิเคราะห์
- นักวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- และ
- อาปาเช่
- การใช้งาน
- การใช้งาน
- ใช้
- สถาปัตยกรรม
- เป็น
- ที่เดินทางมาถึง
- AS
- แง่มุม
- At
- อัตโนมัติ
- เฉลี่ย
- AWS
- การก่อตัวของ AWS Cloud
- AWS กาว
- กลับ
- ตาม
- BE
- ก่อน
- ประโยชน์
- ประโยชน์ที่ได้รับ
- ใหญ่
- ข้อมูลขนาดใหญ่
- ซื้อ
- ยี่ห้อ
- ความกว้าง
- นำ
- สร้าง
- การก่อสร้าง
- สร้าง
- ธุรกิจ
- ระบบธุรกิจอัจฉริยะ
- ปุ่ม
- by
- CAN
- ความสามารถในการ
- ความจุ
- จับ
- กรณี
- แค็ตตาล็อก
- หมวดหมู่
- CDC
- ส่วนกลาง
- ท้าทาย
- เปลี่ยนแปลง
- การเปลี่ยนแปลง
- โหลด
- ตรวจสอบ
- Choose
- เมือง
- ชั้น
- การทำความสะอาด
- ไคลเอนต์
- เมฆ
- รหัส
- รหัส
- รวมกัน
- มุ่งมั่น
- ประกอบ
- สมบูรณ์
- ซับซ้อน
- ครอบคลุม
- คำนวณ
- พร้อมกัน
- การประชุม
- ยืนยัน
- ติดต่อกัน
- คงเส้นคงวา
- ปลอบใจ
- ควบคุม
- ราคา
- ค่าใช้จ่าย
- ได้
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- ลูกค้า
- ลูกค้า
- ข้อมูล
- ดาต้าเลค
- การจัดการข้อมูล
- การประมวลผล
- วิทยาศาสตร์ข้อมูล
- การจัดเก็บข้อมูล
- กลยุทธ์ข้อมูล
- คลังข้อมูล
- คลังข้อมูล
- ฐานข้อมูล
- ทศวรรษ
- การตัดสินใจ
- ลึก
- ค่าเริ่มต้น
- ความล่าช้า
- ล่าช้า
- สาธิต
- แสดงให้เห็นถึง
- ปรับใช้
- รายละเอียด
- dev
- ต่าง
- Dimension
- มิติ
- โดยตรง
- คนขับรถ
- ในระหว่าง
- แต่ละ
- ก่อน
- อย่างง่ายดาย
- ง่าย
- อีคอมเมิร์ซ
- บรรณาธิการ
- กากกะรุน
- พนักงาน
- ให้อำนาจ
- ทำให้สามารถ
- ช่วยให้
- เครื่องยนต์
- วิศวกร
- ประเทือง
- เข้าสู่
- อีเธอร์ (ETH)
- แม้
- วิวัฒนาการ
- ตัวอย่าง
- ตัวอย่าง
- ที่คาดหวัง
- การสำรวจ
- ที่แสดงออก
- ส่วนขยาย
- ภายนอก
- โรงงาน
- คุ้นเคย
- FAST
- ลักษณะ
- ที่โดดเด่น
- คุณสมบัติ
- สองสาม
- รูป
- เนื้อไม่มีมัน
- ไฟล์
- หา
- ชื่อจริง
- ความยืดหยุ่น
- มีความยืดหยุ่น
- เที่ยวบิน
- โฟกัส
- ดังต่อไปนี้
- สำหรับ
- ต่างประเทศ
- รูป
- กรอบ
- ราคาเริ่มต้นที่
- อย่างเต็มที่
- อนาคต
- GDPR
- GitHub
- ให้
- กำหนด
- Go
- การกำกับดูแล
- บัญชีกลุ่ม
- ขึ้น
- Hadoop
- มี
- มี
- หนัก
- ยกของหนัก
- ช่วย
- ซ่อนเร้น
- ลำดับชั้น
- สูงกว่า
- ประวัติ
- รัง
- ถือ
- ถือ
- เจ้าภาพ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- ที่ http
- HTTPS
- AMI
- ID
- เอกลักษณ์
- Idle
- การดำเนินการ
- สำคัญ
- ด้านที่สำคัญ
- ปรับปรุง
- in
- รวมทั้ง
- โครงสร้างพื้นฐาน
- แทรก
- ตัวอย่าง
- ทันที
- รวม
- บูรณาการ
- Intelligence
- การโต้ตอบ
- ภายใน
- International
- ความเหงา
- ปัญหา
- IT
- รายการ
- ITS
- การสัมภาษณ์
- งาน
- การร่วม
- jpg
- เก็บ
- คีย์
- กุญแจ
- ความรู้
- ทะเลสาบ
- เปิดตัว
- การเปิดตัว
- ได้เรียนรู้
- การเรียนรู้
- facelift
- กดไลก์
- จดทะเบียน
- ชีวิต
- โหลด
- โหลด
- ที่ตั้ง
- ที่ต้องการหา
- เครื่อง
- เรียนรู้เครื่อง
- หลัก
- เก็บรักษา
- ทำให้
- การจัดการ
- จัดการ
- การจัดการ
- ผู้ผลิต
- หลาย
- ผสาน
- ผสาน
- เมตาดาต้า
- อาจ
- ล้าน
- นาที
- ML
- แบบ
- การสร้างแบบจำลอง
- โมเดล
- ทันสมัย
- การตรวจสอบ
- เดือน
- ข้อมูลเพิ่มเติม
- ยิ่งไปกว่านั้น
- หลาย
- ชื่อ
- ที่มีชื่อ
- การเดินเรือ
- จำเป็นต้อง
- จำเป็น
- สุทธิ
- ใหม่
- จำนวน
- of
- เก่า
- on
- ONE
- เปิด
- โอเพนซอร์ส
- ตัวเลือกเสริม (Option)
- ใบสั่ง
- organizacja
- องค์กร
- Organized
- อื่นๆ
- ของตนเอง
- หน้า
- บานหน้าต่าง
- เอกสาร
- หลงใหล
- เส้นทาง
- การจ่ายเงิน
- รูปแบบไฟล์ PDF
- การปฏิบัติ
- สถานที่
- แผนการ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ยอดนิยม
- โพสต์
- อำนาจ
- ขับเคลื่อน
- เตรียมการ
- ข้อกำหนดเบื้องต้น
- ก่อนหน้านี้
- ราคา
- ก่อน
- กระบวนการ
- กระบวนการ
- การประมวลผล
- กำไร
- ความคืบหน้า
- โครงการ
- คุณสมบัติ
- ให้
- ให้
- การให้
- บทบัญญัติ
- สาธารณะ
- การตีพิมพ์
- หนึ่งในสี่
- ดิบ
- เหตุผล
- บันทึก
- ลด
- กฎระเบียบ
- วางใจ
- ที่เหลืออยู่
- การรายงาน
- กรุ
- ต้อง
- การวิจัย
- ทรัพยากร
- แหล่งข้อมูล
- ผล
- ผลสอบ
- กลับ
- รวย
- บทบาท
- ม้วน
- วิ่ง
- วิ่ง
- การขาย
- ขาย
- เดียวกัน
- ที่ปรับขนาดได้
- ขนาด
- ปรับ
- วิทยาศาสตร์
- สคริปต์
- SDK
- ไร้รอยต่อ
- ได้อย่างลงตัว
- Section
- ส่วน
- ให้บริการ
- serverless
- เซิร์ฟเวอร์
- บริการ
- ชุด
- การตั้งค่า
- หลาย
- น่า
- โชว์
- แสดง
- ลงชื่อ
- ง่าย
- ที่เรียบง่าย
- ลดความซับซ้อน
- ขนาด
- ภาพย่อ
- ทางออก
- โซลูชัน
- แหล่ง
- จุดประกาย
- ผู้เชี่ยวชาญ
- โดยเฉพาะ
- SQL
- กอง
- เริ่มต้น
- ข้อความที่เริ่ม
- เริ่มต้น
- สถานะ
- สหรัฐอเมริกา
- ขั้นตอน
- หยุด
- การเก็บรักษา
- จัดเก็บ
- ร้านค้า
- ซื่อตรง
- กลยุทธ์
- ที่พริ้ว
- โครงสร้าง
- ข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง
- สตูดิโอ
- ส่ง
- ที่ประสบความสำเร็จ
- ประสบความสำเร็จ
- อย่างเช่น
- ที่สนับสนุน
- รองรับ
- สวิตซ์
- ตาราง
- TAG
- เอา
- ใช้เวลา
- งาน
- ภาษี
- ทีม
- เทคโนโลยี
- เทมเพลต
- ที่
- พื้นที่
- ก้าวสู่อนาคต
- ที่มา
- ของพวกเขา
- พวกเขา
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- สาม
- เวลา
- การเดินทางข้ามเวลา
- ต้องใช้เวลามาก
- การประทับเวลา
- ไปยัง
- ในวันนี้
- เครื่องมือ
- ด้านบน
- รวม
- ลู่
- การฝึกอบรม
- ธุรกรรม
- การทำธุรกรรม
- การแปลง
- เปลี่ยน
- การเดินทาง
- ui
- ปลดล็อค
- บันทึก
- ให้กับคุณ
- การปรับปรุง
- การใช้
- ใช้
- ผู้ใช้งาน
- ความคุ้มค่า
- ความหลากหลาย
- ต่างๆ
- สถานที่จัดงาน
- ตรวจสอบ
- รุ่น
- ผ่านทาง
- รายละเอียด
- คำแนะนำ
- คลังสินค้า
- การจัดเก็บสินค้า
- ทาง..
- เว็บ
- ดี
- ที่
- ในขณะที่
- WHO
- กว้าง
- จะ
- กับ
- ภายใน
- ไม่มี
- ทำงาน
- กลุ่มงาน
- ปี
- ปี
- ของคุณ
- ลมทะเล
- รหัสไปรษณีย์
- โซน
- ซูมเข้า