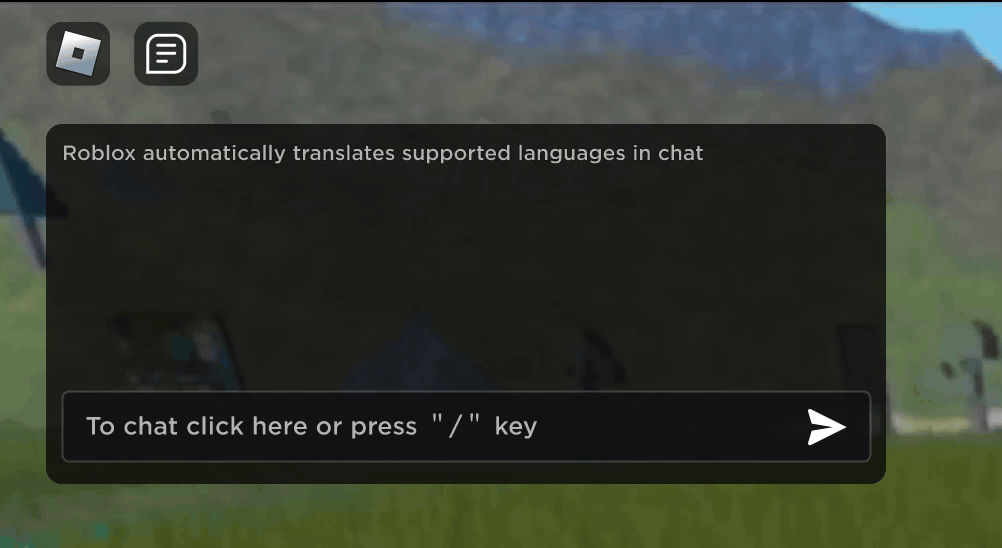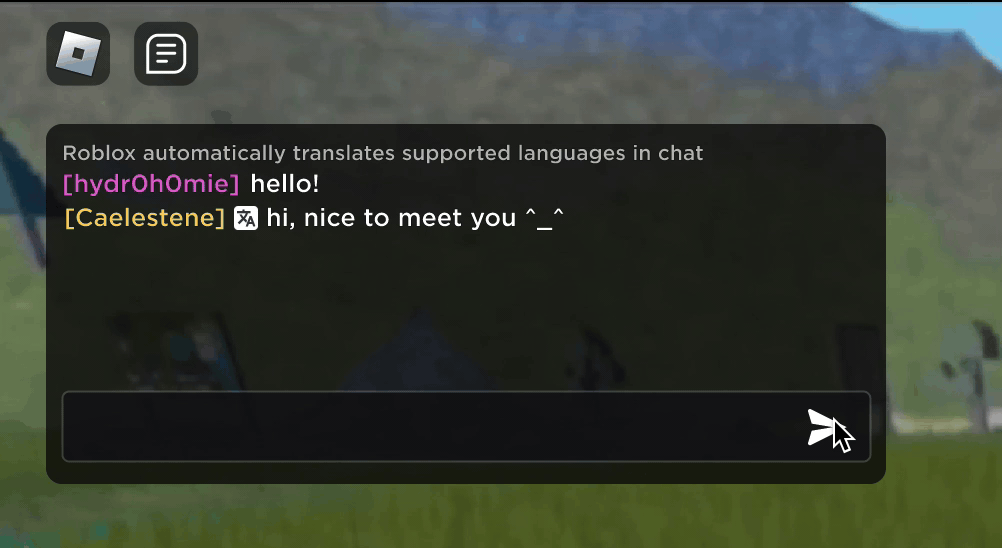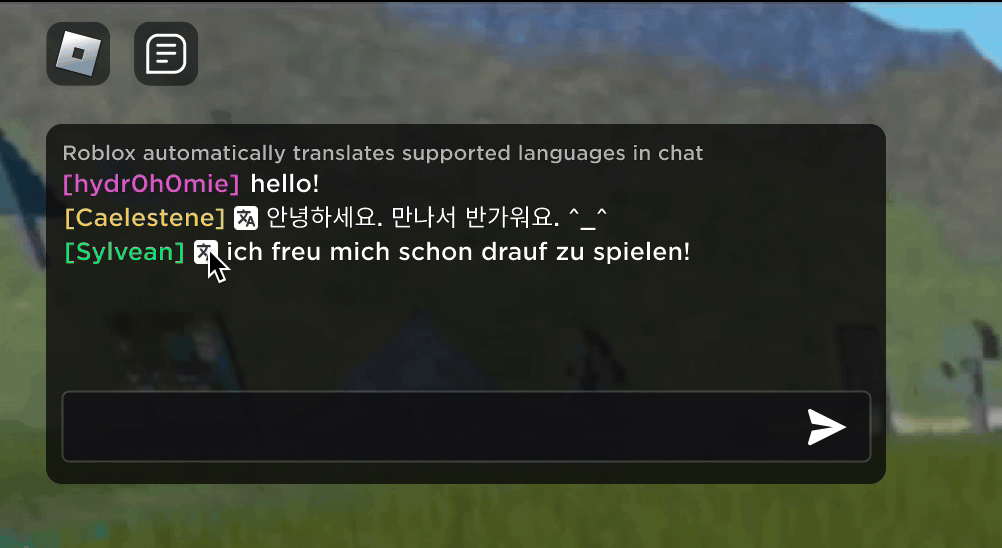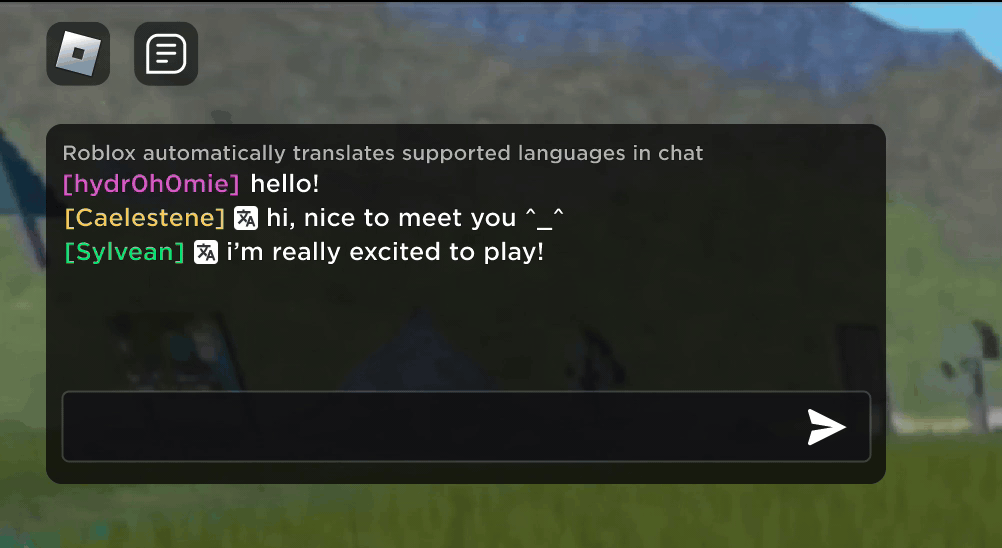
تصور کریں کہ آپ کا نیا روبلوکس دوست، ایک ایسا شخص جس کے ساتھ آپ ایک نئے تجربے میں چیٹنگ اور مذاق کر رہے ہیں، دراصل کوریا میں ہے — اور پورے وقت کورین میں ٹائپ کر رہا ہے، جب کہ آپ انگریزی میں ٹائپ کر رہے ہیں، بغیر کسی ایک کے۔ آپ دیکھ رہے ہیں. ہمارے نئے ریئل ٹائم AI چیٹ ترجمے کی بدولت، ہم نے Roblox پر کچھ ایسا ممکن بنایا ہے جو کہ طبعی دنیا میں بھی ممکن نہیں ہے — مختلف زبانیں بولنے والے لوگوں کو ہمارے عمیق 3D تجربات میں ایک دوسرے کے ساتھ بغیر کسی رکاوٹ کے بات چیت کرنے کے قابل بنانا۔ یہ ہمارے حسب ضرورت کثیر لسانی ماڈل کی وجہ سے ممکن ہے، جو اب 16 زبانوں کے کسی بھی مجموعہ کے درمیان براہ راست ترجمہ کو قابل بناتا ہے جن کی ہم فی الحال حمایت کرتے ہیں (یہ 15 زبانیں، نیز انگریزی)۔
کسی بھی تجربے میں جس نے ہمارے قابل بنایا ہے۔ غیر تجربہ شدہ ٹیکسٹ چیٹ سروس، مختلف ممالک کے لوگوں کو اب وہ لوگ سمجھ سکتے ہیں جو اپنی زبان نہیں بولتے۔ چیٹ ونڈو خودکار طور پر انگریزی میں ترجمہ شدہ کوریائی، یا جرمن میں ترجمہ شدہ ترکی، اور اس کے برعکس دکھائے گی، تاکہ ہر شخص اپنی زبان میں گفتگو کو دیکھ سکے۔ یہ ترجمے حقیقی وقت میں دکھائے جاتے ہیں، 100 ملی سیکنڈ یا اس سے کم تاخیر کے ساتھ، اس لیے پردے کے پیچھے ہونے والا ترجمہ تقریباً پوشیدہ ہے۔ ٹیکسٹ چیٹ میں ریئل ٹائم ترجمہ کو خودکار کرنے کے لیے AI کا استعمال زبان کی رکاوٹوں کو دور کرتا ہے اور زیادہ سے زیادہ لوگوں کو اکٹھا کرتا ہے، چاہے وہ دنیا میں کہیں بھی رہتے ہوں۔
یونیفائیڈ ٹرانسلیشن ماڈل بنانا
AI ترجمہ نیا نہیں ہے، ہمارے زیادہ تر غیر تجربہ کار مواد کا خود بخود ترجمہ ہو چکا ہے۔ ہم تجربات میں جامد مواد کا ترجمہ کرنے سے آگے جانا چاہتے تھے۔ ہم خود بخود تعاملات کا ترجمہ کرنا چاہتے تھے - اور ہم پلیٹ فارم پر ان تمام 16 زبانوں کے لیے کرنا چاہتے تھے جن کی ہم حمایت کرتے ہیں۔ یہ دو وجوہات کی بنا پر ایک دلیرانہ مقصد تھا: پہلا، ہم صرف ایک بنیادی زبان (یعنی انگریزی) سے دوسری زبان میں ترجمہ نہیں کر رہے تھے، ہم ایک ایسا نظام چاہتے تھے جو ہم جن 16 زبانوں کی حمایت کرتے ہیں ان کے کسی بھی مجموعہ کے درمیان ترجمہ کرنے کے قابل ہو۔ دوسرا، یہ ہونا ضروری تھا روزہ. حقیقی چیٹ مکالمات کو سپورٹ کرنے کے لیے کافی تیز، جس کا مطلب ہمارے لیے 100 ملی سیکنڈ یا اس سے کم تاخیر کا ہونا تھا۔
Roblox پوری دنیا میں روزانہ 70 ملین سے زیادہ فعال صارفین کا گھر ہے اور بڑھ رہا ہے۔ لوگ ہمارے پلیٹ فارم پر بات چیت کر رہے ہیں اور تخلیق کر رہے ہیں — ہر ایک اپنی مادری زبان میں — دن کے 24 گھنٹے۔ 15 ملین سے زیادہ فعال تجربات میں ہونے والی ہر گفتگو کا دستی طور پر ترجمہ کرنا، یہ سب کچھ حقیقی وقت میں، ظاہر ہے کہ ممکن نہیں ہے۔ ان لائیو تراجم کو لاکھوں لوگوں تک پہنچانے کے لیے، سبھی ایک ساتھ مختلف تجربات میں مختلف گفتگو کرتے ہیں، زبردست رفتار اور درستگی کے ساتھ LLM کی ضرورت ہوتی ہے۔ ہمیں سیاق و سباق سے آگاہ ماڈل کی ضرورت ہے جو روبلوکس کے لیے مخصوص زبان کو پہچانتا ہو، بشمول بول چال اور مخففات (سوچیں obby، afk، یا lol)۔ ان سب کے علاوہ، ہمارے ماڈل کو 16 زبانوں کے کسی بھی مجموعہ کو سپورٹ کرنے کی ضرورت ہے جو Roblox اس وقت سپورٹ کرتا ہے۔
اس کو حاصل کرنے کے لیے، ہم ہر زبان کے جوڑے (یعنی جاپانی اور ہسپانوی) کے لیے ایک منفرد ماڈل بنا سکتے تھے، لیکن اس کے لیے 16×16، یا 256 مختلف ماڈلز کی ضرورت ہوگی۔ اس کے بجائے، ہم نے ایک ہی ماڈل میں تمام زبان کے جوڑوں کو سنبھالنے کے لیے ایک متحد، ٹرانسفارمر پر مبنی ترجمہ LLM بنایا۔ یہ ایک سے زیادہ ترجمے کی ایپس رکھنے جیسا ہے، ہر ایک ایک جیسی زبانوں کے گروپ میں مہارت رکھتا ہے، سبھی ایک ہی انٹرفیس کے ساتھ دستیاب ہیں۔ ایک ماخذ جملے اور ہدف کی زبان کو دیکھتے ہوئے، ہم متعلقہ "ماہر" کو ترجمے بنانے کے لیے فعال کر سکتے ہیں۔
یہ فن تعمیر وسائل کے بہتر استعمال کی اجازت دیتا ہے، کیونکہ ہر ماہر کی ایک الگ خصوصیت ہوتی ہے، جو ترجمے کے معیار کو قربان کیے بغیر زیادہ موثر تربیت اور اندازہ کا باعث بنتی ہے۔
تخمینہ کے عمل کی مثال۔ ماخذی پیغامات، ماخذ کی زبان اور ہدف کی زبانوں کے ساتھ آر سی سی سے گزرے ہیں۔ پچھلے سرے کو مارنے سے پہلے، ہم سب سے پہلے یہ دیکھنے کے لیے کیش چیک کرتے ہیں کہ آیا ہمارے پاس پہلے سے ہی اس درخواست کے ترجمے موجود ہیں۔ اگر نہیں، تو درخواست کو بیک اینڈ پر اور ڈائنامک بیچنگ کے ساتھ ماڈل سرور کو منتقل کیا جاتا ہے۔ ہم نے متعدد ٹارگٹ زبانوں میں ترجمہ کرتے وقت کارکردگی کو مزید بہتر بنانے کے لیے انکوڈرز اور ڈیکوڈرز کے درمیان ایمبیڈنگ کیشے کی پرت شامل کی۔
یہ فن تعمیر کچھ وجوہات کی بنا پر ہمارے ماڈل کو تربیت دینے اور اسے برقرار رکھنے کے لیے کہیں زیادہ موثر بناتا ہے۔ سب سے پہلے، ہمارا ماڈل زبانوں کے درمیان لسانی مماثلتوں کا فائدہ اٹھانے کے قابل ہے۔ جب تمام زبانوں کو ایک ساتھ تربیت دی جاتی ہے، جو زبانیں ملتی جلتی ہیں، جیسے کہ ہسپانوی اور پرتگالی، تربیت کے دوران ایک دوسرے کے ان پٹ سے فائدہ اٹھاتی ہیں، جو دونوں زبانوں کے لیے ترجمہ کے معیار کو بہتر بنانے میں مدد کرتی ہے۔ ہم LLMs میں نئی تحقیق اور پیشرفت کو اپنے سسٹم میں آسانی سے جانچ سکتے ہیں اور ضم کر سکتے ہیں جیسے ہی وہ جاری ہوں گے، تاکہ دستیاب جدید ترین اور بہترین تکنیکوں سے استفادہ کیا جا سکے۔ ہمیں اس متحد ماڈل کا ایک اور فائدہ ان صورتوں میں نظر آتا ہے جہاں ماخذ کی زبان سیٹ نہیں کی گئی ہے یا غلط طریقے سے سیٹ کی گئی ہے، جہاں ماڈل اتنا درست ہے کہ وہ صحیح ماخذ کی زبان کا پتہ لگانے اور ہدف کی زبان میں ترجمہ کرنے کے قابل ہے۔ درحقیقت، یہاں تک کہ اگر ان پٹ میں زبانوں کا امتزاج ہے، تب بھی سسٹم ہدف کی زبان کا پتہ لگانے اور اس میں ترجمہ کرنے کے قابل ہے۔ ان صورتوں میں، درستگی اتنی زیادہ نہیں ہوسکتی ہے، لیکن حتمی پیغام معقول حد تک قابل فہم ہوگا۔
اس متحد ماڈل کو تربیت دینے کے لیے، ہم نے دستیاب اوپن سورس ڈیٹا کے ساتھ ساتھ اپنے تجرباتی ترجمے کے ڈیٹا، انسانی لیبل والے چیٹ کے ترجمہ کے نتائج، اور عام چیٹ کے جملوں اور فقروں کی تربیت کے ذریعے آغاز کیا۔ ہم نے ترجمہ کے معیار کی پیمائش کرنے کے لیے اپنا ترجمہ تشخیصی میٹرک اور ماڈل بھی بنایا ہے۔ زیادہ تر آف دی شیلف ترجمے کی کوالٹی میٹرکس AI ترجمہ کے نتیجے کا موازنہ کچھ زمینی سچائی یا حوالہ جاتی ترجمہ سے کرتی ہیں اور بنیادی طور پر ترجمے کی سمجھ پر توجہ مرکوز کرتی ہیں۔ ہم اس کا اندازہ لگانا چاہتے تھے۔ معیار ترجمہ کا - بغیر زمینی سچائی کے ترجمہ کے۔
ہم اسے متعدد پہلوؤں سے دیکھتے ہیں، بشمول درستگی (چاہے کوئی اضافہ، بھول چوک یا غلط ترجمہ ہو)، روانی (اوقاف، ہجے، اور گرامر)، اور غلط حوالہ جات (باقی متن کے ساتھ تضادات)۔ ہم ان غلطیوں کو شدت کی سطحوں میں درجہ بندی کرتے ہیں: کیا یہ ایک اہم، بڑی، یا معمولی غلطی ہے؟ معیار کا اندازہ لگانے کے لیے، ہم نے ایک ML ماڈل بنایا اور اسے انسانی لیبل والی غلطی کی اقسام اور اسکور پر تربیت دی۔ اس کے بعد ہم نے لفظی سطح کی غلطیوں اور اقسام کی پیشین گوئی کرنے کے لیے کثیر لسانی زبان کے ماڈل کو ٹھیک بنایا اور اپنے کثیر جہتی معیار کو استعمال کرتے ہوئے اسکور کا حساب لگایا۔ اس سے ہمیں ہونے والی خرابیوں کے معیار اور اقسام کی ایک جامع تفہیم ملتی ہے۔ اس طرح ہم ترجمے کے معیار کا اندازہ لگا سکتے ہیں اور ماخذ متن اور مشینی تراجم کا استعمال کرتے ہوئے غلطیوں کا پتہ لگا سکتے ہیں، بغیر زمینی سچائی کے ترجمہ کی ضرورت ہے۔ اس معیار کی پیمائش کے نتائج کا استعمال کرتے ہوئے، ہم اپنے ترجمہ ماڈل کے معیار کو مزید بہتر بنا سکتے ہیں۔
ماخذ متن اور مشینی ترجمہ کے نتیجے کے ساتھ، ہم اپنے اندرون خانہ ترجمہ کے معیار کے تخمینے کے ماڈل کا استعمال کرتے ہوئے بغیر حوالہ ترجمہ کے مشینی ترجمہ کے معیار کا اندازہ لگا سکتے ہیں۔ یہ ماڈل مختلف پہلوؤں سے معیار کا تخمینہ لگاتا ہے اور غلطیوں کو اہم، بڑی اور چھوٹی غلطیوں میں درجہ بندی کرتا ہے۔
کم عام ترجمے کے جوڑے (کہتے ہیں، فرانسیسی سے تھائی)، اعلیٰ معیار کے ڈیٹا کی کمی کی وجہ سے مشکل ہیں۔ اس فرق کو پورا کرنے کے لیے، ہم نے واپس ترجمہ کا اطلاق کیا، جہاں مواد کا اصل زبان میں ترجمہ کیا جاتا ہے، پھر درستگی کے لیے ماخذ کے متن سے موازنہ کیا جاتا ہے۔ تربیتی عمل کے دوران، ہم نے تکراری بیک ٹرانسلیشن کا استعمال کیا، جہاں ہم اس بیک ترجمہ شدہ ڈیٹا اور نگرانی شدہ (لیبل لگا ہوا) ڈیٹا کا ایک اسٹریٹجک مرکب استعمال کرتے ہیں تاکہ ماڈل کو سیکھنے کے لیے ترجمہ ڈیٹا کی مقدار کو بڑھایا جا سکے۔
ماڈل ٹریننگ پائپ لائن کی مثال۔ ماڈل ٹریننگ کے دوران متوازی ڈیٹا اور بیک ٹرانسلیشن ڈیٹا دونوں استعمال کیے جاتے ہیں۔ ٹیچر ماڈل کی تربیت کے بعد، ہم ماڈل کے سائز کو کم کرنے اور سرونگ کی کارکردگی کو بہتر بنانے کے لیے ڈسٹلیشن اور دیگر سرونگ آپٹیمائزیشن تکنیکوں کا اطلاق کرتے ہیں۔
ماڈل کو جدید بول چال کو سمجھنے میں مدد کرنے کے لیے، ہم نے انسانی تشخیص کاروں سے ہر زبان کے لیے مقبول اور رجحان ساز اصطلاحات کا ترجمہ کرنے کو کہا، اور ان تراجم کو اپنے تربیتی ڈیٹا میں شامل کیا۔ سسٹم کو تازہ ترین سلیگ پر اپ ٹو ڈیٹ رکھنے کے لیے ہم اس عمل کو باقاعدگی سے دہراتے رہیں گے۔
نتیجہ خیز چیٹ ترجمہ ماڈل میں تقریباً 1 بلین پیرامیٹرز ہیں۔ اس بڑے ماڈل کے ذریعے ترجمہ چلانا بڑے پیمانے پر پیش کرنے کے لیے ممنوعہ طور پر وسائل کا حامل ہے اور حقیقی وقت کی بات چیت کے لیے بہت زیادہ وقت لگے گا، جہاں 5,000 سے زیادہ چیٹس فی سیکنڈ کو سپورٹ کرنے کے لیے کم تاخیر بہت ضروری ہے۔ لہٰذا ہم نے اس بڑے ترجمے کے ماڈل کو طالب علم-استاد کے انداز میں ایک چھوٹا، ہلکا وزن والا ماڈل بنانے کے لیے استعمال کیا۔ ہم نے ڈسٹلیشن، کوانٹائزیشن، ماڈل کمپلیشن، اور دیگر سرونگ آپٹیمائزیشنز کا اطلاق کیا تاکہ ماڈل کے سائز کو 650 ملین سے کم پیرامیٹرز تک کم کیا جا سکے اور سرونگ کی کارکردگی کو بہتر بنایا جا سکے۔ اس کے علاوہ، ہم نے تجربہ کار ٹیکسٹ چیٹ کے پیچھے API میں ترمیم کی تاکہ اصل اور ترجمہ شدہ دونوں پیغامات اس شخص کے آلے پر بھیج سکیں۔ یہ وصول کنندہ کو ان کی مادری زبان میں پیغام دیکھنے کے قابل بناتا ہے یا بھیجنے والے کے اصل، غیر ترجمہ شدہ پیغام کو دیکھنے کے لیے فوری طور پر سوئچ کر سکتا ہے۔
حتمی LLM تیار ہونے کے بعد، ہم نے ماڈل سرورز سے منسلک ہونے کے لیے بیک اینڈ کو لاگو کیا۔ یہ بیک اینڈ وہ ہے جہاں ہم اضافی چیٹ ٹرانسلیشن منطق کا اطلاق کرتے ہیں اور سسٹم کو اپنے معمول کے اعتماد اور حفاظتی نظام کے ساتھ مربوط کرتے ہیں۔ یہ یقینی بناتا ہے کہ ترجمہ شدہ متن کو دوسرے متن کی طرح جانچ پڑتال کی جاتی ہے، تاکہ ہماری پالیسیوں کی خلاف ورزی کرنے والے الفاظ یا فقروں کا پتہ لگایا جا سکے۔ Roblox میں ہم جو کچھ بھی کرتے ہیں اس میں حفاظت اور تہذیب سب سے آگے ہے، لہذا یہ اس پہیلی کا ایک بہت اہم حصہ تھا۔
درستگی کو مسلسل بہتر بنانا
جانچ میں، ہم نے دیکھا ہے کہ ترجمہ کا یہ نیا نظام ہمارے پلیٹ فارم پر لوگوں کے لیے مضبوط مصروفیت اور سیشن کے معیار کو آگے بڑھاتا ہے۔ ہمارے اپنے میٹرک کی بنیاد پر، ہمارا ماڈل Roblox مواد پر تجارتی ترجمہ APIs سے بہتر کارکردگی کا مظاہرہ کرتا ہے، جس سے ظاہر ہوتا ہے کہ ہم نے کامیابی کے ساتھ اس بات کو بہتر بنایا ہے کہ لوگ Roblox پر کیسے بات چیت کرتے ہیں۔ ہم یہ دیکھ کر پرجوش ہیں کہ یہ پلیٹ فارم پر موجود لوگوں کے تجربے کو کس طرح بہتر بناتا ہے، جس سے ان کے لیے گیمز کھیلنا، خریداری کرنا، تعاون کرنا، یا صرف مختلف زبان بولنے والے دوستوں سے ملاقات کرنا ممکن ہو جاتا ہے۔
لوگوں کی اپنی مادری زبانوں میں بغیر کسی رکاوٹ کے قدرتی گفتگو کرنے کی صلاحیت ہمیں ایک ارب لوگوں کو امید اور تہذیب کے ساتھ جوڑنے کے اپنے ہدف کے قریب لے جاتی ہے۔
اپنے تراجم کی درستگی کو مزید بہتر بنانے اور اپنے ماڈل کو بہتر تربیتی ڈیٹا فراہم کرنے کے لیے، ہم پلیٹ فارم پر موجود لوگوں کو اپنے تراجم پر تاثرات فراہم کرنے اور نظام کو مزید تیزی سے بہتر کرنے میں مدد دینے کے لیے ایک ٹول تیار کرنے کا ارادہ رکھتے ہیں۔ یہ کسی کو ہمیں بتانے کے قابل بنائے گا جب وہ کوئی ایسی چیز دیکھیں جس کا غلط ترجمہ کیا گیا ہو اور یہاں تک کہ ایک بہتر ترجمہ تجویز کیا جائے جسے ہم ماڈل کو مزید بہتر بنانے کے لیے ٹریننگ ڈیٹا میں شامل کر سکتے ہیں۔
یہ ترجمے آج ان تمام 16 زبانوں کے لیے دستیاب ہیں جن کی ہم حمایت کرتے ہیں — لیکن ہم ابھی بہت دور ہیں۔ ہم اپنے ماڈلز کو اپنے تجربات کے اندر سے تازہ ترین ترجمے کی مثالوں کے ساتھ ساتھ مقبول چیٹ کے فقروں اور ہر اس زبان میں تازہ ترین سلینگ فقروں کے ساتھ اپ ڈیٹ کرنے کا ارادہ رکھتے ہیں جن کی ہم حمایت کرتے ہیں۔ اس کے علاوہ، یہ فن تعمیر نسبتاً کم کوشش کے ساتھ نئی زبانوں پر ماڈل کو تربیت دینا ممکن بنائے گا، کیونکہ ان زبانوں کے لیے کافی تربیتی ڈیٹا دستیاب ہو جاتا ہے۔ اس کے علاوہ، ہم خود بخود ہر چیز کا متعدد جہتوں میں ترجمہ کرنے کے طریقے تلاش کر رہے ہیں: تصاویر پر متن، ساخت، 3D ماڈلز وغیرہ۔
اور ہم پہلے سے ہی دلچسپ نئے محاذوں کو تلاش کر رہے ہیں، بشمول خودکار آواز چیٹ ترجمہ. تصور کریں کہ روبلوکس پر ایک فرانسیسی اسپیکر کسی ایسے شخص کے ساتھ وائس چیٹ کرنے کے قابل ہے جو صرف روسی بولتا ہے۔ دونوں اپنی آواز کے لہجے، تال اور جذبات کے مطابق، اپنی زبان میں، اور کم تاخیر پر ایک دوسرے سے بات اور سمجھ سکتے تھے۔ اگرچہ یہ آج سائنس فکشن کی طرح لگ سکتا ہے، اور اسے حاصل کرنے میں کچھ وقت لگے گا، ہم ترجمے کو آگے بڑھاتے رہیں گے۔ بہت دور نہیں مستقبل میں، Roblox ایک ایسی جگہ ہوگی جہاں پوری دنیا کے لوگ بغیر کسی رکاوٹ اور آسانی کے ساتھ نہ صرف ٹیکسٹ چیٹ کے ذریعے، بلکہ ہر ممکن طریقے سے بات چیت کر سکتے ہیں!
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://blog.roblox.com/2024/02/breaking-down-language-barriers-with-a-multilingual-translation-model/
- : ہے
- : ہے
- : نہیں
- :کہاں
- $UP
- 000
- 06
- 08
- 1
- 100
- 11
- 14
- 15٪
- 16
- 22
- 24
- 27
- 35٪
- 39
- 3d
- 5
- 70
- a
- کی صلاحیت
- قابلیت
- درستگی
- درست
- حاصل
- کے پار
- چالو
- فعال
- اصل میں
- شامل کریں
- شامل کیا
- اس کے علاوہ
- ایڈیشنل
- اضافے
- پتہ
- ترقی
- کے بعد
- AI
- تمام
- کی اجازت
- کی اجازت دیتا ہے
- ساتھ
- پہلے ہی
- بھی
- رقم
- an
- اور
- ایک اور
- کوئی بھی
- اے پی آئی
- APIs
- اطلاقی
- کا اطلاق کریں
- نقطہ نظر
- ایپس
- فن تعمیر
- کیا
- ارد گرد
- AS
- پوچھا
- پہلوؤں
- تشخیص کریں
- At
- اداس
- خود کار طریقے سے
- خودکار
- خود کار طریقے سے
- دستیاب
- واپس
- راہ میں حائل رکاوٹیں
- کی بنیاد پر
- بیچنے والا
- BE
- کیونکہ
- ہو جاتا ہے
- رہا
- اس سے پہلے
- شروع ہوا
- پیچھے
- پردے کے پیچھے
- کیا جا رہا ہے
- فائدہ
- بہتر
- کے درمیان
- سے پرے
- ارب
- بلاک
- بلاگ
- دونوں
- توڑ
- لاتا ہے
- تعمیر
- تعمیر
- لیکن
- by
- کیشے
- حساب
- کر سکتے ہیں
- صلاحیت رکھتا
- مقدمات
- پکڑو
- چیلنج
- بلیوں
- چیٹنگ
- چیک کریں
- درجہ بندی کرنا۔
- قریب
- تعاون
- مجموعہ
- تجارتی
- کامن
- ابلاغ
- بات چیت
- موازنہ
- مقابلے میں
- وسیع
- رابطہ قائم کریں
- مربوط
- مواد
- جاری
- بات چیت
- مکالمات
- درست
- سکتا ہے
- ممالک
- تخلیق
- معیار
- اہم
- اس وقت
- اپنی مرضی کے
- روزانہ
- اعداد و شمار
- تاریخ
- دن
- کا پتہ لگانے کے
- آلہ
- مختلف
- طول و عرض
- براہ راست
- دریافت
- ظاہر
- do
- کیا
- نہیں
- نیچے
- ڈرائیوز
- دو
- کے دوران
- متحرک
- e
- ہر ایک
- ہر شخص
- آسانی سے
- کارکردگی
- ہنر
- کوشش
- محنت سے
- یا تو
- سرایت کرنا
- جذبات
- کو چالو کرنے کے
- چالو حالت میں
- کے قابل بناتا ہے
- کو فعال کرنا
- آخر
- مصروفیت
- انگریزی
- کافی
- یقینی بناتا ہے
- پوری
- خرابی
- نقائص
- تخمینہ
- اندازوں کے مطابق
- وغیرہ
- تشخیص
- بھی
- ہر کوئی
- سب کچھ
- مثال کے طور پر
- بہت پرجوش
- دلچسپ
- توسیع
- تجربہ
- تجربات
- ماہر
- ایکسپلور
- حقیقت یہ ہے
- دور
- فاسٹ
- تیز تر
- ممکن
- آراء
- چند
- کم
- افسانے
- فائنل
- پہلا
- توجہ مرکوز
- کے لئے
- سب سے اوپر
- آگے
- فرانسیسی
- دوست
- دوست
- سے
- سرحدوں
- مزید
- مستقبل
- کھیل
- فرق
- پیدا
- جرمن
- ملتا
- حاصل کرنے
- GIF
- دی
- فراہم کرتا ہے
- Go
- مقصد
- گرائمر
- سب سے بڑا
- گراؤنڈ
- گروپ
- بڑھتے ہوئے
- تھا
- ہینڈل
- ہو رہا ہے۔
- ہے
- ہونے
- مدد
- مدد کرتا ہے
- ہائی
- مارنا
- ہوم پیج (-)
- HOURS
- کس طرح
- HTTPS
- انسانی
- i
- if
- تصاویر
- تصور
- عمیق
- عملدرآمد
- اہم
- کو بہتر بنانے کے
- بہتر ہے
- کو بہتر بنانے کے
- in
- شامل
- سمیت
- غلط
- غلط طریقے سے
- اشارہ کرتے ہیں
- ان پٹ
- کے بجائے
- ضم
- بات چیت
- انٹرفیس
- میں
- پوشیدہ
- IT
- جاپانی
- صرف
- رکھیں
- کوریا
- کوریا
- نہیں
- زبان
- زبانیں
- بڑے
- تاخیر
- تازہ ترین
- پرت
- لیڈز
- جانیں
- کم
- سطح
- سطح
- لیوریج
- ہلکا
- کی طرح
- رہتے ہیں
- ایل ایل ایم
- منطق
- Lol
- لانگ
- دیکھو
- لو
- مشین
- مشین ترجمہ
- بنا
- برقرار رکھنے کے
- اہم
- اکثریت
- بنا
- بناتا ہے
- بنانا
- دستی طور پر
- معاملہ
- زیادہ سے زیادہ چوڑائی
- مئی..
- مراد
- پیمائش
- پیغام
- پیغامات
- میٹرک۔
- پیمائش کا معیار
- دس لاکھ
- لاکھوں
- ملیسیکنڈ
- معمولی
- اختلاط
- ML
- ماڈل
- ماڈل
- جدید
- نظر ثانی کی
- زیادہ
- زیادہ موثر
- سب سے زیادہ
- بہت
- ایک سے زیادہ
- مقامی
- قدرتی
- تقریبا
- ضرورت ہے
- ضروریات
- نئی
- نہیں
- اب
- واقع ہو رہا ہے
- of
- on
- ایک
- صرف
- کھول
- اوپن سورس
- رجائیت
- اصلاح کے
- اصلاح
- اصلاح
- or
- حکم
- اصل
- دیگر
- ہمارے
- باہر
- Outperforms
- پر
- خود
- جوڑی
- جوڑے
- متوازی
- پیرامیٹرز
- منظور
- لوگ
- فی
- انسان
- جملے
- جسمانی
- ٹکڑا
- پائپ لائن
- مقام
- منصوبہ
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- کھیلیں
- pm
- پالیسیاں
- مقبول
- پرتگالی
- ممکن
- پیشن گوئی
- بنیادی طور پر
- پرائمری
- عمل
- فراہم
- پش
- پہیلی
- معیار
- کوالٹی ڈیٹا
- جلدی سے
- بہت
- تیار
- اصلی
- اصل وقت
- وجوہات
- پہچانتا ہے
- کو کم
- حوالہ
- حوالہ جات
- باقاعدگی سے
- نسبتا
- جاری
- متعلقہ
- ہٹاتا ہے
- دوبارہ
- درخواست
- ضرورت
- کی ضرورت ہے
- تحقیق
- وسائل سے متعلق
- وسائل
- باقی
- نتیجہ
- نتیجے
- نتائج کی نمائش
- ٹھیک ہے
- Roblox
- لپیٹنا
- تقریبا
- چل رہا ہے
- روسی
- قربانی دینا
- سیفٹی
- اسی
- کا کہنا ہے کہ
- پیمانے
- سکیلنگ
- مناظر
- سائنس
- اشتھانکلپنا
- سکور
- اسکور
- جانچ پڑتال کے
- ہموار
- بغیر کسی رکاوٹ کے
- دوسری
- دیکھنا
- دیکھا
- دیکھتا
- بھیجنے
- سزا
- خدمت
- سرور
- سرورز
- سروس
- خدمت
- اجلاس
- مقرر
- شدت
- دکان
- دکھائیں
- اسی طرح
- مماثلت
- بیک وقت
- بعد
- ایک
- سائز
- چھوٹے
- So
- کچھ
- کسی
- کچھ
- آواز
- ماخذ
- ہسپانوی
- بات
- اسپیکر
- بولی
- مہارت
- خاص
- تیزی
- املا
- مستحکم
- ابھی تک
- حکمت عملی
- مضبوط
- کامیابی کے ساتھ
- کافی
- مشورہ
- نگرانی
- حمایت
- کی حمایت کرتا ہے
- سوئچ کریں
- کے نظام
- سسٹمز
- لے لو
- ہدف
- استاد
- تکنیک
- بتا
- شرائط
- ٹیسٹ
- ٹیسٹنگ
- متن
- تھائی
- سے
- شکریہ
- کہ
- ۔
- ماخذ
- دنیا
- ان
- ان
- تو
- وہاں.
- یہ
- وہ
- سوچو
- اس
- ان
- کے ذریعے
- وقت
- کرنے کے لئے
- آج
- مل کر
- سر
- بھی
- کے آلے
- ٹرین
- تربیت یافتہ
- ٹریننگ
- ترجمہ کریں
- ترجمہ
- ترجمہ
- ترجمہ کا معیار
- ترجمہ
- زبردست
- رجحان سازی
- بھروسہ رکھو
- حقیقت
- ترکی
- دو
- اقسام
- سمجھ
- فہم
- افہام و تفہیم
- سمجھا
- متحد
- منفرد
- اپ ڈیٹ کریں
- us
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- صارفین
- کا استعمال کرتے ہوئے
- ہمیشہ کی طرح
- استعمال
- اس کے برعکس
- بہت
- کی طرف سے
- وائس
- وائس
- چاہتے تھے
- تھا
- راستہ..
- طریقوں
- we
- وزن
- اچھا ہے
- جب
- چاہے
- جس
- جبکہ
- ڈبلیو
- گے
- ونڈو
- ساتھ
- کے اندر
- بغیر
- الفاظ
- دنیا
- گا
- آپ
- اور
- زیفیرنیٹ