Amazon Atina MERGE komutunu destekler Apaçi Buzdağı ACID (Atomik, Tutarlı, Yalıtılmış, Dayanıklı) ile uyumlu tanıdık SQL deyimlerini kullanarak veri gölünüzde uygun ölçekte eklemeler, güncellemeler ve silmeler gerçekleştirmenize olanak tanıyan tablolar. Apache Iceberg, büyük dosya koleksiyonlarını tablolar olarak yöneten veri gölleri için açık bir tablo biçimidir. Seçtikçe tablo oluşturma (CTAS), yukarı yerleştirme ve birleştirme ve zamanda yolculuk sorguları gibi modern analitik veri gölü işlemlerini destekler. Athena ayrıca, depolama ve performansı optimize etmek için Apache Iceberg tablolarında görünüm oluşturma ve VACUUM (anlık görüntü sona erme) gerçekleştirme yeteneğini de destekler. Bu özelliklerle artık tamamen standart SQL'de sunucusuz, oluşturması daha basit ve ölçekte çalışabilen veri ardışık düzenleri oluşturabilirsiniz. Bu, geliştiricilerin şunları yapmasını sağlar:
- İş mantığı yazmaya odaklanın ve temel altyapıyı kurma ve yönetme konusunda endişelenmeyin
- Athena ile veri dönüşümleri gerçekleştirin
- Belirli veri silme gereksinimlerine uymaya yardımcı olun
- Kaynak veritabanlarından değişiklik verisi yakalama (CDC) uygulayın
Veri gölleriyle, veri ardışık düzenleri tipik olarak verileri bir ham bölgebir Amazon Basit Depolama Hizmeti Kaynak sistemlerden olduğu gibi verileri içeren (Amazon S3) klasörü veya klasörü. Veriler bu bölgede toplanır, böylece kaynak veritabanındaki eklemeler, güncellemeler veya silmeler, kaynakta işlemler gerçekleştikçe yeni dosyalarda kayıtlar olarak görünür. Ham bölge sorgulanabilse de, herhangi bir aşağı akış işleme veya analitik sorgunun, kaynak tablonun geçerli bir görünümünü türetmek için tipik olarak verileri tekilleştirmesi gerekir. Örneğin, kaynak veritabanında tek bir kayıt birden çok kez güncelleniyorsa, bunların tekilleştirilmesi ve en son kaydın seçilmesi gerekir.
Tipik olarak, bu işlemi gerçekleştirmek için veri dönüştürme süreçleri kullanılır ve nihai bir tutarlı görünüm, bir S3 klasöründe veya klasöründe depolanır. Veri dönüştürme süreçleri, daha fazla kodlama, daha fazla test gerektiren karmaşık olabilir ve ayrıca hataya açıktır. Veri gölleri dosyalara dayalı olduğundan ve veri eklemek için optimize edildiğinden bu zorlu bir işti. Daha önce, tüm S3 nesnesinin veya klasörünün üzerine yazmanız gerekiyordu; bu, yalnızca verimsiz olmakla kalmıyor, aynı zamanda aynı verileri sorgulayan kullanıcıları da kesintiye uğratıyordu. Apache Iceberg gibi çerçevelerin gelişmesiyle birlikte, kullanıcı sorgularını engellemeden ve sorgu performansını korumaya devam ederken Athena'yı kullanarak Amazon S3'te yerinde SQL tabanlı upsert gerçekleştirebilirsiniz.
Bu yazıda, bir S3 veri gölündeki hedef tablolara ilişkisel bir veritabanından CDC uygulamak için Athena'yı nasıl kullanabileceğinizi gösteriyoruz.
Çözüme genel bakış
Bu gönderi için, aşağıdakileri temel alan sahte bir spor bileti uygulaması düşünün proje. Bu veritabanında spor etkinlikleri bilgilerini içeren tek bir tablo kullanıyoruz ve bunu sürekli olarak (ilk yükleme ve devam eden değişiklikler) bir S3 veri gölüne alıyoruz. Bu veri alma ardışık düzeni kullanılarak uygulanabilir AWS Veritabanı Geçiş Hizmeti (AWS DMS), hem tam hem de devam eden CDC özetlerini çıkarmak için. CDC ile değişen verileri belirleyip izleyebilir ve bunu bir aşağı akış uygulamasının tüketebileceği bir değişiklik akışı olarak sağlayabilirsiniz. Çoğu veritabanı, veritabanında yapılan değişiklikleri kaydetmek için bir işlem günlüğü kullanır. AWS DMS, motora özel API işlemlerini kullanarak işlem günlüğünü okur ve müdahaleci olmayacak şekilde veritabanında yapılan değişiklikleri yakalar.
Özellikle eklemeler, güncellemeler ve silmeler dahil değiştirilmiş verileri veritabanından çıkarmak için AWS DMS'yi aşağıda açıklandığı gibi iki çoğaltma göreviyle yapılandırabilirsiniz. atölye. İlk görev, tam verilerin ilk kopyasını bir S3 klasörüne gerçekleştirir. İkinci görev, devam eden CDC'yi, kaynak veritabanlarının işlem gerçekleştirme tarihine göre tarih tabanlı alt klasörler halinde daha da düzenlenen S3'teki ayrı bir klasöre çoğaltmak üzere yapılandırıldı. Ayrı S3 klasörlerindeki tam ve CDC verileriyle, veri çoğaltma ve aşağı akış işleme işlerini sürdürmek ve çalıştırmak daha kolaydır. Bunu etkinleştirmek için aşağıdaki ekstra bağlantı özniteliklerini AWS DMS'deki S3 uç noktasına uygulayabilirsiniz (bkz. S3Ayarları diğer CSV ve ilgili ayarlar için):
- Zaman DamgasıSütunAdı – AWS DMS, kaynak veritabanındaki o satırın işlenmesi için zaman damgası bilgileriyle adlandırdığınız bir sütun ekler.
- dahilOpForFullLoad – AWS DMS, kaydın I (INSERT), U (UPDATE) veya D (DELETE) olduğunu belirtmek için her dosyaya Op adlı bir sütun ekler.
- DatePartitionEnabled, DatePartitionSequence, DatePartitionDelimiter – Bu ayarlar, değiştirilen verileri veri gölündeki tarih/saat tabanlı klasörlere yazmak üzere AWS DMS'yi yapılandırmak için kullanılır. Klasörleri bölümlere ayırarak, S3 nesnelerini daha iyi yönetebilir ve sonraki aşağı akış işlemleri için data lake sorgularını optimize edebilirsiniz.
Satır düzeyinde güncellemeleri ifade edebilen MERGE INTO adlı Apache Iceberg tabloları için Athena'daki desteği kullanıyoruz. Apache Iceberg, güncellenmesi gereken satırları içeren veri dosyalarını yeniden yazarak MERGE INTO'yu destekler. Veriler birleştirildikten sonra, zaman yolculuğu yapmak için Athena'yı nasıl kullanacağımızı gösteriyoruz. sporting_event tablo ve son kullanıcılara verilerin farklı sürümlerini soyutlamak ve sunmak için görünümleri kullanın. Son olarak, tablo bakımını basitleştirmek için, hem okuma hem de yazma işlemlerinin gecikmesini ve maliyetini optimize edecek eski anlık görüntüleri silmek için Apache Iceberg tablolarında VACUUM gerçekleştirmeyi gösteriyoruz.
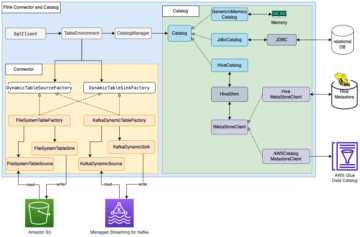
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.

Çözüm iş akışı aşağıdaki adımlardan oluşur:
- Veri alımı:
- Adım 1 ve 2, başlangıç verilerini ve devam eden değişiklikleri (CDC) Amazon S3'e CSV biçiminde yüklemek için kaynak veritabanına bağlanan AWS DMS'yi kullanır. Bu gönderi için, AWS DMS kullanılarak oluşturulmuş örnek tam ve CDC veri kümelerini CSV formatında sağladık.
- Adım 3, aşağıdaki eylemlerden oluşur:
- Athena'da Amazon S3'te alınan kaynak verilere işaret eden harici bir tablo oluşturun.
- Bir Apache Iceberg hedef tablosu oluşturun ve kaynak tablodan veri yükleyin.
- MERGE INTO'yu kullanarak CDC verilerini Apache Iceberg tablosunda birleştirin.
- Veri erişimi:
- 4. Adımda, Apache Iceberg tablosunda bir görünüm oluşturun.
- Standart SQL kullanarak verileri sorgulamak için görünümü kullanın.
Önkoşullar
Başlamadan önce, AWS hesabınızda aşağıdakileri gerçekleştirmek için gerekli izinlere sahip olduğunuzdan emin olun:
Ham veriler üzerinde tablolar oluşturun
İlk olarak, bu demo için bir veritabanı oluşturun.
- Athena konsoluna gidin ve seçin sorgu düzenleyici.
Athena sorgu düzenleyicisini ilk kez kullanıyorsanız, yapılandırmak ve sorgu sonuçlarını depolamak için bir S3 grubu belirtin. - Aşağıdaki kodla bir veritabanı oluşturun:
- Ardından, bu demo için kullanabileceğiniz bir S3 klasöründe bir klasör oluşturun. Bu klasörü adlandırın
sporting_event_full. - Foto Yükle YÜK00000001.csv klasöre.
- Şuna geçin
raw_demoveritabanını açın ve ham girdi verilerine işaret edecek bir tablo oluşturun: - Verileri incelemek için aşağıdaki sorguyu çalıştırın:
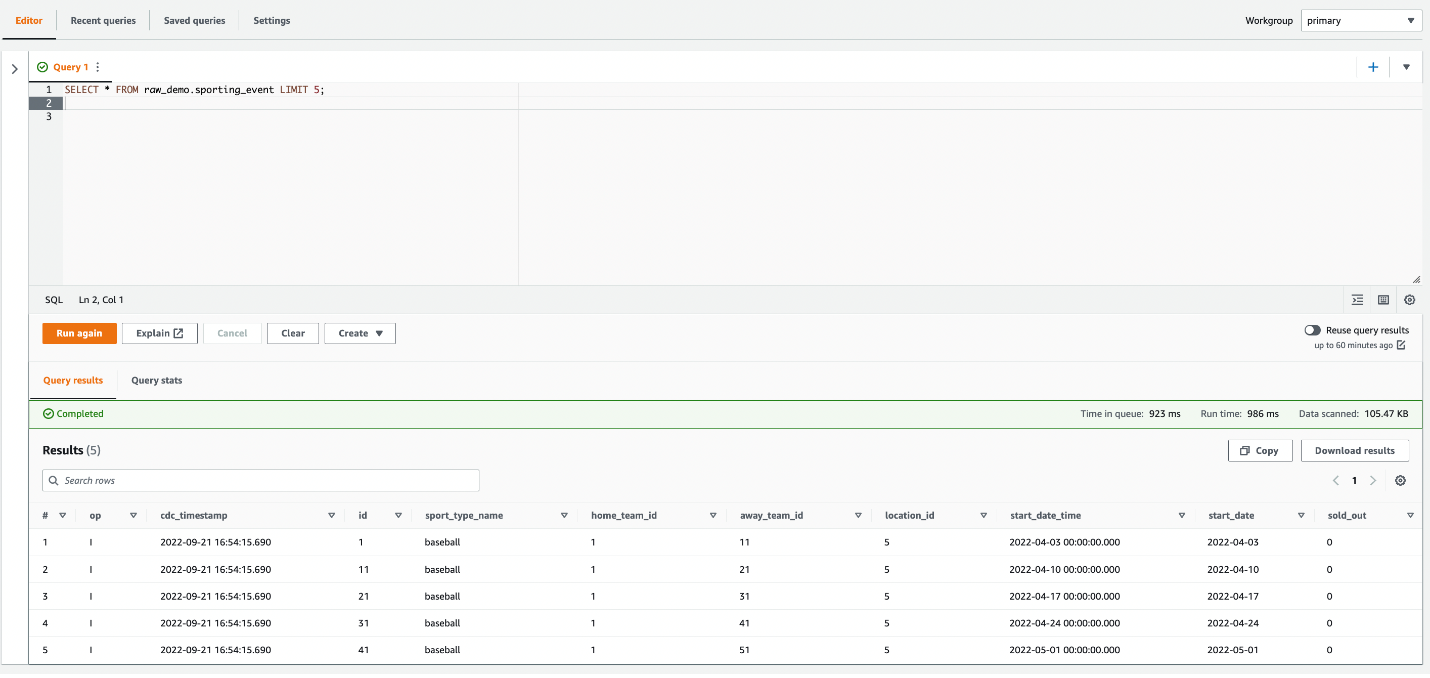
- Ardından, aynı S3 grubunda başka bir klasör oluşturun.
sporting_event_cdc. - Bu klasör içinde, son S3 klasör URI'si şöyle görünecek şekilde bir zaman hiyerarşisi klasör yapısında üç alt klasör oluşturun
s3://<your-bucket>/sporting_event_cdc/2022/09/22/. - Foto Yükle 20220922-184314489.csv Bu klasör yapısı, tarihe dayalı klasör bölümlemeyi etkinleştirdiğinizde AWS DMS'nin CDC verilerini depolama biçimine benzer.
- CDC verilerine işaret edecek bir tablo oluşturun. Amazon S3'teki kaynak veriler tarih tabanlı klasörler halinde düzenlendiğinden, bu tablo bir bölüm sütunu da içerir.
- Ardından, yeni bölümler eklemek için tabloyu değiştirin. Veriler, AWS DMS tarafından Hive olmayan bir biçimde depolandığından, bu verileri sorgulamak için bu bölümü manuel olarak ekleyin veya bir AWS Tutkal paletli Veriler biriktikçe, bu verileri sorgulamak için yeni bölümler eklemeye devam edin.
- CDC verilerini incelemek için aşağıdaki sorguyu çalıştırın:
ID 1 ve 11 olan ve U op kodu ile güncellenen iki kayıt vardır. ID 21 olan kayıt silme (D) op koduna sahiptir ve ID 5 olan kayıt bir insert (I)'dir.

Parke biçiminde hedef Buzdağı tablosunu oluşturmak için CTAS'ı kullanın
CTAS ifadeleri, standart SELECT sorgularını kullanarak yeni tablolar oluşturur. Ortaya çıkan tablo AWS Glue Data Catalog'a eklenir ve sorgulama için kullanılabilir hale getirilir.
- İlk olarak, hedef tabloyu depolamak için başka bir veritabanı oluşturun:
- Ardından, bu veritabanına geçin ve hedef Buzdağı tablosunu oluşturmak için ham girdi tablosundan veri seçmek üzere CTAS deyimini çalıştırın (konumu hesabınızdaki uygun bir S3 grubuyla değiştirin):
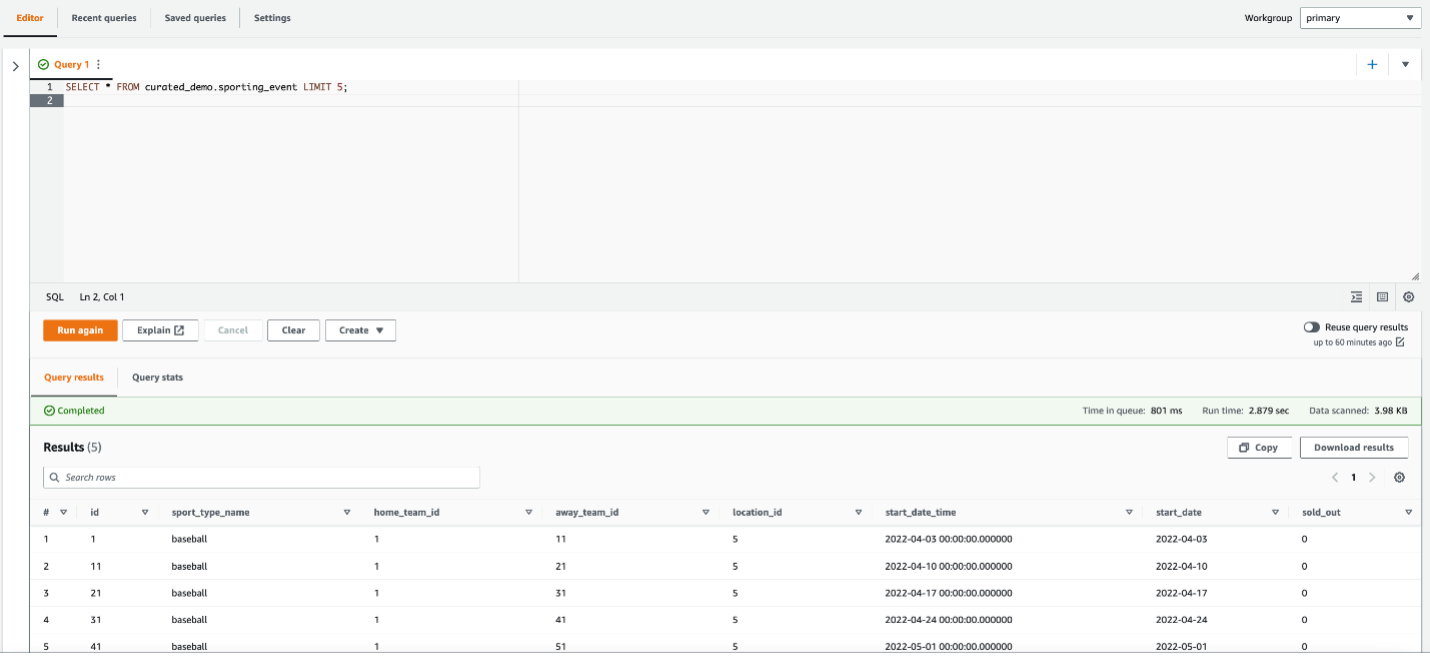
- Buzdağı tablosundaki verileri incelemek için aşağıdaki sorguyu çalıştırın:
Iceberg tablosuna veri eklemek, güncellemek ve silmek için MERGE INTO'yu kullanın
MERGE INTO komutu, hedef tabloyu CDC tablosundaki verilerle günceller. Aşağıdaki ifade, kaynak satırın bir ekleme mi, güncelleme mi yoksa silme mi olduğunu gösteren kaynak verilerde birincil anahtarlar ile Op sütununun bir kombinasyonunu kullanır. Hedef tabloyu kaynak tabloyla birleştirmek için birincil anahtar olarak id sütununu ve bir kaydın silinmesi gerekip gerekmediğini belirlemek için Op sütununu kullanırız.
Buzdağı tablosundaki verileri doğrulamak için aşağıdaki sorguyu çalıştırın:
21 numaralı kayıt silindi ve CDC veri setindeki diğer kayıtlar beklendiği gibi güncellendi ve eklendi.

Önceki durumu içeren bir görünüm oluşturun
Bir Iceberg tablosuna yazdığınızda, her seferinde tablonun yeni bir anlık görüntüsü veya versiyonu oluşturulur.
Anlık görüntü, bir tablonun belirli bir andaki durumunu temsil eder ve tablodaki tüm veri dosyalarına erişmek için kullanılır. Zaman yolculuğu Athena'daki sorgular, Amazon S3'ü belirli bir tarih ve saate veya belirli bir anlık görüntü kimliğine göre tutarlı bir anlık görüntüden geçmiş veriler için sorgular. Ancak bu, bir tablonun geçerli anlık görüntüleri hakkında bilgi gerektirir. Bu bilgileri kullanıcılardan soyutlamak için Iceberg tablolarının üzerinde görünümler oluşturabilirsiniz:
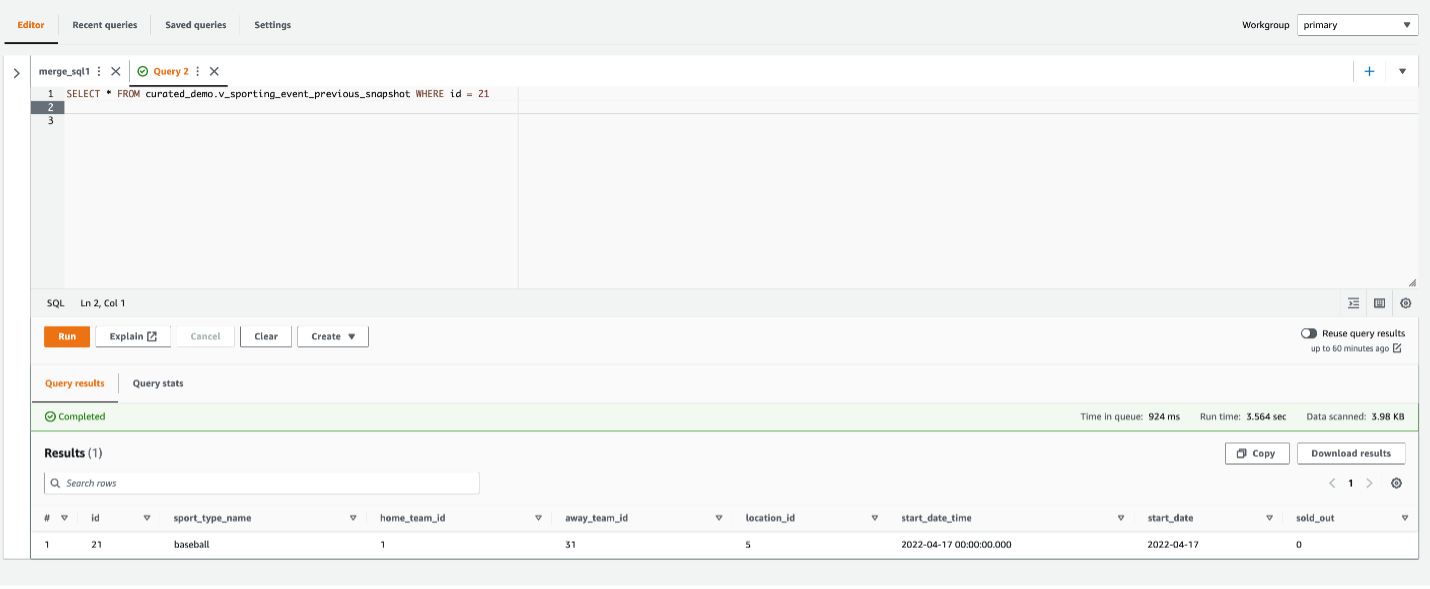
CDC uygulanmadan önce verilerin anlık görüntüsünü almak için bu görünümü kullanarak aşağıdaki sorguyu çalıştırın:
Daha önce silinen ID 21 ile kaydı görebilirsiniz.
Gizlilik düzenlemelerine uyum, tüm anlık görüntülerdeki kayıtları kalıcı olarak silmenizi gerektirebilir. Bunu başarmak için tabloyu oluştururken Athena'da anlık görüntü tutma özelliklerini ayarlayabilir veya tabloyu değiştirebilirsiniz:
Bu, Athena'ya verilerin yalnızca bir sürümünü saklaması ve herhangi bir işlem geçmişi tutmaması talimatını verir. Bir tablo bu özelliklerle güncellendikten sonra, eski anlık görüntüleri kaldırmak ve depolamayı temizlemek için VACUUM komutunu çalıştırın:
Aşağıdaki sorguyu yeniden çalıştırın:
Kimlik 21'e sahip kayıt kalıcı olarak silindi.

Hususlar
Ham bölgenizin CDC klasöründe veriler biriktikçe, eski dosyalar şuraya arşivlenebilir: Amazon S3 Buzulu. Daha sonra, MERGE INTO deyimi, gerekirse tek bir kaynak dosya üzerinde de çalıştırılabilir. $yol USING yan tümcesinin WHERE koşulunda:
Bu, Athena'nın filtre uygulanmadan önce bölümün klasöründeki tüm dosyaları taramasıyla sonuçlanır, ancak ayrıntılı saatlik bölümler seçilerek en aza indirilebilir. Bu yaklaşımla, MERGE INTO'yu Athena'da çalışacak şekilde tetikleyebilirsiniz, çünkü dosyalar S3 kovanıza ulaşır. Amazon S3 olay bildirimleri. Bu, kullanıcıların kaynak sistemlerde oluşturulur oluşturulmaz veri gölündeki verilerin tutarlı bir görünümünü sorgulaması gereken neredeyse gerçek zamanlı kullanım durumlarını etkinleştirebilir.
Temizlemek
Devam eden maliyetlerden kaçınmak için kaynaklarınızı temizlemek için aşağıdaki adımları tamamlayın:
- Tabloları ve görünümleri bırakmak için aşağıdaki SQL'i çalıştırın:
Iceberg tabloları Athena'da yönetilen tablolar olarak kabul edildiğinden, bir Iceberg tablosunun bırakılması ilgili S3 klasöründeki tüm verileri de kaldırır.
- Veritabanlarını bırakmak için aşağıdaki SQL'i çalıştırın:
- Yüklediğiniz S3 klasörlerini ve CSV dosyalarını silin.
Sonuç
Bu gönderi, Athena'da CTAS ve MERGE INTO deyimlerini kullanarak CDC'yi hedef bir Buzdağı tablosuna nasıl uygulayacağınızı gösterdi. Bir CTAS deyimi kullanarak toplu yükleme gerçekleştirebilirsiniz. Yeni veri veya değiştirilmiş veri geldiğinde, CDC değişikliklerini birleştirmek için MERGE INTO deyimini kullanın. Depolamayı optimize etmek ve sorgu performansını artırmak için VACUUM komutunu düzenli olarak kullanın.
Sonraki adımlarda, bu SQL ifadelerini kullanarak düzenleyebilirsiniz. AWS Basamak İşlevleri veri gölünüz için uçtan uca veri ardışık düzenlerini uygulamak için. Daha fazla bilgi için bkz. Amazon Athena ve AWS Step Functions kullanarak ETL ardışık düzenleri oluşturun ve düzenleyin.
Yazarlar Hakkında
 Ranjit Rajan AWS'de Baş Veri Laboratuvarı Çözümleri Mimarıdır. Ranjit, bulutta veri ve analitik uygulamaları tasarlamalarına ve oluşturmalarına yardımcı olmak için AWS müşterileriyle birlikte çalışır.
Ranjit Rajan AWS'de Baş Veri Laboratuvarı Çözümleri Mimarıdır. Ranjit, bulutta veri ve analitik uygulamaları tasarlamalarına ve oluşturmalarına yardımcı olmak için AWS müşterileriyle birlikte çalışır.
 Kannan Iyer AWS'de Kıdemli Veri Laboratuvarı Çözümleri Mimarıdır. Kannan, bulutta veri ve analitik uygulamaları tasarlamalarına ve oluşturmalarına yardımcı olmak için AWS müşterileriyle birlikte çalışır.
Kannan Iyer AWS'de Kıdemli Veri Laboratuvarı Çözümleri Mimarıdır. Kannan, bulutta veri ve analitik uygulamaları tasarlamalarına ve oluşturmalarına yardımcı olmak için AWS müşterileriyle birlikte çalışır.
 Alexandre Rezende AWS'de Veri Laboratuvarı Çözümleri Mimarıdır. Alexandre, müşterilerle İş Zekası, Veri Ambarı ve Veri Gölü kullanım durumları üzerinde çalışır, iş sorunlarını çözmek için mimariler tasarlar ve üretime giden yolları hızlandırmak için MVP'ler oluşturmalarına yardımcı olur.
Alexandre Rezende AWS'de Veri Laboratuvarı Çözümleri Mimarıdır. Alexandre, müşterilerle İş Zekası, Veri Ambarı ve Veri Gölü kullanım durumları üzerinde çalışır, iş sorunlarını çözmek için mimariler tasarlar ve üretime giden yolları hızlandırmak için MVP'ler oluşturmalarına yardımcı olur.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Adryenn Ashley ile Geleceği Basmak. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/perform-upserts-in-a-data-lake-using-amazon-athena-and-apache-iceberg/
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- $UP
- 1
- 10
- 100
- 11
- 20
- 7
- 8
- 9
- a
- kabiliyet
- Yapabilmek
- Hakkımızda
- ÖZET
- hızlandırmak
- erişim
- başarmak
- Hesap
- birikmiş
- eylemler
- eklemek
- katma
- Ekler
- Sonra
- Türkiye
- veriyor
- Ayrıca
- Rağmen
- Amazon
- Amazon Atina
- an
- Analitik
- analytics
- ve
- Başka
- herhangi
- Apache
- api
- görünmek
- Uygulama
- uygulamaları
- uygulamalı
- Tamam
- yaklaşım
- uygun
- mimari
- ARE
- Geldiğinde
- AS
- At
- öznitelikleri
- mevcut
- önlemek
- AWS
- AWS Tutkal
- merkezli
- temel
- BE
- Çünkü
- olmuştur
- önce
- Daha iyi
- bloke etme
- her ikisi de
- inşa etmek
- iş
- iş zekası
- fakat
- by
- denilen
- CAN
- ele geçirmek
- yakalar
- durumlarda
- katalog
- CDC)
- belli
- meydan okuma
- değişiklik
- değişmiş
- değişiklikler
- Klinik
- seçme
- bulut
- kod
- kodlama
- koleksiyon
- Sütun
- kombinasyon
- işlemek
- tamamlamak
- tamamen
- karmaşık
- uyumlu
- oluşur
- koşul
- bağ
- bağlanır
- Düşünmek
- kabul
- tutarlı
- konsolos
- tüketmek
- içeren
- devam etmek
- sürekli
- uyan
- Ücret
- maliyetler
- olabilir
- paletli
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- Oluşturma
- akım
- Müşteriler
- veri
- Veri Gölü
- veri ambarı
- veritabanı
- veritabanları
- veri kümeleri
- Tarih
- Gösteri
- göstermek
- tarif edilen
- Dizayn
- Belirlemek
- geliştiriciler
- farklı
- Damla
- Damlama
- her
- Daha erken
- kolay
- editör
- etkinleştirmek
- sağlar
- son uca
- Son nokta
- hata
- Eter (ETH)
- Etkinlikler
- olaylar
- Her
- evrim
- örnek
- beklenen
- sona erme
- ekspres
- dış
- ekstra
- çıkarmak
- Hulasa
- tanıdık
- Özellikler
- Alanlar
- fileto
- dosyalar
- filtre
- son
- Nihayet
- Ad
- ilk kez
- takip etme
- İçin
- biçim
- çerçeveler
- itibaren
- tam
- daha fazla
- oluşturulan
- alma
- vardı
- Hadoop'un
- Var
- yardım et
- yardımcı olur
- hiyerarşi
- tarihsel
- tarih
- kovan
- Ne kadar
- Nasıl Yapılır
- Ancak
- HTML
- http
- HTTPS
- i
- ID
- kimlikleri
- if
- göstermektedir
- uygulamak
- uygulanan
- iyileştirmek
- in
- içerir
- Dahil olmak üzere
- belirtmek
- gösterir
- verimsiz
- bilgi
- ilk
- giriş
- Uçlar
- İstihbarat
- kesilmiş
- içine
- yalıtılmış
- IT
- Mesleki Öğretiler
- kaydol
- jpg
- anahtar
- anahtarlar
- bilgi
- laboratuvar
- göl
- büyük
- Gecikme
- sevmek
- LİMİT
- yük
- yer
- log
- GÖRÜNÜYOR
- yapılmış
- korumak
- bakım
- yapmak
- yönetmek
- yönetilen
- yönetir
- yönetme
- tavır
- el ile
- eşleşti
- Mayıs..
- gitmek
- göç
- dakika
- Modern
- Daha
- çoğu
- çoklu
- isim
- adlı
- gerek
- gerekli
- ihtiyaçlar
- yeni
- sonraki
- şimdi
- nesne
- nesneler
- of
- on
- ONE
- devam
- bir tek
- OP
- açık
- işletmek
- operasyon
- Operasyon
- optimize
- optimize
- or
- Düzenlenmiş
- Diğer
- yol
- yapmak
- performans
- icra
- gerçekleştirir
- kalıcı olarak
- izinleri
- boru hattı
- Platon
- Plato Veri Zekası
- PlatoVeri
- Nokta
- Çivi
- mevcut
- önceki
- Önceden
- birincil
- Anapara
- gizlilik
- sorunlar
- Süreçler
- işleme
- üretim
- özellikleri
- sağlamak
- sağlanan
- sorgular
- Çiğ
- Okumak
- son
- kayıt
- kayıtlar
- düzenli
- yönetmelik
- ilgili
- Kaldır
- değiştirmek
- kopya
- temsil
- gerektirir
- gereklidir
- gerektirir
- Kaynaklar
- Sonuçlar
- tutma
- yorum
- yeniden
- SIRA
- koşmak
- s
- aynı
- ölçek
- tarama
- İkinci
- görmek
- seçilmiş
- kıdemli
- ayrı
- Serverless
- set
- ayar
- ayarlar
- benzer
- Basit
- basitleştirmek
- tek
- Enstantane fotoğraf
- çözüm
- Çözümler
- ÇÖZMEK
- Yakında
- Kaynak
- kaynaklar
- Belirtilen
- Spor
- SQL
- standart
- başladı
- Eyalet
- Açıklama
- ifadeleri
- adım
- Basamaklar
- Yine
- hafızası
- mağaza
- saklı
- mağaza
- dere
- dizi
- yapı
- stil
- sonraki
- Daha sonra
- böyle
- destek
- Destekler
- elbette
- anahtar
- Sistemler
- tablo
- Hedef
- Görev
- görevleri
- Test yapmak
- o
- The
- Birleştirme
- Kaynak
- Devlet
- ve bazı Asya
- Onları
- sonra
- Bunlar
- Re-Tweet
- üç
- Biletleme
- zaman
- zaman yolculuğu
- zamanlar
- zaman damgası
- için
- üst
- iz
- işlem
- işlemler
- Dönüşüm
- dönüşümler
- seyahat
- tetikleyebilir
- iki
- tipik
- altında yatan
- Güncelleme
- güncellenmiş
- Güncellemeler
- Yüklenen
- URI
- kullanım
- Kullanılmış
- kullanıcı
- kullanıcılar
- kullanma
- Vakum
- onaylama
- Değerler
- doğrulamak
- versiyon
- Görüntüle
- Gösterim
- depo
- oldu
- we
- vardı
- ne zaman
- hangi
- süre
- DSÖ
- irade
- ile
- olmadan
- iş akışı
- çalışır
- Atölyeler
- yazmak
- yazı yazıyor
- sen
- zefirnet