ABBYY ایک عالمی ٹیکنالوجی کمپنی ہے جو دستاویز کی پروسیسنگ، ڈیٹا کیپچر، اور زبان پر مبنی ٹیکنالوجیز کے حل فراہم کرتی ہے۔ اس کی بنیاد 1989 میں ماسکو اسٹیٹ یونیورسٹی کے ماہرین لسانیات اور انجینئروں کے ایک گروپ نے رکھی تھی۔ کمپنی کا نام "ایڈوانسڈ بزنس کمپیوٹر سسٹمز" کا مخفف ہے۔
ABBYY کی پہلی مصنوعات مختلف مارکیٹوں کے لیے لغات اور لسانی سافٹ ویئر تھیں۔ 1990 کی دہائی میں، ABBYY نے آپٹیکل کریکٹر ریکگنیشن (OCR) اور دستاویز سکیننگ ایپس کو شامل کرنے کے لیے اپنی پروڈکٹ لائن کو بڑھایا۔ ABBYY کی PDF مصنوعات مارکیٹ میں سب سے زیادہ مقبول ہیں۔ 100 ملین سے زیادہ لوگ ہر روز ABBYY PDF مصنوعات استعمال کرتے ہیں۔ کمپنی درست، قابل اعتماد، اور صارف دوست حل فراہم کرنے کی کوشش کرتی ہے جسے افراد سے لے کر بڑی تنظیموں تک ہر کوئی استعمال کر سکتا ہے۔
یہ بلاگ پوسٹ ان کی پروڈکٹ لائن کا جائزہ لے گی اور ساتھ کام کرنے کے کچھ فوائد / نقصانات۔ ہم ان کی کچھ مصنوعات کا موازنہ اس صنعت میں دیگر اعلیٰ درجے کی کمپنیوں کی طرف سے پیش کردہ مصنوعات سے بھی کریں گے تاکہ آپ فیصلہ کر سکیں کہ آیا وہ آپ کی ضروریات کے لیے موزوں ہوں گی۔
چلتے ہیں.
ABBYY کیا حل پیش کرتا ہے؟
ABBYY OCR اور PDF کنورژن اور ایڈیٹنگ سافٹ ویئر کی ایک مکمل رینج پیش کرتا ہے جو استعمال میں آسان اور قابل اعتماد ہے۔ ان کی مصنوعات صارفین کو دستاویزات کو قابل تلاش پی ڈی ایف میں تبدیل کرنے، پی ڈی ایف میں ترمیم کرنے اور فارم اور ٹیبلز سے ڈیٹا نکالنے کی اجازت دیتی ہیں۔ کمپنی iOS اور اینڈرائیڈ ڈیوائسز کے لیے ایک موبائل ایپ بھی پیش کرتی ہے جو صارفین کو کاغذی دستاویزات کو اسکین کرنے اور ڈیجیٹل فارمیٹس میں تبدیل کرنے کی اجازت دیتی ہے۔ اس سیکشن میں، ہم ان کی فراہم کردہ مختلف خدمات کو دریافت کریں گے۔
ABBYY Vantage
ABBYY Vantage ایک دستاویز کے انتظام کا حل ہے جو آپ کو سمارٹ الگورتھم اور مصنوعی ذہانت کی مدد سے اپنے کاروباری عمل کو خودکار کرنے کی اجازت دیتا ہے۔ آپ مختلف دستاویزات سے ڈیٹا کو تبدیل کرنے، تشریح کرنے، عمل کرنے اور نکالنے کے لیے اس ٹول کا استعمال کرکے اپنے ورک فلو کی کارکردگی کو بہتر بنا سکتے ہیں۔ یہ ٹول آپ کو دستاویزات کی درجہ بندی، اشاریہ سازی اور تلاش جیسے مختلف مقاصد کے لیے OCR ٹیکنالوجی استعمال کرنے کی بھی اجازت دیتا ہے۔ ABBYY Vantage کمپنیوں کو رجحانات کو ٹریک کرنے اور ان کے کاروبار کے بارے میں نئی بصیرتیں حاصل کرنے میں مدد کرنے کے لیے ڈیٹا اینالیٹکس کی صلاحیتیں بھی پیش کرتا ہے۔
ABBYY ٹائم لائن
ABBYY ٹائم لائن غیر ساختہ ٹیکسٹ دستاویزات جیسے نیوز آرٹیکلز یا ای میلز سے تاریخی واقعات کو دیکھنے کے لیے ایک ایپلی کیشن ہے۔ یہ ٹول صارفین کو یہ دیکھنے کی اجازت دیتا ہے کہ تصورات کیسے تیار ہوتے ہیں اور وقت کے ساتھ رجحانات میں پیٹرن کی شناخت کرتے ہیں۔ بنیادی طور پر، یہ ایپلیکیشن ٹیکسٹ دستاویزات سے واقعات کی شناخت کے لیے قدرتی زبان کی پروسیسنگ تکنیک کا استعمال کرتی ہے اور پھر ان واقعات کو ایونٹ کی قسم کی بنیاد پر ٹائم لائنز میں گروپ کرتی ہے۔
ABBYY FlexiCapture
ABBYY FlexiCapture ایک سافٹ ویئر سوٹ ہے جو تنظیموں کو کاغذی شکلوں سے کلیدی فیلڈز کو ان کے ڈیٹا بیس یا CRM سسٹم میں خودکار طور پر حاصل کرنے میں مدد کرتا ہے۔ یہ ٹول آسانی سے مختلف شکلوں سے ڈیٹا نکال سکتا ہے، بشمول انوائس، پرچیز آرڈر، بینک اسٹیٹمنٹ، انشورنس کلیمز وغیرہ۔
انوائسز کے لیے ABBYY FlexiCapture
ABBYY FlexiCapture for Invoices کو انوائس پروسیسنگ کے کاموں کو خودکار بنا کر کاروباروں کو ان کے انوائس مینجمنٹ کے عمل کو ہموار کرنے میں مدد کرنے کے لیے ڈیزائن کیا گیا ہے۔ یہ حل آپ کو اپنے اندرونی ڈیٹا بیس سے اضافی معلومات کے ساتھ انوائسز سے ڈیٹا کو خود بخود نکال کر، معیاری بنا کر اور اپنی ضروریات کے مطابق حسب ضرورت رپورٹس بنا کر وقت بچانے کی اجازت دیتا ہے۔
ABBYY فائن ریڈر سرور
ABBYY FineReader سرور سرور کی طرف سے خودکار دستاویز کی تبدیلی، اشاریہ سازی، اور بازیافت کے لیے ایک حل ہے۔ یہ OCR (آپٹیکل کریکٹر ریکگنیشن) ٹیکنالوجی کا استعمال کرتے ہوئے اسکین شدہ دستاویزات کو اصل وقت میں قابل تدوین فارمیٹس میں تبدیل کرتا ہے، اس طرح صارفین کو ضرورت کے مطابق ان میں ترمیم اور دوبارہ استعمال کرنے کی اجازت ملتی ہے۔ یہ حل جدید خصوصیات بھی پیش کرتا ہے جیسے تلاش کی اہلیت کے لیے عمدہ اشاریہ سازی اور دوسروں کے درمیان مواد کے ڈھانچے کی بہتر تفہیم کے لیے دستاویز کا بہتر تجزیہ۔
ABBYY کے انٹرپرائز حل SDKs اور ڈویلپر ٹولز کے ذریعے مختلف سسٹمز کے ساتھ ضم کرنے کے لیے دستیاب ہیں۔
ABBYY FlexiCapture اور ABBYY FineReader دو مقبول ترین خدمات ہیں جو ABBYY کی طرف سے پیش کی جاتی ہیں۔ آئیے قریب سے دیکھیں۔
ABBYY FlexiCapture میں ABBYY FineReader Server (پہلے Recognition Server کے نام سے برانڈڈ) کے ساتھ بہت سے افعال مشترک ہیں۔ تاہم، ہر پروڈکٹ کو منفرد فنکشنز کے ساتھ ڈیزائن کیا گیا ہے، جن پر کمپنیوں کو اپنے دستاویز کی گرفتاری اور OCR کی ضروریات کے حل کا جائزہ لیتے وقت غور کرنا چاہیے۔ مصنوعات کا زیادہ آسانی سے موازنہ کرنے میں آپ کی مدد کرنے کے لیے، ہم نے استعمال کے معاملات کی ایک فہرست مرتب کی ہے جو آپ کو ABBYY FlexiCapture اور FineReader سرور کے درمیان اندازہ لگانے کی اجازت دے گی۔
ایک ذہین ٹیکسٹ ریکگنیشن حل تلاش کر رہے ہیں؟ کی طرف بڑھیں۔ نانونٹس اور 95% سے زیادہ درستگی کے ساتھ حل کا استعمال کریں۔
ABBYY Finereader OCR کے کاروباری استعمال کے معاملات کیا ہیں؟
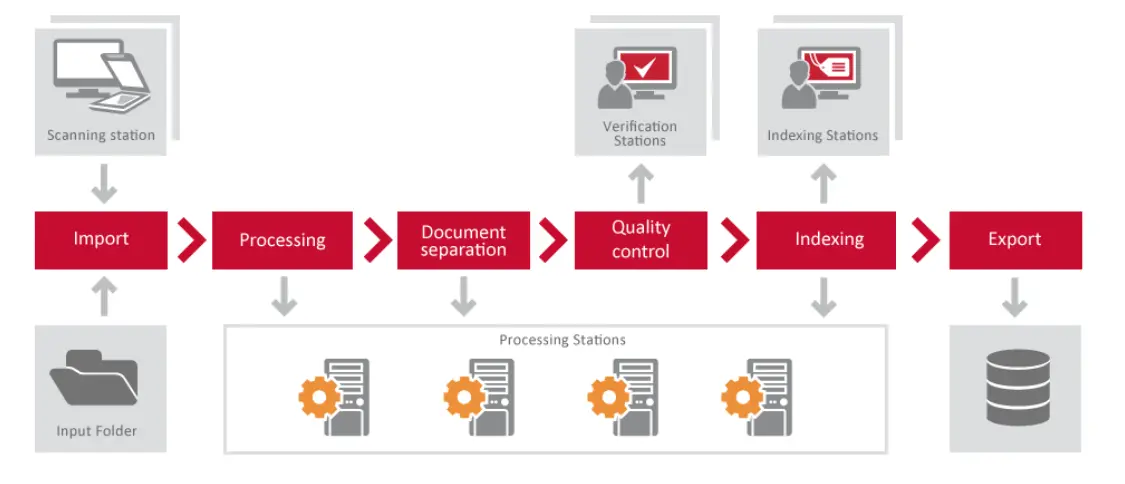
ABBYY FineReader Server ایک دستاویزی تبدیلی کا پروگرام ہے جو دستاویزات اور تصاویر کو تلاش کے قابل فارمیٹس میں تبدیل کرنے کے لیے استعمال کیا جاتا ہے۔ یہ پروگرام ایک سرور پر کام کرتا ہے، جس سے کمپنی کے پروسیسنگ ٹائم فریم کے اندر دستاویزات کی بڑے پیمانے پر تبدیلی ممکن ہوتی ہے۔ یہ کمپنیوں کو کاغذی دستاویزات کو اسکین کرنے یا الیکٹرانک فائلوں اور تصاویر پر کارروائی کرنے کے ذریعے، پورے انٹرپرائز میں دستاویزات کو حاصل کرنے اور دستی طور پر انڈیکس کرنے کے لیے ایک سرمایہ کاری مؤثر ذریعہ بھی فراہم کر سکتا ہے۔ تاہم، ایک خرابی یہ ہے کہ یہ ہینڈ رائٹنگ یا چیک مارک کی اقدار کی تبدیلی کے لیے فراہم نہیں کرتا ہے [1]۔
نیچے دی گئی تصویر میں، آپ FineReader سرور کے اجزاء کے درمیان تعلق دیکھ سکتے ہیں۔
کچھ عام استعمال کے معاملات
بلک پروسیسنگ
نیٹ ورک پر مشترکہ فولڈرز کی نگرانی کریں اور تصاویر یا دستاویزات سے امیج ٹو ٹیکسٹ پی ڈی ایف کنورژن کریں۔ جب ایک نئی فائل کو فولڈر میں شامل کیا جاتا ہے، تو اسے ٹیکسٹ کے قابل تلاش ورژن میں تبدیل کر دیا جاتا ہے اور پھر اصل ذیلی فولڈر کے عہدہ کو برقرار رکھتے ہوئے متعلقہ برآمدی فولڈر میں منتقل کر دیا جاتا ہے۔ برآمدی فائل اصل تصویری فائل کی قانونی سالمیت کو برقرار رکھے گی جبکہ برآمدی فولڈرز میں پی ڈی ایف فائل میں تصویر کے پیچھے تلاش کے قابل ٹیکسٹ لیئر کو شامل کرے گی۔
دستاویز کی اسکیننگ
جب آپ دستاویزات کو ڈیجیٹل فارمیٹ میں اسکین کرتے ہیں، تو آپ کو ان دستاویزات سے متن کو دوسری دستاویزات میں کاپی اور پیسٹ کرنے کے قابل ہونے کا اضافی فائدہ ملتا ہے۔ تاہم، اگر کوئی OCR سافٹ ویئر دستیاب نہیں ہے تو آپ کو متن کو دستی طور پر دوبارہ ٹائپ کرنا ہوگا۔ ایسا کرنے میں جو وقت لگتا ہے وہ اہم ہو سکتا ہے۔ فائن ریڈر او سی آر صارفین کو اسکین شدہ تصاویر کو تیزی سے قابل تدوین ٹیکسٹ فائلوں میں تبدیل کرنے کی اجازت دیتا ہے جن تک آسانی سے رسائی اور دیگر ایپلی کیشنز، جیسے کہ ورڈ یا ایکسل میں ہیرا پھیری کی جا سکتی ہے۔ فیکس کے لیے بھی ایسا ہی ہے، جو اکثر TIFF فارمیٹ میں موصول ہوتے ہیں اور ترمیم یا ہیرا پھیری کی حمایت نہیں کرتے ہیں۔ فائن ریڈر او سی آر کا استعمال کرتے ہوئے، ان فیکس کو چند کلکس کے ساتھ قابل تدوین پی ڈی ایف فائلوں یا حتیٰ کہ ورڈ دستاویزات میں تبدیل کیا جا سکتا ہے۔
دستاویزات کی ڈیجیٹائزیشن (تصاویر سے متن)
ABBYY ڈیٹا نکالنے کا ایک حل پیش کرتا ہے جو پرنٹ شدہ یا ہاتھ سے لکھے ہوئے متن کی تصاویر کو قابل تدوین شکل میں تبدیل کرنے کے لیے استعمال کیا جا سکتا ہے۔ یہ ان کاروباروں اور تنظیموں کے لیے ایک اہم ٹول ہے جنہیں بڑی مقدار میں دستاویزات، جیسے مالی، قانونی یا طبی کو ڈیجیٹائز کرنے کی ضرورت ہے۔ ڈیٹا نکالنے کا عمل خود بخود تصاویر سے متن نکال سکتا ہے، جسے پھر ڈیٹا بیس میں محفوظ کیا جا سکتا ہے یا پی ڈی ایف یا کسی اور دستاویز کی شکل میں تبدیل کیا جا سکتا ہے۔ یہ حل دستی ڈیٹا انٹری کی ضرورت کو کم کرکے کاروباری اداروں اور تنظیموں کو اہم وقت اور رقم بچا سکتا ہے۔ اس کے علاوہ، ڈیٹا نکالنے کے عمل کو کاغذی دستاویزات کو ڈیجیٹل فارمیٹ میں تبدیل کرنے کے لیے ایک مستقل اور درست طریقہ فراہم کرکے ڈیٹا انٹری کی درستگی کو بہتر بنانے کے لیے استعمال کیا جا سکتا ہے۔
مشین ترجمہ
ABBYY FineReader OCR کو کسی تصویر کو دوسری زبان (مشین ٹرانسلیشن) میں متن میں تبدیل کر کے مشینی ترجمہ کے آلے کے طور پر استعمال کیا جا سکتا ہے۔ یہ مفید ہو سکتا ہے اگر آپ اپنے مقام پر انسانی مترجمین کو برقرار رکھے بغیر ترجمے کی خدمات فراہم کرنا چاہتے ہیں لیکن پھر بھی اپنے صارفین کو معیاری ترجمہ فراہم کرنا چاہتے ہیں (یا کسی چیز کا ترجمہ کرنے میں خود وقت ضائع نہیں کرنا چاہتے)۔
ٹیبل ایکسٹرکشن آپٹیکل کریکٹر ریکگنیشن (OCR) کے استعمال کے ذریعے پی ڈی ایف یا ٹیبل دستاویزات کی تصاویر سے ڈیٹا نکالنے کا عمل ہے۔ یہ عام طور پر اسکین شدہ کاغذی دستاویزات، جیسے رسیدوں کو ڈیجیٹل فارمیٹ میں تبدیل کرنے کے لیے استعمال کیا جاتا ہے تاکہ ڈیٹا پر کارروائی، تجزیہ اور زیادہ مؤثر طریقے سے ذخیرہ کیا جا سکے۔ مارکیٹ میں مختلف OCR سافٹ ویئر دستیاب ہیں، لیکن ABBYY FineReader مقبول ترین انتخاب میں سے ایک ہے۔ ٹیکنالوجی لائنوں اور خلیوں کو پہچان سکتی ہے، اور یہ ہیڈر اور فوٹر کا بھی پتہ لگا سکتی ہے۔ متعدد صفحات پر مشتمل دستاویزات کو ایک ساتھ پروسیس کرنا ممکن ہے، جس سے وقت کی بچت ہوتی ہے۔ اس کے علاوہ، ABBYY FineReader زبانوں کی ایک وسیع رینج کو سپورٹ کرتا ہے، جو اسے مختلف زبانوں میں دستاویزات سے ڈیٹا نکالنے کے لیے مثالی بناتا ہے۔
دستاویزات سے ڈیٹا انٹری کو خودکار کرنا چاہتے ہیں؟ Nanonets کا AI پر مبنی OCR سلوشن سٹرکچرڈ/غیر ساختہ دستاویزات سے کلیدی معلومات نکالنے اور عمل کو آٹو پائلٹ پر ڈالنے میں مدد کر سکتا ہے!
Flexicapture OCR کے کاروباری استعمال کے معاملات کیا ہیں؟
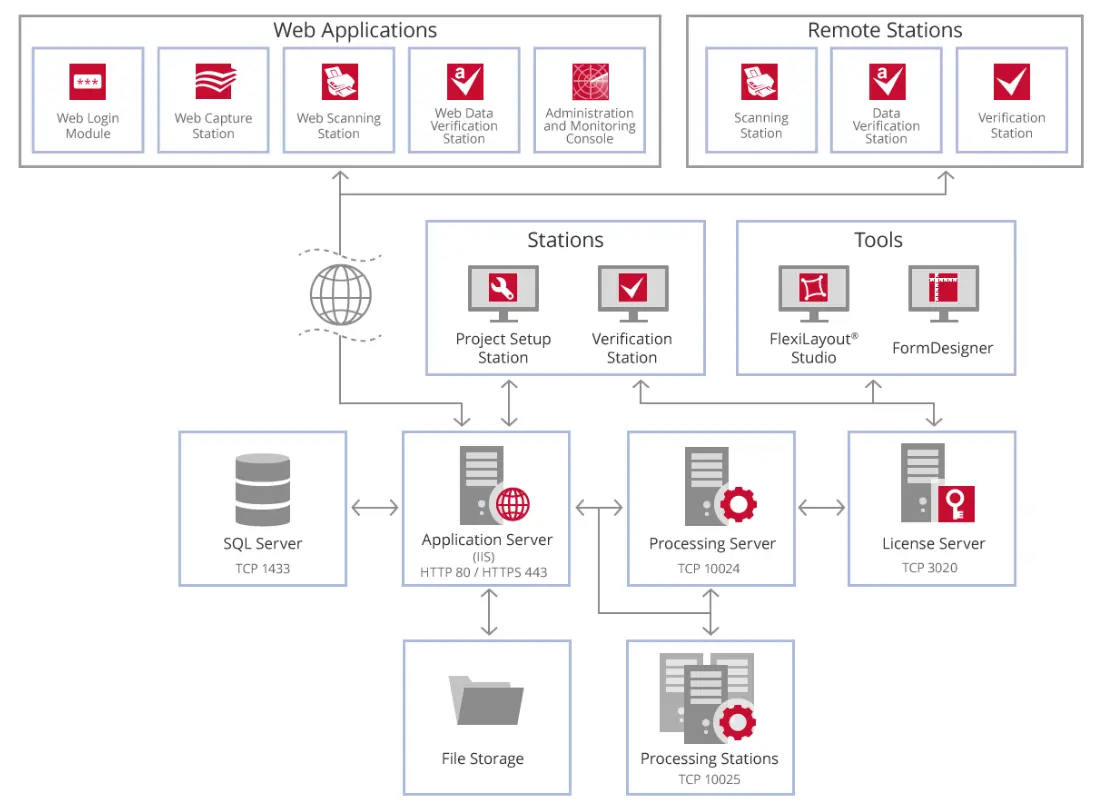
ABBYY FlexiCapture بنیادی طور پر ایک انٹرپرائز لیول ڈیٹا نکالنے والا سافٹ ویئر ایپلی کیشن ہے جو آپٹیکل کریکٹر ریکگنیشن (OCR) فنکشن فراہم کرتا ہے۔ FlexiCapture قواعد کے قیام کی بنیاد پر دستاویزات سے خود بخود معلومات نکالنے کا ایک ذریعہ فراہم کرتا ہے، بشمول مطلوبہ الفاظ اور صفحہ پر ڈیٹا کا مقام۔ FlexiCapture فی الحال خصوصی، چلانے کے لیے تیار حل پیکجوں میں دستیاب ہے جیسے FlexiCapture for Invoices اور FlexiCapture برائے میل روم۔ اگرچہ حل بہت زیادہ انحصار کرتا ہے اسی OCR ٹیکنالوجی کے استعمال پر جو FineReader Server میں پایا جاتا ہے، اور یہ ضرورت پڑنے پر کسی دستاویز کا متن تلاش کرنے کے قابل ورژن برآمد کر سکتا ہے، اس کے بنیادی افعال درج ذیل ہیں:
- دستاویزات کی درجہ بندی (ان کی قسم کا تعین)
- ان دستاویزات کی کلاسوں کو ڈیٹا نکالنے کے متعلقہ اصولوں سے ملانا
- ڈیٹا کو کہیں بھی ایکسپورٹ کرنا جیسے ڈیٹا بیس، XML فائل یا Microsoft Excel۔
FlexiCapture کی دستاویز کی درجہ بندی کی صلاحیتوں کو دستاویز کے سیٹ سے فیلڈ ویلیو کو نکالنے اور پھر موازنہ کرنے کے لیے استعمال کیا جا سکتا ہے۔ مثال کے طور پر، قرض کی درخواست میں نصف درجن دستاویزات شامل ہو سکتی ہیں، جن میں سے کچھ SSN پر مشتمل ہوتی ہیں۔ ایک اصول آسانی سے ترتیب دیا جا سکتا ہے تاکہ ہر دستاویز سے SSNs کا موازنہ کیا جا سکے جس میں اس فیلڈ کے لیے ایک قدر موجود ہو اور پھر دستاویز کی تصدیق کے مرحلے کے دوران آپریٹر کے سامنے کوئی بھی خامیاں پیش کریں۔
نیچے دی گئی تصویر میں، آپ FlexiCapture سرور کے اجزاء کے درمیان تعلق دیکھ سکتے ہیں۔
کچھ عام استعمال کے معاملات
2-طریقہ ملاپ
ABBYY FineReader میں ایسی خصوصیات ہیں جو آپ کے قابل ادائیگی اکاؤنٹس کو زیادہ آسانی سے چلانے میں مدد کر سکتی ہیں۔ اس میں شامل ہے:
- کاغذ اور الیکٹرانک دستاویزات سے انوائس ڈیٹا کا خودکار نکالنا
- ERP سسٹم میں متعلقہ خریداری کے خلاف انوائس لائن آئٹمز کی 2 طرفہ مماثلت
- متن سے تلاش کرنے کے قابل رسیدوں کے ذریعے تلاش کرنا
- ڈالر کی رقم یا دیگر قواعد کے ذریعے ادائیگیوں کی منظوری
- آنے والے خریداری کے آرڈرز کی خودکار پروسیسنگ
دستاویز کی درجہ بندی
- آنے والی دستاویزات کی قسم کے لحاظ سے درجہ بندی کریں اور پہلے سے تشکیل شدہ قواعد کا استعمال کرتے ہوئے دستاویزات سے ڈیٹا نکالیں۔
- دستاویز کا متن تلاش کرنے کے قابل PDF ورژن کو مواد کے انتظام کے نظام میں برآمد کریں اور دستاویز سے نکالے گئے ڈیٹا کے ساتھ فیلڈز کو آباد کریں۔
- صارفین کو دستاویز کے ورک فلو کے عمل کے اندر پہلے سے پروگرام شدہ قواعد کے استثناء کو منظم کرنے کے لیے قطاروں کے ساتھ نکالے گئے ڈیٹا کو درست کرنے کا ذریعہ فراہم کریں۔
ABBYY حل کے لیے سرفہرست متبادل

Amazon Textract ایک ایسی خدمت ہے جو خود بخود اسکین شدہ دستاویزات سے متن اور ڈیٹا نکالتی ہے۔ یہ سادہ آپٹیکل کریکٹر ریکگنیشن (OCR) سے آگے بڑھ کر فارمز میں موجود کھیتوں کے مواد اور ٹیبلز میں محفوظ معلومات کی بھی شناخت کرتا ہے۔
Amazon AWS Textract ایک نیا ٹول ہے جو اپنی کم قیمت اور استعمال میں آسانی کی بدولت مقبولیت میں بڑھ رہا ہے۔ یہ دستاویزات کی ایک بڑی تعداد کو اسکین کرنے کے لیے مثالی ہے، حالانکہ اس کی درستگی کی سطح ABBYY [2] جتنی زیادہ نہیں ہے۔
ABBYY اور Amazon Textract کے درمیان بنیادی فرق یہ ہے کہ جب ABBYY آپٹیکل کریکٹر ریکگنیشن (OCR) کا استعمال کرتے ہوئے تصاویر سے متن نکالنے کے لیے ایک اسٹینڈ حل فراہم کرتا ہے، Amazon اپنے صارفین کو ایک API فراہم کرتا ہے جو وہ اپنی ایپلی کیشنز میں ضم کر سکتے ہیں۔ وہ مختلف SDKs بھی فراہم کرتے ہیں، جس سے ڈویلپرز کے لیے اس خصوصیت کو اپنی مصنوعات میں ضم کرنا آسان ہو جاتا ہے۔ تاہم، اس کے لیے جاوا یا ازگر جیسی پروگرامنگ زبانوں کے بارے میں اضافی معلومات کی ضرورت ہے۔
مزید برآں، AWS Textract کے برعکس، ABBYY آپ کے OCR عمل کے ہر پہلو پر مکمل کنٹرول فراہم کرتا ہے (مثال کے طور پر، یہ آپ کو الفاظ کی تقسیم کو اپنی مرضی کے مطابق کرنے کی اجازت دیتا ہے)۔
ABBYY اور AWS Textract دونوں ہی زیادہ تر معاملات میں درستگی اور رفتار کے لحاظ سے بہت اچھے کام کرتے ہیں۔
متن کے فوائد
- آپ SDK کے ساتھ کسی بھی ٹیکسٹ پروسیسنگ ایپلیکیشن کے ساتھ AWS Textract استعمال کر سکتے ہیں۔
- AWS Textract 25 ممالک اور خطوں میں 200 سے زیادہ زبانوں کو سپورٹ کرتا ہے۔ آپ اسے اپنی تصویری فائلوں کا حقیقی وقت میں ترجمہ کرنے اور کثیر لسانی پروسیسنگ پائپ لائنز بنانے کے لیے استعمال کر سکتے ہیں۔
- یہ آلہ لاگت سے موثر ہے۔ اس کی لاگت صرف $0.0025 فی 100,000 حروف پر کارروائی کی جاتی ہے - دوسرے حل کی لاگت سے نصف سے بھی کم!
- AWS Textract قابل توسیع ہے، یعنی آپ اسے اپنی ضروریات کے مطابق بڑے یا چھوٹے پیمانے پر استعمال کر سکتے ہیں۔
متن کے نقصانات
- AWS Textract کو آپ کے ڈیٹا کو پروڈکشن میں استعمال کرنے سے پہلے تربیت دینے کے لیے کافی وقت اور وسائل درکار ہوتے ہیں۔
- جدید آپٹیکل کریکٹر ریکگنیشن (OCR) سافٹ ویئر تاریخوں کی توثیق، پکسلیٹڈ ریجنز تلاش کرنے، اور دیگر طریقوں سے شناخت کر سکتا ہے کہ آیا اپ لوڈ کردہ دستاویز اصلی ہے یا جعلسازی۔ AWS Textract میں یہ صلاحیت نہیں ہے۔ یہ صرف اپ لوڈ کردہ دستاویز سے متن نکال سکتا ہے۔
- ٹیکسٹریکٹ اپ اسٹریم اور ڈاون اسٹریم فراہم کنندگان کے ساتھ آسانی سے انضمام کی اجازت نہیں دیتا ہے۔ مثال کے طور پر، ہمیں تیسرے فریق کی خدمت کے ساتھ RPA پائپ لائن بنانا پڑ سکتی ہے۔ متن کے مطابق مناسب پلگ ان تلاش کرنا مشکل ہوگا۔
ABBYY بمقابلہ ٹیسریکٹ

Tesseract OCR کو خالص C++ کوڈ میں لکھی گئی زبانوں کی وسیع رینج کو پہچاننے کے لیے ڈیزائن کیا گیا تھا۔ اسے موبائل ڈیوائسز جیسے اینڈرائیڈ اور آئی او ایس پلیٹ فارمز پر استعمال کے لیے بھی مرتب کیا جا سکتا ہے۔ سافٹ ویئر جدید خصوصیات کا استعمال کرتا ہے جیسے عمودی متن کی ترتیب کا پتہ لگانا، صارفین کو درستگی کھونے کے بغیر متن کو مختلف زاویوں سے پڑھنے کی اجازت دیتا ہے۔
ABBYY اور Tesseract OCR حل فراہم کرتے ہیں اور اعلی درستگی کی شرحوں پر فخر کرتے ہیں اور مختلف زبانوں کی حمایت کرتے ہیں۔ تاہم، دونوں کے درمیان کچھ اہم اختلافات ہیں. ABBYY ایک زیادہ صارف دوست انٹرفیس پیش کرتا ہے، جو اسے OCR میں نئے لوگوں کے لیے مثالی بناتا ہے۔ یہ مزید خصوصیات بھی فراہم کرتا ہے، جیسے کہ متعدد فارمیٹس کو برآمد کرنا اور امیج ایڈیٹنگ کرنا۔ دوسری طرف، Tesseract اوپن سورس ہے اور اس لیے استعمال کے لیے آزاد ہے۔ اس میں زیادہ درست انجن بھی ہے، جس کی وجہ سے یہ ان لوگوں کے لیے بہتر انتخاب ہے جن کی درستگی کی اعلی ترین سطح کی ضرورت ہے۔
ٹیسریکٹ کے فوائد
- یہ مختلف زبانوں کے ساتھ مختلف فونٹس میں کام کرتا ہے، بشمول رومن، سیریلک، ہان آئیڈیوگرافک اسکرپٹ، عبرانی، عربی اور تھائی۔
- ماخذ کوڈ اپاچی لائسنس کے تحت دستیاب ہے، لہذا یہ استعمال اور ترمیم کرنے کے لیے مفت ہے۔ دوسرے OCR انجنوں کے مقابلے اس میں میموری کا نشان بھی کم ہے، لہذا یہ آپ کے کمپیوٹر یا اسمارٹ فون پر زیادہ جگہ نہیں لیتا ہے۔
- Tesseract ورسٹائل ہے اور اسے مختلف کاموں کے لیے استعمال کیا جا سکتا ہے، سادہ آپٹیکل کریکٹر ریکگنیشن (OCR) سے لے کر زیادہ پیچیدہ کاموں جیسے کہ مشین لرننگ (ML) تک۔
ٹیسریکٹ کے نقصانات
- Tesseract ہمیشہ کامل نتائج نہیں دیتا، خاص طور پر پیچیدہ یا ہاتھ سے لکھے ہوئے متن کے ساتھ۔
- ٹیسریکٹ کی امیج پروسیسنگ ابتدائی ہے۔ لہذا، آپ کو بہترین نتائج حاصل کرنے کے لیے ایک پری پروسیسر یا ایسی تصویر استعمال کرنے کی ضرورت ہے جس پر پہلے ہی کارروائی کی گئی ہو [8]۔
ABBYY بمقابلہ Ephesoft

Ephesoft ایک اور دستاویز کی شناخت کا آلہ ہے جو تصاویر کو ٹیکسٹ فائلوں میں تبدیل کرنے کے لیے آپٹیکل کریکٹر ریکگنیشن (OCR) ٹیکنالوجی کا استعمال کرتا ہے۔ یہ سافٹ ویئر خاص طور پر ان کاروباروں کے لیے ڈیزائن کیا گیا ہے جنہیں بڑی مقدار میں کاغذی دستاویزات جیسے رسیدیں یا رسیدوں کے انتظام کے لیے حل کی ضرورت ہے۔ ABBYY کی مصنوعات کی طرح، Ephesoft کو صحت کی دیکھ بھال، حکومت، مالیات، اور مینوفیکچرنگ سمیت متعدد صنعتوں میں استعمال کیا جا سکتا ہے۔
دونوں سافٹ ویئر سویٹس خصوصیات اور فوائد کی ایک جامع رینج پیش کرتے ہیں، لیکن ان کے درمیان کچھ اہم اختلافات ہیں۔ مثال کے طور پر، ABBYY کو عام طور پر Ephesoft [6]t سے زیادہ درست سمجھا جاتا ہے، خاص طور پر جب پیچیدہ ترتیب والی دستاویزات میں متن کو پہچانا جائے۔ تاہم، Ephesoft عام طور پر ABBYY سے زیادہ تیز ہوتا ہے، یہ ان تنظیموں کے لیے ایک اچھا انتخاب ہے جنہیں روزانہ دستاویزات کی ایک بڑی مقدار پر کارروائی کرنی چاہیے۔ قیمت کے لحاظ سے، ABBYY عام طور پر Ephesoft سے زیادہ مہنگا ہے، حالانکہ دونوں کمپنیاں والیوم لائسنسنگ کے لیے رعایت پیش کرتی ہیں۔ بالآخر، آپ کے کاروبار کے لیے بہترین OCR سافٹ ویئر آپ کی مخصوص ضروریات اور بجٹ پر منحصر ہوگا۔
Ephesoft کے فوائد
- سسٹم میں ٹریکنگ کی فعالیت ہے جو صارف کی دستاویز کی تبدیلیوں کو ٹریک کرنے میں مدد کرتی ہے۔ یہ دھوکہ دہی کو روکنے اور اس بات پر نظر رکھنے کے لیے مفید ہو سکتا ہے کہ جب متعدد صارفین کسی دستاویز پر کام کرتے ہیں تو کس نے تبدیلیاں کی ہیں۔
- Ephesoft تصویروں سے ڈیٹا نکالنے کے لیے امیج کوالٹی بڑھانے کی تکنیک کا استعمال کرتا ہے، جیسے OCR (آپٹیکل کریکٹر ریکگنیشن)، بارکوڈ کی شناخت، اور کریکٹر ریکگنیشن۔ یہ دستی طریقوں کے مقابلے میں ڈیٹا نکالنے کی درستگی کو نمایاں طور پر بڑھاتا ہے، جہاں تصویر کے خراب معیار یا دیگر عوامل کی وجہ سے ڈیٹا مکمل طور پر درست یا مکمل نہیں ہو سکتا۔
- متعدد زبانوں میں دستاویزات کی حمایت کرتا ہے، جیسے کہ انگریزی، ہسپانوی، فرانسیسی، وغیرہ، جو اسے متنوع کسٹمر بیس والی صنعتوں کے لیے موزوں بناتا ہے جو مختلف زبانوں کو مواصلات/دستاویزات کے اپنے بنیادی موڈ کے طور پر استعمال کرتے ہیں۔
Ephesoft کے نقصانات
- اسے استعمال کرنے سے پہلے مناسب تربیت کی ضرورت ہے۔ اگر آپ کو اس قسم کے سافٹ ویئر کے ساتھ کام کرنے کا پہلے سے تجربہ نہیں ہے، تو آپ کو اسے مؤثر طریقے سے استعمال کرنا مشکل ہو سکتا ہے۔ تاہم، ایک بار جب آپ اس کے عادی ہو جائیں گے، تو آپ کے لیے اس پروڈکٹ کو اپنی کاروباری ترتیب میں مؤثر طریقے سے استعمال کرنا بہت آسان ہو جائے گا۔
- Ephesoft سافٹ ویئر کی قیمت مارکیٹ میں اسی طرح کی دیگر مصنوعات سے زیادہ ہے۔ Ephesoft خریدنے کے لیے درکار ابتدائی سرمایہ کاری زیادہ ہو سکتی ہے، لیکن کلاؤڈ ورژن کا انتخاب کر کے لاگت کو کم کیا جا سکتا ہے [7]۔
ABBYY بمقابلہ ہائپر سائنس

ہائپر سائنس کے ملکیتی مشین لرننگ ماڈلز اور طاقتور آپٹیکل کریکٹر ریکگنیشن (OCR) ٹیکنالوجی دیگر سٹرکچرڈ اور نیم سٹرکچرڈ دستاویزات کے ساتھ ہاتھ سے لکھی ہوئی شکلوں کے لیے ڈیٹا نکالنے کی بے مثال صلاحیت لاتی ہے۔ یہ پلیٹ فارم اعلیٰ کارکردگی کی رپورٹنگ، بلٹ ان کوالٹی ایشورنس، اور درست – اور تیز – دستاویز کی گرفت اور تجزیہ کے لیے اعلیٰ سطح کے اخراج کا حامل ہے۔
ABBYY اور Hyperscience دونوں ڈیسک ٹاپ اور کلاؤڈ بیسڈ OCR حل پیش کرتے ہیں۔ اگر آپ کو دستاویزات کی ایک بڑی مقدار کو او سی آر کرنے کی ضرورت ہے، تو ABBYY ایک بہتر آپشن ہو سکتا ہے، کیونکہ آپ ڈیسک ٹاپ ایپلیکیشن کا استعمال کرتے ہوئے انہیں بیچوں میں پروسیس کرنے کے قابل ہو جائیں گے۔
ABBYY کا OCR انجن مصنوعی ذہانت (AI) پر مبنی ہے، جبکہ Hyperscience کا OCR انجن مشین لرننگ (ML) پر مبنی ہے۔ اس کا مطلب ہے کہ ABBYY وقت کے ساتھ سیکھ سکتا ہے اور بہتر کر سکتا ہے، جبکہ Hyperscience ہمیشہ اپنے تربیتی ڈیٹا کے مطابق نتائج پیدا کرے گا۔ لہذا اگر آپ کو ایک OCR ٹول کی ضرورت ہے جو بدلتے ہوئے حالات (مثلاً، مختلف فونٹس، خراب معیار کی تصاویر، وغیرہ) کے مطابق ہو سکے، ABBYY ایک بہتر انتخاب ہو سکتا ہے۔ تاہم، اگر آپ کو ایک OCR ٹول کی ضرورت ہے جو ہمیشہ ایک ہی اعلیٰ سطح کی درستگی پیدا کرے، ان پٹ دستاویز سے قطع نظر، Hyperscience ایک بہتر آپشن ہو سکتا ہے۔
ABBYY vs. ریڈیریز

ریڈیرس ایک طاقتور اور درست OCR انجن ہے جو اسکین شدہ دستاویزات اور تصاویر کو قابل تدوین اور قابل تلاش متن میں تبدیل کرنے کے لیے استعمال کیا جا سکتا ہے۔ یہ خصوصیات اور اختیارات کی ایک وسیع رینج پیش کرتا ہے، جو اسے مختلف ضروریات کے لیے ایک ورسٹائل اور طاقتور OCR حل بناتا ہے۔
ریڈیرس ABBYY FineReader کے مقبول متبادل میں سے ایک ہے۔ یہ ایک OCR پروگرام بھی ہے جس میں بہت ساری خصوصیات اور بہت سے صارفین ہیں۔
ریڈیرس کے فوائد
- 20% تیز دستاویزات کی پروسیسنگ
- OCR کے ساتھ اپنی تصاویر میں سرایت شدہ متن میں ترمیم کریں۔
- مائیکروسافٹ آفس دستاویزات کو پی ڈی ایف میں تبدیل کریں۔
- تبصرہ کریں اور تبصرہ کریں۔
- پی ڈی ایف کی حفاظت اور دستخط کریں۔
- پرنٹرز کے ساتھ انضمام (ٹوین سکینر) [3]
ریڈیرس کے نقصانات
- بھاری ڈیٹا کے ساتھ کام کرتے وقت قیمتوں کا تعین مہنگا ہو سکتا ہے۔
- دوسرے ٹولز کے مقابلے غیر ساختہ ڈیٹا کے ساتھ کام کرتے وقت درستگی کم ہو سکتی ہے [4]
ABBYY بمقابلہ Google Cloud Vision

گوگل کلاؤڈ ویژن او سی آر کلاؤڈ بیسڈ ٹیکسٹ ریکگنیشن اور تصویری تجزیہ حل ہے۔ یہ سروس تصاویر اور ویڈیوز پر کارروائی کرنے، اشیاء، مناظر اور چہروں کو پہچاننے کے ساتھ ساتھ 100 سے زائد زبانوں میں متن کا پتہ لگانے کے لیے گہری سیکھنے کے الگورتھم کا استعمال کرتی ہے۔
گوگل کلاؤڈ ویژن کے فوائد
- نتائج درست اور قابل اعتماد ہیں—Google اپنی OCR سروس کے لیے ڈیپ لرننگ ماڈلز کا استعمال کرتا ہے، جس کا مطلب ہے کہ یہ اس بارے میں مزید سیکھتا ہے کہ وقت گزرنے کے ساتھ ساتھ آپ کی مخصوص دستاویز کو کس طرح فارمیٹ کیا جاتا ہے، وقت کے ساتھ ساتھ اس کی درستگی میں بہتری آتی ہے۔
- یہ زیادہ تر فائل کی اقسام کے ساتھ مطابقت رکھتا ہے — Google Cloud Vision OCR JPEG، PNG، BMP، TIFF، PDF فائلوں، اور اینیمیٹڈ GIFs کے ساتھ کام کرتا ہے! یہاں تک کہ آپ گوگل کلاؤڈ ویژن OCR کا استعمال کرتے ہوئے HTML صفحات کو سادہ متن میں تبدیل کر سکتے ہیں (حالانکہ تمام فارمیٹنگ کو محفوظ نہیں کیا جائے گا)۔
- یہ استعمال کرنا آسان ہے — آپ کو بس ایک تصویر اپ لوڈ کرنے کی ضرورت ہے جس میں وہ متن شامل ہو جسے آپ تبدیل کرنا چاہتے ہیں اور گوگل کلاؤڈ ویژن کنسول میں "ٹیکسٹ بنائیں" پر کلک کریں۔ آپ کو کوئی سافٹ ویئر انسٹال کرنے یا کسی سافٹ ویئر لائبریری کو ڈاؤن لوڈ کرنے کی ضرورت نہیں ہے۔
- اپنی مرضی کے سافٹ ویئر کے ساتھ ضم کرنے کے لیے API انٹرفیس فراہم کرتا ہے۔
گوگل کلاؤڈ ویژن کے نقصانات
- اس کے لیے انٹرنیٹ کنکشن کی ضرورت ہے (جس کا مطلب ہے کہ آپ اسے آف لائن استعمال نہیں کر سکتے ہیں)۔
- ڈیٹا کی بڑی مقدار پر کارروائی کرنا سست ہے۔ آپ اسے چھوٹی سے درمیانی مقدار میں متن کے لیے استعمال کر سکتے ہیں، لیکن اگر آپ بیچ موڈ میں بڑی مقدار میں ٹیکسٹ پروسیسنگ کرنا چاہتے ہیں، تو یہ حل آپ کی ضروریات کے لیے کافی تیز نہیں ہو سکتا۔
- کچھ معاملات جیسے ٹیبل نکالنے میں، گوگل کلاؤڈ ویژن OCR کی درستگی دوسرے ٹولز کی طرح زیادہ نہیں ہے [5]۔
دستاویزات سے ڈیٹا انٹری کو خودکار کرنا چاہتے ہیں؟ Nanonets کا AI پر مبنی OCR سلوشن سٹرکچرڈ/غیر ساختہ دستاویزات سے کلیدی معلومات نکالنے اور عمل کو آٹو پائلٹ پر ڈالنے میں مدد کر سکتا ہے!
ABBYY بمقابلہ Nanonets

Nanonets ایک AI پر مبنی OCR سافٹ ویئر ہے جو خودکار ہوتا ہے۔ ڈیٹا کیپچر لیے انوائس کی ذہین دستاویز پروسیسنگرسیدیں، شناختی کارڈز، اور مزید۔ نانونٹس جدید او سی آر استعمال کرتے ہیں، مشین لرننگ امیج پروسیسنگ، اور غیر ساختہ ڈیٹا سے متعلقہ معلومات نکالنے کے لیے ڈیپ لرننگ۔ یہ تیز، درست، استعمال میں آسان ہے، صارفین کو شروع سے اپنی مرضی کے مطابق OCR ماڈل بنانے کی اجازت دیتا ہے، اور اس میں کچھ صاف Zapier انضمام ہے۔ دستاویزات کو ڈیجیٹائز کریں، ڈیٹا فیلڈز نکالیں، اور APIs کے ذریعے ایک سادہ، بدیہی انٹرفیس میں اپنی روزمرہ کی ایپس کے ساتھ ضم کریں۔
Nanonets کے فوائد
- جدید UI
- دستاویزات کی بڑی مقدار کو ہینڈل کرتا ہے۔
- مناسب قیمت
- استعمال میں آسانی
- ڈیٹا کی علمی کیپچر - کم سے کم مداخلت کے نتیجے میں
- ڈویلپرز کی کسی اندرونی ٹیم کی ضرورت نہیں ہے۔
- الگورتھم/ماڈلز کو تربیت/دوبارہ تربیت دی جا سکتی ہے۔
- عظیم دستاویزات اور حمایت
- اصلاح کے بہت سے اختیارات
- انضمام کے اختیارات کا وسیع انتخاب
- غیر انگریزی یا متعدد زبانوں کے ساتھ کام کرتا ہے۔
- تقریباً کوئی پوسٹ پروسیسنگ کی ضرورت نہیں ہے۔
- متعدد اکاؤنٹنگ سافٹ ویئر کے ساتھ ہموار 2 طرفہ انضمام
- ڈویلپرز کے لیے زبردست OCR API
Nanonets کے نقصانات
- بہت زیادہ والیوم اسپائکس کو ہینڈل نہیں کر سکتے
- ٹیبل کیپچر UI بہتر ہو سکتا ہے۔
ABBYY قیمتوں کا موازنہ اور جائزہ لیں۔
|
کا آلہ |
زبان کی حمایت |
ڈیمو |
قیمتوں کا تعین |
|
|
ایڈوب ایکروبیٹ پرو ڈی سی |
100+ زبانیں |
7 دن |
14.99$/ماہ شروع ہو رہا ہے۔ |
بادل |
|
IRIS پڑھیں |
130+ زبانیں |
30 دن |
129$/ماہ شروع ہو رہا ہے۔ |
ونڈوز اور میک۔ |
|
ABBY فائن ریڈر |
198+ زبانیں |
7 دن |
$ 117 / سال |
Windows، iOS، Android، اور Mac۔ |
|
گوگل کلاؤڈ ویژن |
130+ زبانیں |
مفت |
مفت ورژن $1.5 فی 1000 یونٹ |
کلاؤڈ، API |
|
نانونٹس |
100+ زبانیں |
FREE |
مفت ورژن پرو: $499 / مہینہ |
کلاؤڈ، ونڈوز اور میک |
|
Tesseract |
120+ زبانیں |
FREE |
FREE |
ونڈوز |
ABBYY پر Nanonets کا انتخاب کیوں کریں؟
Nanonets ایک OCR سافٹ ویئر ہے جو مصنوعی ذہانت کا استعمال کرتا ہے تاکہ پی ڈی ایف دستاویزات، تصاویر اور اسکین فائلوں سے ٹیبل نکالنے کو خودکار بنایا جاسکے۔ دیگر حلوں کے برعکس، اسے ہر نئی دستاویز کی قسم کے لیے الگ الگ اصولوں اور ٹیمپلیٹس کی ضرورت نہیں ہے۔ اس کے بجائے، یہ وقت کے ساتھ بہتر ہوتے ہوئے نیم ساختہ اور غیر دیکھے ہوئے دستاویزات کو سنبھالنے کے لیے علمی ذہانت پر انحصار کرتا ہے۔ آپ آؤٹ پٹ کو صرف اپنی دلچسپی کے ٹیبلز یا ڈیٹا انٹریز کو نکالنے کے لیے بھی اپنی مرضی کے مطابق بنا سکتے ہیں۔
یہ تیز، درست، استعمال میں آسان ہے، صارفین کو شروع سے اپنی مرضی کے مطابق OCR ماڈل بنانے کی اجازت دیتا ہے، اور اس میں کچھ صاف Zapier انضمام ہے۔ دستاویزات کو ڈیجیٹائز کریں، ٹیبلز یا ڈیٹا فیلڈز نکالیں، اور APIs کے ذریعے اپنے روزمرہ کے ایپس کے ساتھ ایک سادہ، بدیہی انٹرفیس میں ضم کریں۔
Nanonets بہترین OCR کیوں ہے؟
- Nanonets صفحہ پر موجود ڈیٹا کو نکال سکتے ہیں جبکہ کمانڈ لائن پی ڈی ایف پارسرز صرف اشیاء، ہیڈر اور میٹا ڈیٹا جیسے (عنوان، صفحات، خفیہ کاری کی حیثیت، وغیرہ) کو نکال سکتے ہیں۔
- Nanonets PDF پارسنگ ٹیکنالوجی ٹیمپلیٹ پر مبنی نہیں ہے۔ مقبول استعمال کے معاملات کے لیے پہلے سے تربیت یافتہ ماڈل پیش کرنے کے علاوہ، Nanonets PDF پارسنگ الگورتھم بھی غیر دیکھی ہوئی دستاویز کی اقسام کو سنبھال سکتا ہے!
- مقامی پی ڈی ایف دستاویزات کو ہینڈل کرنے کے علاوہ، Nanonet کی ان بلٹ OCR صلاحیتیں اسے اسکین شدہ دستاویزات اور تصاویر کو بھی ہینڈل کرنے کی اجازت دیتی ہیں!
- AI اور ML صلاحیتوں کے ساتھ مضبوط آٹومیشن خصوصیات۔
- Nanonets غیر ساختہ ڈیٹا، عام ڈیٹا کی رکاوٹوں، کثیر صفحاتی پی ڈی ایف دستاویزات، میزیں، اور ملٹی لائن آئٹمز کو آسانی کے ساتھ ہینڈل کرتے ہیں۔
- Nanonets ایک بغیر کوڈ والا ٹول ہے جو اپنی مرضی کے مطابق ڈیٹا پر مسلسل سیکھ سکتا ہے اور خود کو دوبارہ تربیت دے سکتا ہے تاکہ ایسے آؤٹ پٹ فراہم کیے جا سکیں جس میں پوسٹ پروسیسنگ کی ضرورت نہیں ہوتی ہے۔
نانونٹس کے ساتھ خودکار انوائس پارس کرنا - مکمل طور پر ٹچ لیس انوائس پروسیسنگ ورک فلوز بنانا۔
اپنے موجودہ ٹولز کو Nanonets کے ساتھ مربوط کریں اور ڈیٹا اکٹھا کرنے، ایکسپورٹ اسٹوریج، اور بک کیپنگ کو خودکار بنائیں۔
نانونیٹس انوائس پارس ورک فلوز کو خودکار بنانے میں بھی مدد کر سکتے ہیں:
- متعدد ذرائع سے انوائس ڈیٹا کو درآمد اور مستحکم کرنا - ای میل، اسکین شدہ دستاویزات، ڈیجیٹل فائلیں/تصاویر، کلاؤڈ اسٹوریج، ERP، API، وغیرہ۔
- رسیدوں، رسیدوں، بلوں اور دیگر مالیاتی دستاویزات سے ذہانت سے انوائس ڈیٹا کیپچر کرنا اور نکالنا۔
- کاروباری قواعد کی بنیاد پر لین دین کی درجہ بندی اور کوڈنگ۔
- داخلی منظوری حاصل کرنے اور مستثنیات کا نظم کرنے کے لیے خودکار منظوری کے ورک فلو کو ترتیب دینا۔
- تمام لین دین کو ملانا۔
- ERPs یا اکاؤنٹنگ سافٹ ویئر جیسے Quickbooks، Sage، Xero، Netsuite، اور مزید کے ساتھ بغیر کسی رکاوٹ کے انضمام۔
حوالہ جات
ہے [1] کیا میں ABBYY FineReader میں ہاتھ سے لکھے ہوئے متن کو پہچان سکتا ہوں؟ - مدداور تعاون کا مرکز
ہے [2] ABBYY FineReader VS Amazon Textract - فرق اور جائزوں کا موازنہ کریں؟
ہے [3] 7 کے 2022 بہترین OCR سافٹ ویئر (مفت اور ادا شدہ)
ہے [4] 10 میں ٹاپ 2022 OCR سافٹ ویئر | بہترین OCR حل
ہے [6] Ephesoft بمقابلہ FineReader PDF برائے Windows اور Mac 2022 | جی 2
ہے [7] 21 میں 2022 بہترین OCR سافٹ ویئر
ہے [8] Pytesseract اور OpenCV کے ساتھ Python میں Tesseract OCR
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://nanonets.com/blog/abbyy-reviews-compare-competitors-alternatives/
- 000
- 1
- 10
- 100
- 2022
- 7
- 95٪
- a
- قابلیت
- ہمارے بارے میں
- اوپر
- مطلق
- رسائی
- اکاؤنٹنگ
- اکاؤنٹنگ سوفٹ ویئر
- اکاؤنٹس
- قابل ادائیگی اکاؤنٹس
- درستگی
- درست
- کے پار
- اپنانے
- شامل کیا
- اس کے علاوہ
- ایڈیشنل
- اضافی معلومات
- اعلی درجے کی
- کے خلاف
- AI
- یلگورتم
- یلگوردمز
- تمام
- تمام لین دین
- اجازت دے رہا ہے
- کی اجازت دیتا ہے
- پہلے ہی
- متبادلات
- اگرچہ
- ہمیشہ
- ایمیزون
- ایمیزون ٹیکسٹ
- کے درمیان
- رقم
- مقدار
- تجزیہ
- تجزیاتی
- اور
- لوڈ، اتارنا Android
- ایک اور
- اپاچی
- علاوہ
- اے پی آئی
- APIs
- اپلی کیشن
- درخواست
- ایپلی کیشنز
- مناسب
- منظوری
- ایپس
- مضامین
- مصنوعی
- مصنوعی ذہانت
- مصنوعی انٹیلی جنس (AI)
- پہلو
- یقین دہانی
- خود کار طریقے سے
- آٹومیٹڈ
- خودکار
- خود کار طریقے سے
- خودکار
- میشن
- دستیاب
- AWS
- بینک
- کی بنیاد پر
- بن
- اس سے پہلے
- پیچھے
- کیا جا رہا ہے
- نیچے
- فائدہ
- فوائد
- BEST
- بہتر
- کے درمیان
- سے پرے
- بل
- بلاگ
- دعوی
- برانڈڈ
- لانے
- بجٹ
- تعمیر
- تعمیر میں
- کاروبار
- کاروباری عمل
- کاروبار
- C ++
- نہیں کر سکتے ہیں
- صلاحیتوں
- قبضہ
- کارڈ
- مقدمات
- خلیات
- تبدیلیاں
- تبدیل کرنے
- کردار
- کردار کی پہچان
- حروف
- چیک کریں
- انتخاب
- انتخاب
- میں سے انتخاب کریں
- دعوے
- کلاس
- درجہ بندی
- قریب
- بادل
- بادل سٹوریج
- کوڈ
- کوڈنگ
- سنجیدگی سے
- مجموعہ
- کامن
- عام طور پر
- کمپنیاں
- کمپنی کے
- موازنہ
- مقابلے میں
- ہم آہنگ
- مکمل
- مکمل طور پر
- پیچیدہ
- اجزاء
- وسیع
- کمپیوٹر
- تصورات
- حالات
- کنکشن
- خامیاں
- غور کریں
- سمجھا
- متواتر
- کنسول
- مضبوط
- رکاوٹوں
- پر مشتمل ہے
- مواد
- مواد کے انتظام
- مندرجات
- کنٹرول
- تبادلوں سے
- تبادلوں
- تبدیل
- تبدیل
- کور
- اسی کے مطابق
- قیمت
- سرمایہ کاری مؤثر
- اخراجات
- ممالک
- تخلیق
- تخلیق
- اہم
- CRM
- اس وقت
- اپنی مرضی کے
- گاہک
- گاہکوں
- اصلاح
- اپنی مرضی کے مطابق
- روزانہ
- اعداد و شمار
- ڈیٹا تجزیات
- ڈیٹا انٹری
- ڈیٹا بیس
- ڈیٹا بیس
- تواریخ
- دن
- گہری
- گہری سیکھنے
- شعبہ
- منحصر ہے
- نامزد
- ڈیزائن
- ڈیسک ٹاپ
- کھوج
- کا تعین کرنے
- ڈیولپر
- ڈویلپرز
- کے الات
- فرق
- اختلافات
- مختلف
- مشکل
- ڈیجیٹل
- ڈیجیٹائزیشن
- ڈیجیٹلائز کرنا
- چھوٹ
- متنوع
- دستاویز
- دستاویزی مینجمنٹ
- دستاویزات
- دستاویزات
- نہیں کرتا
- ڈالر
- نہیں
- ڈاؤن لوڈ، اتارنا
- درجن سے
- کے دوران
- ہر ایک
- استعمال میں آسانی
- آسان
- آسانی سے
- ترمیم سافٹ ویئر
- مؤثر طریقے
- کارکردگی
- مؤثر طریقے سے
- یا تو
- الیکٹرانک
- ای میل
- ای میل
- ایمبیڈڈ
- کو فعال کرنا
- خفیہ کاری
- انجن
- انجینئرز
- انجن
- انگریزی
- بہتر
- کافی
- افزودہ
- انٹرپرائز
- انٹرپرائز کے حل
- انٹرپرائز کی سطح
- اندراج
- ERP
- نقائص
- خاص طور پر
- قیام
- وغیرہ
- Ether (ETH)
- بھی
- واقعہ
- واقعات
- ہر روز
- كل يوم
- سب
- تیار
- مثال کے طور پر
- ایکسل
- موجودہ
- توسیع
- مہنگی
- تجربہ
- تلاش
- برآمد
- نکالنے
- ڈیٹا نکالیں
- نکالنے
- نچوڑ۔
- آنکھ
- چہرے
- عوامل
- فاسٹ
- تیز تر
- نمایاں کریں
- خصوصیات
- چند
- میدان
- قطعات
- فائل
- فائلوں
- کی مالی اعانت
- مالی
- مل
- تلاش
- پہلا
- فٹ
- مندرجہ ذیل ہے
- فونٹ
- فوٹ پرنٹ
- فارمیٹ
- پہلے
- فارم
- ملا
- قائم
- فریم
- دھوکہ دہی
- مفت
- فرانسیسی
- سے
- فعالیت
- افعال
- حاصل کرنا
- عام طور پر
- حاصل
- گلوبل
- جاتا ہے
- اچھا
- گوگل
- گوگل کلاؤڈ
- حکومت
- گروپ
- گروپ کا
- بڑھتے ہوئے
- نصف
- ہینڈل
- ہینڈلنگ
- ہونے
- سر
- ہیڈر
- صحت کی دیکھ بھال
- بھاری
- مدد
- مدد کرتا ہے
- ہائی
- اعلی سطحی
- سب سے زیادہ
- تاریخی
- کس طرح
- کیسے
- تاہم
- HTML
- HTTPS
- بھاری
- انسانی
- مثالی
- شناخت
- تصویر
- تصویری تجزیہ
- تصاویر
- اہم
- کو بہتر بنانے کے
- کو بہتر بنانے کے
- in
- دیگر میں
- شامل
- شامل ہیں
- سمیت
- موصولہ
- اضافہ
- انڈکس
- افراد
- صنعتوں
- صنعت
- معلومات
- ابتدائی
- ان پٹ
- بصیرت
- انسٹال
- کے بجائے
- انشورنس
- ضم
- انضمام
- انضمام
- سالمیت
- انٹیلی جنس
- انٹیلجنٹ
- دلچسپی
- انٹرفیس
- اندرونی
- انٹرنیٹ
- انٹرنیٹ کنکشن
- بدیہی
- سرمایہ کاری
- انوائس مینجمنٹ
- انوائس پروسیسنگ
- iOS
- IT
- اشیاء
- خود
- اعلی درجے کا Java
- رکھیں
- کلیدی
- علم
- زبان
- زبانیں
- بڑے
- بڑے پیمانے پر
- پرت
- لے آؤٹ
- جانیں
- سیکھنے
- قانونی
- سطح
- سطح
- لائبریریوں
- لائسنس
- لائسنسنگ
- لائن
- لائنوں
- لسٹ
- قرض
- محل وقوع
- دیکھو
- کھونے
- بہت
- لو
- میک
- مشین
- مشین لرننگ
- مشین ترجمہ
- بنا
- مین
- برقرار رکھنے کے
- بنا
- بنانا
- انتظام
- انتظام
- مینجمنٹ سلوشن۔
- مینیجنگ
- جوڑی
- ہیرا پھیری
- دستی
- دستی طور پر
- مینوفیکچرنگ
- بہت سے
- نشان
- مارکیٹ
- Markets
- کے ملاپ
- مطلب
- کا مطلب ہے کہ
- طبی
- یاد داشت
- میٹا ڈیٹا
- طریقہ
- طریقوں
- مائیکروسافٹ
- مائیکروسافٹ ایکسل
- مائیکروسافٹ آفس
- دس لاکھ
- کم سے کم
- ML
- موبائل
- موبائل اپلی کیشن
- موبائل آلات
- موڈ
- ماڈل
- قیمت
- زیادہ
- ماسکو
- سب سے زیادہ
- سب سے زیادہ مقبول
- ایک سے زیادہ
- نام
- مقامی
- قدرتی
- قدرتی زبان
- قدرتی زبان عملیات
- Neat
- ضرورت ہے
- ضرورت
- ضرورت ہے
- ضروریات
- نیٹ ورک
- نئی
- خبر
- تعداد
- اشیاء
- OCR
- او سی آر سافٹ ویئر
- او سی آر حل
- او سی آر ٹول
- پیش کرتے ہیں
- کی پیشکش کی
- کی پیشکش
- تجویز
- دفتر
- آف لائن
- ایک
- کھول
- اوپن سورس
- چل رہا ہے
- آپریٹر
- آپٹیکل کریکٹر ریکگنیشن
- اختیار
- آپشنز کے بھی
- احکامات
- تنظیمیں
- اصل
- دیگر
- دیگر
- مجموعی جائزہ
- خود
- پیکجوں کے
- ادا
- کاغذ.
- خاص طور پر
- پیٹرن
- ادائیگی
- لوگ
- کامل
- کارکردگی
- کارکردگی کا مظاہرہ
- مرحلہ
- پائپ لائن
- سادہ
- پلیٹ فارم
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- پلگ ان
- غریب
- مقبول
- مقبولیت
- ممکن
- پوسٹ
- طاقتور
- حال (-)
- کی روک تھام
- قیمت
- بنیادی طور پر
- پرائمری
- پہلے
- فی
- عمل
- عمل
- پروسیسنگ
- پیدا
- مصنوعات
- پیداوار
- حاصل
- پروگرام
- پروگرامنگ
- پروگرامنگ زبانوں
- منصوبے
- مناسب
- ملکیت
- پیشہ
- فراہم
- فراہم کرنے والے
- فراہم کرتا ہے
- فراہم کرنے
- خرید
- مقاصد
- ڈال
- pytesseract
- ازگر
- معیار
- کوئک بوکس
- جلدی سے
- رینج
- قیمتیں
- پڑھیں
- اصل وقت
- رسیدیں
- موصول
- تسلیم
- تسلیم
- کم
- کو کم کرنے
- حوالہ جات
- بے شک
- خطوں
- تعلقات
- متعلقہ
- قابل اعتماد
- رپورٹ
- رپورٹیں
- کی ضرورت
- ضرورت
- ضروریات
- کی ضرورت ہے
- وسائل
- نتیجے
- نتائج کی نمائش
- کا جائزہ لینے کے
- جائزہ
- آر پی اے
- حکمرانی
- قوانین
- رن
- اسی
- محفوظ کریں
- توسیع پذیر
- پیمانے
- اسکین
- سکیننگ
- مناظر
- sdk
- بغیر کسی رکاوٹ کے
- تلاش
- سیکشن
- انقطاع
- سروس
- سروسز
- سیٹ
- قائم کرنے
- مشترکہ
- سائن ان کریں
- اہم
- نمایاں طور پر
- اسی طرح
- سادہ
- صرف
- سست
- چھوٹے
- ہوشیار
- اسمارٹ فون
- آسانی سے
- So
- سافٹ ویئر کی
- حل
- حل
- کچھ
- کچھ
- کہیں
- ماخذ
- ماخذ کوڈ
- ذرائع
- خلا
- ہسپانوی
- خصوصی
- مخصوص
- خاص طور پر
- تیزی
- اسٹینڈ
- مانکیکرن
- حالت
- بیانات
- درجہ
- ابھی تک
- ذخیرہ
- ذخیرہ
- کارگر
- کوشش کرتا ہے
- ساخت
- منظم
- اس طرح
- سوٹ
- موزوں
- سویٹ
- اعلی
- حمایت
- کی حمایت کرتا ہے
- کے نظام
- سسٹمز
- ٹیبل
- میز نکالنا
- لے لو
- لیتا ہے
- کاموں
- ٹیم
- انسو کا گرنا
- تکنیک
- ٹیکنالوجی
- ٹیکنالوجی
- سانچے
- شرائط
- ٹیسریکٹ
- متن کی پہچان۔
- تھائی
- ۔
- ان
- لہذا
- تیسری پارٹی
- کے ذریعے
- وقت
- ٹائم لائن
- عنوان
- کرنے کے لئے
- مل کر
- بھی
- کے آلے
- اوزار
- ٹھوس
- ٹریک
- ٹریکنگ
- ٹرین
- ٹریننگ
- معاملات
- ترجمہ کریں
- ترجمہ
- ترجمہ
- رجحانات
- عام طور پر
- ui
- آخر میں
- کے تحت
- افہام و تفہیم
- منفرد
- یونیورسٹی
- بے مثال۔
- اپ لوڈ کردہ
- استعمال کی شرائط
- رکن کا
- صارف دوست
- صارفین
- عام طور پر
- قیمت
- اقدار
- مختلف اقسام کے
- مختلف
- توثیق
- ورسٹائل
- ورژن
- کی طرف سے
- ویڈیوز
- نقطہ نظر
- حجم
- جلد
- فضلے کے
- چاہے
- جس
- جبکہ
- ڈبلیو
- مکمل طور پر
- وسیع
- وسیع رینج
- گے
- کھڑکیاں
- کے اندر
- بغیر
- لفظ
- کام
- کام کا بہاؤ
- کام کے بہاؤ
- کام کر
- کام کرتا ہے
- گا
- لکھا
- زیرو
- XML
- اور
- اپنے آپ کو
- زیفیرنیٹ