کلاؤڈ کمپیوٹنگ کے استعمال کے ساتھ، بڑے ڈیٹا اور مشین لرننگ (ML) ٹولز جیسے ایمیزون ایتینا or ایمیزون سیج میکر تخلیق اور دیکھ بھال میں زیادہ محنت کیے بغیر کسی کے لیے دستیاب اور قابل استعمال بن گئے ہیں۔ صنعتی کمپنیاں اپنے پورے پورٹ فولیو میں وسائل کی کارکردگی کو بڑھانے کے لیے ڈیٹا اینالیٹکس اور ڈیٹا پر مبنی فیصلہ سازی کو تیزی سے دیکھتی ہیں، آپریشن سے لے کر پیشین گوئی کی دیکھ بھال یا منصوبہ بندی تک۔
آئی ٹی میں تبدیلی کی رفتار کی وجہ سے، روایتی صنعتوں میں صارفین کو مہارت کی ایک مخمصے کا سامنا ہے۔ ایک طرف، تجزیہ کاروں اور ڈومین کے ماہرین کو زیربحث ڈیٹا اور اس کی تشریح کے بارے میں بہت گہرا علم ہے، پھر بھی اکثر ڈیٹا سائنس ٹولنگ اور Python جیسی اعلیٰ سطحی پروگرامنگ زبانوں کی نمائش کا فقدان ہے۔ دوسری طرف، ڈیٹا سائنس کے ماہرین کے پاس اکثر مشین کے ڈیٹا کے مواد کی تشریح کرنے اور متعلقہ چیزوں کے لیے اسے فلٹر کرنے کے تجربے کی کمی ہوتی ہے۔ یہ مخمصہ ایسے موثر ماڈلز کی تخلیق میں رکاوٹ ہے جو کاروبار سے متعلقہ بصیرت پیدا کرنے کے لیے ڈیٹا کا استعمال کرتے ہیں۔
ایمیزون سیج میکر کینوس ڈومین کے ماہرین کو طاقتور تجزیات اور ایم ایل ماڈلز، جیسے پیشن گوئی، درجہ بندی، یا ریگریشن ماڈلز بنانے کے لیے بغیر کوڈ انٹرفیس فراہم کرکے اس مخمصے کو دور کرتا ہے۔ یہ آپ کو تخلیق کے بعد ML اور MLOps ماہرین کے ساتھ ان ماڈلز کو تعینات اور اشتراک کرنے کی بھی اجازت دیتا ہے۔
اس پوسٹ میں، ہم آپ کو دکھاتے ہیں کہ SageMaker Canvas کو اپنے ڈیٹا میں درست خصوصیات کو درست کرنے اور منتخب کرنے کے لیے کیسے استعمال کیا جائے، اور پھر ماڈل ٹیوننگ کے لیے SageMaker Canvas کی بغیر کوڈ کی فعالیت کا استعمال کرتے ہوئے، بے ضابطگی کا پتہ لگانے کے لیے ایک پیشین گوئی ماڈل کو تربیت دیں۔
مینوفیکچرنگ انڈسٹری کے لیے بے ضابطگی کا پتہ لگانا
لکھنے کے وقت، سیج میکر کینوس عام کاروباری استعمال کے معاملات پر توجہ مرکوز کرتا ہے، جیسے پیشن گوئی، رجعت، اور درجہ بندی۔ اس پوسٹ کے لیے، ہم یہ ظاہر کرتے ہیں کہ یہ صلاحیتیں پیچیدہ غیر معمولی ڈیٹا پوائنٹس کا پتہ لگانے میں کس طرح مدد کر سکتی ہیں۔ یہ استعمال کیس متعلقہ ہے، مثال کے طور پر، صنعتی مشینوں کی خرابیوں یا غیر معمولی کاموں کی نشاندہی کرنے کے لیے۔
انڈسٹری ڈومین میں بے ضابطگی کا پتہ لگانا اہم ہے، کیونکہ مشینیں (ٹرین سے لے کر ٹربائن تک) عام طور پر بہت قابل اعتماد ہوتی ہیں، ناکامیوں کے درمیان سالوں پر محیط ہوتا ہے۔ ان مشینوں سے زیادہ تر ڈیٹا، جیسا کہ درجہ حرارت سنور ریڈنگ یا اسٹیٹس میسجز، معمول کے عمل کو بیان کرتا ہے اور فیصلہ سازی کے لیے محدود قدر رکھتا ہے۔ انجینئرز کسی خرابی کی بنیادی وجوہات کی تحقیقات کرتے وقت یا مستقبل کی خرابیوں کے لیے انتباہی اشارے کے طور پر غیر معمولی ڈیٹا تلاش کرتے ہیں، اور کارکردگی کے منتظمین ممکنہ بہتری کی نشاندہی کرنے کے لیے غیر معمولی ڈیٹا کی جانچ کرتے ہیں۔ لہذا، ڈیٹا پر مبنی فیصلہ سازی کی طرف بڑھنے کا عام پہلا قدم اس متعلقہ (غیر معمولی) ڈیٹا کو تلاش کرنے پر انحصار کرتا ہے۔
اس پوسٹ میں، ہم ڈیٹا میں صحیح خصوصیات کو درست کرنے اور منتخب کرنے کے لیے SageMaker Canvas کا استعمال کرتے ہیں، اور پھر ماڈل ٹیوننگ کے لیے SageMaker Canvas no-code فعالیت کا استعمال کرتے ہوئے، بے ضابطگی کا پتہ لگانے کے لیے ایک پیشین گوئی ماڈل کو تربیت دیتے ہیں۔ پھر ہم ماڈل کو سیج میکر اینڈ پوائنٹ کے طور پر تعینات کرتے ہیں۔
حل جائزہ
ہمارے بے ضابطگی کا پتہ لگانے کے استعمال کے معاملے کے لیے، ہم ایک پیشین گوئی ماڈل کو تربیت دیتے ہیں کہ وہ مشین کے معمول کے کام کے لیے خصوصیت کی پیش گوئی کرے، جیسے کہ کار میں اشارہ کردہ موٹر کا درجہ حرارت، اثر کرنے والی خصوصیات سے، جیسے کہ رفتار اور کار میں لگائی گئی حالیہ ٹارک۔ . پیمائش کے نئے نمونے پر بے ضابطگی کا پتہ لگانے کے لیے، ہم خصوصیت کے لیے ماڈل کی پیشین گوئیوں کا موازنہ فراہم کردہ مشاہدات سے کرتے ہیں۔
کار موٹر کی مثال کے طور پر، ایک ڈومین ماہر موٹر کے عام درجہ حرارت، حالیہ موٹر ٹارک، محیطی درجہ حرارت، اور دیگر ممکنہ اثر انداز ہونے والے عوامل کی پیمائش حاصل کرتا ہے۔ یہ آپ کو دیگر خصوصیات سے درجہ حرارت کی پیشن گوئی کرنے کے لیے ماڈل کو تربیت دینے کی اجازت دیتے ہیں۔ پھر ہم باقاعدگی سے موٹر کے درجہ حرارت کا اندازہ لگانے کے لیے ماڈل کا استعمال کر سکتے ہیں۔ جب اس ڈیٹا کے لیے پیشن گوئی شدہ درجہ حرارت اس ڈیٹا میں مشاہدہ کیے گئے درجہ حرارت کی طرح ہوتا ہے، تو موٹر عام طور پر کام کر رہی ہوتی ہے۔ تضاد کسی بے ضابطگی کی طرف اشارہ کرے گا، جیسے کولنگ سسٹم کی خرابی یا موٹر میں خرابی۔
مندرجہ ذیل خاکہ حل کے فن تعمیر کی وضاحت کرتا ہے۔
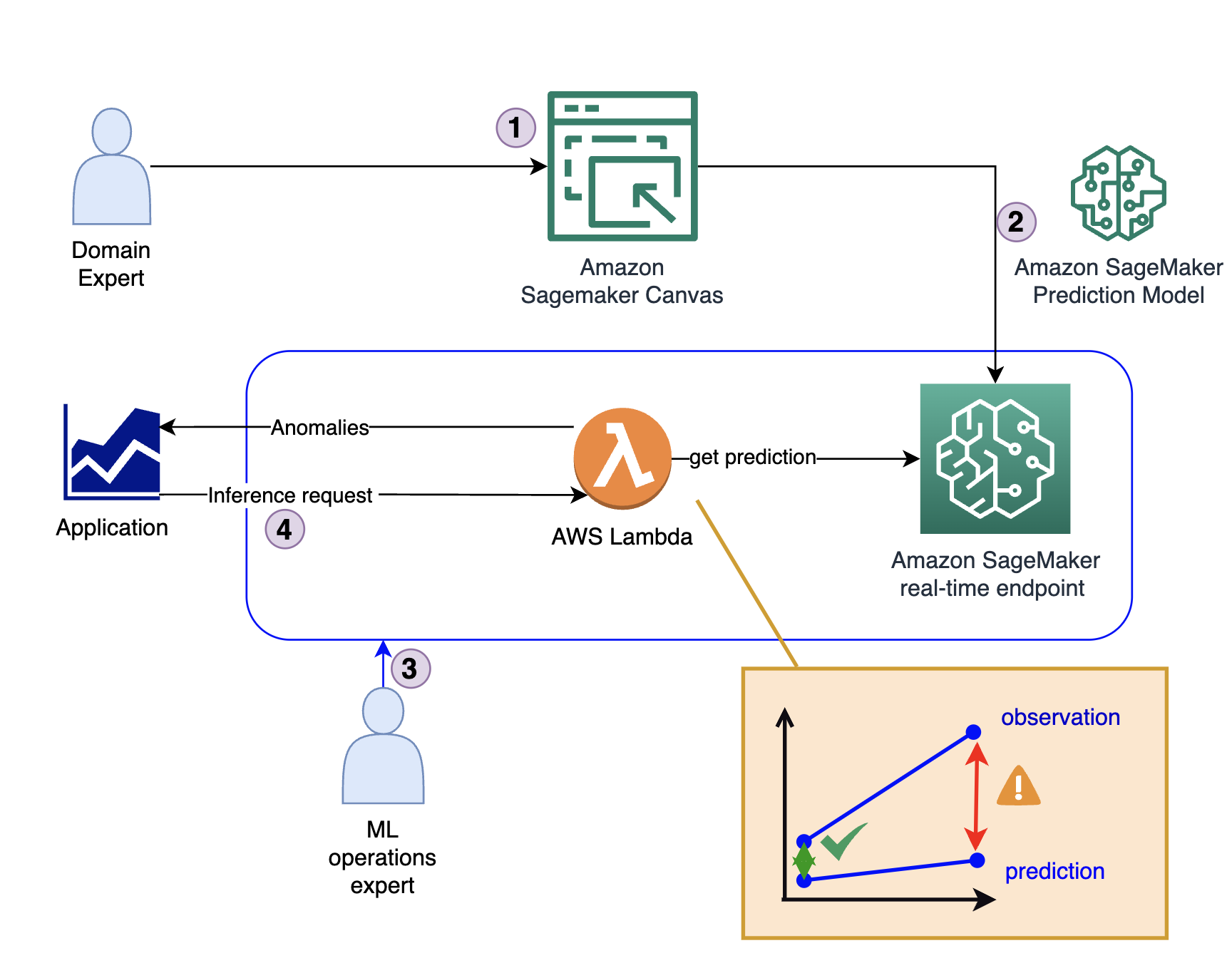
حل چار اہم مراحل پر مشتمل ہے:
- ڈومین ماہر ابتدائی ماڈل بناتا ہے، بشمول ڈیٹا کا تجزیہ اور SageMaker Canvas کا استعمال کرتے ہوئے فیچر کیوریشن۔
- ڈومین ماہر ماڈل کو کے ذریعے شیئر کرتا ہے۔ ایمیزون سیج میکر ماڈل رجسٹری یا اسے براہ راست ریئل ٹائم اینڈ پوائنٹ کے طور پر تعینات کرتا ہے۔
- ایک MLOps ماہر تخمینہ کا بنیادی ڈھانچہ اور کوڈ تخلیق کرتا ہے جو ماڈل آؤٹ پٹ کو پیشین گوئی سے ایک بے ضابطگی اشارے میں ترجمہ کرتا ہے۔ یہ کوڈ عام طور پر ایک کے اندر چلتا ہے۔ او ڈبلیو ایس لامبڈا۔ تقریب.
- جب کسی ایپلیکیشن کو بے ضابطگی کا پتہ لگانے کی ضرورت ہوتی ہے، تو یہ لیمبڈا فنکشن کو کال کرتا ہے، جو ماڈل کو اندازہ کے لیے استعمال کرتا ہے اور جواب فراہم کرتا ہے (چاہے یہ بے ضابطگی ہو یا نہ ہو)۔
شرائط
اس پوسٹ کی پیروی کرنے کے لیے، آپ کو درج ذیل شرائط کو پورا کرنا ہوگا:
SageMaker کا استعمال کرتے ہوئے ماڈل بنائیں
ماڈل بنانے کا عمل SageMaker Canvas میں ریگریشن ماڈل بنانے کے لیے معیاری مراحل کی پیروی کرتا ہے۔ مزید معلومات کے لیے رجوع کریں۔ ایمیزون سیج میکر کینوس کا استعمال شروع کرنا.
سب سے پہلے، ڈومین کا ماہر متعلقہ ڈیٹا کو SageMaker Canvas میں لوڈ کرتا ہے، جیسے کہ پیمائش کی ٹائم سیریز۔ اس پوسٹ کے لیے، ہم ایک CSV فائل استعمال کرتے ہیں جس میں ایک الیکٹریکل موٹر کی (مصنوعی طور پر تیار کردہ) پیمائش ہوتی ہے۔ تفصیلات کے لیے رجوع کریں۔ کینوس میں ڈیٹا درآمد کریں۔. استعمال شدہ نمونہ ڈیٹا بطور ڈاؤن لوڈ کے لیے دستیاب ہے۔ CSV.
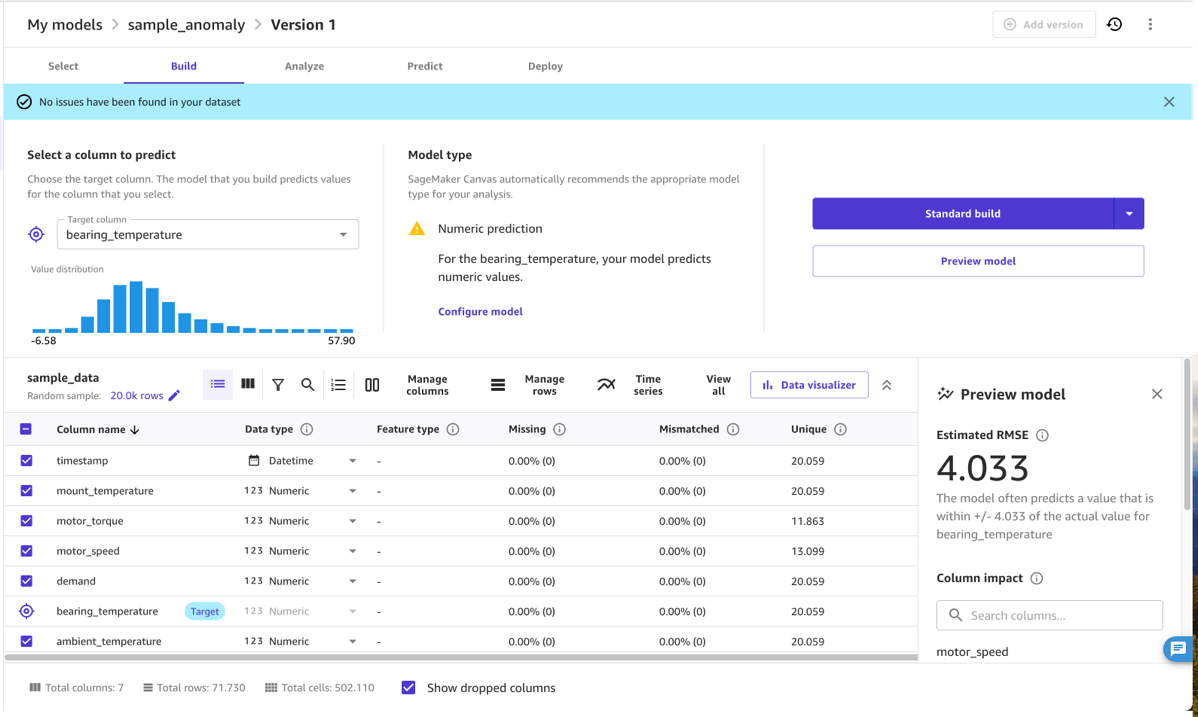
سیج میکر کینوس کے ساتھ ڈیٹا کو درست کریں۔
ڈیٹا لوڈ ہونے کے بعد، ڈومین کا ماہر حتمی ماڈل میں استعمال ہونے والے ڈیٹا کو درست کرنے کے لیے SageMaker Canvas کا استعمال کر سکتا ہے۔ اس کے لیے، ماہر ان کالموں کا انتخاب کرتا ہے جن میں زیر بحث مسئلے کے لیے خصوصیت کی پیمائش ہوتی ہے۔ زیادہ واضح طور پر، ماہر ان کالموں کا انتخاب کرتا ہے جو ایک دوسرے سے متعلق ہوتے ہیں، مثال کے طور پر، کسی جسمانی تعلق سے جیسے کہ دباؤ کے درجہ حرارت کے منحنی خطوط سے، اور جہاں اس تعلق میں تبدیلی ان کے استعمال کے معاملے کے لیے ایک متعلقہ بے ضابطگی ہے۔ بے ضابطگی کا پتہ لگانے والا ماڈل منتخب کالموں کے درمیان معمول کے تعلق کو سیکھے گا اور اس بات کی نشاندہی کرے گا کہ جب ڈیٹا اس کے مطابق نہیں ہوتا ہے، جیسے کہ موٹر پر موجودہ بوجھ کو دیکھتے ہوئے موٹر کا غیر معمولی درجہ حرارت۔
عملی طور پر، ڈومین کے ماہر کو مناسب ان پٹ کالموں کا ایک سیٹ اور ایک ہدف کالم منتخب کرنے کی ضرورت ہے۔ ان پٹ عام طور پر مقداروں (عددی یا واضح) کا مجموعہ ہوتے ہیں جو مشین کے رویے کا تعین کرتے ہیں، مانگ کی ترتیبات سے لے کر لوڈ، رفتار، یا محیطی درجہ حرارت تک۔ آؤٹ پٹ عام طور پر ایک عددی مقدار ہوتی ہے جو مشین کے آپریشن کی کارکردگی کی نشاندہی کرتی ہے، جیسے درجہ حرارت کی پیمائش کرنے والا توانائی کی کھپت یا دوسری کارکردگی میٹرک میں تبدیلی جب مشین سب سے زیادہ حالات میں چلتی ہے۔
ان پٹ اور آؤٹ پٹ کے لیے کن مقداروں کا انتخاب کرنا ہے اس تصور کو واضح کرنے کے لیے، آئیے چند مثالوں پر غور کریں:
- گھومنے والے آلات کے لیے، جیسا کہ ہم اس پوسٹ میں جو ماڈل بناتے ہیں، عام ان پٹ گردش کی رفتار، ٹارک (موجودہ اور تاریخ)، اور محیطی درجہ حرارت ہیں، اور اہداف نتیجے میں پیدا ہونے والے بیئرنگ یا موٹر کا درجہ حرارت ہیں جو گردش کے اچھے آپریشنل حالات کی نشاندہی کرتے ہیں۔
- ونڈ ٹربائن کے لیے، عام ان پٹ ہوا کی رفتار اور روٹر بلیڈ کی ترتیبات کی موجودہ اور حالیہ تاریخ ہیں، اور ہدف کی مقدار پیدا ہونے والی طاقت یا گردشی رفتار ہے۔
- ایک کیمیائی عمل کے لیے، عام ان پٹ مختلف اجزاء اور محیطی درجہ حرارت کا فیصد ہوتے ہیں، اور اہداف پیدا ہونے والی حرارت یا آخری مصنوعات کی چپکنے والی ہوتی ہیں۔
- حرکت پذیر آلات جیسے کہ سلائیڈنگ دروازے کے لیے، عام ان پٹ موٹروں کے لیے پاور ان پٹ ہوتے ہیں، اور ہدف کی قیمت حرکت کے لیے رفتار یا تکمیل کا وقت ہوتی ہے۔
- HVAC سسٹم کے لیے، عام ان پٹ درجہ حرارت کا حاصل کردہ فرق اور بوجھ کی ترتیبات ہیں، اور ہدف کی مقدار توانائی کی کھپت کو ماپا جاتا ہے۔
بالآخر، دیے گئے آلات کے لیے صحیح ان پٹ اور اہداف کا انحصار استعمال کے معاملے اور پتہ لگانے کے لیے غیر معمولی رویے پر ہوگا، اور یہ ایک ایسے ڈومین ماہر کے لیے بہتر طور پر جانا جاتا ہے جو مخصوص ڈیٹاسیٹ کی پیچیدگیوں سے واقف ہو۔
زیادہ تر معاملات میں، مناسب ان پٹ اور ہدف کی مقدار کو منتخب کرنے کا مطلب ہے صرف صحیح کالم کا انتخاب کرنا اور ہدف والے کالم کو نشان زد کرنا (اس مثال کے طور پر، bearing_temperature)۔ تاہم، ایک ڈومین ماہر کالموں کو تبدیل کرنے اور ڈیٹا کو بہتر بنانے یا جمع کرنے کے لیے SageMaker Canvas کی بغیر کوڈ والی خصوصیات کا بھی استعمال کر سکتا ہے۔ مثال کے طور پر، آپ اس ڈیٹا سے مخصوص تاریخوں یا ٹائم سٹیمپ کو نکال یا فلٹر کر سکتے ہیں جو متعلقہ نہیں ہیں۔ SageMaker Canvas اس عمل کی حمایت کرتا ہے، منتخب کردہ مقداروں کے اعدادوشمار دکھاتا ہے، آپ کو یہ سمجھنے کی اجازت دیتا ہے کہ آیا کسی مقدار میں آؤٹ لئیر اور پھیلاؤ ہے جو ماڈل کے نتائج کو متاثر کر سکتا ہے۔
ٹرین، ٹیون، اور ماڈل کا اندازہ
ڈومین ماہر کے ڈیٹاسیٹ میں مناسب کالم منتخب کرنے کے بعد، وہ ماڈل کو تربیت دے سکتے ہیں تاکہ وہ ان پٹ اور آؤٹ پٹس کے درمیان تعلق سیکھ سکے۔ مزید واضح طور پر، ماڈل آدانوں سے منتخب کردہ ہدف کی قیمت کی پیشن گوئی کرنا سیکھے گا۔
عام طور پر، آپ سیج میکر کینوس استعمال کر سکتے ہیں۔ ماڈل کا پیش نظارہ اختیار یہ توقع کرنے کے لیے ماڈل کے معیار کا فوری اشارہ فراہم کرتا ہے، اور آپ کو آؤٹ پٹ میٹرک پر مختلف ان پٹ کے اثرات کی چھان بین کرنے کی اجازت دیتا ہے۔ مثال کے طور پر، مندرجہ ذیل اسکرین شاٹ میں، ماڈل سب سے زیادہ متاثر ہوتا ہے۔ motor_speed اور ambient_temperature پیشن گوئی کرتے وقت میٹرکس bearing_temperature. یہ سمجھدار ہے، کیونکہ ان درجہ حرارت کا آپس میں گہرا تعلق ہے۔ ایک ہی وقت میں، اضافی رگڑ یا توانائی کے نقصان کے دیگر ذرائع اس پر اثر انداز ہوتے ہیں۔
ماڈل کی کوالٹی کے لیے، ماڈل کا RMSE اس بات کا اشارہ ہے کہ ماڈل ٹریننگ ڈیٹا میں نارمل رویے کو سیکھنے اور ان پٹ اور آؤٹ پٹ اقدامات کے درمیان تعلقات کو دوبارہ پیش کرنے کے قابل تھا۔ مثال کے طور پر، مندرجہ ذیل ماڈل میں، ماڈل کو درست پیشین گوئی کرنے کے قابل ہونا چاہیے۔ motor_bearing درجہ حرارت 3.67 ڈگری سیلسیس کے اندر ہے، لہذا ہم ماڈل کی پیشن گوئی سے حقیقی درجہ حرارت کے انحراف پر غور کر سکتے ہیں جو کہ مثال کے طور پر 7.4 ڈگری سے بڑا ہے۔ تاہم، حقیقی حد جو آپ استعمال کریں گے، اس کا انحصار تعیناتی کے منظر نامے میں درکار حساسیت پر ہوگا۔
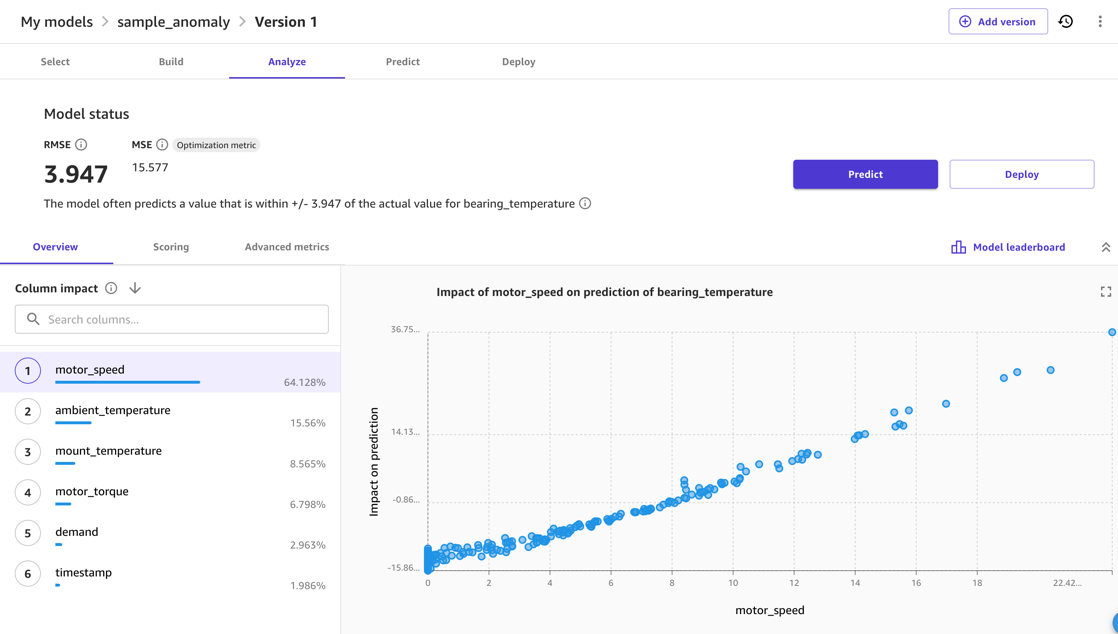
آخر میں، ماڈل کی تشخیص اور ٹیوننگ ختم ہونے کے بعد، آپ مکمل ماڈل ٹریننگ شروع کر سکتے ہیں جو کہ اندازہ لگانے کے لیے استعمال کرنے کے لیے ماڈل بنائے گی۔
ماڈل تعینات کریں۔
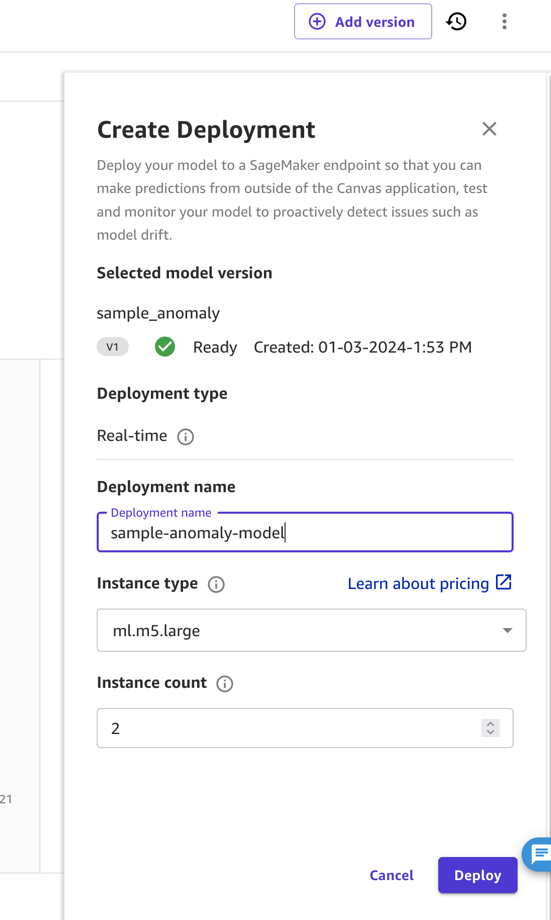
اگرچہ SageMaker Canvas اندازہ کے لیے ماڈل استعمال کر سکتا ہے، لیکن بے ضابطگی کا پتہ لگانے کے لیے نتیجہ خیز تعیناتی کے لیے آپ کو SageMaker Canvas کے باہر ماڈل کو تعینات کرنے کی ضرورت ہوتی ہے۔ مزید واضح طور پر، ہمیں ماڈل کو اختتامی نقطہ کے طور پر تعینات کرنے کی ضرورت ہے۔
اس پوسٹ میں اور سادگی کے لیے، ہم ماڈل کو SageMaker Canvas سے براہ راست اختتامی نقطہ کے طور پر تعینات کرتے ہیں۔ ہدایات کے لیے، رجوع کریں۔ اپنے ماڈلز کو اختتامی نقطہ پر تعینات کریں۔. اس بات کو یقینی بنائیں کہ تعیناتی کا نام نوٹ کریں اور اس مثال کی قسم کی قیمتوں پر غور کریں جس پر آپ تعینات کرتے ہیں (اس پوسٹ کے لیے، ہم ml.m5.large استعمال کرتے ہیں)۔ SageMaker Canvas پھر ایک ماڈل اینڈ پوائنٹ بنائے گا جسے پیشین گوئیاں حاصل کرنے کے لیے بلایا جا سکتا ہے۔
صنعتی ترتیبات میں، ایک ماڈل کو تعینات کرنے سے پہلے اسے مکمل جانچ سے گزرنا پڑتا ہے۔ اس کے لیے، ڈومین کا ماہر اسے تعینات نہیں کرے گا، بلکہ اس کے بجائے ماڈل کو SageMaker ماڈل رجسٹری میں شیئر کرے گا۔ یہاں، ایک MLOps آپریشنز ماہر سنبھال سکتا ہے۔ عام طور پر، وہ ماہر ماڈل اینڈ پوائنٹ کی جانچ کرے گا، ٹارگٹ ایپلیکیشن کے لیے درکار کمپیوٹنگ آلات کے سائز کا اندازہ کرے گا، اور سب سے زیادہ لاگت سے موثر تعیناتی کا تعین کرے گا، جیسے کہ سرور لیس انفرنس یا بیچ انفرنس کے لیے تعیناتی۔ یہ اقدامات عام طور پر خودکار ہوتے ہیں (مثال کے طور پر، استعمال کرنا ایمیزون سیج میکر پائپ لائنز یا ایمیزون SDK).
بے ضابطگی کا پتہ لگانے کے لیے ماڈل استعمال کریں۔
پچھلے مرحلے میں، ہم نے SageMaker Canvas میں ایک ماڈل کی تعیناتی بنائی، جسے کہا جاتا ہے۔ canvas-sample-anomaly-model. ہم اسے a کی پیشین گوئیاں حاصل کرنے کے لیے استعمال کر سکتے ہیں۔ bearing_temperature ڈیٹا سیٹ کے دوسرے کالموں کی بنیاد پر قدر۔ اب، ہم اس اختتامی نقطہ کو بے ضابطگیوں کا پتہ لگانے کے لیے استعمال کرنا چاہتے ہیں۔
غیر متزلزل ڈیٹا کی نشاندہی کرنے کے لیے، ہمارا ماڈل ٹارگٹ میٹرک کی متوقع قدر حاصل کرنے کے لیے پیشین گوئی ماڈل اینڈ پوائنٹ کا استعمال کرے گا اور پھر ڈیٹا میں اصل قدر کے مقابلے میں پیش گوئی کی گئی قدر کا موازنہ کرے گا۔ پیش گوئی کی گئی قدر تربیتی ڈیٹا کی بنیاد پر ہمارے ہدف میٹرک کے لیے متوقع قدر کی نشاندہی کرتی ہے۔ اس قدر کا فرق اس لیے مشاہدہ کیے گئے اصل ڈیٹا کی غیر معمولییت کے لیے ایک میٹرک ہے۔ ہم درج ذیل کوڈ استعمال کر سکتے ہیں:
سابقہ کوڈ درج ذیل اعمال انجام دیتا ہے:
- ان پٹ ڈیٹا کو صحیح خصوصیات میں فلٹر کیا جاتا ہے (فنکشن "
input_transformer"). - سیج میکر ماڈل اینڈ پوائنٹ کو فلٹر شدہ ڈیٹا کے ساتھ طلب کیا جاتا ہے (فنکشن "
do_inference")، جہاں ہم SageMaker Canvas میں اپنی تعیناتی کی تفصیلات کا صفحہ کھولتے وقت فراہم کردہ نمونہ کوڈ کے مطابق ان پٹ اور آؤٹ پٹ فارمیٹنگ کو ہینڈل کرتے ہیں۔ - درخواست کا نتیجہ اصل ان پٹ ڈیٹا سے جوڑ دیا جاتا ہے اور فرق کو ایرر کالم میں محفوظ کیا جاتا ہے (فنکشن "
output_transform").
بے ضابطگیوں کو تلاش کریں اور غیر معمولی واقعات کا اندازہ کریں۔
ایک عام سیٹ اپ میں، بے ضابطگیوں کو حاصل کرنے کے لیے کوڈ لیمبڈا فنکشن میں چلایا جاتا ہے۔ لیمبڈا فنکشن کو کسی ایپلیکیشن یا سے بلایا جا سکتا ہے۔ ایمیزون API گیٹ وے. مرکزی فنکشن ان پٹ ڈیٹا کی ہر قطار کے لیے ایک بے ضابطگی اسکور لوٹاتا ہے — اس صورت میں، ایک بے ضابطگی اسکور کی ٹائم سیریز۔
جانچ کے لیے، ہم کوڈ کو SageMaker نوٹ بک میں بھی چلا سکتے ہیں۔ مندرجہ ذیل گراف نمونہ ڈیٹا استعمال کرتے وقت ہمارے ماڈل کے ان پٹ اور آؤٹ پٹ کو دکھاتے ہیں۔ پیشن گوئی اور حقیقی قدروں کے درمیان انحراف کی چوٹیاں (بے ضابطگی کا سکور، نچلے گراف میں دکھایا گیا ہے) بے ضابطگیوں کی نشاندہی کرتے ہیں۔ مثال کے طور پر، گراف میں، ہم تین مختلف چوٹیاں دیکھ سکتے ہیں جہاں بے ضابطگی کا اسکور (متوقع اور حقیقی درجہ حرارت کے درمیان فرق) 7 ڈگری سیلسیس سے تجاوز کر جاتا ہے: پہلی طویل بیکار وقت کے بعد، دوسری bearing_temperature، اور آخری جہاں bearing_temperature کے مقابلے میں زیادہ ہے motor_speed.
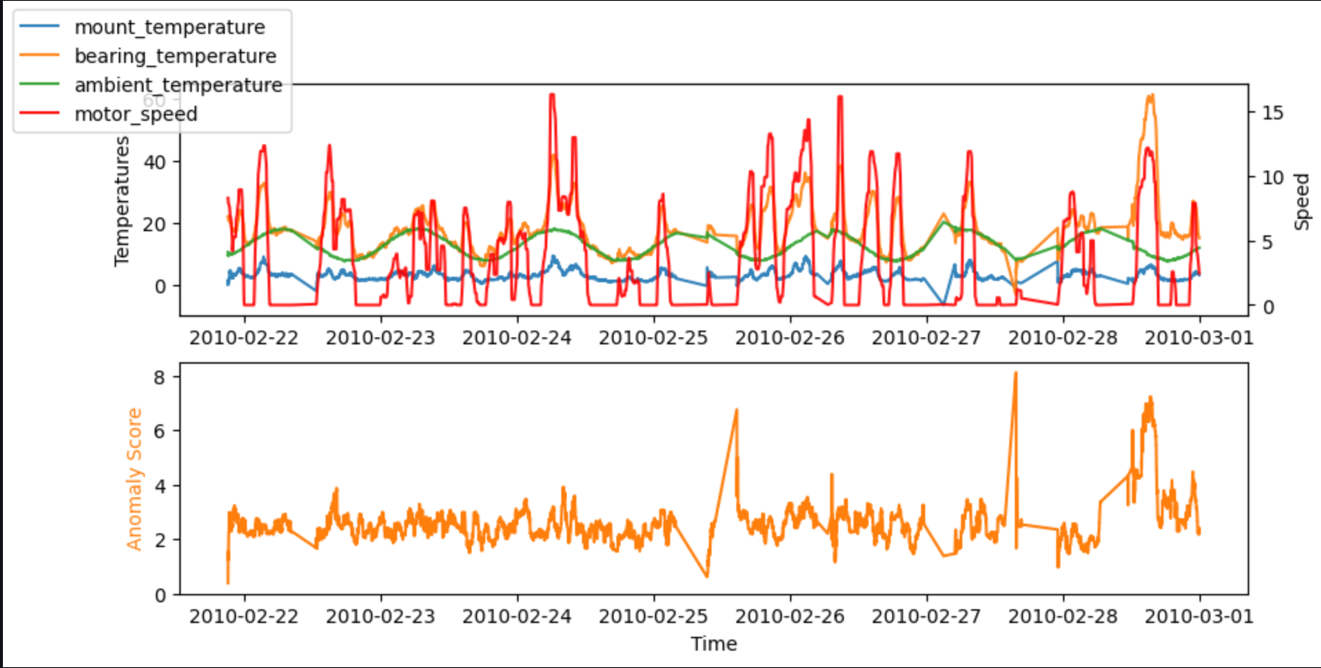
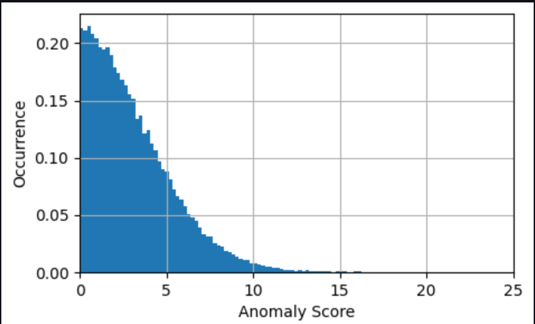
بہت سے معاملات میں، بے ضابطگی کے اسکور کی ٹائم سیریز کو جاننا پہلے سے ہی کافی ہے۔ آپ ماڈل کی حساسیت کی ضرورت کی بنیاد پر ایک اہم بے ضابطگی کے بارے میں خبردار کرنے کے لیے ایک حد مقرر کر سکتے ہیں۔ موجودہ سکور پھر اشارہ کرتا ہے کہ مشین میں ایک غیر معمولی حالت ہے جس کی تحقیقات کی ضرورت ہے۔ مثال کے طور پر، ہمارے ماڈل کے لیے، بے ضابطگی سکور کی مطلق قدر کو تقسیم کیا جاتا ہے جیسا کہ درج ذیل گراف میں دکھایا گیا ہے۔ یہ اس بات کی تصدیق کرتا ہے کہ زیادہ تر بے ضابطگی کے اسکور (2xRMS=)8 ڈگری سے کم ہیں جو ماڈل کی تربیت کے دوران عام غلطی کے طور پر پائے جاتے ہیں۔ گراف دستی طور پر ایک حد کا انتخاب کرنے میں آپ کی مدد کر سکتا ہے، جیسے کہ جانچے گئے نمونوں کا صحیح فیصد بے ضابطگیوں کے بطور نشان زد ہو۔
اگر مطلوبہ آؤٹ پٹ بے ضابطگیوں کے واقعات ہیں، تو ماڈل کے ذریعہ فراہم کردہ بے ضابطگی کے اسکور کو کاروباری استعمال کے لیے متعلقہ ہونے کے لیے تطہیر کی ضرورت ہوتی ہے۔ اس کے لیے، ML ماہر عام طور پر بے ضابطگی کے اسکور پر شور یا بڑی چوٹیوں کو دور کرنے کے لیے پوسٹ پروسیسنگ کا اضافہ کرے گا، جیسے کہ رولنگ کا مطلب شامل کرنا۔ اس کے علاوہ، ماہر عام طور پر بے ضابطگی کے اسکور کو ایک منطق کے ذریعے جانچے گا ایمیزون کلاؤڈ واچ الارم، جیسے ایک مخصوص مدت کے دوران حد کی خلاف ورزی کی نگرانی۔ الارم قائم کرنے کے بارے میں مزید معلومات کے لیے، رجوع کریں۔ Amazon CloudWatch کے الارم استعمال کرنا. لیمبڈا فنکشن میں ان تشخیصات کو چلانے سے آپ کو انتباہات بھیجنے کی اجازت ملتی ہے، مثال کے طور پر، ایک انتباہ شائع کرکے ایمیزون سادہ نوٹیفکیشن سروس (ایمیزون SNS) موضوع۔
صاف کرو
اس حل کو استعمال کرنے کے بعد، آپ کو غیر ضروری لاگت سے بچنے کے لیے صاف کرنا چاہیے:
- SageMaker Canvas میں، اپنے ماڈل اینڈ پوائنٹ کی تعیناتی تلاش کریں اور اسے حذف کریں۔
- SageMaker Canvas سے لاگ آؤٹ کریں تاکہ اس کے بے کار چلنے کے چارجز سے بچ سکیں۔
خلاصہ
اس پوسٹ میں، ہم نے دکھایا کہ کس طرح ایک ڈومین ماہر ان پٹ ڈیٹا کا جائزہ لے سکتا ہے اور کوڈ لکھنے کی ضرورت کے بغیر SageMaker Canvas کا استعمال کرتے ہوئے ML ماڈل بنا سکتا ہے۔ پھر ہم نے دکھایا کہ اس ماڈل کو ایک سادہ ورک فلو کے ذریعے SageMaker اور Lambda کا استعمال کرتے ہوئے ریئل ٹائم بے ضابطگی کا پتہ لگانے کے لیے کیسے استعمال کیا جائے۔ یہ مجموعہ ڈومین کے ماہرین کو طاقت دیتا ہے کہ وہ ڈیٹا سائنس میں بغیر کسی اضافی تربیت کے طاقتور ML ماڈلز بنانے کے لیے اپنے علم کا استعمال کریں، اور MLOps ماہرین کو ان ماڈلز کو استعمال کرنے اور انہیں لچکدار اور مؤثر طریقے سے اندازہ کے لیے دستیاب کرنے کے قابل بناتا ہے۔
SageMaker Canvas کے لیے 2 ماہ کا مفت درجہ دستیاب ہے، اور اس کے بعد آپ صرف وہی ادائیگی کرتے ہیں جو آپ استعمال کرتے ہیں۔ آج ہی تجربہ کرنا شروع کریں اور اپنے ڈیٹا سے زیادہ سے زیادہ فائدہ اٹھانے کے لیے ML شامل کریں۔
مصنف کے بارے میں
 Helge Aufderheide صنعتی ایپلی کیشنز، جیسے مینوفیکچرنگ اور موبلٹی میں آٹومیشن، تجزیات اور مشین لرننگ پر مضبوط توجہ کے ساتھ ڈیٹا کو حقیقی دنیا میں قابل استعمال بنانے کا شوقین ہے۔
Helge Aufderheide صنعتی ایپلی کیشنز، جیسے مینوفیکچرنگ اور موبلٹی میں آٹومیشن، تجزیات اور مشین لرننگ پر مضبوط توجہ کے ساتھ ڈیٹا کو حقیقی دنیا میں قابل استعمال بنانے کا شوقین ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/detect-anomalies-in-manufacturing-data-using-amazon-sagemaker-canvas/
- : ہے
- : ہے
- : نہیں
- :کہاں
- $UP
- 100
- 25
- 4
- 67
- 7
- a
- قابلیت
- غیر معمولی
- غیر معمولی پن
- ہمارے بارے میں
- مطلق
- قبول کریں
- رسائی
- کے مطابق
- حاصل کیا
- کے پار
- اعمال
- اصل
- شامل کریں
- انہوں نے مزید کہا
- اس کے علاوہ
- ایڈیشنل
- پتے
- پر اثر انداز
- متاثر
- کے بعد
- بعد
- کے خلاف
- مجموعی
- الارم
- کی اجازت
- اجازت دے رہا ہے
- کی اجازت دیتا ہے
- ساتھ
- پہلے ہی
- بھی
- ایمیزون
- ایمیزون سیج میکر
- ایمیزون سیج میکر کینوس
- ایمیزون ویب سروسز
- محیطی
- an
- تجزیہ
- تجزیہ کار کہتے ہیں
- تجزیاتی
- اور
- بے ضابطگی کا پتہ لگانا
- ایک اور
- کسی
- اے پی آئی
- درخواست
- ایپلی کیشنز
- اطلاقی
- فن تعمیر
- کیا
- AS
- At
- آٹومیٹڈ
- میشن
- دستیاب
- سے اجتناب
- AWS
- او ڈبلیو ایس لامبڈا۔
- محور
- کی بنیاد پر
- بنیاد
- BE
- کیونکہ
- بن
- اس سے پہلے
- رویے
- نیچے
- معیار
- BEST
- کے درمیان
- بگ
- بگ ڈیٹا
- بلیڈ
- جسم
- خلاف ورزی
- تعمیر
- کاروبار
- لیکن
- بٹن
- by
- کہا جاتا ہے
- کالز
- کر سکتے ہیں
- کینوس
- صلاحیتوں
- کار کے
- کیس
- مقدمات
- وجوہات
- سیلسیس
- تبدیل
- تبدیل کرنے
- خصوصیت
- بوجھ
- کیمیائی
- میں سے انتخاب کریں
- درجہ بندی
- صاف
- قریب سے
- بادل
- کلاؤڈ کمپیوٹنگ
- کوڈ
- مجموعہ
- کالم
- کالم
- مجموعہ
- کمپنیاں
- موازنہ
- مقابلے میں
- مکمل
- تکمیل
- پیچیدہ
- کمپیوٹنگ
- تصور
- حالات
- ترتیب
- غور کریں
- مشتمل
- کھپت
- پر مشتمل ہے
- مواد
- کولنگ کا نظام
- درست
- قیمت
- تخلیق
- بنائی
- پیدا
- مخلوق
- ورزش
- کیپشن
- موجودہ
- وکر
- گاہکوں
- اعداد و شمار
- ڈیٹا تجزیہ
- ڈیٹا تجزیات
- ڈیٹا پوائنٹس
- ڈیٹا سائنس
- اعداد و شمار پر مبنی ہے
- تواریخ
- فیصلہ کرنا
- کم ہے
- گہری
- def
- حذف
- ڈیمانڈ
- مظاہرہ
- انحصار
- تعیناتی
- تعینات
- تعیناتی
- تعینات کرتا ہے
- بیان کرتا ہے
- مطلوبہ
- تفصیلات
- کا پتہ لگانے کے
- کھوج
- اس بات کا تعین
- انحراف
- آریھ
- فرق
- مختلف
- براہ راست
- تضاد
- مختلف
- تقسیم کئے
- نہیں کرتا
- ڈومین
- دروازے
- نیچے
- ڈاؤن لوڈ، اتارنا
- چھوڑ
- مدت
- کے دوران
- ہر ایک
- اثر
- کارکردگی
- ہنر
- مؤثر طریقے سے
- کوشش
- بااختیار بنانا
- کے قابل بناتا ہے
- آخر
- اختتام پوائنٹ
- توانائی
- توانائی کی کھپت
- انجینئرز
- حوصلہ افزائی
- پوری
- کا سامان
- خرابی
- Ether (ETH)
- اندازہ
- اندازہ
- تشخیص
- اندازہ
- واقعات
- جانچ پڑتال
- مثال کے طور پر
- مثال کے طور پر
- توقع ہے
- توقع
- تجربہ
- استعمال
- ماہر
- ماہرین
- نمائش
- نکالنے
- سامنا کرنا پڑا
- عوامل
- ناکامی
- ناکامیوں
- واقف
- غلطی
- غلطیاں
- نمایاں کریں
- خصوصیات
- چند
- فائل
- فلٹر
- فائنل
- مل
- تلاش
- پہلا
- نرمی سے
- توجہ مرکوز
- توجہ مرکوز
- پر عمل کریں
- کے بعد
- مندرجہ ذیل ہے
- کے لئے
- پیشن گوئی
- ملا
- چار
- مفت
- رگڑ
- سے
- تقریب
- فعالیت
- مستقبل
- پیدا
- پیدا
- حاصل
- دی
- اچھا
- گراف
- گرافکس
- ہاتھ
- ہینڈل
- ہینڈلنگ
- ہے
- مدد
- یہاں
- ہائی
- اعلی سطحی
- تاریخ
- کس طرح
- کیسے
- تاہم
- HTML
- HTTP
- HTTPS
- hvac
- HVAC نظام
- شناخت
- ناقابل یقین
- if
- وضاحت
- وضاحت کرتا ہے
- تصویر
- درآمد
- اہم
- بہتری
- in
- سمیت
- اضافہ
- دن بدن
- انڈکس
- اشارہ کرتے ہیں
- اشارہ کیا
- اشارہ کرتا ہے
- اشارہ کرتے ہیں
- اشارہ
- اشارے
- انڈیکیٹر
- صنعتی
- صنعتوں
- صنعت
- اثر انداز
- معلومات
- انفراسٹرکچر
- اجزاء
- ابتدائی
- ان پٹ
- آدانوں
- کے اندر
- بصیرت
- مثال کے طور پر
- کے بجائے
- ہدایات
- انٹرفیس
- تشریح
- میں
- پیچیدگیاں
- کی تحقیقات
- تحقیقات
- تحقیقات
- درخواست کی
- IT
- میں
- شامل ہو گئے
- فوٹو
- JSON
- کلیدی
- جاننا
- علم
- جانا جاتا ہے
- نہیں
- زبانیں
- بڑے
- بڑے
- آخری
- جانیں
- سیکھنے
- کی طرح
- امکان
- لمیٹڈ
- لکیری
- لائنوں
- لوڈ
- بوجھ
- منطق
- لانگ
- دیکھو
- بند
- کم
- مشین
- مشین لرننگ
- مشینیں
- مین
- دیکھ بھال
- بنا
- بنانا
- خرابی
- مینیجر
- دستی طور پر
- مینوفیکچرنگ
- بہت سے
- نشان لگا دیا گیا
- مارکنگ
- مئی..
- مطلب
- کا مطلب ہے کہ
- پیمائش
- اقدامات
- پیمائش
- سے ملو
- پیغامات
- میٹرک۔
- پیمائش کا معیار
- ML
- ایم ایل اوپس
- موبلٹی
- ماڈل
- ماڈل
- نگرانی
- زیادہ
- سب سے زیادہ
- موٹر
- موٹرز
- منتقل
- بہت
- ضروری
- my
- نام
- ضرورت ہے
- ضروریات
- نئی
- شور
- عام
- عام طور پر
- براہ مہربانی نوٹ کریں
- نوٹ بک
- نوٹیفیکیشن
- اب
- مشاہدے
- مشاہدہ
- حاصل
- حاصل
- واقعہ
- of
- اکثر
- on
- ایک
- صرف
- کھولنے
- آپریشن
- آپریشنل
- آپریشنز
- اختیار
- or
- اصل
- دیگر
- ہمارے
- باہر
- پیداوار
- نتائج
- باہر
- پر
- مجموعی جائزہ
- صفحہ
- pandas
- ادا
- فیصد
- انجام دینے کے
- کارکردگی
- کارکردگی کا مظاہرہ
- کارکردگی کا مظاہرہ
- جسمانی
- تصویر
- منصوبہ بندی
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- پوائنٹ
- پوائنٹس
- پورٹ فولیو
- پوسٹ
- ممکنہ
- طاقت
- طاقتور
- پریکٹس
- ٹھیک ہے
- پیشن گوئی
- پیش گوئی
- پیش گوئی
- کی پیشن گوئی
- پیشن گوئی
- پیشن گوئی
- تیار
- ضروریات
- پچھلا
- قیمتوں کا تعین
- مسئلہ
- عمل
- تیار
- پیداواری
- پروگرامنگ
- پروگرامنگ زبانوں
- فراہم
- فراہم
- فراہم کرتا ہے
- فراہم کرنے
- پبلشنگ
- ازگر
- معیار
- مقدار
- سوال
- فوری
- بلند
- پڑھیں
- اصلی
- حقیقی دنیا
- اصل وقت
- حال ہی میں
- کا حوالہ دیتے ہیں
- بہتر
- رجسٹری
- رجعت
- باقاعدہ
- متعلقہ
- تعلقات
- تعلقات
- متعلقہ
- قابل اعتماد
- ہٹا
- کی ضرورت
- ضرورت
- کی ضرورت ہے
- وسائل
- جواب
- نتیجہ
- نتیجے
- نتائج کی نمائش
- واپسی
- واپسی
- ٹھیک ہے
- رولنگ
- جڑ
- ROW
- رن
- چل رہا ہے
- چلتا ہے
- sagemaker
- اسی
- نمونہ
- منظر نامے
- سائنس
- سکور
- اسکور
- دوسری
- دیکھنا
- منتخب
- منتخب
- منتخب
- بھیجنے
- حساسیت
- سیریز
- بے سرور
- سروسز
- مقرر
- قائم کرنے
- ترتیبات
- سیٹ اپ
- سیکنڈ اور
- حصص
- ہونا چاہئے
- دکھائیں
- سے ظاہر ہوا
- ظاہر
- دکھایا گیا
- شوز
- اہم
- اسی طرح
- سادہ
- سادگی
- سائز
- مہارت
- سلائڈنگ
- So
- حل
- کچھ
- تناؤ
- ماہرین
- مخصوص
- تیزی
- رفتار
- پھیلانے
- معیار
- شروع کریں
- شروع
- حالت
- کے اعداد و شمار
- درجہ
- مرحلہ
- مراحل
- ذخیرہ
- مضبوط
- سب سے زیادہ
- اس طرح
- کافی
- موزوں
- کی حمایت کرتا ہے
- اس بات کا یقین
- حد تک
- مصنوعی طور پر
- کے نظام
- لے لو
- ہدف
- اہداف
- ٹیسٹ
- ٹیسٹنگ
- سے
- کہ
- ۔
- گراف
- ان
- ان
- تو
- لہذا
- یہ
- وہ
- اس
- مکمل
- ان
- تین
- حد
- کے ذریعے
- درجے
- وقت
- وقت کا سلسلہ
- اوقات
- کرنے کے لئے
- آج
- اوزار
- سب سے اوپر
- موضوع
- کی طرف
- روایتی
- ٹرین
- ٹریننگ
- ٹرینوں
- تبدیل
- دھن
- ٹیوننگ
- ٹربائن
- دو
- قسم
- ٹھیٹھ
- عام طور پر
- کے تحت
- گزرنا
- سمجھ
- غیر ضروری
- غیر معمولی
- استعمال کے قابل
- استعمال کی شرائط
- استعمال کیس
- استعمال کیا جاتا ہے
- استعمال
- کا استعمال کرتے ہوئے
- قیمت
- اقدار
- VeloCity
- بہت
- کی طرف سے
- چاہتے ہیں
- انتباہ
- تھا
- we
- ویب
- ویب خدمات
- اچھا ہے
- کیا
- کیا ہے
- جب
- چاہے
- جس
- ڈبلیو
- گے
- ونڈ
- ونڈ ٹربائن
- ونڈو
- ساتھ
- کے اندر
- بغیر
- کام کا بہاؤ
- کام کر
- دنیا
- گا
- لکھنا
- کوڈ لکھیں
- تحریری طور پر
- سال
- ابھی
- آپ
- اور
- زیفیرنیٹ