Giriş
Çevrimiçi müşteri hizmetleri, pazarlama ve finans da dahil olmak üzere birçok uygulama için isimlere dayalı cinsiyet tanımlaması çok önemli bir zorluktur. Çok sayıda cinsiyet seçeneği ve dillerin değişkenliği göz önüne alındığında, tüm dillerde doğru olan bir ad cinsiyet kimliği sınıflandırma sistemi bulmak zor olabilir. Bu makale NLP ve Python bu sorunu çözebilir. Burada Hint isimlerine göre cinsiyet belirleme ile ilgileneceğiz.
Bu makalenin sonunda, şunları nasıl yapacağınızı öğrenmiş olacaksınız:
- Ham metni vektör temsillerine dönüştürmek için NLP görevleri için nltk kitaplığını kullanın.
- NLP Pipeline'ı kullanarak isme dayalı bir cinsiyet tanımlama modeli oluşturun.
- Çeşitli Makine Öğrenimi, NLP ve Derin Öğrenme algoritmalarını kullanın ve en iyi performansı göstereni belirleyin.

Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Sorun bildirimi
NLP boru hattı adımları ile çözeceğimiz iş problemi aşağıdaki gibidir:
“İsmi verildiğinde, kişinin cinsiyetini tanımlayın”
Ön koşul
Bu, başlangıç düzeyinde bir NLP projesidir ve aşağıdaki kavramların anlaşılmasını gerektirir:
- Python
- Pandalar veri işleme için kitaplık
- Veri görselleştirmeleri için Matplotlib veya Seaborn
- Makine öğreniminin temelleri ve derin öğrenme algoritmaları
Önerilen çözüm
Bu sorun için önerilen çözüm, derin öğrenme ile makine öğrenimini birleştiren isme dayalı bir cinsiyet belirleme sistemi oluşturmaktır. İkiden fazla cinsiyet olduğunu bilmemize rağmen, sadece 'Erkek' ve 'Kadın'ı dikkate alacağız. Dolayısıyla bu bir ikili sınıflandırma modeli haline gelir.
Veri Kümesinin Açıklaması
Bu proje için şu adreste bulunan Gender_Data veri setini kullanacağız: Kaggle.
Bu veri seti, 53925'ü erkek ve geri kalanı kadın olmak üzere toplam 29014 Hintli isim içermektedir. "Cinsiyet" özelliği, 0 ve 1 değerlerini içerir. 0, bir erkek çocuğun adına karşılık gelirken, 1, bir dişiyi temsil eder.
Algoritmaların Sezgisi
Bu bölümde, bu projeyi oluştururken kullanacağımız NLP kavramlarına ve diğer konulara bakacağız.
Etiket Kodlaması: Bu, kategorik etiketleri sayısal etiketlere dönüştürme sürecini ifade eder. Burada her kategorik etikete, alfabetik sırasına göre belirli bir değer verilir.
Sayım Vektörizasyonu: Sayım vektörleştirme, derlemdeki tüm kelimelerin derlemdeki sıklıklarına göre sayısal verilere dönüştürüldüğü süreçtir. Metinsel verileri seyrek bir matrise dönüştürür. Verilen bir örneği vektörleştirelim:
text = [ 'Bu bir örnek, 'Elmayı karınca yedi' ]
| Re-Tweet | is | an | örnek | karınca | yedik | the | elma | |
| 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 |
Lojistik regresyon
Lojistik regresyon, sınıflandırma problemlerini çözmek için en yaygın kullanılan makine öğrenimi algoritmalarından biridir. Belirli bir kategoriye ait belirli bir değerin olasılığını tahmin etmek için kullanılır. Sınıf 0 veya sınıf 1'e ait bir veri noktasının olasılığını söyler. Sigmoid işlevine dayalı olarak çalışır. Lojistik regresyon, lineer regresyon eğrisini sigmoid fonksiyonuna uydurarak "S" şeklinde bir eğri oluşturur. Burada, sınıfları ayırt etmek için bir eşik noktası (ideal olarak 0.5) kullanılır.

Naif bayanlar
Naïve Bayes, metinleri ve yüksek boyutlu eğitim verilerini sınıflandırmak için yaygın olarak kullanılan denetimli bir öğrenme algoritmasıdır. Çok hızlı kararlar alma yeteneğine sahiptir ve bu nedenle minimum eğitim ve test süresi alır. Bir değerin oluşumunun veri kümesindeki diğer değerlerden tamamen bağımsız olduğunu varsaydığı için 'Naif' olarak adlandırılır. Aşağıdaki gibi Bayes teoremine dayalı olarak çalışır:
P(A/B) = [P(A) * P(B/A)] / P(B)
burada P(A) sonraki olasılık, P(B) marjinal olasılık, P(A) önceki olasılık ve P(B/A) olasılıktır.
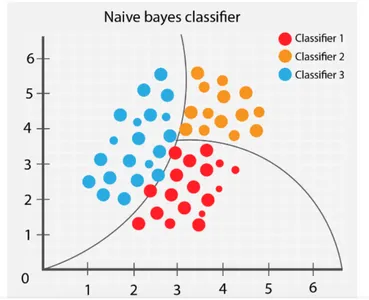
Naive Bayes hem ikili hem de çok sınıflı sınıflandırma problemleri için kullanılabilen hızlı ve kolay bir algoritmadır. Ancak, veri setinin özelliklerinin ilişkisiz olduğunu varsayar, bu da değişkenler arasındaki ilişkinin öğrenilmesini zorlaştırır.
XGBoost
XGBoost, günümüzde kullanılan en güçlü makine öğrenimi algoritmalarından biridir. EXtreme Gradient Boosted Trees'in kısaltmasıdır. Derin öğrenme ağlarına gömülü örüntü tanıma yeteneklerinden yararlanarak tahmine dayalı modellerin performansını iyileştirmek için tasarlanmıştır. XGBoost'un hızlı, verimli ve ölçeklenebilir olması, onu büyük modelleri hızlı bir şekilde eğitmesi gereken kişiler için popüler bir seçim haline getiriyor.
LSTM
Makine öğreniminde, Uzun Kısa Süreli Bellek (LSTM), makine çevirisi ve görme gibi görevler için çok yararlı olabilecek tekrarlayan bir sinir ağıdır. LSTM'ler, bir önceki cümle veya görüntü verilen bir sonraki cümleyi veya görüntüyü oluşturabilmeleri için birden çok unutkanlık olayını hatırlayabilir.
LSTM'ler, bir bölümden (bağlamdan) bir şey hatırlamanız ve sonraki bölümde kullanmanız gereken belirli görevler için harika bir özel algoritmadır. Örneğin, geçmiş cümleleri hatırlayarak ve bu bilgiyi bir sonraki cümleyi oluşturmak için kullanarak birinin nasıl konuştuğunu modellemek isteyebilirsiniz.
LSTM'ler özellikle çok sayıda benzer girdiniz olduğunda kullanışlıdır (bir görüntüdeki benzer pikseller, metindeki benzer kelimeler). Bu durumlar akış sorunları olarak bilinir. Yeterli eğitim verisi ile bir LSTM, girdilerinin herhangi bir alt kümesi verildiğinde yüksek doğrulukla farklı çıktıların nasıl üretileceğini öğrenebilir. Makine çevirisi ve tanıma gibi makine öğrenimi görevlerinde bu kadar popüler olmalarının nedeni budur.
metodoloji
Bu projede yer alan iş boru hattı aşağıdaki gibidir:
- Kitaplıkları içe aktarın.
- Veri kümesini yükleyin.
- Keşif veri analizi.
- Etiketleri kodlama.
- Tahmin edici metin değerlerinin vektörleştirmesini sayın.
- Veri setini eğitim ve test setlerine ayırma.
- Lojistik regresyon, saf Bayes ve XGBoost kullanarak modeller oluşturma
- Yukarıdaki modellerin sonuçlarının karşılaştırılması.
- Bir LSTM modeli oluşturma.
- Modeli daha sonra kullanmak üzere kaydetme.
Kod Uygulama
Adım 1. Kitaplıkları İçe Aktarın
Herhangi bir veri ile çalışmak ve bir çözüm oluşturmak için önce gerekli kitaplıkları içe aktarmalıyız. Projemiz Numpy, Pandas, Matplotlib, Seaborn, Scikit-Learn, TensorFlow ve Keras'ı kullanacak.
import numpy as np import pandas as pd import matplotlib.pyplotas plt import seaborn as sns from wordcloud importWordCloudAdım 2. Veri Kümesini Yükleyin
dataset = pd.read_csv("C:\Users\admin\Desktop\ Python_anaconda\Projects\Name Gender\Gender_Data.csv")Adım 3. Keşifsel Veri Analizi
Artık verilerimiz hazır olduğuna göre, üzerinde çalışacağımız verileri daha iyi anlamak için bunlara bir göz atalım.
Veri Kümesi Örneği
dataset.head()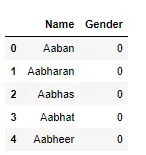
Niteliklerin Sütun Adları ve Veri Türleri
Veri kümesindeki her bir özelliğin veya sütunun veri türlerinin belirlenmesi, ne tür bir ön işleme yapılması gerektiğine karar verilmesine yardımcı olur.
print(dataset.columns) print(dataset.dtypes)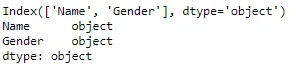
Veri setinde iki özellik olduğunu görüyoruz. "Ad" özelliği, kişinin adına karşılık gelir ve "Cinsiyet" sütunları, kişinin erkek mi yoksa kadın mı olduğunu gösterir.
Sütun Değerlerini Değiştirme
Burada 'Cinsiyet' sütunundaki 0 ve 1, sırasıyla erkek ve kadını ifade eder. Ancak kolaylık sağlamak için bunları 'M' ve 'F' ile değiştireceğiz.
dataset['Gender'] = dataset['Gender'].replace({0:"M",1:"F"})Verilerin Şekli
print(dataset.shape)Yukarıdaki kod parçacığını çalıştırmak bize toplam 53982 satır ve 2 sütun olduğunu gösterir. Yani 53982 isim var.
Benzersiz Adların Sayısı ve Sınıf Dengesizliğinin Aranması
print(len(dataset['Name'].unique()))53982 Hintli isim arasında 53925 benzersiz isim vardır, bu da tekrarlanan 57 değer olduğunu ima eder. Bunlar hem erkekler hem de kızlar için kullanılan isimlerdir ve bu nedenle birçok kez etiketlenmiştir.
Veri kümesinde kaç tane erkek ve kadın adı bulunduğunu görmek için bir grafik oluşturalım.
sns.countplot(x='Gender',data = dataset) plt.title('No. of male and female names in the dataset') plt.xticks([0,1],('Female','Male')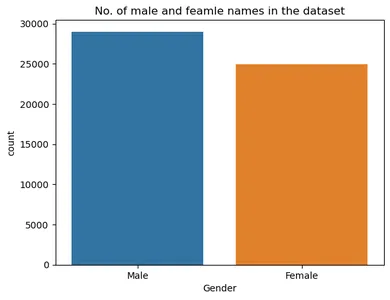
Yukarıdaki grafikten, büyük bir sınıf dengesizliği olmadığı açıkça görülmektedir.
İsimlerin Başlangıç Harfini Analiz Etme
Genel olarak, bir ismin ilk alfabesi olarak en yaygın olarak birkaç alfabe kullanılır. Veri setimiz, İngilizce alfabelerin başlangıç harflerine göre dağılımını görmemizi sağlar.
alphabets= ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P', 'Q','R','S','T','U','V','W','X','Y','Z'] startletter_count = {} for i in alphabets: startletter_count[i] = len(dataset[dataset['Name'].str.startswith(i)]) print(startletter_count)
Yukarıdaki bilgileri bir çubuk grafik kullanarak görselleştirmek, yaklaşık 6,000 ismin "A" harfiyle başladığını gösterir.
plt.figure(figsize = (16,8)) plt.bar(startletter_count.keys(),startletter_count.values()) plt.xlabel('Starting alphabet') plt.ylabel('No. of names') plt.title('Number of names starting with each letter')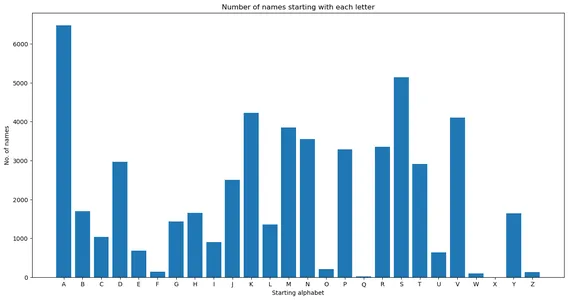
İsimlerin çoğunun başladığı en yaygın alfabelerin neler olduğunu görelim.
print('The 5 most name starting letters are : ', *sorted(startletter_count.items(), key=lambda item: item[1])[-5:][::-1])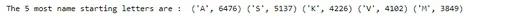
Hintli isimlerin çoğu A, S, K, V ve M harfleriyle başlar.
İsimlerin Bitiş Harfini Analiz Etme
Benzer şekilde, şimdi ortak bitiş harflerinin ne olduğunu ve veri kümesindeki adlar arasındaki dağılımlarını görelim.
small_alphabets = ['a','b','c','d','e','f','g','h', 'i','j','k','l','m','n','o','p','q','r','s','t','u','v','x','y','z'] endletter_count ={} for i in small_alphabets: endletter_count[i]=len(dataset[dataset['Name'].str.endswith(i)]) print(endletter_count)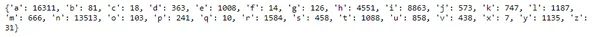
plt.figure(figsize = (16,8)) plt.bar(endletter_count.keys(),endletter_count.values()) plt.xlabel('Ending alphabet') plt.ylabel('No. of names') plt.title('Number of names ending with each letter')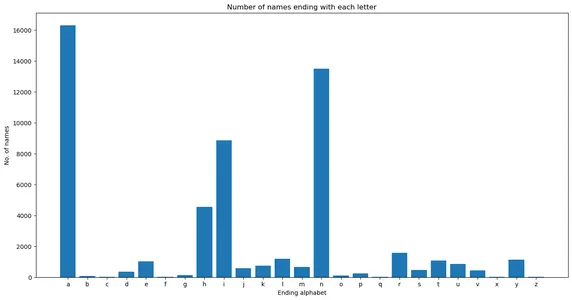
Yukarıdaki çubuk grafik, yaklaşık 16000 ve 14000 ismin "a" ve "n" harfleriyle bittiğini göstermektedir.
print('The 5 most name endind letters are : ', *sorted(endletter_count.items(), key=lambda item: item[1])[-5:][::-1])Yukarıda belirtilen kodu çalıştırmak bize aşağıdaki çıktıyı verir:
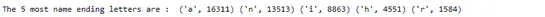
Bu nedenle isimlerin çoğu “a”, “n”, “i”, “h” ve “r” harfleriyle biter.
kelime Bulutu
Kelime bulutları genellikle metinsel verileri görselleştirmemize yardımcı olur. Veri setindeki isimleri temsil eden bir kelime bulutu oluşturacağız. Her ismin boyutu, veri kümesindeki sıklığına bağlı olacaktır.
# building a word cloud text = " ".join(i for i in dataset.Name) word_cloud = WordCloud( width=3000, height=2000, random_state=1, background_color="white", colormap="BuPu", collocations=False, stopwords=STOPWORDS, ).generate(text) plt.imshow(word_cloud) plt.axis("off") plt.show()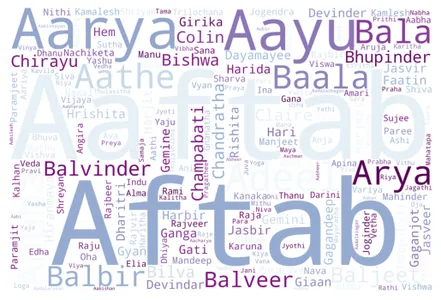
Kelime bulutu içinde 'A' harfi ile başlayan isimlerin belirgin bir şekilde görünür olduğunu görebiliriz. Bu, veri kümesindeki adların çoğunun 'A' harfiyle başladığına dair daha önceki analizimizi destekler.
Adım 4. Modelleri Oluşturma
İlk önce tahmin değişkeni 'X'i ve hedef değişkeni 'Y'yi tanımlayalım. İkili sınıflandırma problemimizde, 'İsim' belirleyici, 'Cinsiyet' ise hedef özniteliktir. İsme göre cinsiyet belirlememiz gerekiyor.
X =list( dataset['Name']) Y = list(dataset['Gender'])Etiketleri Kodlayın
Şimdi, 'F' ve 'M' etiketlerini makine tarafından okunabilir bir formata dönüştürmek için Sklearn'deki LabelEncoder özelliğini kullanıyoruz.
from sklearn.preprocessing importLabelEncoder encoder= LabelEncoder() Y = encoder.fit_transform(Y)Sayı Vektörleştirme
Modelleme sürecini kolaylaştırmak için isimleri vektör benzeri verilere vektörleştiriyoruz. 'X' değişkeni bir vektör dizisine dönüştürülür.
from sklearn.feature_extraction.text import CountVectorizer cv=CountVectorizer(analyzer='char') X=cv.fit_transform(X).toarray()Veri Kümesini Bölme
Artık hedef ve öngörücü değişkenlerimiz modelleme için kullanılmaya hazır olduğuna göre, veri setini eğitim ve test setlerine ayırıyoruz. Verileri, %33'ü test için ayrılacak ve geri kalanı modellerin ilk eğitimi için kullanılacak şekilde böleceğiz.
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=42)Lojistik regresyon
Burada, önce tüm modelleri oluşturup test edeceğiz ve daha sonra performanslarını değerlendireceğiz. Kullanacağımız ilk algoritma lojistik regresyondur. İlk olarak LogisticRegression fonksiyonunu Scikit-Learn'den import edeceğiz ve ardından onu kullanarak bir model oluşturacağız. Ardından, eğitim amacıyla x_train ve y_train'i modele sığdırıyoruz. Son olarak, daha önce oluşturduğumuz test veri seti üzerinde modeli test ediyoruz.
from sklearn.linear_model import LogisticRegression LR_model= LogisticRegression() LR_model.fit(x_train,y_train) LR_y_pred = LR_model.predict(x_test)Naif bayanlar
Modelleri oluşturmak için boru hattı aynı kalacaktır.
from sklearn.naive_bayes import MultinomialNB NB_model= MultinomialNB() NB_model.fit(x_train,y_train) NB_y_pred = NB_model.predict(x_test)XGBoost
from xgboost import XGBClassifier XGB_model = XGBClassifier(use_label_encoder= False) XGB_model.fit(x_train,y_train) XGB_y_pred = XGB_model.predict(x_test)Performans Karşılaştırması
Modelin performansını değerlendirmek için, bir değerlendirme ölçüsü olarak doğruluğu kullanacağız ve ayrıca ilgili model tarafından kaç tane doğru ve yanlış tahmin yapıldığını görmek için bir karışıklık matrisi oluşturacağız.
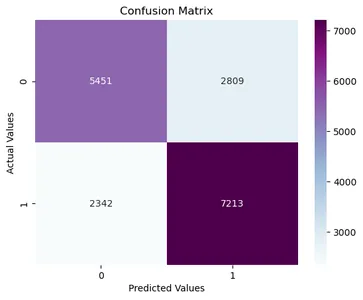
# function for confusion matrix from sklearn.metrics import confusion_matrix def cmatrix(model): y_pred = model.predict(x_test) cmatrix = confusion_matrix(y_test, y_pred) print(cmatrix) sns.heatmap(cmatrix,fmt='d',cmap='BuPu',annot=True) plt.xlabel('Predicted Values') plt.ylabel('Actual Values') plt.title('Confusion Matrix')import sklearn.metrics as metrics #for logistic regression print(metrics.accuracy_score(LR_y_pred,y_test)) print(metrics.classification_report(y_test, LR_y_pred)) print(cmatrix(LR_model))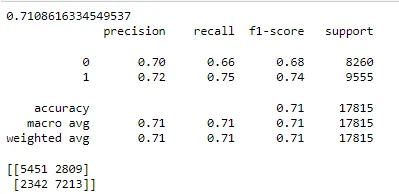
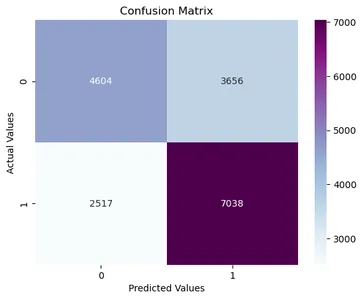
# for naive bayes print(metrics.accuracy_score(NB_y_pred,y_test)) print(metrics.classification_report(y_test, NB_y_pred)) print(cmatrix(NB_model))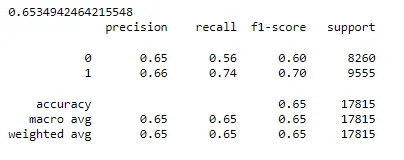
# for XGBoost
print(metrics.accuracy_score(XGB_y_pred,y_test)) print(metrics.classification_report(y_test, XGB_y_pred)) print(cmatrix(XGB_model))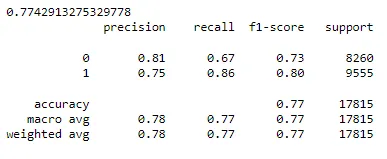
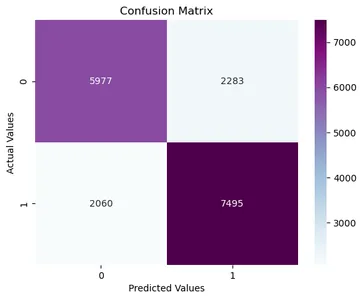
Yukarıdaki çıktılara bakıldığında, lojistik regresyonun doğruluğu %71'dir. Yaklaşık 3000 kadın ismini erkek olarak ve 2300 erkek ismini kadın olarak sınıflandırdı.
Bahsedilen üç algoritmadan XGBoost daha iyi performans göstermiş görünüyor. 77 test örneğinden yapılan 4343 yanlış tahminle %17815 gibi oldukça iyi bir doğruluğa sahipti.
LSTM
XGBoost kullanarak iyi bir doğruluk elde etmemize rağmen, derin öğrenme modellerini kullanarak sınıflandırmayı daha da geliştirebiliriz. LSTM, metin sınıflandırması için en yaygın kullanılan sinir ağlarından biridir. Cinsiyet sınıflandırması için bir LSTM ağı oluşturacağız ve performansını verilerimiz üzerinde test edeceğiz.
Gerekli Kitaplıkları İçe Aktar
Bir LSTM ağı oluşturmak, Keras ve TensorFlow gibi daha gelişmiş kitaplıklar gerektirir.
Naive Bayes, yalnızca %65 test doğruluğu ile lojistik regresyondan çok daha az verimli performans gösterdi.
from tensorflow.keras import models
from tensorflow.keras.models import Model
from tensorflow.keras.models import load_model
from keras.layers import Embedding
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input, LeakyReLU
from tensorflow.keras.layers import BatchNormalization, Activation, Conv2D from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, MaxPooling2D, Dense, Dropout
from tensorflow.keras.layers import LSTMLSTM Katmanlarını Tanımlama
max_words = 1000 max_len = 26 LSTM_model = Sequential() LSTM_model.add(Embedding(voc_size,40,input_length=26)) LSTM_model.add(Dropout(0.3)) LSTM_model.add(LSTM(100)) LSTM_model.add(Dropout(0.3)) LSTM_model.add(Dense(64,activation='relu')) LSTM_model.add(Dropout(0.3)) LSTM_model.add(Dense(1,activation='sigmoid')) LSTM_model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy']) print(LSTM_model.summary())
Eğitim
Ağı oluşturduğumuza göre, x_train ve y_train özelliklerini kullanarak onu eğiteceğiz. Modelin doğru bir şekilde genellenebilmesini sağlamak için 100 dönem kullanacağız.
LSTM_model.fit(x_train,y_train,epochs=100,batch_size=64)Bu adımın uygulanması biraz zaman alacaktır.
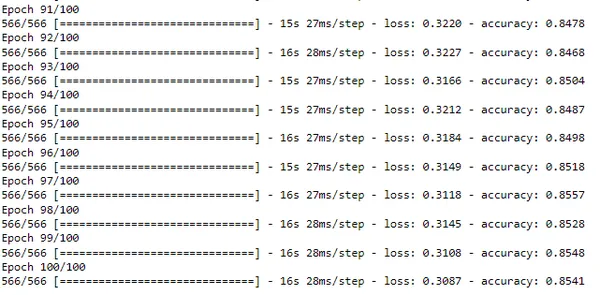
Yukarıdaki resim, çıktının yalnızca son parçasını gösterir. LSTM'nin %85 doğruluk verdiğini görüyoruz ki bu XGBoost'tan %8 daha fazla. Herhangi bir ismi girdi olarak alan ve bu LSTM modelini kullanarak ismi sınıflandıran bir fonksiyon tanımlayalım.
def predict(name): prediction = LSTM_model.predict([name_samplevector]) if prediction >=0.5: out = 'Male ♂' else: out = 'Female ♀'print(name+' is a '+ out)Örnek testi
predict('Yamini Ane') name_samplevector = cv.transform([name]).toarray()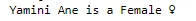
Modelin 'Yamini Ane' ismini kadın olarak tahmin ettiğini görüyoruz. Ancak, modelin yanlış tahminlerde bulunduğu bazı durumlar olabilir. Bunun nedeni, modeli eğitmek için yalnızca Hint adlarının kullanılmış olması olabilir.
Son olarak, bu LSTM'yi daha fazla kullanım için kaydedeceğiz.
import pickle pickle.dump(LSTM_model, open("LSTM_model.pkl", 'wb'))Sonuç
Bu da bizi toplumsal cinsiyet sınıflandırma projesinin sonuna getiriyor. Çalışmalarımızı gözden geçirelim. İlk olarak, kullanacağımız algoritmalara ve NLP uygulama boru hattına bakarak sorun bildirimimizi tanımlayarak başladık. Ardından, lojistik regresyon, naif Bayes ve XGBoost algoritmalarını kullanarak adlara dayalı cinsiyet tanımlama ve sınıflandırmasını pratik olarak uygulamaya geçtik. İleriye dönük olarak, bu modellerin performanslarını karşılaştırdık. Son olarak, bir LSTM ağı kurduk ve isme dayalı cinsiyet tanımlama NLP problemlerinde en iyi sonucu verdiğini kanıtladık.
Bu NLP projesinin ana çıkarımları şunlardır:
- İsim kullanarak cinsiyetin belirlenmesi birçok işletme için önemlidir.
- XGBoost, cinsiyet sınıflandırma problemlerinde kullanıldığında lojistik regresyon ve naif bölmelere kıyasla daha iyi doğruluk sağlar.
- LSTM, metin sınıflandırması için en iyi şekilde çalışan tekrarlayan bir sinir ağıdır.
- LSTM, en doğru sonuçları vererek %85'lik bir doğruluk sağlar.
“NLP ve Python Kullanarak İsim Cinsiyet Sınıflandırması” başlıklı yazımı umarım beğenirsiniz. Kodun tamamı benim içinde bulunabilir GitHub depo. benimle buradan bağlantı kurabilirsiniz LinkedIn.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/03/name-based-gender-identification-using-nlp-and-python/
- :dır-dir
- ][P
- $UP
- 000
- 1
- 100
- 8
- a
- yukarıdaki
- doğruluk
- doğru
- tam olarak
- karşısında
- Etkinleştirme
- Adem
- ileri
- algoritma
- algoritmalar
- Türkiye
- tahsis
- Alfabe
- Rağmen
- analiz
- analytics
- Analitik Vidhya
- ve
- karınca
- uygulamaları
- yaklaşık olarak
- ARE
- etrafında
- Dizi
- göre
- AS
- At
- öznitelikleri
- mevcut
- bar
- merkezli
- BE
- Çünkü
- olur
- İYİ
- Daha iyi
- arasında
- blogathon
- arttırdı
- Getiriyor
- inşa etmek
- bina
- yapılı
- iş
- işletmeler
- by
- CAN
- yetenekleri
- yetenekli
- durumlarda
- Kategoriler
- belli
- meydan okuma
- Grafik
- seçim
- sınıf
- sınıflar
- sınıflandırma
- sınıflandırma sistemi
- sınıflandırılmış
- sınıflandırmak
- bulut
- kod
- Sütun
- Sütunlar
- birleştirme
- nasıl
- ortak
- çoğunlukla
- karşılaştırıldığında
- kavramlar
- sonuç
- karışıklık
- Sosyal medya
- Düşünmek
- içeren
- bağlam
- kolaylık
- dönüştürmek
- dönüştürülmüş
- tekabül
- olabilir
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- çok önemli
- eğri
- müşteri
- Müşteri Hizmetleri
- veri
- veri analizi
- anlaşma
- karar vermek
- kararlar
- derin
- derin öğrenme
- tanımlarken
- tasarlanmış
- Belirlemek
- farklı
- zor
- takdir
- tartışmak
- ayırmak
- dağıtım
- e
- her
- Daha erken
- kolay
- kolay
- verimli
- verimli biçimde
- gömülü
- İngilizce
- yeterli
- sağlamak
- Tüm
- Baştan sona
- Bölümler
- devirler
- özellikle
- Eter (ETH)
- değerlendirmek
- değerlendirilmesi
- değerlendirme
- örnek
- aşırı
- HIZLI
- Özellikler(Hazırlık aşamasında)
- Özellikler
- kadın
- az
- maliye
- Ad
- uygun
- sabit
- takip etme
- şu
- İçin
- biçim
- ileri
- bulundu
- Sıklık
- itibaren
- işlev
- daha fazla
- Cinsiyet
- genellikle
- oluşturmak
- üreten
- kızlar
- verilmiş
- verir
- Verilmesi
- gidiş
- Tercih Etmenizin
- grafik
- harika
- Var
- yardım et
- yardımcı olur
- okuyun
- Yüksek
- umut
- Ne kadar
- Nasıl Yapılır
- Ancak
- HTTPS
- i
- Kimlik
- belirlemek
- belirlenmesi
- Kimlik
- görüntü
- dengesizlik
- uygulamak
- uygulama
- uygulanması
- ithalat
- önemli
- iyileştirmek
- in
- Dahil olmak üzere
- bağımsız
- Hintli
- bilgi
- ilk
- giriş
- Giriş
- sezgi
- ilgili
- IT
- ONUN
- keras
- anahtar
- Nezaket.
- Bilmek
- bilinen
- etiket
- Etiketler
- Diller
- büyük
- Soyad
- katmanları
- ÖĞRENİN
- öğrendim
- öğrenme
- Lets
- mektup
- kütüphaneler
- Kütüphane
- sevmek
- yük
- Uzun
- Bakın
- bakıyor
- makine
- makine öğrenme
- makine çevirisi
- yapılmış
- büyük
- yapmak
- YAPAR
- Yapımı
- çok
- Pazarlama
- matplotlib
- Matris
- ölçmek
- medya
- Bellek
- Erkek
- adı geçen
- metodoloji
- Metrikleri
- en az
- ML
- model
- Modelleme
- modelleri
- Daha
- çoğu
- hareketli
- çoklu
- isim
- adlı
- isimleri
- nav
- gerekli
- gerek
- ağ
- ağlar
- sinirsel
- sinir ağı
- nöral ağlar
- sonraki
- nlp
- numara
- dizi
- elde
- of
- on
- ONE
- Online
- Opsiyonlar
- Diğer
- çıktı
- Sahip olunan
- pandalar
- Bölüm
- geçmiş
- model
- İnsanlar
- performans
- performansları
- kişi
- resim
- boru hattı
- Platon
- Plato Veri Zekası
- PlatoVeri
- Nokta
- Popüler
- güçlü
- pratikte
- tahmin
- tahmin
- tahmin
- Tahminler
- Predictor
- mevcut
- güzel
- önceki
- Önceki
- Sorun
- sorunlar
- süreç
- proje
- kanıtladı
- sağlar
- yayınlanan
- amaçlı
- Python
- Hızlı
- hızla
- Çiğ
- hazır
- tanıma
- ifade eder
- gerileme
- ilişki
- kalmak
- kalan
- hatırlamak
- hatırlama
- tekrarlanan
- değiştirmek
- Depo
- temsil etmek
- temsil
- temsil
- gerektirir
- bu
- DİNLENME
- Sonuçlar
- yorum
- s
- aynı
- İndirim
- ölçeklenebilir
- Bilim
- scikit-öğrenme
- Seaborn
- Bölüm
- görünüyor
- cümle
- hizmet
- Setleri
- Shape
- kısa dönem
- meli
- gösterilen
- Gösteriler
- benzer
- durumlar
- beden
- So
- çözüm
- ÇÖZMEK
- Çözme
- biraz
- Birisi
- bir şey
- seyrek matris
- Konuştu
- özel
- özel
- bölmek
- standları
- başlama
- başladı
- XNUMX dakika içinde!
- Açıklama
- adım
- Basamaklar
- akış
- böyle
- denetimli öğrenme
- Destekler
- sistem
- tablo
- Bizi daha iyi tanımak için
- Takeaways
- alır
- Hedef
- görevleri
- anlatır
- tensorflow
- test
- Test yapmak
- Metin Sınıflandırması
- o
- The
- ve bazı Asya
- Onları
- Bunlar
- üç
- eşik
- zaman
- zamanlar
- için
- bugün
- Konular
- Toplam
- Tren
- Eğitim
- transforme
- Çeviri
- Ağaçlar
- türleri
- ilintisiz
- anlamak
- anlayış
- benzersiz
- us
- kullanım
- kullanım
- değer
- Değerler
- değişkenler
- çeşitli
- gözle görülür
- vizyonumuz
- görselleştirmek
- W
- Yol..
- Ne
- hangi
- süre
- beyaz
- DSÖ
- geniş ölçüde
- irade
- ile
- Kadın
- Word
- sözler
- İş
- çalışma
- çalışır
- Yanlış
- X
- XGBoost
- zefirnet