ออนเอ็นเอ็กซ์ (เปิด Neural Network Exchange) เป็นมาตรฐานโอเพ่นซอร์สสำหรับการแสดงโมเดลการเรียนรู้เชิงลึกที่ได้รับการสนับสนุนอย่างกว้างขวางจากผู้ให้บริการจำนวนมาก ONNX มีเครื่องมือสำหรับการเพิ่มประสิทธิภาพและการวัดปริมาณโมเดลเพื่อลดหน่วยความจำและการคำนวณที่จำเป็นในการเรียกใช้โมเดลแมชชีนเลิร์นนิง (ML) ประโยชน์ที่ใหญ่ที่สุดอย่างหนึ่งของ ONNX คือมีรูปแบบมาตรฐานสำหรับการแสดงและแลกเปลี่ยนโมเดล ML ระหว่างเฟรมเวิร์กและเครื่องมือต่างๆ ซึ่งช่วยให้นักพัฒนาสามารถฝึกโมเดลของตนในเฟรมเวิร์กหนึ่งและปรับใช้ในอีกเฟรมเวิร์กหนึ่ง โดยไม่จำเป็นต้องแปลงโมเดลหรือฝึกซ้ำมากมาย ด้วยเหตุผลเหล่านี้ ONNX จึงมีความสำคัญอย่างมากในชุมชน ML
ในโพสต์นี้ เราจะแสดงวิธีปรับใช้โมเดลที่ใช้ ONNX สำหรับปลายทางแบบหลายโมเดล (MME) ที่ใช้ GPU นี่คือความต่อเนื่องของโพสต์ เรียกใช้โมเดลการเรียนรู้เชิงลึกหลายรายการบน GPU ด้วยตำแหน่งข้อมูลหลายรุ่นของ Amazon SageMakerซึ่งเราได้แสดงวิธีการปรับใช้โมเดล ResNet50 เวอร์ชัน PyTorch และ TensorRT บนเซิร์ฟเวอร์ Triton Inference ของ Nvidia ในโพสต์นี้ เราใช้โมเดล ResNet50 เดียวกันในรูปแบบ ONNX พร้อมกับโมเดลตัวอย่างการประมวลผลภาษาธรรมชาติ (NLP) เพิ่มเติมในรูปแบบ ONNX เพื่อแสดงวิธีการปรับใช้บน Triton นอกจากนี้ เรายังเปรียบเทียบโมเดล ResNet50 และดูประโยชน์ด้านประสิทธิภาพที่ ONNX มีให้เมื่อเปรียบเทียบกับรุ่น PyTorch และ TensorRT ของรุ่นเดียวกัน โดยใช้อินพุตเดียวกัน

รันไทม์ ONNX
รันไทม์ ONNX เป็นเครื่องมือรันไทม์สำหรับการอนุมาน ML ที่ออกแบบมาเพื่อเพิ่มประสิทธิภาพการทำงานของโมเดลในแพลตฟอร์มฮาร์ดแวร์ต่างๆ รวมถึง CPU และ GPU อนุญาตให้ใช้เฟรมเวิร์ก ML เช่น PyTorch และ TensorFlow มันอำนวยความสะดวก การปรับแต่งประสิทธิภาพ เพื่อเรียกใช้โมเดลอย่างคุ้มค่าบนฮาร์ดแวร์เป้าหมายและรองรับคุณสมบัติต่างๆ เช่น quantization และการเร่งฮาร์ดแวร์ ทำให้เป็นหนึ่งในตัวเลือกที่เหมาะสมที่สุดสำหรับการปรับใช้แอปพลิเคชัน ML ที่มีประสิทธิภาพและประสิทธิภาพสูง สำหรับตัวอย่างวิธีการปรับแต่งโมเดล ONNX สำหรับ GPU ของ Nvidia ด้วย TensorRT โปรดดูที่ การเพิ่มประสิทธิภาพ TensorRT (ORT-TRT) และ รันไทม์ ONNX พร้อมการเพิ่มประสิทธิภาพ TensorRT.
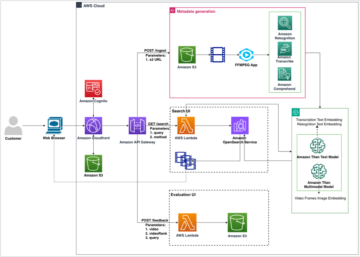
พื้นที่ อเมซอน SageMaker ตู้คอนเทนเนอร์ไทรทัน การไหลแสดงไว้ในไดอะแกรมต่อไปนี้
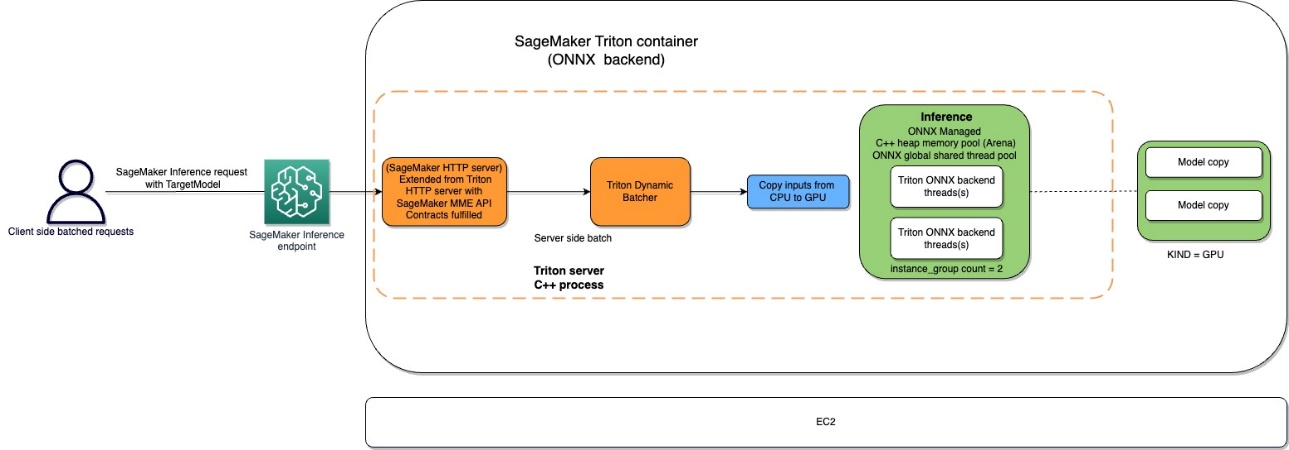
ผู้ใช้สามารถส่งคำขอ HTTPS พร้อมเพย์โหลดอินพุตสำหรับการอนุมานตามเวลาจริงที่อยู่เบื้องหลังตำแหน่งข้อมูล SageMaker ผู้ใช้สามารถระบุ TargetModel ส่วนหัวที่มีชื่อของรุ่นที่คำขอดังกล่าวถูกกำหนดให้เรียกใช้ ภายใน คอนเทนเนอร์ SageMaker Triton ใช้เซิร์ฟเวอร์ HTTP ที่มีสัญญาเดียวกันกับที่กล่าวถึง คอนเทนเนอร์ตอบสนองคำขออย่างไร. มีการรองรับการแบทช์แบบไดนามิกและรองรับทั้งหมด แบ็กเอนด์ที่ไทรทันมีให้. ตามการกำหนดค่า รันไทม์ ONNX จะถูกเรียกใช้และคำขอจะได้รับการประมวลผลบน CPU หรือ GPU ตามที่กำหนดไว้ล่วงหน้าในการกำหนดค่าโมเดลที่ผู้ใช้ให้มา
ภาพรวมโซลูชัน
หากต้องการใช้แบ็กเอนด์ ONNX ให้ทำตามขั้นตอนต่อไปนี้:
- รวบรวมโมเดลเป็นรูปแบบ ONNX
- กำหนดค่าโมเดล
- สร้างปลายทาง SageMaker
เบื้องต้น
ตรวจสอบว่าคุณมีสิทธิ์เข้าถึงบัญชี AWS ที่เพียงพอ AWS Identity และการจัดการการเข้าถึง สิทธิ์ IAM ในการสร้างสมุดบันทึก เข้าถึง บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon บัคเก็ต (Amazon S3) และปรับใช้โมเดลกับตำแหน่งข้อมูล SageMaker ดู สร้างบทบาทการดำเนินการ สำหรับข้อมูลเพิ่มเติม
รวบรวมโมเดลเป็นรูปแบบ ONNX
ไลบรารี Transformers มีวิธีการที่สะดวกในการคอมไพล์โมเดล PyTorch เป็นรูปแบบ ONNX รหัสต่อไปนี้บรรลุการแปลงสำหรับโมเดล NLP:
การส่งออกโมเดล (ทั้ง PyTorch หรือ TensorFlow) ทำได้อย่างง่ายดายผ่านเครื่องมือการแปลงที่จัดเตรียมไว้ให้โดยเป็นส่วนหนึ่งของที่เก็บ Hugging Face Transformers
ต่อไปนี้คือสิ่งที่เกิดขึ้นภายใต้ประทุน:
- จัดสรรโมเดลจากหม้อแปลง (PyTorch หรือ TensorFlow)
- ส่งต่ออินพุตดัมมี่ผ่านโมเดล ด้วยวิธีนี้ ONNX สามารถบันทึกชุดการดำเนินการที่รันได้
- หม้อแปลงจะดูแลแกนไดนามิกโดยเนื้อแท้เมื่อส่งออกโมเดล
- บันทึกกราฟพร้อมกับพารามิเตอร์เครือข่าย
มีการใช้กลไกที่คล้ายกันสำหรับกรณีการใช้คอมพิวเตอร์วิทัศน์จากสวนสัตว์จำลองคบเพลิง:
กำหนดค่าโมเดล
ในส่วนนี้ เรากำหนดค่าการมองเห็นของคอมพิวเตอร์และโมเดล NLP เราแสดงวิธีสร้างโมเดลขนาดใหญ่ ResNet50 และ RoBERTA ที่ได้รับการฝึกอบรมล่วงหน้าสำหรับการปรับใช้บน SageMaker MME โดยใช้การกำหนดค่าโมเดล Triton Inference Server โน้ตบุ๊ก ResNet50 พร้อมใช้งานบน GitHub. โน้ตบุ๊ก RoBERTA ก็มีจำหน่ายเช่นกัน GitHub. สำหรับ ResNet50 เราใช้วิธี Docker เพื่อสร้างสภาพแวดล้อมที่มีการขึ้นต่อกันทั้งหมดที่จำเป็นสำหรับการสร้างโมเดล ONNX ของเราอยู่แล้ว และสร้างอาร์ติแฟกต์โมเดลที่จำเป็นสำหรับแบบฝึกหัดนี้ วิธีการนี้ทำให้การแบ่งปันการอ้างอิงและสร้างสภาพแวดล้อมที่แน่นอนซึ่งจำเป็นต่อการทำงานนี้ให้สำเร็จนั้นง่ายขึ้นมาก
ขั้นตอนแรกคือการสร้างแพ็คเกจโมเดล ONNX ตามโครงสร้างไดเร็กทอรีที่ระบุใน รุ่น ONNX. เป้าหมายของเราคือการใช้ที่เก็บโมเดลขั้นต่ำสำหรับโมเดล ONNX ที่มีอยู่ในไฟล์เดียวดังนี้:
ต่อไปเราจะสร้าง การกำหนดค่าแบบจำลอง ไฟล์ที่อธิบายอินพุต เอาต์พุต และการกำหนดค่าแบ็คเอนด์สำหรับ Triton Server เพื่อรับและเรียกใช้เคอร์เนลที่เหมาะสมสำหรับ ONNX ไฟล์นี้เรียกว่า config.pbtxt และแสดงในรหัสต่อไปนี้สำหรับกรณีการใช้งานของ ROBERTA โปรดทราบว่า BATCH มิติข้อมูลถูกตัดออกจาก config.pbtxt. อย่างไรก็ตาม เมื่อส่งข้อมูลไปยังโมเดล เราจะรวมมิติแบทช์ไว้ด้วย รหัสต่อไปนี้ยังแสดงวิธีที่คุณสามารถเพิ่มคุณสมบัตินี้ด้วยไฟล์การกำหนดค่าแบบจำลองเพื่อตั้งค่าการแบทช์แบบไดนามิกด้วยขนาดแบทช์ที่ต้องการเป็น 5 สำหรับการอนุมานจริง ด้วยการตั้งค่าปัจจุบัน อินสแตนซ์โมเดลจะถูกเรียกใช้ทันทีเมื่อถึงขนาดแบทช์ที่ต้องการที่ 5 หรือเวลาหน่วง 100 ไมโครวินาทีผ่านไปตั้งแต่คำขอแรกมาถึงแบทช์แบบไดนามิก
ต่อไปนี้คือไฟล์การกำหนดค่าที่คล้ายกันสำหรับกรณีการใช้งานการมองเห็นของคอมพิวเตอร์:
สร้างปลายทาง SageMaker
เราใช้ Boto3 API เพื่อสร้างปลายทาง SageMaker สำหรับโพสต์นี้ เราแสดงขั้นตอนสำหรับโน้ตบุ๊ก RoBERTA แต่เป็นขั้นตอนทั่วไป และจะเหมือนกันสำหรับรุ่น ResNet50 เช่นกัน
สร้างโมเดล SageMaker
ตอนนี้เราสร้าง รุ่น SageMaker. เราใช้ การลงทะเบียน Amazon Elastic Container รูปภาพ (Amazon ECR) และสิ่งประดิษฐ์แบบจำลองจากขั้นตอนก่อนหน้าเพื่อสร้างแบบจำลอง SageMaker
สร้างคอนเทนเนอร์
ในการสร้างคอนเทนเนอร์ เราดึง ภาพที่เหมาะสม จาก Amazon ECR สำหรับ Triton Server SageMaker ช่วยให้เราสามารถปรับแต่งและใส่ตัวแปรสภาพแวดล้อมต่างๆ คุณสมบัติหลักบางประการคือความสามารถในการตั้งค่า BATCH_SIZE; เราสามารถตั้งค่านี้ต่อรุ่นใน config.pbtxt ไฟล์ หรือเราสามารถกำหนดค่าเริ่มต้นได้ที่นี่ สำหรับรุ่นที่จะได้รับประโยชน์จากขนาดหน่วยความจำที่ใช้ร่วมกันที่ใหญ่ขึ้น เราสามารถตั้งค่าเหล่านั้นภายใต้ SHM ตัวแปร หากต้องการเปิดใช้งานการบันทึก ให้ตั้งค่าบันทึก verbose ระดับถึง true. เราใช้รหัสต่อไปนี้เพื่อสร้างแบบจำลองเพื่อใช้ในจุดสิ้นสุดของเรา:
สร้างจุดสิ้นสุด SageMaker
คุณสามารถใช้อินสแตนซ์ใดก็ได้กับ GPU หลายตัวสำหรับการทดสอบ ในโพสต์นี้ เราใช้อินสแตนซ์ g4dn.4xlarge เราไม่ได้ตั้งค่า VolumeSizeInGB พารามิเตอร์เนื่องจากอินสแตนซ์นี้มาพร้อมกับที่จัดเก็บอินสแตนซ์ในเครื่อง เดอะ VolumeSizeInGB พารามิเตอร์ใช้ได้กับอินสแตนซ์ GPU ที่รองรับ ร้านค้า Amazon Elastic Block ไฟล์แนบปริมาณ (Amazon EBS) เราสามารถปล่อยให้การหมดเวลาดาวน์โหลดโมเดลและการตรวจสอบความสมบูรณ์ของการเริ่มต้นคอนเทนเนอร์เป็นค่าเริ่มต้น สำหรับรายละเอียดเพิ่มเติม โปรดดูที่ สร้าง EndpointConfig.
สุดท้ายนี้ เราสร้างจุดสิ้นสุด SageMaker:
เรียกใช้จุดสิ้นสุดของโมเดล
นี่เป็นแบบจำลองเชิงกำเนิด เราจึงผ่านใน input_ids และ attention_mask ไปยังโมเดลโดยเป็นส่วนหนึ่งของเพย์โหลด รหัสต่อไปนี้แสดงวิธีการสร้างเทนเซอร์:
ตอนนี้เราสร้างเพย์โหลดที่เหมาะสมโดยตรวจสอบให้แน่ใจว่าประเภทข้อมูลตรงกับที่เรากำหนดค่าไว้ใน config.pbtxt. นอกจากนี้ยังให้เทนเซอร์พร้อมมิติแบทช์ซึ่งเป็นสิ่งที่ Triton คาดหวัง เราใช้รูปแบบ JSON เพื่อเรียกใช้โมเดล Triton ยังมีวิธีการเรียกใช้แบบไบนารีแบบเนทีฟสำหรับโมเดล
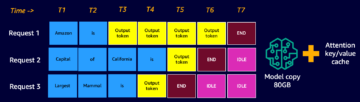
หมายเหตุ TargetModel พารามิเตอร์ในรหัสก่อนหน้า เราส่งชื่อของโมเดลที่จะเรียกใช้เป็นส่วนหัวของคำขอเนื่องจากนี่คือจุดสิ้นสุดแบบหลายรุ่น ดังนั้นเราจึงสามารถเรียกใช้หลายรุ่นในขณะรันไทม์บนจุดสิ้นสุดการอนุมานที่ปรับใช้แล้วโดยการเปลี่ยนพารามิเตอร์นี้ นี่แสดงให้เห็นถึงพลังของอุปกรณ์ปลายทางหลายรุ่น!
เราสามารถใช้รหัสต่อไปนี้ในการส่งออกการตอบสนอง:
ONNX สำหรับการปรับแต่งประสิทธิภาพ
แบ็กเอนด์ ONNX ใช้การจัดสรรหน่วยความจำ C++ arena การจัดสรร Arena เป็นคุณลักษณะเฉพาะของ C++ เท่านั้นที่ช่วยคุณเพิ่มประสิทธิภาพการใช้หน่วยความจำและปรับปรุงประสิทธิภาพ การจัดสรรหน่วยความจำและการจัดสรรคืนถือเป็นส่วนสำคัญของเวลา CPU ที่ใช้ในรหัสบัฟเฟอร์ของโปรโตคอล ตามค่าเริ่มต้น การสร้างออบเจกต์ใหม่จะทำการจัดสรรแบบฮีปสำหรับแต่ละออบเจ็กต์ แต่ละอ็อบเจ็กต์ย่อย และฟิลด์หลายประเภท เช่น สตริง การจัดสรรเหล่านี้เกิดขึ้นเป็นกลุ่มเมื่อแยกวิเคราะห์ข้อความและเมื่อสร้างข้อความใหม่ในหน่วยความจำ และการจัดสรรคืนที่เกี่ยวข้องจะเกิดขึ้นเมื่อข้อความและทรีออบเจ็กต์ย่อยว่าง
การจัดสรรตามอารีน่าได้รับการออกแบบเพื่อลดต้นทุนประสิทธิภาพนี้ ด้วยการจัดสรรอารีน่า วัตถุใหม่จะถูกจัดสรรจากหน่วยความจำขนาดใหญ่ที่จัดสรรไว้ล่วงหน้าซึ่งเรียกว่า สนามกีฬา. ออบเจกต์ทั้งหมดสามารถปลดปล่อยได้ในคราวเดียวโดยการทิ้งอารีน่าทั้งหมด โดยไม่ต้องใช้ตัวทำลายของวัตถุที่มีอยู่ (แม้ว่าอารีน่าจะยังสามารถรักษารายการตัวทำลายได้เมื่อจำเป็น) สิ่งนี้ทำให้การจัดสรรออบเจกต์เร็วขึ้นโดยการลดการเพิ่มพอยน์เตอร์อย่างง่าย และทำให้การจัดสรรคืนเกือบจะฟรี การจัดสรร Arena ยังให้ประสิทธิภาพแคชที่สูงกว่า: เมื่อมีการแยกวิเคราะห์ข้อความ ข้อความเหล่านั้นมีแนวโน้มที่จะได้รับการจัดสรรในหน่วยความจำต่อเนื่อง ซึ่งทำให้การข้ามผ่านข้อความมีโอกาสมากขึ้นที่จะเข้าถึง Hot Cache Line ข้อเสียของการจัดสรรตามอารีน่าคือหน่วยความจำฮีปของ C++ จะถูกจัดสรรมากเกินไปและยังคงจัดสรรต่อไปแม้ว่าออบเจกต์จะถูกจัดสรรคืนแล้วก็ตาม ซึ่งอาจนำไปสู่การใช้หน่วยความจำไม่เพียงพอหรือใช้หน่วยความจำ CPU สูง เพื่อให้ได้สิ่งที่ดีที่สุดจากทั้งสองโลก เราใช้การกำหนดค่าต่อไปนี้ซึ่งจัดทำโดย ไทรทัน และ ONNX:
- arena_extend_strategy – พารามิเตอร์นี้อ้างถึงกลยุทธ์ที่ใช้ในการขยายพื้นที่หน่วยความจำโดยคำนึงถึงขนาดของโมเดล เราขอแนะนำให้ตั้งค่าเป็น 1 (=
kSameAsRequested) ซึ่งไม่ใช่ค่าเริ่มต้น เหตุผลมีดังนี้: ข้อเสียเปรียบของกลยุทธ์การขยายเวทีเริ่มต้น (kNextPowerOfTwo) คืออาจจัดสรรหน่วยความจำมากเกินความจำเป็น ซึ่งอาจทำให้สิ้นเปลือง ตามชื่อที่แนะนำkNextPowerOfTwo(ค่าเริ่มต้น) ขยายอารีน่าด้วยพลัง 2 ในขณะที่kSameAsRequestedขยายตามขนาดที่เหมือนกับคำขอจัดสรรในแต่ละครั้งkSameAsRequestedเหมาะสำหรับการกำหนดค่าขั้นสูงที่คุณทราบการใช้หน่วยความจำที่คาดไว้ล่วงหน้า ในการทดสอบของเรา เนื่องจากเราทราบดีว่าขนาดของโมเดลมีค่าคงที่ เราจึงสามารถเลือกได้อย่างปลอดภัยkSameAsRequested. - GPU_mem_limit – เราตั้งค่าเป็นขีดจำกัดหน่วยความจำ CUDA หากต้องการใช้หน่วยความจำที่เป็นไปได้ทั้งหมด ให้ป้อนค่าสูงสุด
size_t. มีค่าเริ่มต้นเป็นSIZE_MAXหากไม่ได้ระบุไว้ เราขอแนะนำให้เก็บไว้เป็นค่าเริ่มต้น - Enable_cpu_mem_arena – สิ่งนี้เปิดใช้งานเวทีหน่วยความจำบน CPU อารีน่าอาจจัดสรรหน่วยความจำล่วงหน้าสำหรับการใช้งานในอนาคต ตั้งค่าตัวเลือกนี้เป็น
falseถ้าคุณไม่ต้องการมัน ค่าเริ่มต้นคือTrue. หากคุณปิดใช้งานอารีน่า การจัดสรรหน่วยความจำแบบฮีปจะใช้เวลา ดังนั้นเวลาแฝงในการอนุมานจะเพิ่มขึ้น ในการทดสอบของเรา เราปล่อยไว้เป็นค่าเริ่มต้น - Enable_mem_pattern – พารามิเตอร์นี้อ้างถึงกลยุทธ์การจัดสรรหน่วยความจำภายในตามรูปร่างอินพุต ถ้ารูปร่างคงที่ เราสามารถเปิดใช้งานพารามิเตอร์นี้เพื่อสร้างรูปแบบหน่วยความจำสำหรับอนาคตและประหยัดเวลาในการจัดสรร ทำให้เร็วขึ้น ใช้ 1 เพื่อเปิดใช้งานรูปแบบหน่วยความจำและ 0 เพื่อปิดใช้งาน ขอแนะนำให้ตั้งค่านี้เป็น 1 เมื่อคาดว่าคุณลักษณะอินพุตจะเหมือนกัน ค่าเริ่มต้นคือ 1
- do_copy_in_default_stream – ในบริบทของผู้ให้บริการการดำเนินการ CUDA ใน ONNX สตรีมการประมวลผลคือลำดับของการดำเนินการ CUDA ที่ทำงานแบบอะซิงโครนัสบน GPU รันไทม์ ONNX กำหนดการดำเนินการในสตรีมต่างๆ ตามการพึ่งพา ซึ่งช่วยลดเวลาว่างของ GPU และทำให้ประสิทธิภาพดีขึ้น ขอแนะนำให้ใช้การตั้งค่าเริ่มต้นที่ 1 สำหรับการใช้สตรีมเดียวกันสำหรับการคัดลอกและคำนวณ อย่างไรก็ตาม คุณสามารถใช้ 0 เพื่อใช้สตรีมแยกกันสำหรับการคัดลอกและประมวลผล ซึ่งอาจส่งผลให้อุปกรณ์ไปป์ไลน์ทั้งสองกิจกรรม ในการทดสอบโมเดล ResNet50 เราใช้ทั้ง 0 และ 1 แต่ไม่พบความแตกต่างที่เห็นได้ชัดเจนระหว่างทั้งสองในแง่ของประสิทธิภาพและการใช้หน่วยความจำของอุปกรณ์ GPU
- การเพิ่มประสิทธิภาพกราฟ – แบ็กเอนด์ ONNX สำหรับ Triton รองรับพารามิเตอร์หลายตัวที่ช่วยปรับขนาดโมเดลอย่างละเอียดรวมถึงประสิทธิภาพรันไทม์ของโมเดลที่ปรับใช้ เมื่อโมเดลถูกแปลงเป็นตัวแทน ONNX (ช่องแรกในไดอะแกรมต่อไปนี้ที่ระยะ IR) รันไทม์ ONNX ให้การเพิ่มประสิทธิภาพกราฟในสามระดับ: การปรับพื้นฐาน ขยาย และเค้าโครง คุณสามารถเปิดใช้งานการเพิ่มประสิทธิภาพกราฟทุกระดับโดยเพิ่มพารามิเตอร์ต่อไปนี้ในไฟล์การกำหนดค่าโมเดล:
- cudnn_conv_algo_search – เนื่องจากเราใช้ GPU Nvidia ที่ใช้ CUDA ในการทดสอบของเรา สำหรับกรณีการใช้งานคอมพิวเตอร์วิทัศน์ของเรากับโมเดล ResNet50 เราจึงสามารถใช้การเพิ่มประสิทธิภาพตามผู้ให้บริการการประมวลผล CUDA ที่เลเยอร์ที่สี่ในไดอะแกรมต่อไปนี้ด้วย
cudnn_conv_algo_searchพารามิเตอร์. ตัวเลือกเริ่มต้นคือสมบูรณ์ (0) แต่เมื่อเราเปลี่ยนการกำหนดค่านี้เป็น1 – HEURISTICเราเห็นเวลาแฝงของโมเดลในสถานะคงที่ลดลงเหลือ 160 มิลลิวินาที สาเหตุนี้เกิดขึ้นเนื่องจากรันไทม์ ONNX เรียกใช้น้ำหนักที่เบากว่า cudnnGetConvolutionForwardAlgorithm_v7 การส่งผ่านไปข้างหน้าจึงช่วยลดเวลาแฝงด้วยประสิทธิภาพที่เพียงพอ - โหมดวิ่ง – ขั้นตอนต่อไปคือการเลือกที่ถูกต้อง การดำเนินการ_โหมด ที่เลเยอร์ 5 ในไดอะแกรมต่อไปนี้ พารามิเตอร์นี้ควบคุมว่าคุณต้องการเรียกใช้ตัวดำเนินการในกราฟของคุณตามลำดับหรือแบบขนาน โดยปกติเมื่อโมเดลมีหลายสาขา การตั้งค่าตัวเลือกนี้เป็น
ExecutionMode.ORT_PARALLEL(1) จะทำให้คุณมีประสิทธิภาพที่ดีขึ้น ในสถานการณ์ที่โมเดลของคุณมีหลายกิ่งในกราฟ การตั้งค่าโหมดการทำงานเป็นแบบขนานจะช่วยให้มีประสิทธิภาพดีขึ้น โหมดเริ่มต้นคือโหมดต่อเนื่อง คุณจึงสามารถเปิดใช้งานโหมดนี้ให้เหมาะกับความต้องการของคุณได้
สำหรับความเข้าใจที่ลึกซึ้งยิ่งขึ้นเกี่ยวกับโอกาสในการปรับแต่งประสิทธิภาพใน ONNX โปรดดูรูปต่อไปนี้
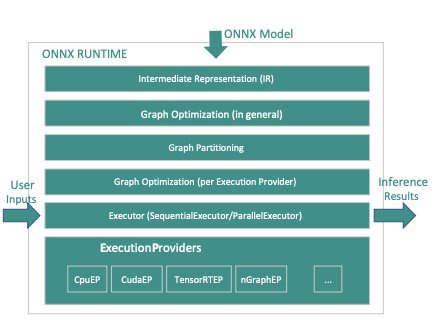
ตัวเลขเกณฑ์มาตรฐานและการปรับแต่งประสิทธิภาพ
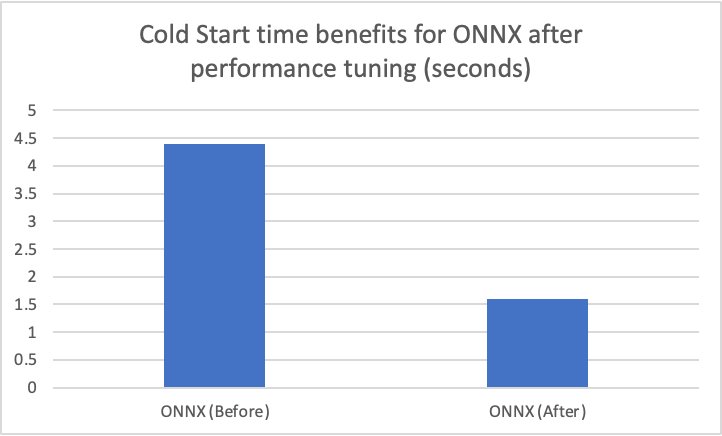
เมื่อเปิดการเพิ่มประสิทธิภาพกราฟ cudnn_conv_algo_searchและพารามิเตอร์โหมดการทำงานแบบขนานในการทดสอบโมเดล ResNet50 เราพบว่าเวลาเริ่มต้นเย็นของกราฟโมเดล ONNX ลดลงจาก 4.4 วินาทีเป็น 1.61 วินาที ตัวอย่างของไฟล์คอนฟิกูเรชันโมเดลที่สมบูรณ์มีอยู่ในส่วนคอนฟิกูเรชัน ONNX ต่อไปนี้ สมุดบันทึก.
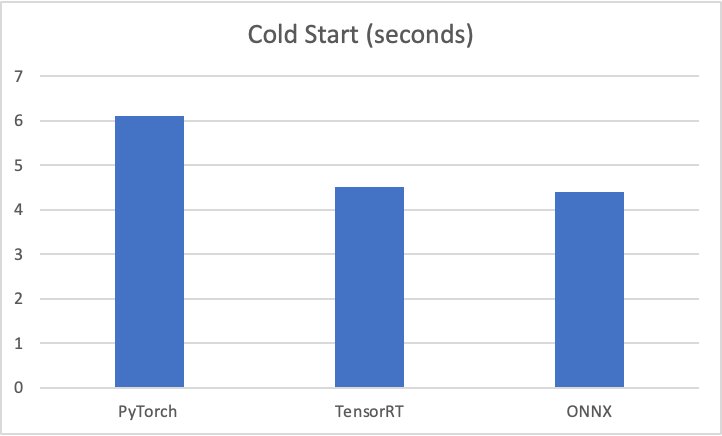
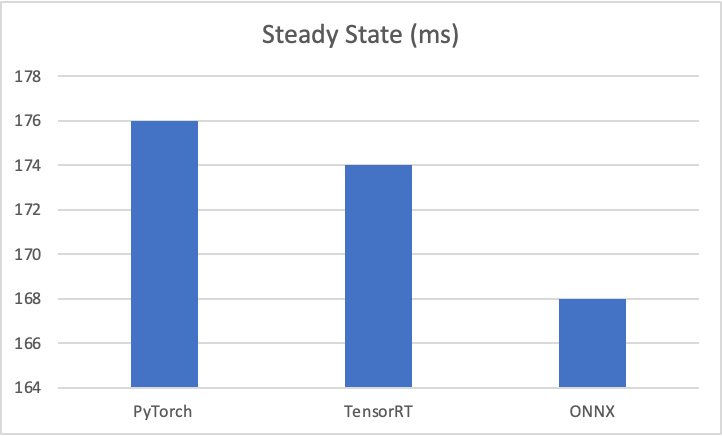
ผลเกณฑ์มาตรฐานการทดสอบมีดังนี้:
- ไพทอร์ช – 176 มิลลิวินาที เริ่มเย็น 6 วินาที
- เทนเซอร์RT – 174 มิลลิวินาที เริ่มเย็น 4.5 วินาที
- ออนเอ็นเอ็กซ์ – 168 มิลลิวินาที เริ่มเย็น 4.4 วินาที
กราฟต่อไปนี้แสดงภาพเมตริกเหล่านี้
นอกจากนี้ ในการทดสอบกรณีการใช้งานการมองเห็นด้วยคอมพิวเตอร์ของเรา ให้ลองส่งคำขอเพย์โหลดในรูปแบบไบนารีโดยใช้ไคลเอ็นต์ HTTP ที่ Triton จัดหาให้ เนื่องจากช่วยปรับปรุงการเรียกใช้โมเดลได้อย่างมาก
พารามิเตอร์อื่นๆ ที่ SageMaker แสดงสำหรับ ONNX บน Triton มีดังนี้:
- การแบ่งกลุ่มแบบไดนามิก – การแบทช์แบบไดนามิกเป็นคุณสมบัติของ Triton ที่อนุญาตให้รวมคำขอการอนุมานโดยเซิร์ฟเวอร์ เพื่อให้แบทช์ถูกสร้างขึ้นแบบไดนามิก การสร้างคำขอเป็นชุดมักจะส่งผลให้ปริมาณงานเพิ่มขึ้น ควรใช้แบทช์แบบไดนามิกสำหรับโมเดลไร้สถานะ ชุดงานที่สร้างขึ้นแบบไดนามิกจะถูกแจกจ่ายไปยังอินสแตนซ์โมเดลทั้งหมดที่กำหนดค่าสำหรับโมเดล
- ขนาดแบทช์สูงสุด -
max_batch_sizeคุณสมบัติระบุขนาดแบทช์สูงสุดที่โมเดลรองรับสำหรับ ประเภทของการแบทช์ ที่ไทรทันใช้ประโยชน์ได้ หากมิติแบทช์ของโมเดลเป็นมิติแรก และอินพุตและเอาต์พุตทั้งหมดของโมเดลมีมิติแบทช์นี้ Triton สามารถใช้ ตัวแบทช์แบบไดนามิก or ตัวแบ่งลำดับ เพื่อใช้การแบทช์กับโมเดลโดยอัตโนมัติ ในกรณีนี้,max_batch_sizeควรตั้งค่าเป็นค่าที่มากกว่าหรือเท่ากับ 1 ซึ่งระบุขนาดแบทช์สูงสุดที่ Triton ควรใช้กับรุ่นดังกล่าว - ขนาดแบทช์สูงสุดเริ่มต้น – ใช้ค่าขนาดแบทช์เริ่มต้นสูงสุดสำหรับ
max_batch_sizeในระหว่าง ข้อมูลอัตโนมัติ เมื่อไม่พบค่าอื่น เดอะonnxruntimeแบ็กเอนด์จะตั้งค่าmax_batch_sizeของโมเดลให้เป็นค่าเริ่มต้นนี้ หากการเติมข้อความอัตโนมัติได้พิจารณาแล้วว่าโมเดลนั้นสามารถขอแบทช์ได้ และmax_batch_sizeเป็น 0 ในการกำหนดค่าโมเดลหรือmax_batch_sizeถูกตัดออกจากการกำหนดค่าโมเดล ถ้าmax_batch_sizeมากกว่า 1 และไม่ใช่ กำหนดการ มีให้ จะใช้ตัวจัดกำหนดการแบทช์แบบไดนามิก ขนาดแบทช์สูงสุดเริ่มต้นคือ 4
ทำความสะอาด
ตรวจสอบให้แน่ใจว่าคุณลบโมเดล การกำหนดค่าโมเดล และจุดสิ้นสุดของโมเดลหลังจากเรียกใช้โน้ตบุ๊ก ขั้นตอนในการดำเนินการนี้มีให้ที่ส่วนท้ายของสมุดบันทึกตัวอย่างใน GitHub ซื้อคืน
สรุป
ในโพสต์นี้ เราจะลงลึกถึงแบ็คเอนด์ ONNX ที่ Triton Inference Server รองรับบน SageMaker แบ็กเอนด์นี้ให้การเร่ง GPU ของรุ่น ONNX ของคุณ มีตัวเลือกมากมายให้พิจารณาเพื่อให้ได้ประสิทธิภาพสูงสุดสำหรับการอนุมาน เช่น ขนาดแบทช์ รูปแบบการป้อนข้อมูล และปัจจัยอื่นๆ ที่สามารถปรับให้ตรงกับความต้องการของคุณ SageMaker ให้คุณใช้ความสามารถนี้โดยใช้จุดสิ้นสุดแบบรุ่นเดียวและหลายรุ่น MME ช่วยให้ประสิทธิภาพการทำงานดีขึ้นและประหยัดต้นทุน หากต้องการเริ่มต้นใช้งานการรองรับ MME สำหรับ GPU โปรดดู โฮสต์หลายรุ่นในคอนเทนเนอร์เดียวหลังปลายทางเดียว.
เราขอเชิญคุณลองใช้คอนเทนเนอร์ Triton Inference Server ใน SageMaker และแบ่งปันความคิดเห็นและคำถามของคุณในความคิดเห็น
เกี่ยวกับผู้แต่ง
 อภิศิวะดิตยา เป็นสถาปนิกโซลูชันอาวุโสของ AWS ซึ่งทำงานร่วมกับองค์กรระดับองค์กรเชิงกลยุทธ์ทั่วโลกเพื่ออำนวยความสะดวกในการนำบริการของ AWS ไปใช้ในด้านต่างๆ เช่น ปัญญาประดิษฐ์ การประมวลผลแบบกระจาย ระบบเครือข่าย และพื้นที่จัดเก็บ ความเชี่ยวชาญของเขาอยู่ในการเรียนรู้เชิงลึกในโดเมนของ Natural Language Processing (NLP) และ Computer Vision Abhi ช่วยเหลือลูกค้าในการปรับใช้โมเดลแมชชีนเลิร์นนิงประสิทธิภาพสูงอย่างมีประสิทธิภาพภายในระบบนิเวศของ AWS
อภิศิวะดิตยา เป็นสถาปนิกโซลูชันอาวุโสของ AWS ซึ่งทำงานร่วมกับองค์กรระดับองค์กรเชิงกลยุทธ์ทั่วโลกเพื่ออำนวยความสะดวกในการนำบริการของ AWS ไปใช้ในด้านต่างๆ เช่น ปัญญาประดิษฐ์ การประมวลผลแบบกระจาย ระบบเครือข่าย และพื้นที่จัดเก็บ ความเชี่ยวชาญของเขาอยู่ในการเรียนรู้เชิงลึกในโดเมนของ Natural Language Processing (NLP) และ Computer Vision Abhi ช่วยเหลือลูกค้าในการปรับใช้โมเดลแมชชีนเลิร์นนิงประสิทธิภาพสูงอย่างมีประสิทธิภาพภายในระบบนิเวศของ AWS
 เจมส์พาร์ค เป็นสถาปนิกโซลูชันที่ Amazon Web Services เขาทำงานร่วมกับ Amazon.com ในการออกแบบ สร้าง และปรับใช้โซลูชันเทคโนโลยีบน AWS และมีความสนใจเป็นพิเศษใน AI และการเรียนรู้ของเครื่อง ในเวลาว่างเขาชอบที่จะแสวงหาวัฒนธรรมใหม่ๆ ประสบการณ์ใหม่ๆ และติดตามเทรนด์เทคโนโลยีล่าสุด คุณสามารถพบเขาได้ที่ LinkedIn.
เจมส์พาร์ค เป็นสถาปนิกโซลูชันที่ Amazon Web Services เขาทำงานร่วมกับ Amazon.com ในการออกแบบ สร้าง และปรับใช้โซลูชันเทคโนโลยีบน AWS และมีความสนใจเป็นพิเศษใน AI และการเรียนรู้ของเครื่อง ในเวลาว่างเขาชอบที่จะแสวงหาวัฒนธรรมใหม่ๆ ประสบการณ์ใหม่ๆ และติดตามเทรนด์เทคโนโลยีล่าสุด คุณสามารถพบเขาได้ที่ LinkedIn.
 รูพินเดอร์ กรีวาล เป็น Sr Ai/ML Specialist Solutions Architect กับ AWS ปัจจุบันเขามุ่งเน้นการให้บริการโมเดลและ MLOps บน SageMaker ก่อนหน้าจะรับตำแหน่งนี้ เขาเคยทำงานเป็นวิศวกรด้านการเรียนรู้ของเครื่องจักรในการสร้างและโฮสต์โมเดล นอกเวลางาน เขาชอบเล่นเทนนิสและขี่จักรยานบนเส้นทางบนภูเขา
รูพินเดอร์ กรีวาล เป็น Sr Ai/ML Specialist Solutions Architect กับ AWS ปัจจุบันเขามุ่งเน้นการให้บริการโมเดลและ MLOps บน SageMaker ก่อนหน้าจะรับตำแหน่งนี้ เขาเคยทำงานเป็นวิศวกรด้านการเรียนรู้ของเครื่องจักรในการสร้างและโฮสต์โมเดล นอกเวลางาน เขาชอบเล่นเทนนิสและขี่จักรยานบนเส้นทางบนภูเขา
 ดาวัล พาเทล เป็นหัวหน้าสถาปนิก Machine Learning ที่ AWS เขาได้ทำงานร่วมกับองค์กรต่างๆ ตั้งแต่องค์กรขนาดใหญ่ไปจนถึงสตาร์ทอัพขนาดกลางในปัญหาที่เกี่ยวข้องกับการคำนวณแบบกระจายและปัญญาประดิษฐ์ เขามุ่งเน้นไปที่การเรียนรู้อย่างลึกซึ้งรวมถึงโดเมน NLP และ Computer Vision เขาช่วยให้ลูกค้าบรรลุการอนุมานแบบจำลองประสิทธิภาพสูงบน SageMaker
ดาวัล พาเทล เป็นหัวหน้าสถาปนิก Machine Learning ที่ AWS เขาได้ทำงานร่วมกับองค์กรต่างๆ ตั้งแต่องค์กรขนาดใหญ่ไปจนถึงสตาร์ทอัพขนาดกลางในปัญหาที่เกี่ยวข้องกับการคำนวณแบบกระจายและปัญญาประดิษฐ์ เขามุ่งเน้นไปที่การเรียนรู้อย่างลึกซึ้งรวมถึงโดเมน NLP และ Computer Vision เขาช่วยให้ลูกค้าบรรลุการอนุมานแบบจำลองประสิทธิภาพสูงบน SageMaker
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- การเงิน EVM ส่วนต่อประสานแบบครบวงจรสำหรับการเงินแบบกระจายอำนาจ เข้าถึงได้ที่นี่.
- กลุ่มสื่อควอนตัม IR/PR ขยาย เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. ข้อมูลอัจฉริยะ Web3 ขยายความรู้ เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/host-ml-models-on-amazon-sagemaker-using-triton-onnx-models/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 1
- 100
- 11
- 13
- 14
- 16
- 20
- 200
- 22
- 224
- 7
- 9
- a
- ความสามารถ
- การเร่งความเร็ว
- เข้า
- บรรลุผล
- ลงชื่อเข้าใช้
- บรรลุ
- ประสบความสำเร็จ
- ประสบความสำเร็จ
- ข้าม
- กิจกรรม
- ที่เกิดขึ้นจริง
- เพิ่ม
- เพิ่ม
- เพิ่มเติม
- การนำมาใช้
- ความก้าวหน้า
- สูง
- หลังจาก
- AI
- AI / ML
- จุดมุ่งหมาย
- ทั้งหมด
- จัดสรร
- การจัดสรร
- การจัดสรร
- อนุญาต
- ช่วยให้
- ตาม
- แล้ว
- ด้วย
- อเมซอน
- อเมซอน SageMaker
- Amazon Web Services
- Amazon.com
- an
- และ
- อื่น
- ใด
- APIs
- เหมาะสม
- การใช้งาน
- เข้าใกล้
- เหมาะสม
- เป็น
- พื้นที่
- สนามกีฬา
- เทียม
- ปัญญาประดิษฐ์
- AS
- ช่วย
- ที่เกี่ยวข้อง
- At
- ข้อมูลอัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- AWS
- แกน
- กลับ
- แบ็กเอนด์
- ยอดคงเหลือ
- ตาม
- ขั้นพื้นฐาน
- BE
- เพราะ
- รับ
- หลัง
- มาตรฐาน
- ประโยชน์
- ประโยชน์ที่ได้รับ
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- ที่ใหญ่ที่สุด
- ปิดกั้น
- ร่างกาย
- ทั้งสอง
- กล่อง
- สาขา
- สร้าง
- การก่อสร้าง
- แต่
- by
- C + +
- แคช
- ที่เรียกว่า
- CAN
- สามารถ
- ซึ่ง
- กรณี
- กรณี
- การเปลี่ยนแปลง
- เปลี่ยนแปลง
- ตรวจสอบ
- ทางเลือก
- Choose
- ไคลเอนต์
- รหัส
- ผู้สมัครที่ไม่รู้จัก
- COM
- รวม
- มา
- ความคิดเห็น
- ร่วมกัน
- ชุมชน
- เมื่อเทียบกับ
- สมบูรณ์
- คำนวณ
- คอมพิวเตอร์
- วิสัยทัศน์คอมพิวเตอร์
- การคำนวณ
- องค์ประกอบ
- การกำหนดค่า
- พิจารณา
- คงที่
- การบริโภค
- ที่มีอยู่
- ภาชนะ
- ภาชนะบรรจุ
- มี
- สิ่งแวดล้อม
- ความต่อเนื่อง
- ต่อเนื่องกัน
- สัญญา
- การควบคุม
- สะดวกสบาย
- การแปลง
- แปลง
- การทำสำเนา
- แก้ไข
- ราคา
- ประหยัดค่าใช้จ่าย
- ได้
- ซีพียู
- สร้าง
- ที่สร้างขึ้น
- การสร้าง
- การสร้าง
- ปัจจุบัน
- ขณะนี้
- ลูกค้า
- ปรับแต่ง
- ข้อมูล
- วันที่
- ลึก
- การเรียนรู้ลึก ๆ
- ลึก
- ค่าเริ่มต้น
- ค่าเริ่มต้น
- ความล่าช้า
- ปรับใช้
- นำไปใช้
- ปรับใช้
- การใช้งาน
- ออกแบบ
- ได้รับการออกแบบ
- รายละเอียด
- แน่นอน
- นักพัฒนา
- เครื่อง
- ความแตกต่าง
- ต่าง
- Dimension
- กระจาย
- คอมพิวเตอร์แบบกระจาย
- do
- นักเทียบท่า
- โดเมน
- Dont
- นกพิราบ
- ดาวน์โหลด
- ข้อเสีย
- ในระหว่าง
- พลวัต
- แบบไดนามิก
- แต่ละ
- ง่ายดาย
- อย่างง่ายดาย
- EBS
- ระบบนิเวศ
- อย่างมีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ทั้ง
- ทำให้สามารถ
- ช่วยให้
- ปลาย
- ปลายทาง
- ปลายทาง
- เครื่องยนต์
- วิศวกร
- การสร้างความมั่นใจ
- Enterprise
- ผู้ประกอบการ
- ทั้งหมด
- สิ่งแวดล้อม
- เท่ากัน
- อีเธอร์ (ETH)
- แม้
- ตัวอย่าง
- ตัวอย่าง
- การแลกเปลี่ยน
- การปฏิบัติ
- การออกกำลังกาย
- ที่คาดหวัง
- คาดว่า
- ประสบการณ์
- ความชำนาญ
- ใช้ประโยชน์
- ขยายออก
- ขยาย
- กว้างขวาง
- ใบหน้า
- อำนวยความสะดวก
- อำนวยความสะดวก
- ปัจจัย
- เร็วขึ้น
- ลักษณะ
- คุณสมบัติ
- ข้อเสนอแนะ
- สนาม
- รูป
- เนื้อไม่มีมัน
- ไฟล์
- หา
- ชื่อจริง
- ไหล
- มุ่งเน้นไปที่
- ตาม
- ดังต่อไปนี้
- ดังต่อไปนี้
- สำหรับ
- รูป
- ข้างหน้า
- พบ
- ที่สี่
- เศษ
- กรอบ
- กรอบ
- ฟรี
- ราคาเริ่มต้นที่
- นอกจากนี้
- อนาคต
- ที่ได้รับ
- สร้าง
- กำเนิด
- แบบจำลองการกำเนิด
- ได้รับ
- ให้
- เหตุการณ์ที่
- GPU
- GPUs
- กราฟ
- กราฟ
- มากขึ้น
- ขึ้น
- เกิดขึ้น
- ที่เกิดขึ้น
- ฮาร์ดแวร์
- มี
- he
- สุขภาพ
- ช่วย
- จะช่วยให้
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- จุดสูง
- ประสิทธิภาพสูง
- พระองค์
- ของเขา
- ตี
- กระโปรงหน้ารถ
- เจ้าภาพ
- โฮสติ้ง
- ร้อน
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- ที่ http
- HTTPS
- AMI
- ในอุดมคติ
- เอกลักษณ์
- Idle
- if
- ภาพ
- การดำเนินการ
- นำเข้า
- ความสำคัญ
- ปรับปรุง
- ช่วยเพิ่ม
- in
- ประกอบด้วย
- รวม
- รวมทั้ง
- เพิ่ม
- เพิ่มขึ้น
- เพิ่มขึ้น
- บ่งชี้ว่า
- ข้อมูล
- อย่างโดยเนื้อแท้
- ฉีด
- อินพุต
- ปัจจัยการผลิต
- ตัวอย่าง
- ทันที
- Intelligence
- อยากเรียนรู้
- ภายใน
- ภายใน
- เข้าไป
- เชิญ
- เรียก
- จะเรียก
- IT
- ITS
- jpg
- JSON
- การเก็บรักษา
- คีย์
- กุญแจ
- ชนิด
- ทราบ
- ที่รู้จักกัน
- ภาษา
- ใหญ่
- องค์กรขนาดใหญ่
- ที่มีขนาดใหญ่
- ความแอบแฝง
- ล่าสุด
- ชั้น
- แบบ
- นำ
- การเรียนรู้
- ทิ้ง
- ซ้าย
- ชั้น
- ระดับ
- ห้องสมุด
- ตั้งอยู่
- น้ำหนักเบา
- กดไลก์
- น่าจะ
- LIMIT
- เส้น
- รายการ
- ในประเทศ
- เข้าสู่ระบบ
- การเข้าสู่ระบบ
- เครื่อง
- เรียนรู้เครื่อง
- เก็บรักษา
- ทำให้
- การทำ
- หลาย
- แม็กซ์
- สูงสุด
- อาจ..
- กลไก
- พบ
- หน่วยความจำ
- กล่าวถึง
- ข่าวสาร
- ข้อความ
- ครึ่ง
- วิธี
- ตัวชี้วัด
- อาจ
- ต่ำสุด
- ลด
- ML
- ม.ป.ป
- โหมด
- แบบ
- โมเดล
- ข้อมูลเพิ่มเติม
- ภูเขา
- มาก
- ปลายทางหลายรุ่น
- หลาย
- ชื่อ
- พื้นเมือง
- โดยธรรมชาติ
- ภาษาธรรมชาติ
- ประมวลผลภาษาธรรมชาติ
- จำเป็นต้อง
- จำเป็น
- ความต้องการ
- เครือข่าย
- เครือข่าย
- ประสาท
- เครือข่ายประสาท
- ใหม่
- ถัดไป
- NLP
- ไม่
- หมายเหตุ
- สมุดบันทึก
- ไม่มีอะไร
- ตอนนี้
- ตัวเลข
- มึน
- Nvidia
- วัตถุ
- วัตถุ
- เกิดขึ้น
- of
- on
- ครั้งเดียว
- ONE
- โอเพนซอร์ส
- การดำเนินการ
- ผู้ประกอบการ
- โอกาส
- การเพิ่มประสิทธิภาพ
- เพิ่มประสิทธิภาพ
- การปรับให้เหมาะสม
- การเพิ่มประสิทธิภาพ
- ตัวเลือกเสริม (Option)
- Options
- or
- องค์กร
- อื่นๆ
- ของเรา
- ออก
- เอาท์พุต
- ด้านนอก
- แพ็คเกจ
- Parallel
- พารามิเตอร์
- พารามิเตอร์
- ส่วนหนึ่ง
- ในสิ่งที่สนใจ
- ส่ง
- แบบแผน
- รูปแบบไฟล์ PDF
- การปฏิบัติ
- ดำเนินการ
- สิทธิ์
- เลือก
- ชิ้น
- เวที
- แพลตฟอร์ม
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- เป็นไปได้
- โพสต์
- อำนาจ
- ที่ต้องการ
- ก่อน
- หลัก
- ก่อน
- ปัญหาที่เกิดขึ้น
- การประมวลผล
- การประมวลผล
- คุณสมบัติ
- โปรโตคอล
- ให้
- ผู้จัดหา
- ผู้ให้บริการ
- ให้
- ไฟฉาย
- คำถาม
- คำถาม
- ตั้งแต่
- ถึง
- เรียลไทม์
- เหตุผล
- เหตุผล
- แนะนำ
- แนะนำ
- ระเบียน
- ลด
- ลด
- ลด
- หมายถึง
- ความนับถือ
- ภูมิภาค
- ที่เกี่ยวข้อง
- กรุ
- การแสดง
- เป็นตัวแทนของ
- ขอ
- การร้องขอ
- จำเป็นต้องใช้
- คำตอบ
- ผล
- ผลสอบ
- การอบรมขึ้นใหม่
- บทบาท
- วิ่ง
- วิ่ง
- อย่างปลอดภัย
- sagemaker
- เดียวกัน
- ลด
- เงินออม
- เห็น
- สถานการณ์
- วินาที
- Section
- เห็น
- ที่กำลังมองหา
- การเลือก
- ส่ง
- การส่ง
- ระดับอาวุโส
- แยก
- ลำดับ
- ให้บริการ
- บริการ
- การให้บริการ
- ชุด
- การตั้งค่า
- การตั้งค่า
- หลาย
- รูปร่าง
- รูปร่าง
- Share
- ที่ใช้ร่วมกัน
- น่า
- โชว์
- แสดง
- แสดงให้เห็นว่า
- แสดง
- แสดงให้เห็นว่า
- สำคัญ
- อย่างมีความหมาย
- คล้ายคลึงกัน
- ง่าย
- ตั้งแต่
- เดียว
- ขนาด
- ขนาด
- So
- โซลูชัน
- บาง
- ผู้เชี่ยวชาญ
- ที่ระบุไว้
- การใช้จ่าย
- ระยะ
- มาตรฐาน
- เริ่มต้น
- ข้อความที่เริ่ม
- การเริ่มต้น
- startups
- สถานะ
- เข้าพัก
- คงที่
- ขั้นตอน
- ขั้นตอน
- ยังคง
- การเก็บรักษา
- ยุทธศาสตร์
- กลยุทธ์
- กระแส
- ลำธาร
- โครงสร้าง
- อย่างเช่น
- เพียงพอ
- ชี้ให้เห็นถึง
- สูท
- สนับสนุน
- ที่สนับสนุน
- ที่สนับสนุน
- รองรับ
- เอา
- เป้า
- งาน
- เทคโนโลยี
- เทนนิส
- tensorflow
- เงื่อนไขการใช้บริการ
- การทดสอบ
- กว่า
- ที่
- พื้นที่
- ก้าวสู่อนาคต
- กราฟ
- ของพวกเขา
- พวกเขา
- แล้วก็
- ที่นั่น
- ดังนั้น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- เหล่านั้น
- แต่?
- สาม
- ตลอด
- ปริมาณงาน
- เวลา
- ไปยัง
- เครื่องมือ
- เครื่องมือ
- คบเพลิง
- รถไฟ
- การแปลง
- หม้อแปลง
- ต้นไม้
- แนวโน้ม
- ไทรทัน
- ลอง
- การหมุน
- สอง
- ชนิด
- ชนิด
- เป็นปกติ
- ภายใต้
- ความเข้าใจ
- us
- การใช้
- ใช้
- ใช้กรณี
- มือสอง
- ผู้ใช้งาน
- ใช้
- การใช้
- มักจะ
- การใช้ประโยชน์
- ความคุ้มค่า
- ความคุ้มค่า
- ตัวแปร
- ต่างๆ
- วิสัยทัศน์
- เห็นภาพ
- ปริมาณ
- ต้องการ
- เสีย
- ทาง..
- we
- เว็บ
- บริการเว็บ
- น้ำหนัก
- ดี
- อะไร
- เมื่อ
- แต่ทว่า
- ว่า
- ที่
- อย่างกว้างขวาง
- จะ
- กับ
- ภายใน
- ไม่มี
- งาน
- ทำงาน
- การทำงาน
- โรงงาน
- ของโลก
- เธอ
- ของคุณ
- ลมทะเล
- สวนสัตว์