تعارف
OpenAI کے ChatGPT کی ریلیز نے بڑے لینگوئج ماڈلز (LLMs) میں کافی دلچسپی پیدا کی ہے، اور اب ہر کوئی مصنوعی ذہانت کے بارے میں بات کر رہا ہے۔ لیکن یہ صرف دوستانہ گفتگو نہیں ہے۔ مشین لرننگ (ML) کمیونٹی نے LLMOps کے نام سے ایک نئی اصطلاح متعارف کرائی ہے۔ ہم سب نے MLOps کے بارے میں سنا ہے، لیکن LLMOps کیا ہے؟ ٹھیک ہے، یہ سب کچھ اس بارے میں ہے کہ ہم ان طاقتور زبان کے ماڈلز کو ان کی زندگی بھر میں کیسے برتاؤ اور ان کا نظم کرتے ہیں۔
LLMs ہمارے AI سے چلنے والی مصنوعات بنانے اور برقرار رکھنے کے طریقے کو تبدیل کر رہے ہیں، اور یہ تبدیلی نئے ٹولز اور بہترین طریقوں کی ضرورت کا باعث بن رہی ہے۔ اس مضمون میں، ہم LLMOps اور اس کے پس منظر کو پگھلا دیں گے۔ ہم یہ بھی جائزہ لیں گے کہ LLMs کے ساتھ AI پروڈکٹس بنانا روایتی ML ماڈلز سے کس طرح مختلف ہے۔ اس کے علاوہ، ہم دیکھیں گے کہ کس طرح MLOps (مشین لرننگ آپریشنز) ان اختلافات کی وجہ سے LLMOps سے مختلف ہیں۔ آخر میں، ہم اس بات پر تبادلہ خیال کریں گے کہ ہم جلد ہی LLMOps کی دنیا میں کن دلچسپ پیشرفت کی توقع کر سکتے ہیں۔
سیکھنے کے مقاصد:
- LLMOps اور اس کی ترقی کے بارے میں اچھی سمجھ حاصل کریں۔
- مثالوں کے ذریعے LLMOps کا استعمال کرتے ہوئے ماڈل بنانا سیکھیں۔
- LLMOps اور MLOps کے درمیان فرق جانیں۔
- LLMOps کے مستقبل میں جھانکیں۔
اس مضمون کے ایک حصے کے طور پر شائع کیا گیا تھا۔ ڈیٹا سائنس بلاگتھون۔
کی میز کے مندرجات
LLMOps کیا ہے؟
LLMOps کا مطلب ہے Large Language Model Operations، MLOps کی طرح لیکن خاص طور پر اس کے لیے ڈیزائن کیا گیا ہے۔ بڑے زبان کے ماڈل (LLMs)۔ اس کے لیے LLM سے چلنے والی ایپلی کیشنز سے متعلق ہر چیز کو سنبھالنے کے لیے نئے ٹولز اور بہترین طریقوں کے استعمال کی ضرورت ہوتی ہے، ترقی سے لے کر تعیناتی اور مسلسل دیکھ بھال تک۔
اسے بہتر طور پر سمجھنے کے لیے، آئیے اس بات کو توڑتے ہیں کہ LLMs اور MLOps کا کیا مطلب ہے:
- ایل ایل ایم زبان کے بڑے ماڈل ہیں جو انسانی زبانیں تیار کر سکتے ہیں۔ ان کے پاس اربوں پیرامیٹرز ہیں اور وہ اربوں ٹیکسٹ ڈیٹا پر تربیت یافتہ ہیں۔
- MLOps (مشین لرننگ آپریشنز) ٹولز اور طریقوں کا ایک مجموعہ ہے جو مشین لرننگ کے ذریعے چلنے والی ایپلیکیشنز کے لائف سائیکل کو منظم کرنے کے لیے استعمال کیا جاتا ہے۔
اب جب کہ ہم نے بنیادی باتوں کی وضاحت کر دی ہے، آئیے اس موضوع پر مزید گہرائی سے غور کریں۔
LLMOps کے ارد گرد ہائپ کیا ہے؟
سب سے پہلے، ایل ایل ایم پسند کرتے ہیں۔ برٹ اور GPT-2 تقریباً 2018 سے موجود ہیں۔ پھر بھی، اب، تقریباً پانچ سال بعد، ہمیں LLMOps کے خیال کے ایک چمکتے ہوئے عروج کا سامنا ہے۔ اس کی بنیادی وجہ یہ ہے کہ LLMs نے دسمبر 2022 میں ChatGPT کی ریلیز کے ساتھ میڈیا کی زیادہ توجہ حاصل کی۔
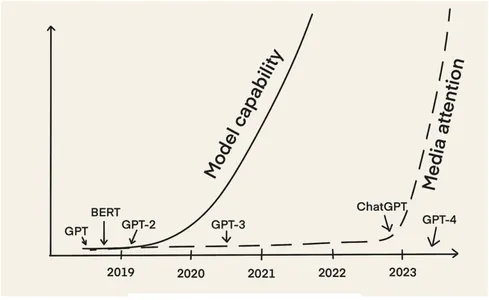
تب سے، ہم نے LLMs کی طاقت کا استحصال کرتے ہوئے بہت سی مختلف قسم کی ایپلی کیشنز دیکھی ہیں۔ اس میں چیٹ بوٹس شامل ہیں جیسے مانوس مثالوں سے لے کر چیٹ جی پی ٹی، ترمیم یا خلاصہ کے لیے مزید ذاتی تحریری معاونین (مثلاً، تصور AI) اور کاپی رائٹنگ کے لیے ہنر مند (مثلاً، یشب اور copy.ai)۔ اس میں کوڈ لکھنے اور ڈیبگ کرنے کے لیے پروگرامنگ اسسٹنٹس بھی شامل ہیں (مثال کے طور پر، گٹ ہب کوپیلٹ)، کوڈ کی جانچ کرنا (مثال کے طور پر، کوڈیم اے آئی)، اور حفاظتی پریشانی کی نشاندہی کرنا (مثال کے طور پر، ساکٹ AI).
بہت سے لوگوں کے ساتھ ایل ایل ایم سے چلنے والی ایپلی کیشنز کو تیار کرنے اور اسے پروڈکشن میں لے جانے کے ساتھ، لوگ اپنے تجربات میں حصہ ڈال رہے ہیں۔
"LLMs کے ساتھ کچھ ٹھنڈا کرنا آسان ہے، لیکن ان کے ساتھ کچھ پروڈکشن کے لیے تیار کرنا بہت مشکل ہے۔" - چپ ہیوین
یہ واضح ہے کہ پروڈکشن کے لیے تیار ایل ایل ایم سے چلنے والی ایپلی کیشنز کی تعمیر اپنی مشکلات کے ساتھ آتی ہے، جو کہ کلاسیکی ML ماڈلز کے ساتھ AI پروڈکٹس بنانے سے الگ ہے۔ ہمیں LLM ایپلیکیشن لائف سائیکل کو چلانے کے لیے ان چیلنجوں سے نمٹنے کے لیے نئے ٹولز اور بہترین طریقے تیار کرنے چاہییں۔ اس طرح، ہم "LLMOps" کی اصطلاح کا وسیع استعمال دیکھتے ہیں۔
LLMOps میں کون سے اقدامات شامل ہیں؟
LLMOps میں شامل اقدامات کم از کم MLOps سے ملتے جلتے ہیں۔ تاہم، فاؤنڈیشن ماڈلز کے آغاز کی وجہ سے ایل ایل ایم سے چلنے والی ایپلیکیشن بنانے کے مراحل مختلف ہیں۔ LLMs کو شروع سے تربیت دینے کے بجائے، پہلے سے تربیت یافتہ LLMs کو مندرجہ ذیل کاموں پر توجہ مرکوز کرنے پر مرکوز ہے۔
پہلے ہی ایک سال پہلے، آندریج کارپاتھی نے بتایا تھا کہ مستقبل میں AI مصنوعات بنانے کا عمل کس طرح بدلے گا:
"لیکن سب سے اہم رجحان یہ ہے کہ کسی ہدف کے کام پر نیورل نیٹ ورک کو شروع سے تربیت دینے کی پوری ترتیب فائن ٹیوننگ کی وجہ سے تیزی سے پرانی ہوتی جارہی ہے، خاص طور پر جی پی ٹی جیسے بیس ماڈلز کے ابھرنے کے ساتھ۔ ان بیس ماڈلز کو کافی کمپیوٹنگ وسائل کے ساتھ صرف چند اداروں کی طرف سے تربیت دی جاتی ہے، اور زیادہ تر ایپلی کیشنز نیٹ ورک کے حصے کی ہلکی پھلکی فائن ٹیوننگ، پرامپٹ انجینئرنگ، یا ڈیٹا یا ماڈل پروسیسنگ کے اختیاری قدم کے ذریعے چھوٹے، خاص مقصد والے انفرنس نیٹ ورکس میں حاصل کیے جاتے ہیں۔ " - اندریج کارپاتھی۔
یہ اقتباس پہلی بار پڑھتے وقت حیران کن ہو سکتا ہے۔ لیکن یہ بالکل ان تمام چیزوں کا خلاصہ کرتا ہے جو حال ہی میں چل رہا ہے، لہذا آئیے اسے درج ذیل ذیلی حصوں میں مرحلہ وار بیان کرتے ہیں۔
مرحلہ 1: ایک بنیادی ماڈل کا انتخاب
فاؤنڈیشن ماڈلز یا بیس ماڈلز LLMs ہیں جو کہ بڑی مقدار میں ڈیٹا پر پہلے سے تربیت یافتہ ہیں جنہیں کاموں کی ایک وسیع رینج کے لیے استعمال کیا جا سکتا ہے۔ چونکہ ایک بنیادی ماڈل کو شروع سے تربیت دینا مشکل، وقت طلب اور انتہائی مہنگا ہے، صرف چند اداروں کے پاس مطلوبہ تربیتی وسائل ہیں۔
اسے تناظر میں رکھنے کے لیے، 2020 میں Lambda Labs کے ایک مطالعے کے مطابق، OpenAI کے GPT-3 (175 بلین پیرامیٹرز کے ساتھ) کی تربیت کے لیے Tesla V355 کلاؤڈ مثال کے استعمال سے 4.6 سال اور 100 ملین ڈالر درکار ہوں گے۔
AI فی الحال اس سے گزر رہا ہے جسے کمیونٹی اپنا "Linux Moment" کہتی ہے۔ فی الحال، ڈویلپرز کو کارکردگی، لاگت، استعمال میں آسانی، اور ملکیتی ماڈلز یا اوپن سورس ماڈلز کی لچک کی بنیاد پر دو قسم کے بیس ماڈلز میں سے انتخاب کرنا ہوتا ہے۔
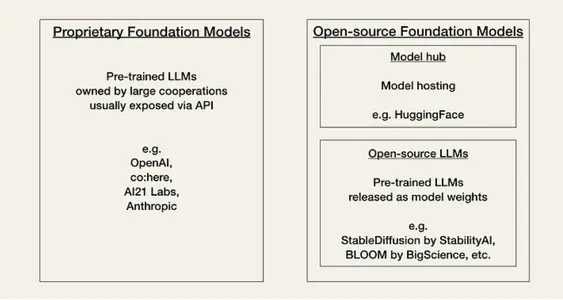
خصوصی یا ملکیتی ماڈل یہ بند سورس فاؤنڈیشن ماڈل ہیں جو بڑی ماہر ٹیموں اور بڑے AI بجٹ والی کمپنیوں کے پاس ہیں۔ وہ عام طور پر اوپن سورس ماڈل سے بڑے ہوتے ہیں اور ان کی کارکردگی بہتر ہوتی ہے۔ وہ بھی خریدے جاتے ہیں اور عام طور پر استعمال میں آسان ہیں۔ ملکیتی ماڈلز کا بنیادی منفی پہلو ان کے مہنگے APIs (ایپلی کیشن پروگرامنگ انٹرفیس) ہیں۔ مزید برآں، بند سورس فاؤنڈیشن ماڈل ڈویلپرز کے لیے موافقت کے لیے کم یا کوئی لچک نہیں پیش کرتے ہیں۔
ملکیتی ماڈل فراہم کنندگان کی مثالیں ہیں:
اوپن سورس ماڈلز اکثر منظم اور میزبانی کی جاتی ہیں۔ گلے لگانے والا چہرہ ایک کمیونٹی ہب کے طور پر۔ عام طور پر، وہ ملکیتی ماڈلز کے مقابلے میں کم صلاحیتوں کے حامل چھوٹے ماڈل ہوتے ہیں۔ لیکن اس کے برعکس، وہ ملکیتی ماڈلز سے زیادہ اقتصادی ہیں اور ڈویلپرز کے لیے زیادہ لچک پیش کرتے ہیں۔
اوپن سورس ماڈلز کی مثالیں ہیں:
کا کوڈ:
اس قدم میں تمام مطلوبہ لائبریریوں کو درآمد کرنا شامل ہے۔
from transformers import GPT2LMHeadModel, GPT2Tokenizer # Can you load pre-trained GPT-3 model and tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")مندرجہ بالا کوڈ کا آؤٹ پٹ:

مرحلہ 2: درج ذیل کاموں کو اپنانا
ایک بار جب آپ اپنا بیس ماڈل منتخب کر لیتے ہیں، تو آپ اس کے API کے ذریعے LLM تک رسائی حاصل کر سکتے ہیں۔ اگر آپ عام طور پر دوسرے APIs کے ساتھ کام کرتے ہیں تو، LLM APIs کے ساتھ کام کرنا بنیادی طور پر تھوڑا سا عجیب محسوس ہوگا کیونکہ یہ ہمیشہ واضح نہیں ہوتا ہے کہ کون سا ان پٹ پہلے آؤٹ پٹ کا سبب بنے گا۔ کسی بھی ٹیکسٹ پرامپٹ کو دیکھتے ہوئے، API آپ کے پیٹرن سے مماثل ہونے کی کوشش کرتے ہوئے، ایک متن کی تکمیل واپس کرے گا۔
یہاں ایک مثال ہے کہ آپ OpenAI API کو کس طرح استعمال کریں گے۔ آپ API ان پٹ کو ایک پرامپٹ کے طور پر دیتے ہیں، مثال کے طور پر، پرامپٹ = "اسے معیاری انگریزی میں درست کریں: nnوہ بازار میں نہیں گیا۔"
import openai
openai.api_key = ...
response = openai.Completion.create( engine = "text-davinci-003", prompt = "Correct this to standard English:nnHe no went to the market.", # ... )API ایک جواب دے گا جس میں تکمیلی جواب['choices'][0]['text'] = "وہ بازار نہیں گیا تھا۔"
اہم چیلنج یہ ہے کہ ایل ایل ایم طاقتور ہونے کے باوجود طاقتور نہیں ہیں، اور اس طرح، اہم سوال یہ ہے کہ: آپ اپنی مطلوبہ آؤٹ پٹ دینے کے لیے ایل ایل ایم کیسے حاصل کرتے ہیں؟
ایل ایل ایم ان پروڈکشن سروے میں ایک تشویش کے جواب دہندگان کا ذکر کیا گیا تھا ماڈل کی درستگی اور فریب کاری۔ اس کا مطلب ہے کہ آپ کے مطلوبہ فارمیٹ میں LLM API سے آؤٹ پٹ حاصل کرنے میں کچھ تکرار لگ سکتی ہے، اور یہ بھی کہ، اگر LLMs کے پاس مطلوبہ مخصوص علم نہیں ہے تو وہ فریب کا شکار ہو سکتے ہیں۔ ان خدشات سے نمٹنے کے لیے، آپ مندرجہ ذیل طریقوں سے بیس ماڈلز کو درج ذیل کاموں کے لیے ڈھال سکتے ہیں۔
- فوری انجینئرنگ ان پٹ کو بہتر بنانے کی ایک تکنیک ہے تاکہ آؤٹ پٹ آپ کی توقعات کے مطابق ہو۔ آپ اپنے پرامپٹ کو بہتر بنانے کے لیے مختلف چالیں استعمال کر سکتے ہیں (دیکھیں۔ اوپن اے آئی کک بک)۔ ایک طریقہ متوقع آؤٹ پٹ فارمیٹ کی کچھ مثالیں فراہم کرنا ہے۔ یہ زیرو شاٹ لرننگ یا چند شاٹ لرننگ کی طرح ہے۔ جیسے اوزار لینگ چین or ہنی ہائیو آپ کے پرامپٹ ٹیمپلیٹس کا نظم کرنے اور ورژن بنانے میں آپ کی مدد کے لیے پہلے سے ہی دستیاب ہیں۔

- عمدہ ٹیوننگ پہلے سے تربیت یافتہ ماڈلز ML میں نظر آنے والی ایک تکنیک ہے۔ یہ آپ کے مخصوص کام پر آپ کے ماڈل کی کارکردگی اور درستگی کو بہتر بنانے میں مدد کر سکتا ہے۔ اگرچہ اس سے تربیتی کوششوں میں اضافہ ہو گا، لیکن اس سے اندازہ لگانے کی لاگت کم ہو سکتی ہے۔ LLM APIs کی لاگت ان پٹ اور آؤٹ پٹ ترتیب کی لمبائی پر منحصر ہے۔ اس طرح، ان پٹ ٹوکنز کی تعداد کو کم کرنے سے API کے اخراجات کم ہوجاتے ہیں کیونکہ اب آپ کو پرامپٹ میں مثالیں دینے کی ضرورت نہیں ہے۔
- بیرونی ڈیٹا: بیس ماڈلز اکثر مختصر سیاق و سباق کی معلومات (مثلاً، کچھ مخصوص دستاویزات تک رسائی) اور تیزی سے پرانے ہو سکتے ہیں۔ مثال کے طور پر، GPT-4 کو ستمبر 2021 تک ڈیٹا پر تربیت دی گئی تھی۔ چونکہ LLMs چیزوں کا تصور کر سکتے ہیں اگر ان کے پاس کافی معلومات نہ ہوں، ہمیں انہیں اہم بیرونی ڈیٹا تک رسائی دینے کے قابل ہونے کی ضرورت ہے۔
- ایمبیڈنگز: قدرے زیادہ پیچیدہ طریقہ یہ ہے کہ LLM APIs (مثلاً پروڈکٹ کی تفصیل) سے ایمبیڈنگز کی شکل میں معلومات نکالیں اور ان کے اوپر ایپلی کیشنز بنائیں (مثلاً، تلاش، موازنہ، سفارشات)۔
- متبادل: چونکہ یہ فیلڈ تیزی سے تیار ہو رہا ہے، AI مصنوعات میں LLMs کی بہت سی مزید ایپلی کیشنز موجود ہیں۔ کچھ مثالیں انسٹرکشن ٹیوننگ/پرامپٹ ٹیوننگ اور ماڈل ریفائننگ ہیں۔
کا کوڈ:
from transformers import GPT2LMHeadModel, GPT2Tokenizer, TextDataset, Trainer, TrainingArguments # Load your dataset
dataset = TextDataset(tokenizer=tokenizer, file_path="your_dataset.txt") # Fine-tune the model
training_args = TrainingArguments( output_dir="./your_fine_tuned_model", overwrite_output_dir=True, num_train_epochs=3, per_device_train_batch_size=4,
) trainer = Trainer( model=model, args=training_args, data_collator=data_collator, train_dataset=dataset,
) trainer.train()
trainer.save_model()مرحلہ 3: ماڈل کی تشخیص
کلاسیکی MLOps میں، ML ماڈلز کو ہولڈ آؤٹ توثیق سیٹ پر ایک میٹرک کے ساتھ دکھایا جاتا ہے جو ماڈلز کی کارکردگی کو ظاہر کرتا ہے۔ لیکن آپ ایل ایل ایم کے عمل کو کیسے جانچتے ہیں؟ آپ کیسے فیصلہ کرتے ہیں کہ آؤٹ پٹ اچھا ہے یا برا؟ فی الحال، ایسا لگتا ہے کہ تنظیمیں A/B اپنے ماڈلز کی جانچ کر رہی ہیں۔
LLMs کی تشخیص میں مدد کے لیے، ہنی ہائیو یا ہیومن لوپ جیسے ٹولز سامنے آئے ہیں۔
کا کوڈ:
from transformers import pipeline # Create a text generation pipeline
generator = pipeline("text-generation", model="your_fine_tuned_model") # Generate text and evaluate
generated_text = generator("Prompt text")
print(generated_text)مرحلہ 4: تعیناتی اور نگرانی
LLMs کی کامیابی ریلیز کے درمیان انتہائی تبدیل ہو سکتی ہے۔ مثال کے طور پر، OpenAI نے اپنے ماڈلز کو اپ ڈیٹ کیا ہے تاکہ نامناسب مواد کی تخلیق، مثلاً نفرت انگیز تقریر کو دور کیا جا سکے۔ نتیجے کے طور پر، ٹویٹر پر "بطور اے آئی لینگویج ماڈل" کے فقرے کو اسکین کرنے سے اب ان گنت بوٹس ظاہر ہوتے ہیں۔
ایل ایل ایم کے ظاہر ہونے کی نگرانی کے لیے پہلے ہی ٹولز موجود ہیں، جیسے Whylabs یا HumanLoop۔
کا کوڈ:
# Import your necessary libraries
from flask import Flask, request, jsonify
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import logging # Initialize Flask app
app = Flask(__name__) # you can load the fine-tuned GPT-2 model and tokenizer
model = GPT2LMHeadModel.from_pretrained("./your_fine_tuned_model")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2") # Set up logging
logging.basicConfig(filename='app.log', level=logging.INFO) # Define a route for text generation
@app.route('/generate_text', methods=['POST'])
def generate_text(): try: data = request.get_json() prompt = data['prompt'] # Generate text generated_text = model.generate( tokenizer.encode(prompt, return_tensors='pt'), max_length=100, # Adjust max length as needed num_return_sequences=1, no_repeat_ngram_size=2, top_k=50, top_p=0.95, )[0] generated_text = tokenizer.decode(generated_text, skip_special_tokens=True) # Log the request and response logging.info(f"Generated text for prompt: {prompt}") logging.info(f"Generated text: {generated_text}") return jsonify({'generated_text': generated_text}) except Exception as e: # Log any exceptions logging.error(f"Error: {str(e)}") return jsonify({'error': 'An error occurred'}), 500 if __name__ == '__main__': app.run(host='0.0.0.0', port=5000)اوپر والے کوڈ کا کام کرنا:
- ضروری لائبریریاں درآمد کریں: اس کا مطلب ہے مطلوبہ لائبریریوں اور ماڈیولز کو درآمد کرنا۔ فلاسک کا استعمال ویب ایپلیکیشنز بنانے کے لیے کیا جاتا ہے، ٹرانسفارمرز کو GPT-2 ماڈل کو لے جانے اور ہینڈل کرنے کے لیے استعمال کیا جاتا ہے، اور لاگنگ کا استعمال معلومات کو ریکارڈ کرنے کے لیے کیا جاتا ہے۔
- فلاسک ایپ کو شروع کریں۔
- ماڈل لوڈ کریں: آپ پہلے سے تربیت یافتہ GPT-2 ماڈل اور متعلقہ ٹوکنائزر لوڈ کر سکتے ہیں۔ آپ انہیں ./your_fine_tuned_model کو اپنے حقیقی فائن ٹیونڈ GPT-2 ماڈل کے راستے سے بدل سکتے ہیں۔
- لاگنگ ترتیب دیں: یہ درخواست میں لاگ ان ہونے کی نشاندہی کرتا ہے۔ یہ لاگ فائل کا نام app.log پر سیٹ کرتا ہے اور لاگنگ لیول کو INFO پر سیٹ کرتا ہے۔
- فلاسک کا استعمال کرتے ہوئے روٹ اسکیچ ترتیب دیں: یہ بتاتا ہے کہ جب POST کی درخواست /generate_text اینڈ پوائنٹ پر کی جاتی ہے تو generate_text فنکشن کو کال کیا جانا چاہیے۔
- متن تیار کرنا: یہ کوڈ آنے والی POST درخواست سے JSON ڈیٹا نکالتا ہے۔ یہ فرض کرتا ہے کہ JSON ڈیٹا میں ایک "پرامپٹ" فیلڈ شامل ہے، جو کہ وہ متن ہے جسے اضافی متن بنانے کے لیے استعمال کیا جائے گا۔
- GPT-2 کا استعمال کرتے ہوئے ٹیکسٹ جنریشن: یہ سیکشن لوڈ شدہ GPT-2 ماڈل اور ٹوکنائزر کا استعمال کرتا ہے تاکہ فراہم کردہ پرامپٹ کی بنیاد پر متن تیار کیا جا سکے۔ یہ مختلف جنریشن پیرامیٹرز سیٹ کرتا ہے، جیسے کہ زیادہ سے زیادہ لمبائی کا جنریٹڈ ٹیکسٹ، جنریٹ کرنے کے لیے سیریز کی تعداد، اور سیمپلنگ پیرامیٹرز۔
- ڈی کوڈنگ اور تیار کردہ متن کو واپس کرنا: متن تیار کرنے کے بعد، یہ تیار کردہ سیریز کو ڈی کوڈ کرتا ہے اور خصوصی ٹوکنز کو ہٹاتا ہے۔ پھر، یہ تیار کردہ متن کو JSON جواب کے طور پر واپس کرتا ہے۔
- درخواست اور جواب کو لاگ کرنا: یہ درخواست کے پرامپٹ اور تیار کردہ متن کو لاگ فائل میں لاگ کرتا ہے۔
- ہینڈلنگ مستثنیات: اگر ٹیکسٹ جنریشن کے عمل کے دوران کوئی استثناء ہوتا ہے، تو وہ کیپچر کیے جاتے ہیں اور غلطیوں کے بطور لاگ ان ہوتے ہیں۔ سرور کی خرابی کو ظاہر کرنے کے لیے 500 اسٹیٹس کوڈ کے ساتھ غلطی کے پیغام کے ساتھ JSON آؤٹ پٹ واپس کیا جاتا ہے۔
- فلاسک ایپ چلانا: یہ یقینی بناتا ہے کہ فلاسک ایپ صرف اس وقت چلائی جائے جب اسکرپٹ کو سیدھے راستے پر چلایا جائے۔ یہ ایپ کو میزبان '0.0.0.0' اور پورٹ 5000 پر چلاتا ہے، جو اسے کسی بھی IP ایڈریس سے آسان بناتا ہے۔
مندرجہ بالا کوڈ کا آؤٹ پٹ:
ان پٹ پرامپٹ:
#{ "prompt": "Once upon a time" } Output prompt: { "generated_text": "Once upon a time, in a faraway land, there lived a..." }import csvLLMOps MLOps سے کیسے مختلف ہے؟
MLOps اور LLMOps کے درمیان فرق اس فرق سے پیدا ہوتا ہے کہ ہم کس طرح کلاسیکل ML ماڈلز بمقابلہ LLMs کے ساتھ AI پروڈکٹس بناتے ہیں۔ اختلافات زیادہ تر ڈیٹا مینجمنٹ، تجربہ، تشخیص، لاگت اور تاخیر کو متاثر کرتے ہیں۔
ڈیٹا مینجمنٹ
معیاری MLOps میں، ہم ڈیٹا بھوکے ML ماڈلز کے عادی ہیں۔ ایک نیورل نیٹ ورک کو شروع سے تربیت دینے کے لیے بہت زیادہ لیبل والے ڈیٹا کی ضرورت ہوتی ہے، اور یہاں تک کہ پہلے سے تربیت یافتہ ماڈل کو ٹھیک کرنے میں کم از کم چند سو نمونے شامل ہوتے ہیں۔ تاہم، ڈیٹا کی صفائی ML کی ترقی کے عمل کے لیے ضروری ہے، جیسا کہ ہم جانتے اور قبول کرتے ہیں کہ بڑے ڈیٹا سیٹس میں نقائص ہیں۔
LLMOps میں، فائن ٹیوننگ MLOps کی طرح ہے۔ لیکن فوری انجینئرنگ ایک زیرو شاٹ یا چند شاٹ سیکھنے کی صورت حال ہے۔ اس کا مطلب ہے کہ ہمارے پاس چند لیکن ہاتھ سے چنے ہوئے نمونے ہیں۔
تجربہ
MLOps میں، تفتیش اسی طرح کی نظر آتی ہے کہ آیا آپ کسی ماڈل کو شروع سے تربیت دیتے ہیں یا پہلے سے تربیت یافتہ ماڈل کو ٹھیک کرتے ہیں۔ دونوں صورتوں میں، آپ ان پٹس کو روٹ کریں گے، جیسے کہ ماڈل آرکیٹیکچر، ہائپر پیرامیٹر، اور ڈیٹا میں اضافہ، اور آؤٹ پٹ، جیسے میٹرکس۔
لیکن LLMOps میں، سوال یہ ہے کہ آیا پرامپٹس کو انجینئر کرنا ہے یا ٹھیک ٹیون کرنا ہے۔ تاہم، فائن ٹیوننگ LLMOps میں MLOps کی طرح نظر آئے گی، جبکہ پرامپٹ انجینئرنگ میں ایک مختلف تجرباتی سیٹ اپ شامل ہوتا ہے جس میں پرامپٹ کا انتظام شامل ہوتا ہے۔
تشخیص
کلاسیکی MLOps میں، ایک تشخیصی میٹرک کے ساتھ ایک ہولڈ آؤٹ توثیق سیٹ ماڈل کی کارکردگی کا اندازہ کرتا ہے۔ چونکہ LLMs کی کارکردگی کا اندازہ لگانا زیادہ مشکل ہے، فی الحال ایسا لگتا ہے کہ تنظیمیں A/B ٹیسٹنگ کا استعمال کر رہی ہیں۔
قیمت
جبکہ روایتی MLOps کی لاگت عام طور پر ڈیٹا اکٹھا کرنے اور ماڈل ٹریننگ میں ہوتی ہے، LLMOps کی لاگت تخمینہ میں ہوتی ہے۔ اگرچہ ہم تجربے کے دوران مہنگے APIs کے استعمال سے کچھ اخراجات کی توقع کر سکتے ہیں، Chip Huyen ظاہر کرتا ہے کہ طویل اشارے کی لاگت کا اندازہ لگایا جاتا ہے۔
رفتار تیز
پروڈکشن سروے میں ایل ایل ایم میں ذکر کردہ ایک اور تشویش والے جواب دہندگان میں تاخیر تھی۔ LLM کی تکمیل کی لمبائی تاخیر کو نمایاں طور پر متاثر کرتی ہے۔ اگرچہ MLOps میں بھی تاخیر کے خدشات موجود ہیں، لیکن وہ LLMOps میں بہت زیادہ نمایاں ہیں کیونکہ یہ ترقی کے دوران تجربہ کی رفتار اور پیداوار میں صارف کے تجربے کے لیے ایک بڑا مسئلہ ہے۔
LLMOps کا مستقبل
LLMOps ایک آنے والا فیلڈ ہے۔ جس رفتار سے یہ خلا تیار ہو رہا ہے، کوئی بھی پیشین گوئی کرنا مشکل ہے۔ یہ بھی مشکوک ہے کہ آیا "LLMOps" کی اصطلاح یہاں باقی ہے۔ ہمیں صرف یقین ہے کہ ہم LLMs اور ٹولز کے استعمال کے بہت سے نئے کیسز اور LLM لائف سائیکل کو منظم کرنے کے لیے بہترین ٹرائلز دیکھیں گے۔
AI کا میدان تیزی سے ترقی کر رہا ہے، ممکنہ طور پر ہم جو کچھ بھی لکھتے ہیں اسے ایک مہینے میں پرانا ہو جاتا ہے۔ ہم ابھی بھی LLM سے چلنے والی ایپلیکیشنز کو پروڈکشن میں لے جانے کے ابتدائی مراحل میں ہیں۔ بہت سے سوالات ہیں جن کے جواب ہمارے پاس نہیں ہیں، اور صرف وقت ہی بتائے گا کہ معاملات کیسے چلیں گے:
- کیا یہاں "LLMOps" کی اصطلاح باقی ہے؟
- MLOps کی روشنی میں LLMOps کیسے تیار ہوں گے؟ کیا وہ ایک ساتھ تبدیل ہو جائیں گے، یا وہ آپریشن کے الگ الگ سیٹ بن جائیں گے؟
- AI کا "Linux Moment" کیسے چلے گا؟
ہم یقین کے ساتھ کہہ سکتے ہیں کہ ہم جلد ہی بہت سی پیشرفت اور نئے اوزار اور بہترین طریقہ کار دیکھیں گے۔ اس کے علاوہ، ہم پہلے سے ہی بیس ماڈلز کے لیے لاگت اور تاخیر میں کمی کے لیے کی جانے والی کوششوں کو دیکھ رہے ہیں۔ یہ یقینی طور پر دلچسپ اوقات ہیں!
نتیجہ
OpenAI کے ChatGPT کے اجراء کے بعد سے، LLMs AI کے میدان میں ایک گرما گرم موضوع بن گئے ہیں۔ یہ گہرے سیکھنے کے ماڈل انسانی زبان میں آؤٹ پٹ پیدا کر سکتے ہیں، جو انہیں بات چیت کے AI، پروگرامنگ اسسٹنٹس، اور تحریری معاون جیسے کاموں کے لیے ایک مضبوط ٹول بنا سکتے ہیں۔
تاہم، ایل ایل ایم سے چلنے والی ایپلی کیشنز کو پروڈکشن میں لے جانا اس کے اپنے چیلنجوں کا ایک مجموعہ پیش کرتا ہے، جس کی وجہ سے ایک نئی اصطلاح، "LLMOps" کی آمد ہوئی ہے۔ اس سے مراد LLM سے چلنے والی ایپلی کیشنز کے لائف سائیکل کو منظم کرنے کے لیے استعمال ہونے والے ٹولز اور بہترین طریقوں کا ہے، بشمول ڈیولپمنٹ، تعیناتی، اور دیکھ بھال۔
LLMOps کو MLOps کے ذیلی زمرے کے طور پر دیکھا جا سکتا ہے۔ تاہم، ایل ایل ایم سے چلنے والی ایپلیکیشن کی تعمیر میں شامل اقدامات بیس ایم ایل ماڈلز کے ساتھ ایپلی کیشنز بنانے کے اقدامات سے مختلف ہیں۔ LLM کو شروع سے تربیت دینے کے بجائے، پہلے سے تربیت یافتہ LLMs کو درج ذیل کاموں کے لیے ڈھالنے پر توجہ دی جاتی ہے۔ اس میں فاؤنڈیشن ماڈل کا انتخاب، درج ذیل کاموں میں LLMs کا استعمال، ان کا جائزہ لینا، اور ماڈل کی تعیناتی اور نگرانی شامل ہے۔ اگرچہ LLMOps اب بھی ایک نسبتاً نیا فیلڈ ہے، لیکن یہ یقینی ہے کہ یہ ترقی اور ارتقاء جاری رکھے گا کیونکہ LLMs AI صنعت میں زیادہ مقبول ہو رہے ہیں۔
کلیدی لوازمات:
- LLMOps (Large Language Model Operations) ایک سائنسی شعبہ ہے جو ChatGPT جیسے طاقتور زبان کے ماڈلز کے لائف سائیکل کو منظم کرنے، AI سے چلنے والی مصنوعات کی تخلیق اور دیکھ بھال کو تبدیل کرنے پر مرکوز ہے۔
- GPT-3، GPT-3.5، اور GPT-4 جیسے بڑے لینگویج ماڈلز (LLMs) کا استعمال کرنے والی ایپلی کیشنز میں اضافہ LLMOps کے عروج کا باعث بنا ہے۔
- LLMOps کے عمل میں ایک بیس ماڈل کا انتخاب، اسے مخصوص کاموں میں ڈھالنا، A/B ٹیسٹنگ کے ذریعے ماڈل کی کارکردگی کا جائزہ لینا، اور LLM سے چلنے والی ایپلی کیشنز سے وابستہ لاگت اور تاخیر سے ہونے والی پریشانی سے آگاہ کرنا شامل ہے۔
- LLMOps ڈیٹا مینجمنٹ (چند شاٹ لرننگ)، امتحان (پرامپٹ انجینئرنگ)، تشخیص (A/B ٹیسٹنگ)، لاگت (تخصیص سے متعلقہ اخراجات)، اور رفتار (دیر سے عکاسی) کے لحاظ سے روایتی MLOps سے مختلف ہیں۔
مجموعی طور پر، LLMs اور LLMOps کا اضافہ AI سے چلنے والی مصنوعات کی تعمیر اور دیکھ بھال میں ایک اہم تبدیلی کو بیان کرتا ہے۔ مجھے امید ہے کہ آپ کو یہ مضمون پسند آیا ہوگا۔ آپ یہاں مجھ سے رابطہ کر سکتے ہیں۔ لنکڈ.
اکثر پوچھے گئے سوالات
جواب بڑے لینگویج ماڈلز (LLMs) انسانی زبانوں پر کام کرنے کے لیے گہری سیکھنے کے ماڈلز میں حالیہ بہتری ہیں۔ ایک بڑی زبان کا ماڈل ایک تربیت یافتہ گہری سیکھنے والا ماڈل ہے جو انسان کی طرح کے انداز میں متن کو سمجھتا اور تخلیق کرتا ہے۔ پردے کے پیچھے، ایک بڑے ٹرانسفارمر ماڈل نے سارا جادو کر دیا۔
جواب LLMOps میں جن اہم اقدامات کی پیروی کی جاتی ہے وہ ہیں:
1. اپنی درخواست کی بنیاد کے طور پر پہلے سے تربیت یافتہ بڑی زبان کا ماڈل منتخب کریں۔
2. پرامپٹ انجینئرنگ اور فائن ٹیوننگ جیسی تکنیکوں کا استعمال کرتے ہوئے خاص کاموں کے لیے ایل ایل ایم میں ترمیم کریں۔
3. A/B ٹیسٹنگ اور ہنی ہائیو جیسے ٹولز کے ذریعے اکثر LLM کی کارکردگی کا اندازہ لگائیں۔
4. ایل ایل ایم سے چلنے والی ایپلیکیشن کو تعینات کریں، اس کی کارکردگی کی مسلسل نگرانی کریں، اور اسے ہموار کریں۔
اس مضمون میں دکھایا گیا میڈیا Analytics ودھیا کی ملکیت نہیں ہے اور مصنف کی صوابدید پر استعمال ہوتا ہے۔
متعلقہ
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.analyticsvidhya.com/blog/2023/09/llmops-for-machine-learning-engineering/
- : ہے
- : ہے
- : نہیں
- $UP
- 1
- 10
- 11
- 12
- 2018
- 2020
- 2021
- 2022
- 500
- 5000
- 7
- a
- قابلیت
- ہمارے بارے میں
- اوپر
- قبول کریں
- تک رسائی حاصل
- کے مطابق
- درستگی
- حاصل کیا
- کامیابی
- اپنانے
- موافقت
- اپنانے
- ایڈیشنل
- اس کے علاوہ
- پتہ
- ایڈجسٹ
- پر اثر انداز
- اثر انداز ہوتا ہے
- کے بعد
- پہلے
- AI
- اے آئی ماڈلز
- AI سے چلنے والا
- تمام
- تقریبا
- ساتھ
- پہلے ہی
- بھی
- اگرچہ
- ہمیشہ
- مقدار
- an
- تجزیاتی
- تجزیات ودھیا
- اور
- جواب
- بے چینی
- کوئی بھی
- کچھ
- اے پی آئی
- APIs
- اپلی کیشن
- ظاہر ہوتا ہے
- درخواست
- ایپلی کیشنز
- فن تعمیر
- کیا
- اٹھتا
- ارد گرد
- آمد
- مضمون
- مصنوعی
- مصنوعی ذہانت
- AS
- پوچھا
- اسسٹنٹ
- منسلک
- فرض کرتا ہے
- At
- کوشش کرنا
- توجہ
- دستیاب
- پس منظر
- برا
- بیس
- کی بنیاد پر
- مبادیات
- BE
- کیونکہ
- بن
- بننے
- رہا
- ابتدائی
- شروع
- پیچھے
- پردے کے پیچھے
- کیا جا رہا ہے
- BEST
- بہترین طریقوں
- بہتر
- کے درمیان
- بگ
- ارب
- اربوں
- بلاگتھون
- دونوں
- خودکار صارف دکھا ئیں
- خریدا
- توڑ
- بجٹ
- تعمیر
- عمارت
- لیکن
- by
- کہا جاتا ہے
- کالز
- کر سکتے ہیں
- صلاحیتوں
- پر قبضہ کر لیا
- لے جانے کے
- لے جانے والا۔
- مقدمات
- کیونکہ
- یقین
- چیلنج
- چیلنجوں
- تبدیل
- چیٹ بٹس
- چیٹ جی پی ٹی
- چپ
- میں سے انتخاب کریں
- منتخب کیا
- حالات
- صفائی
- واضح
- بادل
- کوڈ
- مجموعہ
- آتا ہے
- کمیونٹی
- کمپنیاں
- موازنہ
- تکمیل
- پیچیدہ
- کمپیوٹنگ
- اندیشہ
- اندراج
- رابطہ قائم کریں
- مواد
- متعلقہ
- جاری
- جاری
- مسلسل
- تعاون کرنا
- آسان
- سنوادی
- بات چیت AI
- مکالمات
- تبدیل کرنا
- ٹھنڈی
- copywriting
- درست
- اسی کے مطابق
- قیمت
- اخراجات
- بے شمار
- تخلیق
- مخلوق
- اس وقت
- اعداد و شمار
- ڈیٹا مینجمنٹ
- ڈیٹاسیٹس
- نمٹنے کے
- دسمبر
- فیصلہ کرنا
- کمی
- گہری
- گہری سیکھنے
- وضاحت
- ضرور
- demonstrated,en
- اشارہ کرتا ہے
- انحصار
- تعیناتی
- تعینات
- تعیناتی
- بیان
- ڈیزائن
- مطلوبہ
- کے باوجود
- ترقی
- ڈویلپرز
- ترقی
- ترقی
- رفت
- DID
- اختلافات
- مختلف
- مشکل
- مشکلات
- صوابدید
- بات چیت
- مختلف
- ڈوبکی
- do
- دستاویزات
- کرتا
- نہیں
- شکایات
- نیچے
- نیچے کی طرف
- دو
- کے دوران
- e
- اس سے قبل
- ابتدائی
- کو کم
- استعمال میں آسانی
- آسان
- کوششوں
- ابھرتی ہوئی
- خروج
- مقابلہ کرنا
- اختتام پوائنٹ
- انجن
- انجینئر
- انجنیئرنگ
- انگریزی
- یقینی بناتا ہے
- خرابی
- نقائص
- خاص طور پر
- ضروری
- تخمینہ
- Ether (ETH)
- اندازہ
- کا جائزہ لینے
- تشخیص
- بھی
- سب
- سب کچھ
- تیار
- تیار ہوتا ہے
- بالکل
- امتحان
- جانچ پڑتال
- مثال کے طور پر
- مثال کے طور پر
- اس کے علاوہ
- رعایت
- ایکسچینج
- دلچسپ
- پھانسی
- پھانسی
- وجود
- توسیع
- توقع ہے
- توقعات
- توقع
- مہنگی
- تجربہ
- تجربات
- ماہر
- وضاحت کی
- استحصال کرنا
- بیرونی
- نکالنے
- نچوڑ۔
- انتہائی
- واقف
- فیشن
- محسوس
- چند
- میدان
- فائل
- آخر
- آخر
- پہلا
- پہلی بار
- پانچ
- چمکتا
- لچک
- توجہ مرکوز
- توجہ مرکوز
- پیچھے پیچھے
- کے بعد
- کے لئے
- فارم
- فارمیٹ
- فاؤنڈیشن
- اکثر
- دوستانہ
- سے
- تقریب
- مستقبل
- عام طور پر
- پیدا
- پیدا
- پیدا ہوتا ہے
- پیدا کرنے والے
- نسل
- جنریٹر
- حاصل
- حاصل کرنے
- دے دو
- دی
- Go
- جا
- اچھا
- گوگل
- بڑھتے ہوئے
- رہنمائی
- ہینڈل
- ہارڈ
- نفرت
- نفرت انگیز تقریر
- ہے
- سنا
- مدد
- یہاں
- امید ہے کہ
- میزبان
- میزبانی کی
- HOT
- کس طرح
- تاہم
- HTTPS
- حب
- انسانی
- سو
- ہائپ
- i
- خیال
- کی نشاندہی
- if
- تصور
- درآمد
- اہم
- درآمد
- کو بہتر بنانے کے
- بہتری
- in
- شامل ہیں
- سمیت
- موصولہ
- اضافہ
- صنعت
- معلومات
- معلومات
- ان پٹ
- آدانوں
- متاثر
- مثال کے طور پر
- کے بجائے
- اداروں
- انٹیلی جنس
- دلچسپی
- دلچسپ
- انٹرفیسز
- میں
- متعارف
- تحقیقات
- ملوث
- شامل ہے
- شامل
- IP
- IP ایڈریس
- مسئلہ
- IT
- تکرار
- میں
- JSON
- صرف
- کلیدی
- جان
- علم
- لیبز
- لینڈ
- زبان
- زبانیں
- بڑے
- بڑے
- حال ہی میں
- تاخیر
- بعد
- معروف
- سیکھنے
- کم سے کم
- قیادت
- لمبائی
- کم
- سطح
- لائبریریوں
- جھوٹ ہے
- زندگی کا دورانیہ
- روشنی
- ہلکا پھلکا
- کی طرح
- لنکڈ
- تھوڑا
- لوڈ
- لاگ ان کریں
- انکرنا
- لاگ ان
- لانگ
- اب
- دیکھو
- تلاش
- دیکھنا
- بہت
- کم
- مشین
- مشین لرننگ
- بنا
- ماجک
- مین
- برقرار رکھنے کے
- برقرار رکھنے
- دیکھ بھال
- بنا
- بنانا
- انتظام
- انتظام
- مینیجنگ
- بہت سے
- بہت سے لوگ
- مارکیٹ
- میچ
- میکس
- زیادہ سے زیادہ
- مئی..
- me
- مطلب
- کا مطلب ہے کہ
- میڈیا
- ذکر کیا
- پیغام
- طریقہ
- میٹرک۔
- پیمائش کا معیار
- شاید
- طاقتور
- دس لاکھ
- ML
- ایم ایل اوپس
- ماڈل
- ماڈل
- نظر ثانی کرنے
- ماڈیولز
- لمحہ
- کی نگرانی
- نگرانی
- مہینہ
- زیادہ
- سب سے زیادہ
- زیادہ تر
- بہت
- ضروری
- نام
- ضروری
- ضرورت ہے
- ضرورت
- ضروریات
- نیٹ ورک
- نیٹ ورک
- عصبی
- عصبی نیٹ ورک
- نئی
- نہیں
- تصور
- اب
- تعداد
- مقاصد
- حاصل کی
- واقع
- ہوا
- of
- پیش کرتے ہیں
- اکثر
- on
- ایک بار
- ایک
- والوں
- صرف
- اوپن سورس
- اوپنائی
- آپریشنز
- or
- تنظیمیں
- منظم
- دیگر
- باہر
- پیداوار
- پر
- خود
- ملکیت
- پیرامیٹرز
- حصہ
- خاص طور پر
- راستہ
- پاٹرن
- لوگ
- کارکردگی
- ذاتی
- نقطہ نظر
- پائپ لائن
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- کھیلیں
- علاوہ
- مقبول
- پوسٹ
- ممکنہ طور پر
- طاقت
- طاقت
- طاقتور
- طریقوں
- پیشن گوئی
- تحفہ
- بنیادی طور پر
- عمل
- پروسیسنگ
- مصنوعات
- پیداوار
- حاصل
- پروگرامنگ
- ممتاز
- ملکیت
- فراہم
- فراہم
- فراہم کرنے والے
- شائع
- ڈال
- سوال
- سوالات
- جلدی سے
- اقتباس
- رینج
- لے کر
- میں تیزی سے
- بلکہ
- پڑھیں
- اصلی
- وجہ
- حال ہی میں
- سفارشات
- ریکارڈ
- کم
- کمی
- مراد
- ادائیگی
- عکاسی
- متعلقہ
- نسبتا
- جاری
- ریلیز
- کی جگہ
- جواب
- درخواست
- کی ضرورت
- ضرورت
- کی ضرورت ہے
- وسائل
- جواب دہندگان
- جواب
- نتیجہ
- واپسی
- واپس لوٹنے
- واپسی
- پتہ چلتا
- اضافہ
- روٹ
- رن
- چلتا ہے
- کا کہنا ہے کہ
- سکیننگ
- مناظر
- سائنس
- سائنسی
- فیرنا
- اسکرپٹ
- تلاش کریں
- سیکشن
- سیکورٹی
- دیکھنا
- لگتا ہے
- لگتا ہے
- دیکھا
- منتخب
- انتخاب
- علیحدہ
- ستمبر
- تسلسل
- سیریز
- سرور
- مقرر
- سیٹ
- قائم کرنے
- سیٹ اپ
- منتقل
- مختصر
- جلد ہی
- ہونا چاہئے
- دکھایا گیا
- شوز
- اہم
- نمایاں طور پر
- اسی طرح
- بعد
- ہنر مند
- چھوٹے
- چپکے سے
- So
- کچھ
- کچھ
- اسی طرح
- آواز
- خلا
- خصوصی
- مخصوص
- خاص طور پر
- تقریر
- تیزی
- مراحل
- معیار
- کھڑا ہے
- درجہ
- رہنا
- مرحلہ
- مراحل
- ابھی تک
- کارگر
- مضبوط
- مطالعہ
- شاندار
- کافی
- اس طرح
- کافی
- اس بات کا یقین
- سروے
- لے لو
- Takeaways
- بات کر
- ہدف
- ٹاسک
- کاموں
- ٹیموں
- تکنیک
- بتا
- سانچے
- اصطلاح
- شرائط
- Tesla
- ٹیسٹنگ
- متن
- متن کی نسل
- سے
- کہ
- ۔
- مبادیات
- مستقبل
- کے بارے میں معلومات
- دنیا
- ان
- ان
- تو
- وہاں.
- یہ
- وہ
- چیزیں
- اس
- ان
- کے ذریعے
- بھر میں
- اس طرح
- وقت
- وقت لگتا
- کرنے کے لئے
- مل کر
- ٹوکن
- بتایا
- کے آلے
- اوزار
- سب سے اوپر
- موضوع
- کی طرف
- روایتی
- ٹرین
- تربیت یافتہ
- ٹریننگ
- تبدیل
- ٹرانسفارمر
- ٹرانسفارمرز
- تبدیل
- نقل و حمل
- علاج
- رجحان
- ٹرائلز
- چالوں
- مصیبت
- کوشش
- ٹویٹر
- دو
- اقسام
- سمجھ
- افہام و تفہیم
- سمجھتا ہے۔
- جب تک
- آئندہ
- اپ ڈیٹ
- صلی اللہ علیہ وسلم
- الٹا
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- رکن کا
- صارف کا تجربہ
- استعمال
- کا استعمال کرتے ہوئے
- عام طور پر
- استعمال کرنا۔
- توثیق
- VeloCity
- ورژن
- بنام
- بہت
- کی طرف سے
- vs
- چاہتے ہیں
- تھا
- راستہ..
- طریقوں
- we
- ویب
- ویب ایپلی کیشنز
- ویبپی
- اچھا ہے
- چلا گیا
- کیا
- کیا ہے
- جب
- چاہے
- جس
- جبکہ
- پوری
- وسیع
- وسیع رینج
- گے
- ساتھ
- کام
- کام کر
- دنیا
- گا
- لکھنا
- تحریری طور پر
- سال
- سال
- ابھی
- آپ
- اور
- زیفیرنیٹ
- زیرو شاٹ لرننگ