Вступ
Субтитри до зображень — це ще одна цікава інновація в області штучного інтелекту та його внесок у розвиток комп’ютерного зору. Новий інструмент Salesforce, BLIP, є великим стрибком. Ця модель штучного інтелекту із субтитрами до зображень забезпечує велику кількість інтерпретацій у своєму робочому процесі. Bootstrapping Language-image Pretraining (BLIP) — це технологія, яка генерує підписи із зображень із високим рівнем ефективності.

Мета навчання
- Отримайте уявлення про модель Salesforce BLIP Image Captioning.
- Вивчіть стратегії декодування та текстові підказки використання цього інструменту.
- Отримайте уявлення про особливості та функції субтитрів до зображень BLIP.
- Дізнайтеся про застосування цієї моделі в реальному житті та про те, як виконувати висновок.
Ця стаття була опублікована як частина Blogathon Data Science.
Зміст
Розуміння субтитрів зображень BLIP
Модель субтитрів до зображень BLIP використовує виняткове значення техніка глибокого навчання інтерпретувати зображення в описовий підпис. Він також без особливих зусиль генерує зображення в текст із високою точністю за допомогою обробки природної мови та комп’ютерного зору.
Ви можете дослідити цю модель з кількома ключовими функціями. Використання кількох текстових підказок дає змогу отримати найбільш описову частину зображення. Ви можете легко знайти ці підказки, коли завантажуєте зображення в інструмент створення субтитрів Salesforce BLIP на обличчі, яке обіймається. Їх функціональні можливості також великі та ефективні.
За допомогою цієї моделі ви можете ставити запитання про деталі кольорів або форми завантаженого зображення. Вони також використовують функції пошуку пучка та ядра, щоб надати описовий підпис до зображення.
Основні характеристики та функції BLIP Image Captioning
Ця модель має високу точність у розпізнаванні об’єктів і демонструє реальну обробку під час надання підписів до зображень. За допомогою цього інструменту можна дослідити кілька функцій. Проте три основні функції визначають можливості інструмента створення субтитрів до зображень BLIP. Ми коротко обговоримо їх тут;
Контекстне розуміння BLIP
Контекст зображення – це важлива деталь, яка допомагає в інтерпретації та підписах. Наприклад, зображення кота та мишки не мало б чіткого контексту, якби між ними не існувало зв’язку. Salesforce BLIP може розуміти зв’язок між об’єктами та використовувати просторове розміщення для створення підписів. Ця ключова функція може допомогти створити людський підпис, а не просто загальний.
Отже, ваше зображення отримує підпис із чітким контекстом, наприклад «кіт ганяється за мишкою під столом». Це створює кращий контекст, ніж підпис із написом «кіт і мишка».
Підтримує кілька мов
Salesforce прагнення задовольнити глобальну аудиторію спонукало до впровадження кількох мов для цієї моделі. Отже, використання цієї моделі як маркетингового інструменту може принести користь міжнародним брендам і компаніям.
Обробка в реальному часі
Той факт, що BLIP дозволяє обробляти зображення в реальному часі, робить його великою перевагою. Використання субтитрів до зображень BLIP як маркетингового інструменту може отримати вигоду від цієї функції. Висвітлення подій у прямому ефірі, підтримка в чаті, залучення в соціальні мережі та інші маркетингові стратегії можуть бути реалізовані.
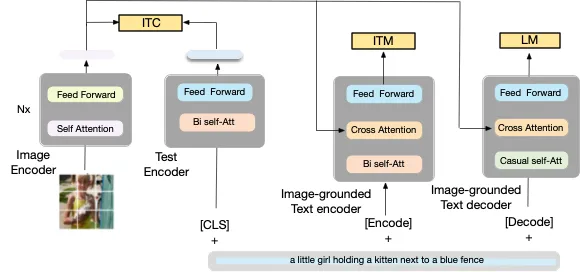
Архітектура моделі BLIP Image Captioning
Субтитри до зображень BLIP використовує структуру попереднього навчання Vision-Language (VLP), яка об’єднує завдання розуміння та створення. Він ефективно використовує зашумлені веб-дані через a механізм завантаження, де субтитри генерують синтетичні субтитри, відфільтровані за допомогою процесу видалення шуму.
Цей підхід дозволяє досягти найсучасніших результатів у різних завданнях, пов’язаних із мовою зору, як-от пошук зображень і тексту, підписи до зображень і візуальні відповіді на запитання (VQA). Архітектура BLIP забезпечує гнучке перенесення між завданнями розуміння мови бачення та створення.
Примітно, що він демонструє сильну здатність до узагальнення в нульових перенесеннях до завдань відеомови. Модель попередньо навчена на наборі даних COCO, який містить понад 120,000 XNUMX зображень і підписів. Інноваційний дизайн BLIP і використання веб-даних виділяють його як піонерське рішення в уніфікованому розумінні та створенні мови візуалізації.
BLIP використовує Vision Transformer ViT. Цей механізм кодує вхідне зображення, розділяючи його на фрагменти з додатковим маркером, що представляє глобальну функцію зображення. Цей процес використовує менше обчислювальних витрат, що робить його простішою моделлю.
Ця модель використовує унікальний метод навчання/попереднього навчання для створення завдань і розуміння функцій. BLIP використовує мультимодальну суміш кодера та декодера для передачі своїх основних функцій: кодувальник тексту, кодер основного тексту зображення та декодер.
- Кодувальник тексту: Цей кодер використовує втрату контрастності зображення й тексту (ITC), щоб вирівняти текст і зображення як пару та зробити їх схожими представленнями. Ця концепція допомагає унімодальним кодувальникам краще розуміти семантичне значення зображень і текстів.
- Кодувальник тексту на основі зображення: Цей кодер використовує втрату відповідності зображення та землі (IMT), щоб знайти узгодження між зором і мовою в цій моделі. Він діє як фільтр для пошуку відповідних позитивних пар і невідповідних негативних пар.
- Декодер тексту на основі зображення: Декодер використовує втрату мови моделювання (LM). Це спрямовано на створення текстових підписів і описів зображень. Саме LM активує цей декодер для прогнозування точних описів.
Ось графічне представлення того, як це працює;

Запуск цієї моделі (GPU і CPU)
Ця модель працює гладко, використовуючи кілька циклів виконання. Через різні середовища розробки ми проводимо висновки щодо GPU та CPU, щоб побачити, як ця модель генерує підписи до зображень.
Давайте розглянемо запуск Salesforce BLIP Image captioning на GPU (з повною точністю)
Імпортуйте модуль PIL
Перший рядок дозволяє HTTP-запити в Python. Потім PIL допомагає імпортувати модуль зображення з бібліотеки, дозволяючи відкривати, змінювати та зберігати зображення в різних форматах.
Наступний крок - завантаження процесора з Підписи до зображень Salesforce/Blip. Тут починається ініціалізація процесора. Це здійснюється шляхом завантаження попередньо навченої конфігурації процесора та токенізації, пов’язаної з цією моделлю.
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-large")Завантаження/завантаження зображення
Змінна 'img_url' вказує зображення, яке буде завантажено після використання зображення PIL. У функції відкриття ви можете переглянути необроблене зображення URL-адреси після його завантаження.
img_url = 'https://www.shutterstock.com/image-photo/young-happy-schoolboy-using-computer-600nw-1075168769.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')Коли ви введете новий кодовий блок і введете «необроблене зображення», ви зможете отримати вигляд зображення, як показано нижче:
Підписи до зображень. Частина 1
Ця модель підписує зображення двома способами: умовним і безумовним підписом зображення. Для першого вхідними даними є ваше необроблене зображення, текст (який надсилає запит на підпис до зображення на основі тексту), а потім функція 'generate' видає оброблені вхідні дані.
З іншого боку, безумовні підписи до зображень можуть надавати підписи без введення тексту.
# conditional image captioning
text = "a photography of"
inputs = processor(raw_image, text, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
# unconditional image captioning
inputs = processor(raw_image, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))Давайте розглянемо запуск субтитрів зображень BLIP на графічному процесорі (з половинною точністю)
Імпортування необхідних бібліотек із Hugging Face Transformer і обробки моделі та конфігурації процесора
Цей крок імпортує необхідні бібліотеки та запити Python. Інші етапи включають модель генерації зображення BLIP і процесор для завантаження попередньо навченої конфігурації та токенізації.
import torch
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-large", torch_dtype=torch.float16).to("cuda")URL зображення
Якщо у вас є URL-адреса зображення, PIL може виконати цю роботу звідси, оскільки відкрити зображення буде легко.
img_url = 'https://www.shutterstock.com/image-photo/young-happy-schoolboy-using-computer-600nw-1075168769.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')Підписи до зображень. Частина 2
Тут ми знову говоримо про умовні та безумовні методи підписів до зображень, і ви можете написати щось більше, ніж «фотографія», щоб отримати іншу інформацію про зображення. Але в цьому випадку нам потрібен лише підпис;
# unconditional image captioning
text = "a photography of"
inputs = processor(raw_image, text, return_tensors="pt").to("cuda", torch.float16)
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
# unconditional image captioning
inputs = processor(raw_image, return_tensors="pt").to("cuda", torch.float16)
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
#import csvДавайте розглянемо запуск субтитрів зображень BLIP під час виконання CPU.
Імпорт бібліотек
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGenerationЗавантаження попередньо навченої конфігурації
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-large")Введення зображення
img_url = 'https://www.shutterstock.com/image-photo/young-happy-schoolboy-using-computer-600nw-1075168769.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')Підписи до зображень
# conditional image captioning
text = "a photography of"
inputs = processor(raw_image, text, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
# unconditional image captioning
inputs = processor(raw_image, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))Застосування BLIP Image Captioning
Здатність моделі BLIP Image captioning генерувати підписи із зображень є великою цінністю для багатьох галузей, особливо для цифрового маркетингу. Давайте розглянемо кілька реальних застосувань моделі субтитрів зображень BLIP.
- Маркетинг соціальних медіа: Цей інструмент може допомогти маркетологам соціальних медіа створити підписи до зображень, підвищити доступність у пошукових системах (SEO) і підвищити залучення.
- Підтримка клієнтів: Взаємодія з користувачем може бути представлена віртуально, і ця модель може допомогти як система підтримки для отримання швидших результатів для користувачів.
- Генерації титрів від авторів: Оскільки штучний інтелект широко використовується для створення контенту, блогери та інші творці знайдуть цей режим ефективним інструментом для створення контенту, економлячи час.
Висновок
Субтитри до зображень сьогодні стали цінною розробкою ШІ. Ця модель багато в чому допомагає цьому розвитку. Використовуючи вдосконалені методи обробки природної мови, це налаштування надає розробникам потужні інструменти для створення точних підписів із зображень.
Ключові винесення
Ось кілька важливих моментів із моделі субтитрів зображень BLIP;
- Ідеальні інтерпретації зображень:
- Розуміння контексту зображення:
- Програми в реальному житті:
ЧАСТІ ЗАПИТАННЯ
Ans. Модель субтитрів зображення BLIP не лише точний при виявленні об’єктів. Його розуміння просторового розташування забезпечує перевагу в контексті під час підписання зображення.
Відповідь Ця модель задовольняє глобальну аудиторію, оскільки підтримує кілька мов. BLIP Підписи до зображень також унікальні, оскільки вони можуть обробляти підписи в режимі реального часу.
Відповідь Для умовних підписів до зображень BLIP надає підписи до зображень за допомогою текстових підказок. З іншого боку, ця модель може виконувати безумовне створення титрів лише на основі зображення.
Відповідь BLIP використовує структуру Vision-Language Pre-training (VLP), використовуючи механізм завантаження для ефективного використання зашумлених веб-даних. Він досягає найсучасніших результатів у різних мовних завданнях.
Медіафайли, показані в цій статті, не належать Analytics Vidhya та використовуються на розсуд Автора.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.analyticsvidhya.com/blog/2024/03/salesforce-blip-revolutionizing-image-captioning/
- : має
- :є
- : ні
- :де
- 000
- 10
- 12
- 120
- 7
- 8
- a
- здатність
- Здатний
- МЕНЮ
- доступність
- точність
- точний
- Досягає
- через
- акти
- Додатковий
- просунутий
- після
- знову
- AI
- Цілі
- вирівнювати
- вирівнювання
- Дозволити
- дозволяє
- тільки
- Також
- an
- аналітика
- Аналітика Vidhya
- та
- Інший
- відповідь
- крім
- застосування
- підхід
- архітектура
- ЕСТЬ
- розташування
- заходи
- стаття
- штучний
- штучний інтелект
- AS
- запитати
- запитав
- активи
- асоційований
- At
- аудиторія
- заснований
- BE
- Промінь
- оскільки
- ставати
- було
- за
- буття
- нижче
- користь
- Краще
- між
- Блокувати
- блогатон
- підвищення
- завантаження
- бренди
- коротко
- підприємства
- але
- by
- CAN
- можливості
- Підписи
- carried
- нести
- випадок
- КПП
- догоджати
- заміна
- чат
- ясно
- кокос
- код
- обчислювальна
- комп'ютер
- Комп'ютерне бачення
- концепція
- умовний
- конфігурація
- містить
- зміст
- контекст
- контекстуальний
- внесок
- витрати
- охоплення
- центральний процесор
- створювати
- Творці
- дані
- набір даних
- угода
- Декодування
- визначати
- демонструє
- дизайн
- деталь
- деталі
- виявлення
- розробників
- розробка
- відрізняються
- різний
- цифровий
- цифровий маркетинг
- розсуд
- обговорювати
- поділ
- do
- робить
- Завантажений
- два
- легше
- легко
- легко
- край
- Ефективний
- фактично
- ефективність
- легко
- працює
- дозволяє
- заохочувати
- зачеплення
- Двигуни
- Що натомість? Створіть віртуальну версію себе у
- середовищах
- особливо
- Event
- приклад
- винятковий
- захоплюючий
- Виставкові
- існували
- досвід
- дослідити
- Face
- факт
- швидше
- особливість
- риси
- кілька
- фільтрувати
- знайти
- виявлення
- Перший
- відповідати
- гнучкий
- для
- Формати
- Колишній
- Рамки
- від
- Повний
- функція
- функціональні можливості
- функціональність
- породжувати
- генерує
- породжує
- покоління
- покоління
- отримати
- отримує
- GIF
- дає
- дає
- Глобальний
- глобальна аудиторія
- GPU
- Графічні процесори
- великий
- Земля
- рука
- обробляти
- Мати
- допомога
- допомагає
- тут
- Високий
- Як
- How To
- Однак
- HTTP
- HTTPS
- if
- зображення
- генерація зображень
- зображень
- реалізація
- реалізовані
- імпорт
- імпорт
- in
- включати
- Augmenter
- вказує
- промисловості
- інформація
- інновація
- інноваційний
- вхід
- витрати
- розуміння
- Інтеграція
- Інтелект
- Міжнародне покриття
- інтерпретація
- в
- IT
- ЙОГО
- робота
- JPG
- просто
- ключ
- мова
- мови
- Стрибок
- вивчення
- менше
- рівень
- Важіль
- важелі
- використання
- libraries
- бібліотека
- як
- Лінія
- жити
- погрузка
- подивитися
- від
- головний
- зробити
- РОБОТИ
- Робить
- багато
- маркетологи
- Маркетинг
- Маркетингові стратегії
- матч
- узгодження
- макс-ширина
- сенс
- механізм
- Медіа
- середа
- метод
- методика
- суміш
- режим
- модель
- моделювання
- Моделі
- Модулі
- більше
- найбільш
- миша
- множинний
- Природний
- Природна мова
- Обробка природних мов
- необхідно
- негативний
- Нові
- наступний
- немає
- шум
- Помітний
- об'єкти
- of
- on
- ONE
- тільки
- відкрити
- відкриття
- or
- Інше
- з
- над
- яка перебуває у власності
- пара
- пар
- частина
- Патчі
- малюнок
- картина
- Піонерський
- plato
- Інформація про дані Платона
- PlatoData
- точок
- позитивний
- потужний
- потужні інструменти
- Точність
- передбачати
- процес
- оброблена
- обробка
- процесор
- підказок
- забезпечувати
- забезпечує
- забезпечення
- опублікований
- Python
- пошук
- питання
- питань
- Сировина
- реального часу
- визнаючи
- відносини
- видалення
- подання
- уявлення
- представлений
- представляє
- запросити
- запитів
- результати
- пошук
- революційні
- RGB
- прогін
- біг
- пробіжки
- час виконання
- Salesforce
- задовольняє
- економія
- наука
- Пошук
- Пошукові системи
- побачити
- смисловий
- посилає
- пошукова оптимізація
- комплект
- установка
- кілька
- Форма
- показаний
- shutterstock
- аналогічний
- плавно
- So
- соціальна
- соціальні медіа
- рішення
- деякі
- що в сім'ї щось
- просторовий
- починається
- впроваджений
- Крок
- заходи
- стратегії
- сильний
- такі
- підтримка
- Опори
- синтетичний
- система
- таблиця
- балаканина
- завдання
- методи
- Технологія
- текст
- ніж
- Що
- Команда
- їх
- Їх
- потім
- Там.
- Ці
- вони
- це
- три
- через
- час
- до
- сьогодні
- знак
- Токенізація
- інструмент
- інструменти
- факел
- традиційний
- переклади
- трансформатор
- Трансформатори
- передавати
- два
- тип
- безумовно
- при
- розуміти
- розуміння
- єдиний
- створеного
- неперевершений
- завантажено
- URL
- використання
- використовуваний
- користувач
- User Experience
- користувачі
- використовує
- використання
- утилізація
- використовує
- Цінний
- значення
- змінна
- різний
- різний
- вид
- фактично
- бачення
- візуальний
- хотіти
- було
- способи
- we
- Web
- webp
- Що
- Що таке
- коли
- який
- в той час як
- широко
- волі
- з
- без
- робочий
- працює
- б
- запис
- ви
- вашу
- зефірнет





![Що таке функція SUBSTRING у SQL? [Пояснено на прикладах]](https://platoaistream.net/wp-content/uploads/2023/07/what-is-substring-function-in-sql-explained-with-examples-360x189.webp)




