Вступ
У швидкоплинному світі підтримки клієнтів ефективність і оперативність мають першорядне значення. Використання великих мовних моделей (LLM), як-от GPT-3.5 OpenAI для оптимізації проектів у підтримці клієнтів, відкриває унікальну перспективу. У цій статті досліджується застосування LLM для автоматизації сортування квитків, забезпечуючи безперебійне та ефективне рішення для команд підтримки клієнтів. Крім того, ми включимо практичну реалізацію коду, щоб проілюструвати впровадження цього проекту.
Мета навчання
- Вивчіть фундаментальні концепції великих мовних моделей і те, як їх можна оптимізувати в різних аспектах управління проектами.
- Отримайте уявлення про конкретні сценарії проекту, включно з сортуванням заявок на основі настрою та автоматичним коментуванням коду, щоб зрозуміти різноманітні застосування LLM.
- Ознайомтеся з найкращими практиками, потенційними проблемами та міркуваннями під час інтеграції LLMs у процеси управління проектами, забезпечуючи ефективне та етичне використання цих передових мовних моделей.
Ця стаття була опублікована як частина Блогатон науки про дані.
Зміст
Оптимізація великої мовної моделі для проектів (LLMOP)
Оптимізація великої мовної моделі для проектів (LLMOP) представляє зміну парадигми в управлінні проектами, використовуючи розширені мовні моделі для автоматизації та вдосконалення різних аспектів життєвого циклу проекту.
Автоматизоване проектування та документація
Посилання: Поліпшення розуміння мови шляхом генеративної попередньої підготовки» (Radford et al., 2018)
LLMs, такі як OpenAI GPT-3, демонструють свою майстерність у розумінні природної мови, уможливлюючи автоматизоване планування проектів. Вони аналізують текстові дані для створення комплексних планів проекту, зменшуючи ручні зусилля на етапі планування. Крім того, LLMs сприяють створенню динамічної документації, забезпечуючи актуальність проектної документації з мінімальним втручанням людини.
Генерація та оптимізація коду
Великі мовні моделі продемонстрували виняткові можливості в розумінні вимог проекту високого рівня та створенні фрагментів коду. Дослідження вивчали використання LLM для оптимізації коду, де ці моделі надають код на основі специфікацій і аналізують існуючі кодові бази, щоб виявити неефективність і запропонувати оптимізовані рішення.
Системи підтримки прийняття рішень
Посилання: Мовні моделі мало хто вивчає» (Brown та ін., 2020)
LLM діють як надійні системи підтримки прийняття рішень, аналізуючи текстові дані та пропонуючи цінну інформацію. Незалежно від того, оцінюють відгуки користувачів, оцінюють ризики проекту чи виявляють вузькі місця, LLM сприяють прийняттю обґрунтованих рішень в управлінні проектами. Можливість швидкого навчання дозволяє LLM адаптуватися до конкретних сценаріїв прийняття рішень з мінімальною кількістю прикладів.
Сортування квитків на основі настрою
Посилання: Різні аналізи настроїв
Аналіз настроїв, ключовий компонент LLMOPs, передбачає навчання моделей для розуміння та класифікації настроїв у тексті. У контексті підтримки клієнтів сортування квитків на основі настроїв визначає пріоритетність проблем на основі настроїв клієнтів. Це забезпечує оперативне вирішення запитів, що виражають негативні настрої, тим самим покращуючи задоволеність клієнтів.
Створення сюжетної лінії на основі ШІ
Посилання: Мовні моделі мало хто вивчає (Brown та ін., 2020)
У сфері інтерактивних медіа магістерські програми LLM сприяють створенню сюжетної лінії на основі ШІ. Це передбачає динамічне створення та адаптацію сюжетних ліній на основі взаємодії користувача. Модель розуміє контекстуальні підказки та адаптує розповідь, надаючи користувачам персоналізований та захоплюючий досвід.
Проблема в сортуванні запитів служби підтримки клієнтів
Команди підтримки клієнтів часто стикаються з великою кількістю вхідних заявок, кожну з яких потрібно класифікувати та визначити пріоритети. Процес сортування вручну може зайняти багато часу та призвести до затримок у вирішенні критичних проблем. LLM можуть відігравати ключову роль в автоматизації процесу сортування квитків, дозволяючи командам підтримки зосередитися на наданні своєчасних і практичних рішень для клієнтів.
1. Автоматизована категоризація квитків
Можливе навчання LLM розумінню контексту запитів у службу підтримки клієнтів і класифікації їх на основі заздалегідь визначених критеріїв. Ця автоматизація забезпечує оптимізовані процеси вирішення, скеровуючи заявки відповідним командам або окремим особам.
2. Пріоритетне призначення на основі вмісту квитка
Визначення пріоритетів вимагає розуміння терміновості запиту в службу підтримки. LLM можуть автоматично призначати рівні пріоритету, аналізувати вміст заявок і знаходити ключові слова або почуття, які вказують на терміновість. Це гарантує швидке вирішення нагальних проблем.
3. Генерація відповідей на загальні запити
Запити, які часто зустрічаються, часто відповідають передбачуваним шаблонам. LLM можна використовувати для створення стандартних відповідей на поширені проблеми, заощаджуючи час для агентів служби підтримки. Це не тільки прискорює час відповіді, але й забезпечує узгодженість спілкування.
Унікальна перспектива: сортування квитків на основі настрою
Ця стаття буде зосереджена на унікальній перспективі в рамках LLMOPs – сортуванні квитків на основі настрою. Використовуючи аналіз настроїв за допомогою LLM, ми прагнемо визначити пріоритетність заявок у службу підтримки на основі емоційного тону, висловленого клієнтами. Такий підхід гарантує, що квитки, що відображають негативні настрої, розглядатимуться швидко, покращуючи задоволеність клієнтів.
Впровадження проекту: Система сортування квитків на основі настрою
Наш унікальний проект передбачає створення системи сортування квитків на основі настрою за допомогою LLM. Реалізація коду продемонструє, як аналіз настроїв можна інтегрувати в сортування заявок, щоб автоматично визначати пріоритети та класифікувати заявки служби підтримки.
Впровадження коду
# Importing necessary libraries
from transformers import AutoModelForSequenceClassification, AutoTokenizer, pipeline # Support tickets for analysis
support_tickets = [ "The product is great, but I'm having difficulty with the setup.", "I am extremely frustrated with the service outage!", "I love the new features in the latest update! Great job!", "The instructions for troubleshooting are clear and helpful.", "I'm confused about the product's pricing. Can you provide more details?", "The service is consistently unreliable, and it's frustrating.", "Thank you for your quick response to my issue. Much appreciated!"
] # Function to triage tickets based on sentiment
def triage_tickets(support_tickets, sentiment_analyzer): prioritized_tickets = {'positive': [], 'negative': [], 'neutral': []} for ticket in support_tickets: sentiment = sentiment_analyzer(ticket)[0]['label'] if sentiment == 'NEGATIVE': prioritized_tickets['negative'].append(ticket) elif sentiment == 'POSITIVE': prioritized_tickets['positive'].append(ticket) else: prioritized_tickets['neutral'].append(ticket) return prioritized_tickets # Using the default sentiment analysis model
default_sentiment_analyzer = pipeline('sentiment-analysis')
default_prioritized_tickets = triage_tickets(support_tickets, default_sentiment_analyzer) # Using a custom sentiment analysis model
custom_model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
custom_model = AutoModelForSequenceClassification.from_pretrained(custom_model_name)
custom_tokenizer = AutoTokenizer.from_pretrained(custom_model_name)
custom_sentiment_analyzer = pipeline('sentiment-analysis', model=custom_model, tokenizer=custom_tokenizer)
custom_prioritized_tickets = triage_tickets(support_tickets, custom_sentiment_analyzer) # Using the AutoModel for sentiment analysis
auto_model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
auto_model = AutoModelForSequenceClassification.from_pretrained(auto_model_name)
auto_tokenizer = AutoTokenizer.from_pretrained(auto_model_name)
auto_sentiment_analyzer = pipeline('sentiment-analysis', model=auto_model, tokenizer=auto_tokenizer)
auto_prioritized_tickets = triage_tickets(support_tickets, auto_sentiment_analyzer) # Displaying the prioritized tickets for each sentiment analyzer
for analyzer_name, prioritized_tickets in [('Default Model', default_prioritized_tickets), ('Custom Model', custom_prioritized_tickets), ('AutoModel', auto_prioritized_tickets)]: print("---------------------------------------------") print(f"nTickets Prioritized Using {analyzer_name}:") for sentiment, tickets in prioritized_tickets.items(): print(f"n{sentiment.capitalize()} Sentiment Tickets:") for idx, ticket in enumerate(tickets, start=1): print(f"{idx}. {ticket}") print()
Наданий код є прикладом практичної реалізації аналізу настроїв для сортування квитків у службу підтримки клієнтів за допомогою бібліотеки Transformers. Спочатку код встановлює канали аналізу настроїв із застосуванням різних моделей, щоб продемонструвати гнучкість бібліотеки. Аналізатор настроїв за замовчуванням спирається на попередньо навчену модель, надану бібліотекою. Крім того, було представлено дві альтернативні моделі: спеціальну модель аналізу настроїв («nlptown/bert-base-multilingual-uncased-sentiment») і AutoModel, що демонструє можливість налаштовувати та використовувати зовнішні моделі в екосистемі Transformers.
Згодом код визначає функцію triage_tickets, яка оцінює настрої кожного квитка підтримки за допомогою зазначеного аналізатора настроїв і класифікує їх на позитивні, негативні або нейтральні настрої. Потім код застосовує цю функцію до набору даних заявок підтримки за допомогою кожного аналізатора настрою, представляючи пріоритетні квитки на основі настрою для порівняння. Цей підхід дозволяє отримати всебічне розуміння варіацій моделі аналізу настроїв та їх впливу на сортування квитків, підкреслюючи універсальність і адаптивність бібліотеки Transformers у реальних програмах.
ВИХІД:
1. Модель за замовчуванням
- Квитки позитивного настрою: 3 позитивні квитки виражають задоволення продуктом або послугою.
- Квитки негативних настроїв: 4 квитки є негативними, що вказує на проблеми або розчарування.
- Квитки на нейтральний настрій: у списку 0 квитків.
2. Спеціальна модель
- Квитки позитивного настрою: у списку немає квитків позитивного настрою.
- Квитки негативного настрою: у списку немає квитків негативного настрою.
- Квитки на нейтральний настрій: усі квитки, включаючи квитки з позитивним і негативним настроєм із моделі за замовчуванням, перераховані тут.
3. Автомодель:
- Квитки позитивного настрою: у списку немає квитків позитивного настрою.
- Квитки негативного настрою: у списку немає квитків негативного настрою.
- Квитки на нейтральний настрій: усі квитки, включаючи квитки з позитивним і негативним настроєм із моделі за замовчуванням, перераховані тут.
Важливо зазначити, що аналіз настроїв іноді може бути суб’єктивним, і інтерпретація моделі може не повністю відповідати людській інтуїції. У реальному сценарії для більш точних результатів рекомендується точно налаштувати моделі аналізу настрою на даних, що стосуються конкретної області.
Показники ефективності для оцінки
Вимірювання ефективності оптимізації великої мовної моделі для проектів (LLMOP), зокрема в контексті сортування квитків на основі настрою, передбачає оцінку ключових показників, які відображають ефективність, ефективність і надійність реалізованої системи. Ось деякі відповідні показники ефективності:
1. Точність категоризації квитків
- Визначення: Вимірює відсоток звернень до служби підтримки, правильно класифікованих LLM.
- Важливість: Гарантує, що LLM точно розуміє та класифікує контекст кожного запиту в службу підтримки.
- формула:
2. Точність визначення пріоритету
- Визначення: Оцініть правильність рівнів пріоритету, призначених LLM на основі вмісту квитка.
- Важливість: Відображає здатність LLM виявляти термінові проблеми, сприяючи ефективному та своєчасному вирішенню запитів.
- формула:
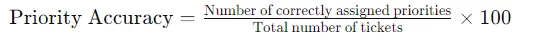
3. Скорочення часу відгуку
- Визначення: Вимірює середній час, заощаджений під час відповідей на запити в службу підтримки, порівняно з ручним процесом.
- Важливість: Вказує на підвищення ефективності, досягнуте завдяки автоматизації відповідей на типові запити за допомогою LLM.
- формула:
4. Послідовність у відповідях
- Визначення: Оцініть однаковість відповідей, створених LLM на загальні проблеми.
- Важливість: Гарантує, що стандартні відповіді, створені LLM, зберігають узгодженість у спілкуванні з клієнтами.
- формула:

5. Точність почуття
- Визначення: Вимірює правильність аналізу настроїв у класифікації настроїв клієнтів.
- Важливість: Оцініть здатність LLM точно інтерпретувати та визначати пріоритети заявок на основі емоцій клієнтів.
- формула:
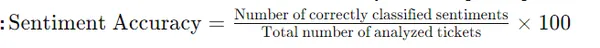
6. Підвищення рівня задоволеності клієнтів
- Визначення: Вимірює вплив сортування квитків, керованого LLM, на загальні показники задоволеності клієнтів.
- Важливість: Вимірює успіх LLMOPs у покращенні досвіду підтримки клієнтів.
- Formula :

7. Рівень помилкових позитивних результатів в аналізі настроїв
- Визначення: Обчислює відсоток квитків, неправильно класифікованих як такі, що містять негативні настрої.
- Важливість: Висвітлює потенційні області покращення точності аналізу настрою.
- формула:
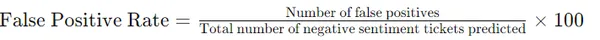
8. Показник помилкових негативних результатів в аналізі настроїв
- Визначення: Обчислює відсоток квитків, неправильно класифікованих як такі, що мають позитивні настрої.
- Важливість: Вказує на області, де аналіз настроїв може потребувати уточнення, щоб не пропустити критичні негативні настрої.
- формула:
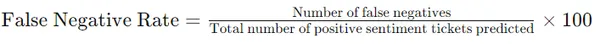
9. Стійкість до предметно-специфічних настроїв
- Визначення: Вимірює адаптивність LLM до нюансів настроїв, характерних для галузі чи домену.
- Критерії: Проведіть тести перевірки ефективності аналізу настрою, використовуючи дані, що стосуються домену.
10. Етичні міркування
- Визначення: Оцініть етичні наслідки та упередження, пов’язані з результатами аналізу настроїв.
- Критерії: Розгляньте справедливість і потенційні упередження, внесені LLM у класифікацію настроїв.
Етичні міркування
Змішування великих мовних моделей (LLM) разом із OpenAI GPT-3. Етичні міркування мають вирішальне значення для забезпечення відповідального та правдивого розгортання LLM в управлінні завданнями та підтримці клієнтів. Ось основні етичні міркування, про які слід пам’ятати:
1. Упередженість і справедливість:
Задача: LLM навчаються на великих наборах даних, що може ненавмисно закріпити упередження, наявні в навчальних записах.
Пом'якшення: Регулярно оцінюйте та перевіряйте результати моделі на наявність упереджень. Впроваджуйте методи разом із техніками усунення упереджень на певному етапі системи навчання.
2. Прозорість:
Задача: LLM, особливо складні, такі як GPT-3.5, часто вважаються «чорними ящиками», що ускладнює інтерпретацію того, як вони роблять конкретні висновки.
Пом'якшення: Покращення інтерпретабельності моделі шляхом забезпечення прозорості стратегій вибору. Запишіть особливості та проблеми, що впливають на результати моделі.
3. Інформована згода:
Задача: Користувачі, які взаємодіють із системами LLM, не знатимуть, які розширені мовні моделі діють або потенційні наслідки автоматизованих рішень.
Пом'якшення: Надайте пріоритет прозорості спілкування з користувачами. Інформуйте користувачів, коли LLM використовуються в процесах управління проектами, пояснюючи їх роль і потенційний вплив.
4. Конфіденційність даних:
Задача: LLMs, в основному впроваджені в службу підтримки клієнтів, вивчають величезні обсяги текстових даних, які можуть містити конфіденційні записи.
Пом'якшення: Застосуйте надійні підходи до анонімізації та шифрування інформації. Використовуйте лише дані, необхідні для навчання моделі, і уникайте непотрібного зберігання конфіденційної інформації
5. Підзвітність і відповідальність:
Задача: Визначення відповідальності за результати рішень, керованих LLM, може бути складним через спільний характер управління проектом.
Пом'якшення: Чітко визначте ролі та обов’язки в команді для нагляду за процесами, керованими LLM. Встановіть механізми підзвітності для моніторингу та вирішення потенційних проблем.
6. Громадське сприйняття:
Задача: Громадське сприйняття LLM може вплинути на довіру до автоматизованих систем, особливо якщо користувачі відчувають упередженість або брак прозорості.
Пом'якшення: Залучайтеся до прозорого спілкування з громадськістю щодо моральних міркувань. Завчасно вирішуйте проблеми та виявляйте відданість відповідальним практикам ШІ.
7. Добросовісне використання та уникнення шкоди:
Задача: Потенціал непередбачуваних результатів, неправильного використання або шкоди в основному на основі контролю за проектом LLM.
Пом'якшення: Встановіть інструкції щодо відповідального використання та потенційні перешкоди LLMs. Ставте пріоритет вибору, який уникає шкоди та відповідає моральним концепціям.
Урахування цих етичних міркувань має важливе значення для сприяння відповідальному та справедливому розгортанню LLM під час оптимізації проекту.
Висновок
Інтеграція великих мовних моделей у процеси сортування запитів служби підтримки клієнтів є значним кроком у напрямку підвищення ефективності та оперативності. Реалізація коду демонструє, як організації можуть застосовувати LLM для визначення пріоритетів і категоризації запитів у службу підтримки на основі настроїв клієнтів, підкреслюючи унікальну перспективу сортування запитів на основі настроїв. Оскільки організації прагнуть забезпечити винятковий досвід клієнтів, використання LLM для автоматичного сортування квитків стає цінним активом, гарантуючи оперативне вирішення критичних проблем і максимізуючи задоволеність клієнтів.
Ключові винесення
1. Великі мовні моделі (LLM) демонструють надзвичайну універсальність у вдосконаленні процесів управління проектами. Від автоматизації документації та генерації коду до підтримки прийняття рішень, LLMs є цінним активом для впорядкування різних аспектів оптимізації проекту.
2. Стаття представляє унікальні перспективи проекту, такі як визначення пріоритетів завдань на основі настрою та генерація сюжетної лінії на основі ШІ. Ці точки зору показують, що творче застосування LLMs може призвести до інноваційних рішень від підтримки клієнтів до інтерактивних медіа.
3. стаття дає можливість читачам застосовувати LLMs у своїх проектах, надаючи практичну реалізацію коду для унікальних проектів. Практичні приклади усувають розрив між теорією та застосуванням, сприяючи глибшому розумінню LLMOPs.
ЧАСТІ ЗАПИТАННЯ
A. У цій статті розглядається застосування великих мовних моделей (LLM) для оптимізації проектів у різних сферах, демонструючи їх можливості для підвищення ефективності та процесів прийняття рішень.
A. LLMs використовуються для автоматизації планування проекту, створення документації, оптимізації коду та підтримки прийняття рішень, зрештою оптимізуючи процеси управління проектами.
A. Стаття представляє унікальну перспективу проекту сортування запитів на основі настроїв, демонструючи, як LLM можна застосовувати для визначення пріоритетів і категоризації заявок у службу підтримки на основі настроїв клієнтів.
А. Аналіз настроїв відіграє вирішальну роль у розумінні відгуків користувачів, динаміки команди та настроїв зацікавлених сторін, сприяючи більш обґрунтованому прийняттю рішень під час управління проектом.
A. Стаття містить практичні реалізації коду для унікальних перспектив проекту, пропонуючи читачам практичний досвід використання LLM для таких завдань, як коментування коду, сортування квитків і генерація динамічної сюжетної лінії.
посилання
- https://arxiv.org/abs/2005.14165
- https://huggingface.co/transformers/
Медіафайли, показані в цій статті, не належать Analytics Vidhya та використовуються на розсуд Автора.
споріднений
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.analyticsvidhya.com/blog/2023/11/enhancing-customer-support-efficiency-through-automated-ticket-triage/
- : має
- :є
- : ні
- :де
- $UP
- 10
- 11
- 12
- 20
- 2018
- 2020
- a
- здатність
- МЕНЮ
- прискорюється
- підзвітність
- точність
- точний
- точно
- досягнутий
- Діяти
- пристосовувати
- адаптивність
- пристосування
- Додатково
- адресований
- адресація
- просунутий
- зачіпає
- агенти
- AI
- мета
- AL
- вирівнювати
- ВСІ
- Дозволити
- дозволяє
- по
- Також
- альтернатива
- am
- an
- аналіз
- аналітика
- Аналітика Vidhya
- аналізувати
- Аналізуючи
- та
- додаток
- застосування
- прикладної
- застосовується
- Застосовувати
- Застосування
- підхід
- підходи
- відповідний
- ЕСТЬ
- області
- стаття
- AS
- запитав
- аспекти
- оцінити
- оцінює
- Оцінювання
- активи
- Активи
- призначений
- асоційований
- At
- аудит
- автоматизувати
- Автоматизований
- автоматично
- автоматизація
- Автоматизація
- середній
- уникнути
- уникає
- заснований
- BE
- стає
- було
- за
- КРАЩЕ
- передового досвіду
- між
- зміщення
- упередження
- вузькі місця
- BRIDGE
- коричневий
- Створюємо
- але
- by
- обчислює
- CAN
- можливості
- можливості
- категоризація
- виклик
- проблеми
- вибір
- вибір
- ясно
- очевидно
- код
- спільний
- Коментуючи
- коментарі
- зобов'язання
- загальний
- Комунікація
- порівняний
- порівняння
- комплекс
- складний
- компонент
- всеосяжний
- поняття
- Турбота
- Висновки
- Проводити
- спутаний
- згода
- Наслідки
- міркування
- вважається
- послідовно
- зміст
- контекст
- контекстуальний
- сприяти
- внесок
- контроль
- правильно
- може
- створення
- Творчо
- Критерії
- критичний
- вирішальне значення
- виготовлений на замовлення
- клієнт
- Задоволеність клієнтів
- підтримка клієнтів
- Клієнти
- налаштувати
- дані
- конфіденційність даних
- набори даних
- угода
- рішення
- Прийняття рішень
- рішення
- глибокий
- глибше
- дефолт
- визначати
- Визначає
- затримки
- демонструвати
- продемонстрований
- демонстрація
- розгортання
- деталі
- різний
- важкий
- трудність
- керівництво
- розсуд
- показ
- Різне
- do
- документація
- домен
- домени
- керований
- два
- динамічний
- динамічно
- динаміка
- E&T
- кожен
- екосистема
- Ефективний
- ефективність
- ефективність
- ефективний
- зусилля
- ще
- емоційний
- емоції
- підкреслюючи
- працевлаштований
- наймаючи
- повноваження
- дозволяє
- займатися
- залучення
- підвищувати
- підвищення
- забезпечувати
- гарантує
- забезпечення
- особливо
- істотний
- встановити
- Ефір (ETH)
- етичний
- оцінювати
- оцінки
- досліджувати
- Приклади
- винятковий
- ілюструє
- проявляти
- існуючий
- досвід
- Досліди
- пояснюючи
- Розвіданий
- досліджує
- експрес
- виражений
- висловлюючи
- зовнішній
- надзвичайно
- Face
- ярмарок
- справедливість
- false
- швидкий темп
- риси
- зворотний зв'язок
- почуття
- знайти
- Гнучкість
- Сфокусувати
- стежити
- для
- виховання
- від
- розчарування
- розчарування
- Розчарування
- функція
- фундаментальний
- прибуток
- розрив
- породжувати
- генерується
- породжує
- покоління
- генеративний
- великий
- гарантії
- керівні вказівки
- практичний
- шкодити
- Мати
- має
- корисний
- тут
- Високий
- на вищому рівні
- виділивши
- тримати
- Як
- HTTPS
- величезний
- людина
- i
- ідентифікувати
- ідентифікує
- IDX
- if
- ілюструвати
- Impact
- здійснювати
- реалізація
- реалізації
- реалізовані
- наслідки
- імпорт
- важливо
- імпорт
- поліпшення
- поліпшення
- in
- ненавмисно
- включати
- У тому числі
- Вхідний
- включати
- вказувати
- вказує
- вказуючи
- осіб
- промисловість
- неефективність
- повідомити
- інформація
- повідомив
- спочатку
- інноваційний
- вхід
- розуміння
- інструкції
- інтегрований
- Інтеграція
- взаємодіючих
- Взаємодії
- інтерактивний
- інтерактивні ЗМІ
- інтерпретація
- втручання
- в
- введені
- Вводить
- інтуїція
- включає в себе
- питання
- питання
- IT
- зберігання
- ключ
- ключові слова
- Знати
- етикетка
- відсутність
- мова
- великий
- останній
- вести
- учнів
- вивчення
- рівні
- використання
- libraries
- бібліотека
- Життєвий цикл
- як
- Перераховані
- любов
- підтримувати
- Робить
- управління
- керівництво
- максимізація
- Може..
- заходи
- механізми
- Медіа
- Метрика
- mind
- мінімальний
- відсутній
- зловживання
- модель
- Моделі
- моніторинг
- моральний
- більше
- Більше того
- багато
- my
- NARRATIVE
- Природний
- Природна мова
- природа
- необхідно
- Необхідність
- негативний
- Нейтральний
- Нові
- Нові можливості
- немає
- увагу
- нюанси
- перешкодами
- of
- пропонує
- часто
- on
- ті,
- тільки
- OpenAI
- оптимізація
- оптимізований
- or
- організації
- Результати
- виходи
- загальний
- спостереження
- яка перебуває у власності
- парадигма
- Першорядний
- частина
- особливо
- моделі
- відсоток
- сприйняття
- відмінно
- продуктивність
- Персоналізовані
- перспектива
- перспективи
- фаза
- трубопровід
- основний
- планування
- плани
- plato
- Інформація про дані Платона
- PlatoData
- Play
- відіграє
- позитивний
- це можливо
- потенціал
- Практичний
- практики
- Передбачуваний
- представити
- представлений
- пресування
- ціни без прихованих комісій
- в першу чергу
- пріоритетів
- Пріоритетність
- пріоритетні
- розставляє пріоритети
- пріоритет
- недоторканність приватного життя
- проблеми
- процес
- процеси
- обробка
- Product
- проект
- управління проектом
- проектів
- сприяти
- пропонувати
- забезпечувати
- за умови
- забезпечує
- забезпечення
- доблесть
- громадськість
- опублікований
- запити
- Швидко
- швидко
- ставка
- досягати
- читачі
- Реальний світ
- царство
- рекомендований
- запис
- облік
- зниження
- відображати
- що відображають
- Відображає
- регулярно
- доречний
- надійність
- чудовий
- представляє
- Вимога
- Вимагається
- дослідження
- дозвіл
- вирішене
- відповідаючи
- відповідь
- час відгуку
- відповіді
- обов'язки
- відповідальність
- відповідальний
- результати
- повертати
- ризики
- міцний
- стійкість
- Роль
- ролі
- s
- задоволення
- зберігаються
- економія
- сценарій
- сценарії
- наука
- безліч
- безшовні
- чутливий
- настрій
- почуття
- обслуговування
- набори
- установка
- зсув
- Показувати
- демонстрації
- демонстрація
- показаний
- значний
- рішення
- Рішення
- деякі
- іноді
- конкретний
- специфікації
- зазначений
- площа
- Стажування
- зацікавлені сторони
- standard
- Крок
- стратегії
- обтічний
- упорядкування
- прагнути
- успіх
- такі
- підтримка
- системи підтримки
- Підтримуючий
- система
- Systems
- Завдання
- завдання
- команда
- команди
- методи
- Тести
- текст
- текстуальний
- дякувати
- Що
- Команда
- їх
- Їх
- потім
- теорія
- тим самим
- Ці
- вони
- це
- через
- квиток
- квитки
- час
- трудомісткий
- своєчасно
- times
- до
- TONE
- до
- навчений
- Навчання
- Трансформатори
- прозорість
- прозорий
- сортування
- Довіряйте
- два
- Зрештою
- розуміти
- розуміння
- розумієш
- створеного
- відповідний сучасним вимогам
- терміновість
- терміново
- використання
- використовуваний
- користувач
- користувачі
- використання
- використовувати
- використовувати
- використовує
- перевірка достовірності
- Цінний
- варіації
- різний
- Універсальність
- обсяг
- Обсяги
- було
- we
- webp
- Що
- Що таке
- коли
- Чи
- який
- в той час як
- чому
- волі
- з
- в
- світ
- ви
- вашу
- зефірнет