Зображення автора
Однією з сфер, яка лежить в основі науки про дані, є машинне навчання. Отже, якщо ви хочете потрапити в науку про дані, розуміння машинного навчання є одним із перших кроків, які вам потрібно зробити.
Але з чого почати? Ви починаєте з розуміння різниці між двома основними типами алгоритмів машинного навчання. Тільки після цього ми можемо говорити про окремі алгоритми, які повинні бути в списку ваших пріоритетів для вивчення як новачка.
Основна відмінність між алгоритмами полягає в тому, як вони навчаються.

Зображення автора
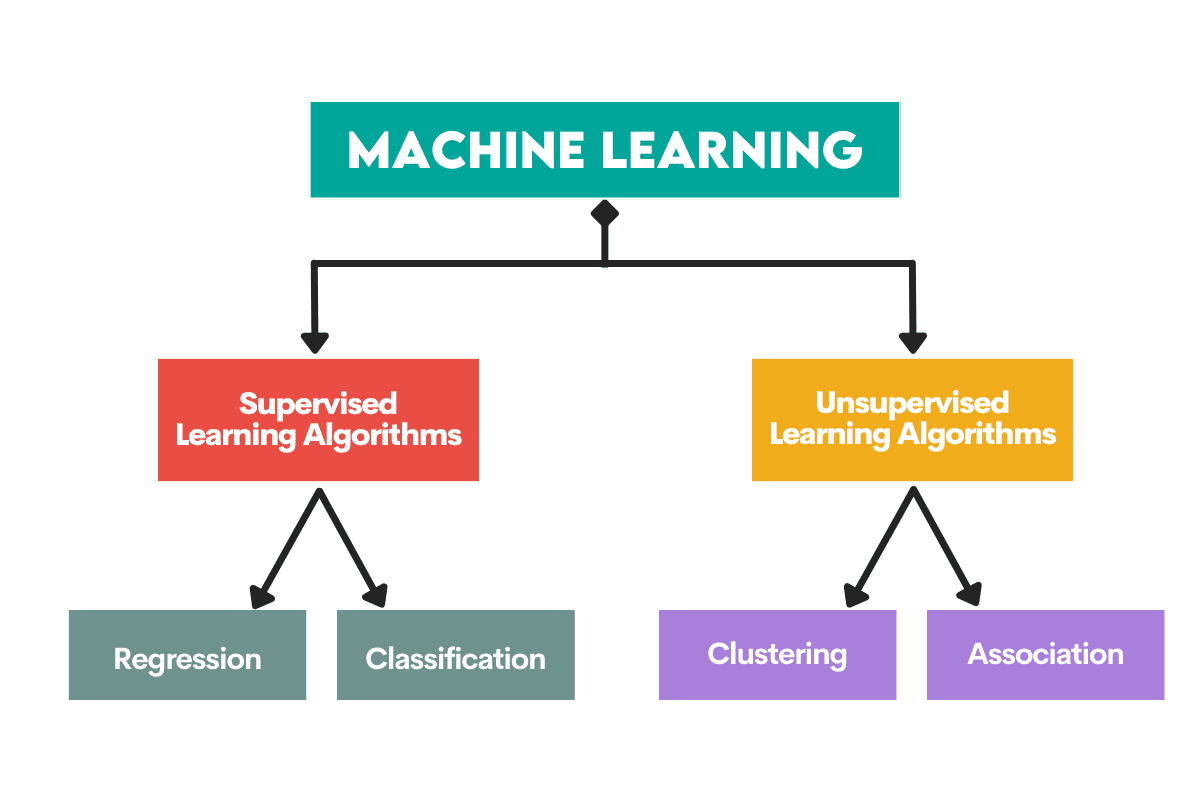
Алгоритми навчання під наглядом навчаються на a позначений набір даних. Цей набір даних служить для спостереження (звідси і назва) для навчання, оскільки деякі дані, які він містить, уже позначені як правильна відповідь. На основі цих вхідних даних алгоритм може вивчати та застосовувати це навчання до решти даних.
З іншого боку, алгоритми неконтрольованого навчання вчитися на ан набір даних без міток, тобто вони беруть участь у пошуку шаблонів у даних без вказівок від людей.
Ви можете прочитати докладніше про алгоритми машинного навчання і види навчання.
Існують також деякі інші види машинного навчання, але не для початківців.
Алгоритми використовуються для вирішення двох основних проблем у кожному типі машинного навчання.
Знову ж таки, є ще завдання, але вони не для новачків.
Зображення автора
Контрольовані навчальні завдання
Регресія є завдання прогнозування a числове значення, Називаний безперервна змінна результату або залежна змінна. Прогноз ґрунтується на змінній (змінних) предиктора або незалежній змінній (змінних).
Подумайте про прогнозування цін на нафту чи температури повітря.
Класифікація використовується для прогнозування категорія (клас) вхідних даних. The змінна результату ось категоричний або дискретний.
Подумайте про те, чи є лист спамом чи не спамом, чи захворіє пацієнт на певну хворобу чи ні.
Навчальні завдання без контролю
Кластеризація засоби поділ даних на підмножини або кластери. Мета полягає в тому, щоб групувати дані якомога природніше. Це означає, що точки даних в одному кластері більше схожі одна на одну, ніж точки даних з інших кластерів.
Зменшення розмірності означає зменшення кількості вхідних змінних у наборі даних. Це в основному означає скорочуючи набір даних до дуже небагатьох змінних, але все ще фіксуючи його суть.
Ось огляд алгоритмів, про які я розповім.
Зображення автора
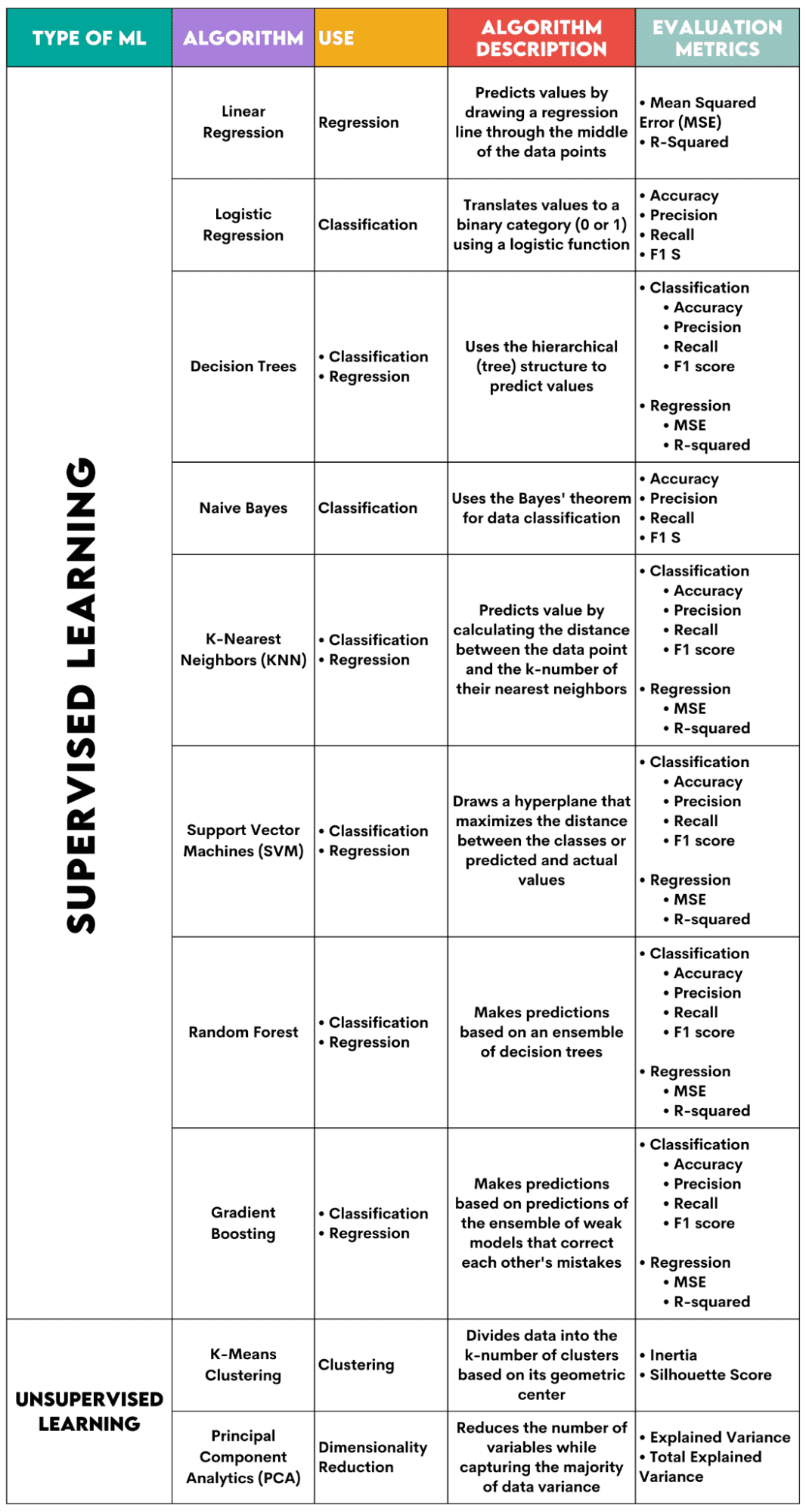
Контрольовані алгоритми навчання
Вибираючи алгоритм для вашої задачі, важливо знати, для якої задачі цей алгоритм використовується.
Як фахівець із обробки даних, ви, ймовірно, застосуєте ці алгоритми в Python за допомогою бібліотека scikit-learn. Хоча він робить (майже) все за вас, бажано знати принаймні загальні принципи внутрішньої роботи кожного алгоритму.
Нарешті, після навчання алгоритму ви повинні оцінити, наскільки добре він працює. Для цього кожен алгоритм має деякі стандартні показники.
1. Лінійна регресія
Використовуваний для: Регресія
Опис: Лінійна регресія малює пряму лінію називається лінією регресії між змінними. Ця лінія проходить приблизно через середину точок даних, таким чином мінімізуючи помилку оцінки. Він показує прогнозоване значення залежної змінної на основі значення незалежних змінних.
Метрики оцінювання:
- Середня квадратична помилка (MSE): представляє середнє значення квадрата помилки, причому помилка є різницею між фактичним і прогнозованим значеннями. Чим менше значення, тим краща продуктивність алгоритму.
- R-квадрат: представляє відсоток дисперсії залежної змінної, який можна передбачити незалежною змінною. Для цього показника ви повинні прагнути наблизитися до 1 якомога ближче.
2. Логістична регресія
Використовуваний для: Класифікація
Опис: Він використовує a логістична функція щоб перевести значення даних у двійкову категорію, тобто 0 або 1. Це робиться за допомогою порогового значення, яке зазвичай встановлюється на 0.5. Двійковий результат робить цей алгоритм ідеальним для передбачення двійкових результатів, таких як ТАК/НІ, ІСТИНА/ХИБЬ або 0/1.
Метрики оцінювання:
- Точність: співвідношення між правильними та загальними прогнозами. Чим ближче до 1, тим краще.
- Точність: міра точності моделі в позитивних прогнозах; показано як співвідношення між правильними позитивними прогнозами та загальними очікуваними позитивними результатами. Чим ближче до 1, тим краще.
- Нагадаємо: він також вимірює точність моделі в позитивних прогнозах. Він виражається як співвідношення між правильними позитивними прогнозами та загальними спостереженнями, зробленими в класі. Докладніше про ці показники тут.
- Оцінка F1: Середнє гармонійне відкликання та точності моделі. Чим ближче до 1, тим краще.
3. Дерева рішень
Використовуваний для: Регресія та класифікація
Опис: Рішення дерев це алгоритми, які використовують ієрархічну або деревоподібну структуру для прогнозування значення або класу. Кореневий вузол представляє весь набір даних, який потім розгалужується на вузли прийняття рішень, розгалуження та листя на основі значень змінних.
Метрики оцінювання:
- Точність, точність, запам'ятовування та оцінка F1 -> для класифікації
- MSE, R-квадрат -> для регресії
4. Наївний Байєс
Використовуваний для: Класифікація
Опис: Це сімейство алгоритмів класифікації, які використовують Теорема Байєса, тобто вони припускають незалежність між функціями в межах класу.
Метрики оцінювання:
- Точність
- Точність
- Згадувати
- F1 бал
5. K-найближчі сусіди (KNN)
Використовуваний для: Регресія та класифікація
Опис: Він обчислює відстань між тестовими даними та k-кількість найближчих точок даних з даних навчання. Тестові дані належать до класу з більшою кількістю «сусідів». Щодо регресії, прогнозоване значення є середнім k вибраних точок навчання.
Метрики оцінювання:
- Точність, точність, запам'ятовування та оцінка F1 -> для класифікації
- MSE, R-квадрат -> для регресії
6. Підтримка векторних машин (SVM)
Використовуваний для: Регресія та класифікація
Опис: Цей алгоритм малює a гіперплощина розділяти різні класи даних. Він розташований на найбільшій відстані від найближчих точок кожного класу. Чим вище відстань точки даних від гіперплощини, тим більше вона належить до свого класу. Для регресії принцип аналогічний: гіперплощина максимізує відстань між прогнозованими та фактичними значеннями.
Метрики оцінювання:
- Точність, точність, запам'ятовування та оцінка F1 -> для класифікації
- MSE, R-квадрат -> для регресії
7. Випадковий ліс
Використовуваний для: Регресія та класифікація
Опис: Алгоритм випадкового лісу використовує ансамбль дерев рішень, які потім створюють ліс рішень. Прогнозування алгоритму базується на передбаченні багатьох дерев рішень. Дані будуть віднесені до класу, який набере найбільшу кількість голосів. Для регресії прогнозоване значення є середнім серед усіх прогнозованих значень дерев.
Метрики оцінювання:
- Точність, точність, запам'ятовування та оцінка F1 -> для класифікації
- MSE, R-квадрат -> для регресії
8. Посилення градієнта
Використовуваний для: Регресія та класифікація
Опис: Ці алгоритми використовувати ансамбль слабких моделей, при цьому кожна наступна модель розпізнає та виправляє помилки попередньої моделі. Цей процес повторюється, поки помилка (функція втрат) не буде мінімізована.
Метрики оцінювання:
- Точність, точність, запам'ятовування та оцінка F1 -> для класифікації
- MSE, R-квадрат -> для регресії
Алгоритми неконтрольованого навчання
9. Кластеризація K-середніх
Використовуваний для: Кластеризація
Опис: Алгоритм ділить набір даних на k-число кластерів, кожен представлений своїм центроїд або геометричний центр. За допомогою ітераційного процесу поділу даних на k-кількість кластерів мета полягає в тому, щоб мінімізувати відстань між точками даних і центроїдом їхнього кластера. З іншого боку, він також намагається максимізувати відстань цих точок даних від центроїда інших кластерів. Простіше кажучи, дані, що належать одному кластеру, повинні бути якомога схожішими та максимально відрізнятися від даних з інших кластерів.
Метрики оцінювання:
- Інерція: сума квадратів відстані кожної точки даних від найближчого центроїда кластера. Чим менше значення інерції, тим компактніше кластер.
- Оцінка силуету: вимірює згуртованість (подібність даних у межах власного кластера) та відокремлення (відмінність даних від інших кластерів) кластерів. Значення цієї оцінки коливається від -1 до +1. Чим вище значення, тим краще дані відповідають своєму кластеру, і тим гірше вони відповідають іншим кластерам.
10. Аналіз основних компонентів (PCA)
Використовуваний для: Зменшення розмірності
Опис: Алгоритм зменшує кількість використовуваних змінних шляхом створення нових змінних (основних компонентів), намагаючись максимізувати отриману дисперсію даних. Іншими словами, він обмежує дані найпоширенішими компонентами, не втрачаючи суті даних.
Метрики оцінювання:
- Пояснена дисперсія: відсоток дисперсії, що покривається кожним основним компонентом.
- Загальна пояснена дисперсія: відсоток дисперсії, охоплений усіма основними компонентами.
Машинне навчання є важливою частиною науки про дані. За допомогою цих десяти алгоритмів ви охопите найпоширеніші завдання машинного навчання. Звичайно, цей огляд дає лише загальне уявлення про те, як працює кожен алгоритм. Отже, це тільки початок.
Тепер вам потрібно навчитися реалізовувати ці алгоритми в Python і вирішувати реальні проблеми. Для цього я рекомендую використовувати scikit-learn. Не лише тому, що це відносно проста у використанні бібліотека ML, але й через її обширні матеріали на алгоритмах ML.
Нейт Розіді є науковцем з обробки даних і займається стратегією продуктів. Він також є ад’юнкт-професором, який викладає аналітику, і є засновником StrataScratch, платформи, яка допомагає дослідникам даних готуватися до інтерв’ю за допомогою реальних питань для інтерв’ю від провідних компаній. Нейт пише про останні тенденції ринку кар’єри, дає поради на співбесідах, ділиться науковими проектами з даних і охоплює все, що стосується SQL.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.kdnuggets.com/a-beginner-guide-to-the-top-10-machine-learning-algorithms?utm_source=rss&utm_medium=rss&utm_campaign=a-beginners-guide-to-the-top-10-machine-learning-algorithms
- : має
- :є
- : ні
- :де
- 1
- 10
- 5
- a
- МЕНЮ
- точність
- фактичний
- доповнення
- рада
- доцільно
- після
- AIR
- алгоритм
- алгоритми
- ВСІ
- майже
- вже
- Також
- хоча
- an
- аналітика
- та
- відповідь
- Застосовувати
- приблизно
- ЕСТЬ
- AS
- призначений
- припустити
- At
- спроба
- середній
- заснований
- В основному
- BE
- оскільки
- Початківець
- початківці
- буття
- належність
- належить
- Краще
- між
- двійковий
- гілки
- але
- by
- обчислює
- званий
- CAN
- захоплений
- захопивши
- кар'єра
- Категорія
- певний
- Вибираючи
- вибраний
- клас
- класів
- класифікація
- близько
- ближче
- Найближчий
- кластер
- згуртованість
- загальний
- компактний
- Компанії
- компонент
- Компоненти
- будівництво
- містить
- виправити
- курс
- обкладинка
- покритий
- охоплює
- дані
- точки даних
- наука про дані
- вчений даних
- рішення
- залежний
- деталь
- різниця
- різний
- напрямки
- Захворювання
- відстань
- чіткий
- відмінність
- розділяє
- поділ
- do
- робить
- зроблений
- малює
- e
- кожен
- легкий у використанні
- працевлаштований
- займатися
- помилка
- помилки
- сутність
- істотний
- Ефір (ETH)
- оцінювати
- Кожен
- все
- очікуваний
- пояснені
- виражений
- f1
- сім'я
- риси
- кілька
- Поля
- виявлення
- Перший
- перші кроки
- для
- ліс
- засновник
- від
- функція
- Загальне
- отримати
- дає
- дає
- мета
- йде
- Group
- керівництво
- рука
- he
- допомогу
- отже
- тут
- вище
- Як
- How To
- HTML
- HTTPS
- Людей
- i
- Я БУДУ
- ідея
- if
- здійснювати
- важливо
- in
- В інших
- незалежність
- незалежний
- індивідуальний
- інерція
- внутрішній
- вхід
- інтерв'ю
- питання інтерв'ю
- інтерв'ю
- в
- IT
- ЙОГО
- просто
- KDnuggets
- Знати
- найбільших
- останній
- УЧИТЬСЯ
- вивчення
- найменш
- листя
- бібліотека
- рамки
- Лінія
- лінійний
- список
- програш
- від
- знизити
- машина
- навчання за допомогою машини
- Машинки для перманенту
- made
- головний
- зробити
- РОБОТИ
- багато
- ринок
- відповідає
- Максимізувати
- максимізує
- значити
- сенс
- засоби
- вимір
- заходи
- Метрика
- Середній
- мінімізувати
- мінімізація
- ML
- Алгоритми ML
- модель
- Моделі
- більше
- найбільш
- наївний
- ім'я
- природно
- Необхідність
- сусіди
- Нові
- вузол
- вузли
- номер
- спостереження
- of
- Нафта
- on
- ONE
- тільки
- or
- Інше
- Результат
- Результати
- огляд
- власний
- частина
- пацієнт
- моделі
- відсоток
- ідеальний
- продуктивність
- виступає
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- точка
- точок
- розташовані
- позитивний
- це можливо
- Точність
- передбачати
- передвіщений
- прогнозування
- прогноз
- Прогнози
- Прогноз
- Готувати
- попередній
- ціни
- Головний
- принцип
- Принципи
- пріоритет
- ймовірно
- Проблема
- проблеми
- процес
- Product
- Професор
- проектів
- put
- Python
- питань
- випадковий
- діапазони
- співвідношення
- Читати
- реальний
- отримує
- визнаючи
- рекомендувати
- знижує
- зниження
- відноситься
- про
- регресія
- щодо
- повторний
- представлений
- представляє
- REST
- корінь
- s
- то ж
- наука
- вчений
- Вчені
- scikit-вчитися
- рахунок
- окремий
- служить
- комплект
- акції
- Повинен
- показаний
- Шоу
- аналогічний
- просто
- So
- ВИРІШИТИ
- деякі
- спам
- SQL
- в квадраті
- standard
- старт
- заходи
- Як і раніше
- прямий
- Стратегія
- прагнути
- структура
- наступні
- такі
- сума
- нагляд
- підтримка
- SVG
- Приймати
- балаканина
- Завдання
- завдання
- Навчання
- десять
- тест
- ніж
- Що
- Команда
- їх
- потім
- Там.
- Ці
- вони
- це
- поріг
- через
- Таким чином
- до
- занадто
- топ
- Кращі 10
- Усього:
- навчений
- Навчання
- переводити
- дерево
- Дерева
- Тенденції
- намагається
- турінг
- два
- тип
- Типи
- розуміння
- до
- використання
- використовуваний
- використовує
- використання
- зазвичай
- значення
- Цінності
- змінна
- змінні
- вектор
- дуже
- голосів
- хотіти
- we
- ДОБРЕ
- Що
- який
- в той час як
- всі
- Вікіпедія
- волі
- з
- в
- без
- слова
- виробки
- працює
- гірше
- ви
- вашу
- зефірнет