تعارف
ریئل ٹائم اے آئی سسٹمز تیزی سے اندازہ لگانے پر بہت زیادہ انحصار کرتے ہیں۔ OpenAI، Google، اور Azure جیسے صنعت کے لیڈروں کے Inference APIs تیزی سے فیصلہ سازی کو قابل بناتے ہیں۔ Groq's Language Processing Unit (LPU) ٹیکنالوجی ایک بہترین حل ہے، جس سے AI پروسیسنگ کی کارکردگی میں اضافہ ہوتا ہے۔ یہ مضمون Groq کی جدید ٹیکنالوجی، AI تخمینہ کی رفتار پر اس کے اثرات، اور Groq API کا استعمال کرتے ہوئے اس کا فائدہ اٹھانے کے طریقہ کے بارے میں بتاتا ہے۔
سیکھنے کے مقاصد
- Groq کی لینگویج پروسیسنگ یونٹ (LPU) ٹیکنالوجی اور AI inference اسپیڈ پر اس کے اثرات کو سمجھیں۔
- ریئل ٹائم، کم تاخیر والے AI پروسیسنگ کے کاموں کے لیے Groq کے API اینڈ پوائنٹس کو استعمال کرنے کا طریقہ سیکھیں۔
- قدرتی زبان کی تفہیم اور نسل کے لیے Groq کے تعاون یافتہ ماڈلز، جیسے Mixtral-8x7b-Instruct-v0.1 اور Llama-70b کی صلاحیتوں کو دریافت کریں۔
- Groq کے LPU سسٹم کا دوسرے inference APIs کے ساتھ موازنہ کریں اور اس کے برعکس رفتار، کارکردگی، اور اسکیل ایبلٹی جیسے عوامل کی جانچ کریں۔
اس مضمون کے ایک حصے کے طور پر شائع کیا گیا تھا۔ ڈیٹا سائنس بلاگتھون۔
فہرست
Groq کیا ہے؟
2016 میں قائم گروک کیلیفورنیا میں مقیم AI سلوشنز اسٹارٹ اپ ہے جس کا ہیڈ کوارٹر ماؤنٹین ویو میں واقع ہے۔ Groq، جو انتہائی کم لیٹنسی AI تخمینہ میں مہارت رکھتا ہے، نے AI کمپیوٹنگ کی کارکردگی کو نمایاں طور پر ترقی دی ہے۔ Groq AI ٹکنالوجی کی جگہ میں ایک نمایاں حصہ لینے والا ہے، جس نے اپنا نام بطور ٹریڈ مارک رجسٹر کیا ہے اور AI تک رسائی کو جمہوری بنانے کے لیے پرعزم عالمی ٹیم کو اکٹھا کیا ہے۔
لینگویج پروسیسنگ یونٹس
Groq's Language Processing Unit (LPU)، ایک جدید ٹیکنالوجی، کا مقصد AI کمپیوٹنگ کی کارکردگی کو بڑھانا ہے، خاص طور پر Large Language Models (LLMs) کے لیے۔ Groq LPU سسٹم غیر معمولی کارکردگی کی کارکردگی کے ساتھ حقیقی وقت، کم تاخیر کے تجربات فراہم کرنے کی کوشش کرتا ہے۔ Groq نے Meta AI کے Llama-300 2B ماڈل پر فی صارف 70 سے زیادہ ٹوکن فی سیکنڈ حاصل کیے، ایک نیا صنعتی معیار قائم کیا۔
Groq LPU سسٹم AI سپورٹ ٹیکنالوجیز کے لیے انتہائی کم لیٹنسی صلاحیتوں کا حامل ہے۔ خاص طور پر ترتیب وار اور کمپیوٹ-انٹینسیو GenAI لینگویج پروسیسنگ کے لیے ڈیزائن کیا گیا ہے، یہ روایتی GPU سلوشنز سے بہتر کارکردگی کا مظاہرہ کرتا ہے، قدرتی زبان کی تخلیق اور تفہیم جیسے کاموں کے لیے موثر پروسیسنگ کو یقینی بناتا ہے۔
Groq کی پہلی نسل کی GroqChip، LPU سسٹم کا حصہ، رفتار، کارکردگی، درستگی، اور لاگت کی تاثیر کے لیے موزوں ٹینسر اسٹریمنگ فن تعمیر کی خصوصیات رکھتی ہے۔ یہ چپ موجودہ حل کو پیچھے چھوڑتی ہے، فی صارف فی سیکنڈ ٹوکن میں ماپی جانے والی بنیادی LLM رفتار میں نئے ریکارڈ قائم کرتی ہے۔ دو سالوں کے اندر 1 ملین AI انفرنس چپس کو تعینات کرنے کے منصوبوں کے ساتھ، Groq نے AI ایکسلریشن ٹیکنالوجیز کو آگے بڑھانے کے لیے اپنے عزم کا اظہار کیا۔
خلاصہ یہ کہ Groq کا لینگویج پروسیسنگ یونٹ سسٹم AI کمپیوٹنگ ٹیکنالوجی میں ایک اہم پیشرفت کی نمائندگی کرتا ہے، جو AI میں جدت طرازی کرتے ہوئے بڑی زبان کے ماڈلز کے لیے شاندار کارکردگی اور کارکردگی پیش کرتا ہے۔
بھی پڑھیں: اے ڈبلیو ایس سیج میکر میں ایم ایل ماڈل بنانا
Groq کے ساتھ شروع کرنا
ابھی، Groq Groq LPU – لینگویج پروسیسنگ یونٹ پر چلنے والے بڑے لینگویج ماڈلز کو مفت استعمال کرنے کے لیے API اینڈ پوائنٹس فراہم کر رہا ہے۔ شروع کرنے کے لیے، یہ ملاحظہ کریں۔ صفحہ اور لاگ ان پر کلک کریں۔ صفحہ نیچے کی طرح لگتا ہے:
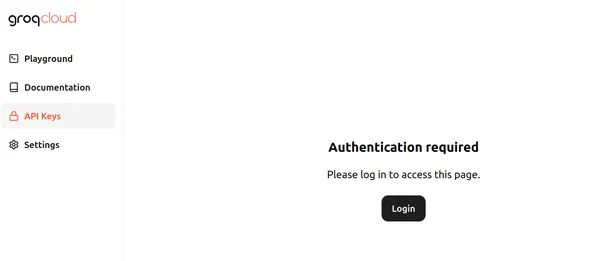
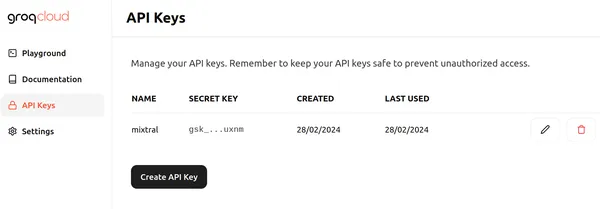
لاگ ان پر کلک کریں اور Groq میں سائن ان کرنے کے لیے مناسب طریقوں میں سے ایک کا انتخاب کریں۔ پھر ہم Create API Key بٹن پر کلک کرکے نیچے کی طرح ایک نیا API بنا سکتے ہیں۔
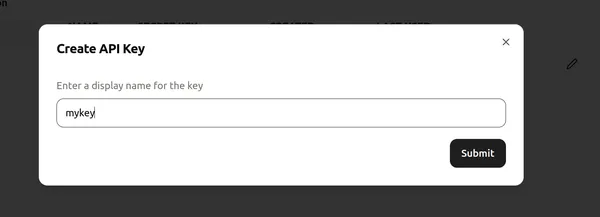
اگلا، API کلید کو ایک نام تفویض کریں اور ایک نئی API کلید بنانے کے لیے "جمع کروائیں" پر کلک کریں۔ اب، کسی بھی کوڈ ایڈیٹر/کولاب پر جائیں اور Groq کا استعمال شروع کرنے کے لیے مطلوبہ لائبریریاں انسٹال کریں۔
!pip install groqیہ کمانڈ Groq لائبریری کو انسٹال کرتی ہے، جس سے ہم Groq LPUs پر چلنے والے بڑے لینگویج ماڈلز کا اندازہ لگا سکتے ہیں۔
اب، آئیے کوڈ کے ساتھ آگے بڑھتے ہیں۔
کوڈ کا نفاذ
# Importing Necessary Libraries
import os
from groq import Groq
# Instantiation of Groq Client
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)یہ کوڈ کا ٹکڑا Groq API کے ساتھ تعامل کرنے کے لیے ایک Groq کلائنٹ آبجیکٹ قائم کرتا ہے۔ یہ GROQ_API_KEY نامی ماحولیاتی متغیر سے API کلید کو بازیافت کرنے سے شروع ہوتا ہے اور اسے api_key دلیل میں منتقل کرتا ہے۔ اس کے بعد، API کلید Groq کلائنٹ آبجیکٹ کو شروع کرتی ہے، Groq سرورز کے اندر بڑی زبان کے ماڈلز پر API کالز کو فعال کرتی ہے۔
ہمارے ایل ایل ایم کی تعریف کرنا
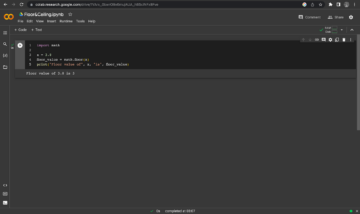
llm = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful AI Assistant. You explain ever
topic the user asks as if you are explaining it to a 5 year old"
},
{
"role": "user",
"content": "What are Black Holes?",
}
],
model="mixtral-8x7b-32768",
)
print(llm.choices[0].message.content)- پہلی لائن ایک llm آبجیکٹ کو شروع کرتی ہے، جو OpenAI Chat Completion API کی طرح بڑے لینگویج ماڈل کے ساتھ تعامل کو فعال کرتی ہے۔
- اس کے بعد کا کوڈ LLM کو بھیجے جانے والے پیغامات کی ایک فہرست بناتا ہے، جو پیغامات کے متغیر میں محفوظ ہوتا ہے۔
- پہلا پیغام اس کردار کو "نظام" کے طور پر تفویض کرتا ہے اور LLM کے مطلوبہ رویے کی وضاحت کرتا ہے تاکہ موضوعات کی وضاحت کی جائے جیسا کہ یہ 5 سال کے بچے کو کرتا ہے۔
- دوسرا پیغام بطور "صارف" کردار تفویض کرتا ہے اور اس میں بلیک ہولز کے بارے میں سوال شامل ہے۔
- مندرجہ ذیل سطر جواب پیدا کرنے کے لیے استعمال کیے جانے والے LLM کی وضاحت کرتی ہے، جسے "mixtral-8x7b-32768" پر سیٹ کیا گیا ہے، ایک 32k سیاق و سباق Mixtral-8x7b-Instruct-v0.1 Groq API کے ذریعے قابل رسائی بڑی زبان کا ماڈل۔
- اس کوڈ کا آؤٹ پٹ LLM کی طرف سے جواب ہو گا جس میں بلیک ہولز کی وضاحت 5 سالہ بچے کی سمجھ کے لیے موزوں ہو۔
- آؤٹ پٹ تک رسائی OpenAI اینڈ پوائنٹ کے ساتھ کام کرنے کے لئے اسی طرح کے نقطہ نظر کی پیروی کرتی ہے۔
آؤٹ پٹ
ذیل میں Mixtral-8x7b-Instruct-v0.1 بڑے لینگویج ماڈل کے ذریعہ تیار کردہ آؤٹ پٹ دکھاتا ہے:

۔ completions.create() آبجیکٹ اضافی پیرامیٹرز میں بھی لے سکتا ہے جیسے درجہ حرارت, ٹاپ_پی، اور max_tokens.
جواب پیدا کرنا
آئیے ان پیرامیٹرز کے ساتھ جواب پیدا کرنے کی کوشش کریں:
llm = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful AI Assistant. You explain ever
topic the user asks as if you are explaining it to a 5 year old"
},
{
"role": "user",
"content": "What is Global Warming?",
}
],
model="mixtral-8x7b-32768",
temperature = 1,
top_p = 1,
max_tokens = 256,
)- درجہ حرارت: جوابات کی بے ترتیب پن کو کنٹرول کرتا ہے۔ کم درجہ حرارت زیادہ متوقع نتائج کا باعث بنتا ہے، جبکہ زیادہ درجہ حرارت کے نتیجے میں زیادہ مختلف اور بعض اوقات زیادہ تخلیقی نتائج برآمد ہوتے ہیں۔
- max_tokens: ٹوکنز کی زیادہ سے زیادہ تعداد جس پر ماڈل ایک جواب میں کارروائی کر سکتا ہے۔ یہ حد کمپیوٹیشنل کارکردگی اور وسائل کے انتظام کو یقینی بناتی ہے۔
- ٹاپ_پی: ٹیکسٹ جنریشن کا ایک طریقہ جو سب سے زیادہ ممکنہ ٹوکنز کی ممکنہ تقسیم سے اگلا ٹوکن منتخب کرتا ہے۔ یہ نسل کے دوران تلاش اور استحصال میں توازن رکھتا ہے۔
آؤٹ پٹ

یہاں تک کہ Groq اینڈ پوائنٹ سے پیدا ہونے والے جوابات کو اسٹریم کرنے کا آپشن بھی موجود ہے۔ ہمیں صرف اس کی وضاحت کرنے کی ضرورت ہے۔ سلسلہ = سچ میں اختیار completions.create() جوابات کا سلسلہ شروع کرنے کے لیے ماڈل کے لیے اعتراض۔
Langchain میں Groq
Groq LangChain کے ساتھ بھی مطابقت رکھتا ہے۔ LangChain میں Groq کا استعمال شروع کرنے کے لیے، لائبریری ڈاؤن لوڈ کریں:
!pip install langchain-groqمندرجہ بالا LangChain مطابقت کے لیے Groq لائبریری کو انسٹال کرے گا۔ اب آئیے اسے کوڈ میں آزماتے ہیں:
# Import the necessary libraries.
from langchain_core.prompts import ChatPromptTemplate
from langchain_groq import ChatGroq
# Initialize a ChatGroq object with a temperature of 0 and the "mixtral-8x7b-32768" model.
llm = ChatGroq(temperature=0, model_name="mixtral-8x7b-32768")مندرجہ بالا کوڈ مندرجہ ذیل کام کرتا ہے:
- llm نامی ایک نیا ChatGroq آبجیکٹ بناتا ہے۔
- سیٹ کرتا ہے۔ درجہ حرارت پیرامیٹر 0 تک، اس بات کی نشاندہی کرتا ہے کہ جوابات زیادہ متوقع ہونے چاہئیں
- سیٹ کرتا ہے۔ ماڈل نام پیرامیٹر کو "mixtral-8x7b-32768"، استعمال کرنے کے لیے زبان کے ماڈل کی وضاحت کرنا
# AI اسسٹنٹ کی صلاحیتوں کو متعارف کرانے والے سسٹم کے پیغام کی وضاحت کریں۔
# Define the system message introducing the AI assistant's capabilities.
system = "You are an expert Coding Assistant."
# Define a placeholder for the user's input.
human = "{text}"
# Create a chat prompt consisting of the system and human messages.
prompt = ChatPromptTemplate.from_messages([("system", system), ("human", human)])
# Invoke the chat chain with the user's input.
chain = prompt | llm
response = chain.invoke({"text": "Write a simple code to generate Fibonacci numbers in Rust?"})
# Print the Response.
print(response.content)- کوڈ ChatPromptTemplate کلاس کا استعمال کرتے ہوئے چیٹ پرامپٹ تیار کرتا ہے۔
- پرامپٹ میں دو پیغامات شامل ہیں: ایک "سسٹم" (AI اسسٹنٹ) سے اور دوسرا "انسان" (صارف) سے۔
- سسٹم کا پیغام AI اسسٹنٹ کو ایک ماہر کوڈنگ اسسٹنٹ کے طور پر پیش کرتا ہے۔
- انسانی پیغام صارف کے ان پٹ کے لیے پلیس ہولڈر کے طور پر کام کرتا ہے۔
- llm طریقہ فراہم کردہ پرامپٹ اور صارف کے ان پٹ کی بنیاد پر جواب تیار کرنے کے لیے llm چین کو طلب کرتا ہے۔
آؤٹ پٹ
Mixtral Large Language Model کے ذریعہ تیار کردہ آؤٹ پٹ یہ ہے:

Mixtral LLM مسلسل متعلقہ ردعمل پیدا کرتا ہے۔ زنگ کھیل کے میدان میں کوڈ کی جانچ اس کی فعالیت کی تصدیق کرتی ہے۔ فوری جواب بنیادی لینگویج پروسیسنگ یونٹ (LPU) سے منسوب ہے۔
Groq بمقابلہ دیگر Inference APIs
Groq کے لینگویج پروسیسنگ یونٹ (LPU) سسٹم کا مقصد بڑے لینگویج ماڈلز (LLMs) کے لیے بجلی کی تیز رفتار انفرنس اسپیڈ فراہم کرنا ہے، جو OpenAI اور Azure کی طرف سے فراہم کردہ دیگر inference APIs کو پیچھے چھوڑتا ہے۔ LLMs کے لیے آپٹمائزڈ، Groq کا LPU سسٹم انتہائی کم لیٹنسی صلاحیتیں فراہم کرتا ہے جو AI امدادی ٹیکنالوجیز کے لیے اہم ہے۔ یہ LLMs کی بنیادی رکاوٹوں کو دور کرتا ہے، بشمول کمپیوٹ ڈینسٹی اور میموری بینڈوڈتھ، جس سے ٹیکسٹ سیکوینسز کی تیز تر نسل کو قابل بنایا جا سکتا ہے۔
دیگر انفرنس APIs کے مقابلے میں، Groq کا LPU سسٹم تیز تر ہے، جس میں Anyscale کے LLMPerf لیڈر بورڈ پر کلاؤڈ پر مبنی دیگر اعلیٰ فراہم کنندگان کے مقابلے میں 18x تک تیز تر انفرنس پرفارمنس پیدا کرنے کی صلاحیت ہے۔ Groq کا LPU سسٹم بھی زیادہ موثر ہے، جس میں سنگل کور فن تعمیر اور ہم وقت ساز نیٹ ورکنگ بڑے پیمانے پر تعیناتیوں میں برقرار ہے، جس سے LLMs کی خودکار تالیف اور فوری میموری تک رسائی ممکن ہے۔
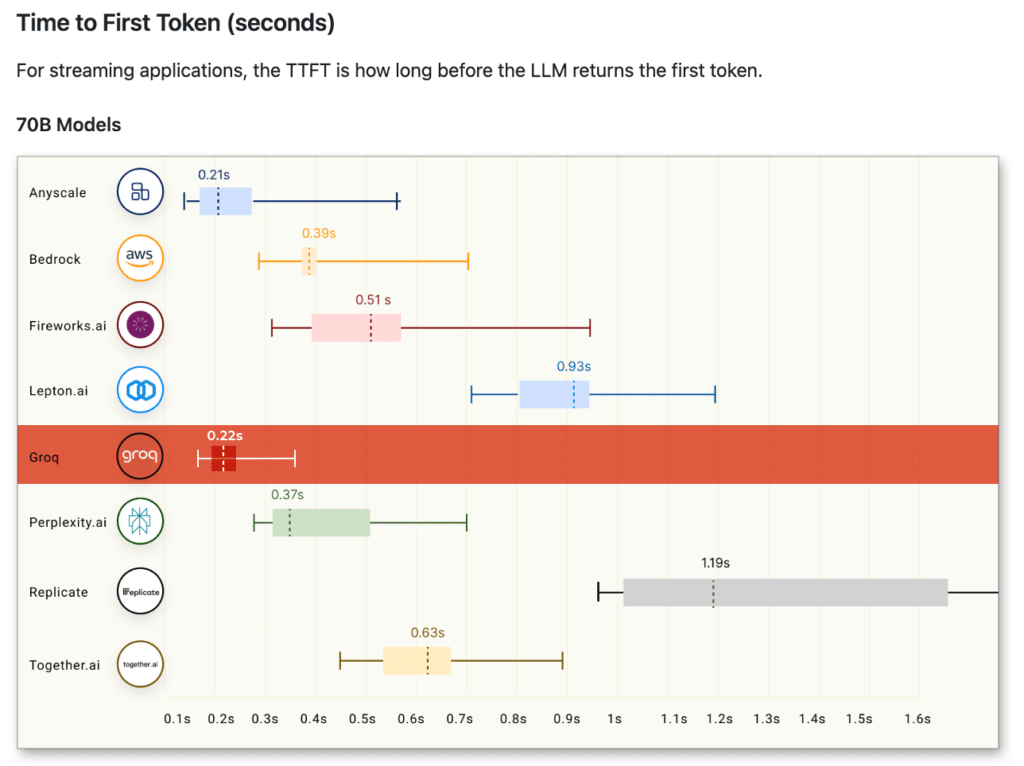
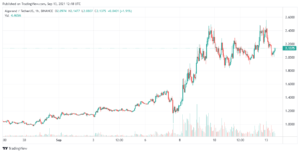
مندرجہ بالا تصویر 70B ماڈلز کے لیے بینچ مارکس دکھاتی ہے۔ آؤٹ پٹ ٹوکنز تھرو پٹ کا حساب لگانے میں فی سیکنڈ واپس آنے والے آؤٹ پٹ ٹوکنز کی اوسط تعداد شامل ہوتی ہے۔ ہر LLM انفرنس فراہم کنندہ نتائج جمع کرنے کے لیے 150 درخواستوں پر کارروائی کرتا ہے، اور ان درخواستوں کو استعمال کرتے ہوئے اوسط آؤٹ پٹ ٹوکنز تھرو پٹ کا حساب لگایا جاتا ہے۔ LLM انفرنس فراہم کنندہ کی بہتر کارکردگی کا اشارہ آؤٹ پٹ ٹوکنز کے اعلی تھرو پٹ سے ہوتا ہے۔ یہ واضح ہے کہ Groq کے آؤٹ پٹ ٹوکن فی سیکنڈ دکھائے گئے کلاؤڈ فراہم کرنے والوں میں سے بہت سے بہتر کارکردگی کا مظاہرہ کرتے ہیں۔
نتیجہ
آخر میں، Groq's Language Processing Unit (LPU) سسٹم AI کمپیوٹنگ کے دائرے میں ایک انقلابی ٹیکنالوجی کے طور پر نمایاں ہے، جو Large Language Models (LLMs) کو سنبھالنے اور AI کے میدان میں جدت لانے کے لیے بے مثال رفتار اور کارکردگی پیش کرتا ہے۔ اپنی انتہائی کم لیٹنسی کی صلاحیتوں اور آپٹمائزڈ فن تعمیر کا فائدہ اٹھاتے ہوئے، Groq انفرنس اسپیڈ کے لیے نئے معیارات مرتب کر رہا ہے، روایتی GPU سلوشنز اور دیگر انڈسٹری کے معروف انفرنس APIs کو پیچھے چھوڑ رہا ہے۔ AI تک رسائی کو جمہوری بنانے کے لیے اپنی وابستگی اور حقیقی وقت، کم تاخیر کے تجربات پر توجہ مرکوز کرنے کے ساتھ، Groq AI ایکسلریشن ٹیکنالوجیز کے منظر نامے کو نئی شکل دینے کے لیے تیار ہے۔
کلیدی لے لو
- Groq's Language Processing Unit (LPU) سسٹم AI inference کے لیے بے مثال رفتار اور کارکردگی پیش کرتا ہے، خاص طور پر Large Language Models (LLMs) کے لیے، ریئل ٹائم، کم تاخیر کے تجربات کو قابل بناتا ہے۔
- Groq کا LPU سسٹم، GroqChip کو نمایاں کرتا ہے، روایتی GPU سلوشنز سے بہتر کارکردگی کا مظاہرہ کرتے ہوئے AI سپورٹ ٹیکنالوجیز کے لیے انتہائی کم لیٹنسی صلاحیتوں کا حامل ہے۔
- دو سالوں کے اندر 1 ملین AI انفرنس چپس کو تعینات کرنے کے منصوبوں کے ساتھ، Groq نے AI ایکسلریشن ٹیکنالوجیز کو آگے بڑھانے اور AI تک رسائی کو جمہوری بنانے کے لیے اپنی لگن کا مظاہرہ کیا۔
- Groq Groq LPU پر چلنے والے بڑے لینگویج ماڈلز کے لیے مفت استعمال کے لیے API اینڈ پوائنٹس فراہم کرتا ہے، جس سے ڈویلپرز کو اپنے پروجیکٹس میں ضم کرنے کے لیے قابل رسائی بناتا ہے۔
- LangChain اور LlamaIndex کے ساتھ Groq کی مطابقت اس کے استعمال کو مزید وسعت دیتی ہے، جو اپنے لینگویج پروسیسنگ کے کاموں میں Groq ٹیکنالوجی سے فائدہ اٹھانے کے خواہاں ڈویلپرز کے لیے ہموار انضمام کی پیشکش کرتی ہے۔
اکثر پوچھے گئے سوالات
A. Groq انتہائی کم لیٹنسی AI inference میں مہارت رکھتا ہے، خاص طور پر Large Language Models (LLMs) کے لیے، جس کا مقصد AI کمپیوٹنگ کی کارکردگی میں انقلاب لانا ہے۔
A. Groq کا LPU سسٹم، جس میں GroqChip شامل ہے، خاص طور پر GenAI لینگویج پروسیسنگ کی کمپیوٹ-انٹینسیو نوعیت کے لیے تیار کیا گیا ہے، جو روایتی GPU سلوشنز کے مقابلے میں اعلیٰ رفتار، کارکردگی، اور درستگی پیش کرتا ہے۔
A. Groq AI تخمینہ کے لیے ماڈلز کی ایک رینج کو سپورٹ کرتا ہے، بشمول Mixtral-8x7b-Instruct-v0.1 اور Llama-70b۔
A. ہاں، Groq LangChain اور LlamaIndex کے ساتھ مطابقت رکھتا ہے، اس کے استعمال کو بڑھا رہا ہے اور اپنے لینگویج پروسیسنگ کے کاموں میں Groq ٹیکنالوجی سے فائدہ اٹھانے کے خواہاں ڈویلپرز کے لیے ہموار انضمام کی پیشکش کرتا ہے۔
A. Groq کا LPU سسٹم رفتار اور کارکردگی کے لحاظ سے دیگر inference APIs کو پیچھے چھوڑتا ہے، 18x تک تیز تر انفرنس اسپیڈ اور اعلیٰ کارکردگی فراہم کرتا ہے، جیسا کہ Anyscale کے LLMPerf لیڈر بورڈ پر بینچ مارکس سے ظاہر ہوتا ہے۔
اس مضمون میں دکھایا گیا میڈیا Analytics ودھیا کی ملکیت نہیں ہے اور مصنف کی صوابدید پر استعمال ہوتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.analyticsvidhya.com/blog/2024/03/getting-started-with-groq-api/
- : ہے
- : ہے
- : نہیں
- ][p
- $UP
- 1
- 10
- 11
- 14
- 150
- 20
- 2016
- 300
- 5
- 9
- a
- کی صلاحیت
- ہمارے بارے میں
- اوپر
- تیزی
- تک رسائی حاصل
- قابل رسائی
- درستگی
- حاصل کیا
- ایڈیشنل
- پتے
- اعلی درجے کی
- ترقی
- پیش قدمی کرنا
- AI
- اے آئی اسسٹنٹ
- اے آئی سسٹمز
- مقصد
- مقصد ہے
- اجازت دے رہا ہے
- بھی
- an
- تجزیاتی
- تجزیات ودھیا
- اور
- کوئی بھی
- اے پی آئی
- APIs
- نقطہ نظر
- مناسب
- فن تعمیر
- کیا
- دلیل
- مضمون
- AS
- پوچھا
- جمع
- تفویض
- اسسٹنس
- اسسٹنٹ
- At
- دستیاب
- نگرانی
- AWS
- Azure
- توازن
- بینڈوڈتھ
- کی بنیاد پر
- BE
- شروع کریں
- شروع ہوتا ہے
- رویے
- نیچے
- معیار
- معیارات
- سیاہ
- سیاہ سوراخ
- بلاگتھون
- دعوی
- رکاوٹیں
- by
- حساب
- حساب
- کالز
- کر سکتے ہیں
- صلاحیتوں
- چین
- چیٹ
- چپ
- چپس
- میں سے انتخاب کریں
- طبقے
- واضح
- کلک کریں
- پر کلک
- کلائنٹ
- بادل
- کوڈ
- کوڈنگ
- وابستگی
- انجام دیا
- موازنہ
- مقابلے میں
- موازنہ
- مطابقت
- ہم آہنگ
- تکمیل
- پر مشتمل ہے
- کمپیوٹیشنل
- کمپیوٹنگ
- کمپیوٹنگ
- اختتام
- مسلسل
- پر مشتمل ہے
- تعمیرات
- مواد
- سیاق و سباق
- اس کے برعکس
- کنٹرول
- روایتی
- کور
- تخلیق
- مخلوق
- تخلیقی
- اہم
- فیصلہ کرنا
- اعتراف کے
- وضاحت
- وضاحت کرتا ہے
- نجات
- ترسیل
- delves
- جمہوری بنانا
- demonstrated,en
- ثبوت
- کثافت
- تعیناتی
- تعینات
- ڈیزائن
- مطلوبہ
- ڈویلپرز
- مختلف
- صوابدید
- ظاہر
- دکھاتا ہے
- تقسیم
- do
- کرتا
- ڈاؤن لوڈ، اتارنا
- ڈرائیونگ
- کے دوران
- ہر ایک
- کارکردگی
- ہنر
- کو چالو کرنے کے
- کو فعال کرنا
- اختتام پوائنٹ
- اختتام
- بڑھانے کے
- بڑھانے
- یقینی بناتا ہے
- کو یقینی بنانے ہے
- ماحولیات
- ضروری
- قائم ہے
- Ether (ETH)
- بھی
- کبھی نہیں
- جانچ کر رہا ہے
- غیر معمولی
- توسیع
- توسیع
- تجربات
- ماہر
- وضاحت
- کی وضاحت
- استحصال
- کی تلاش
- عوامل
- فاسٹ
- تیز تر
- سب سے تیزی سے
- خصوصیات
- خاصیت
- فیبوناکی
- میدان
- پہلا
- توجہ مرکوز
- کے بعد
- مندرجہ ذیل ہے
- کے لئے
- بنیاد پرست
- سے
- فعالیت
- مزید
- جمع
- جینئی
- پیدا
- پیدا
- پیدا ہوتا ہے
- پیدا کرنے والے
- نسل
- حاصل
- حاصل کرنے
- گلوبل
- گلوبل وارمنگ
- گوگل
- GPU
- ہینڈلنگ
- ہونے
- ہیڈکوارٹر
- بھاری
- مدد گار
- ہائی
- اعلی
- سوراخ
- کس طرح
- کیسے
- HTTPS
- انسانی
- if
- تصویر
- اثر
- درآمد
- درآمد
- بہتر
- in
- شامل ہیں
- سمیت
- مابعد
- اشارہ کیا
- اشارہ کرتے ہیں
- صنعت
- صنعت کے معروف
- جدت طرازی
- جدید
- جدید ٹیکنالوجی
- ان پٹ
- انسٹال
- فوری
- فوری
- ضم
- انضمام
- بات چیت
- بات چیت
- میں
- متعارف کرانے
- پکارتے ہیں۔
- شامل ہے
- IT
- میں
- صرف
- کلیدی
- زمین کی تزئین کی
- زبان
- بڑے
- بڑے پیمانے پر
- تاخیر
- رہنماؤں
- لیڈز
- لیوریج
- لیورنگنگ
- لائبریریوں
- لائبریری
- بجلی کی تیز
- کی طرح
- امکان
- LIMIT
- لائن
- لسٹ
- ایل ایل ایم
- واقع ہے
- لاگ ان
- دیکھنا
- کم
- برقرار رکھا
- بنانا
- انداز
- بہت سے
- زیادہ سے زیادہ چوڑائی
- زیادہ سے زیادہ
- مطلب
- ماپا
- میڈیا
- یاد داشت
- پیغام
- پیغامات
- میٹا
- طریقہ
- طریقوں
- دس لاکھ
- ML
- ماڈل
- ماڈل
- زیادہ
- زیادہ موثر
- سب سے زیادہ
- ماؤنٹین
- نام
- نامزد
- قدرتی
- قدرتی زبان
- قدرتی زبان کی تفہیم
- فطرت، قدرت
- ضروری
- ضرورت ہے
- نیٹ ورکنگ
- نئی
- اگلے
- اب
- تعداد
- تعداد
- اعتراض
- of
- کی پیشکش
- تجویز
- پرانا
- on
- ایک
- اوپنائی
- اصلاح
- اختیار
- or
- OS
- دیگر
- ہمارے
- باہر
- باہر نکلنا
- باہر نکلنا
- Outperforms
- پیداوار
- نتائج
- بقایا
- پر
- ملکیت
- صفحہ
- پیرامیٹر
- پیرامیٹرز
- حصہ
- شریک
- خاص طور پر
- گزرتا ہے
- فی
- کارکردگی
- پلیس ہولڈر
- کی منصوبہ بندی
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- کھیل کے میدان
- تیار
- پیش قیاسی
- تحفہ
- پرائمری
- پرنٹ
- امکان
- آگے بڑھو
- عمل
- عمل
- پروسیسنگ
- پیدا
- ممتاز
- اشارہ کرتا ہے
- فراہم
- فراہم کنندہ
- فراہم کرنے والے
- فراہم کرتا ہے
- فراہم کرنے
- شائع
- سوال
- فوری
- بے ترتیب پن
- رینج
- تیزی سے
- پڑھیں
- اصل وقت
- دائرے میں
- ریکارڈ
- رجسٹرڈ
- متعلقہ
- انحصار کرو
- کی نمائندگی کرتا ہے
- درخواستوں
- ضرورت
- نئی شکل دینا
- وسائل
- جواب
- جوابات
- نتائج کی نمائش
- انقلابی
- انقلاب
- کردار
- چل رہا ہے
- مورچا
- s
- سائنس
- ہموار
- دوسری
- کی تلاش
- بھیجا
- سرورز
- کام کرتا ہے
- مقرر
- قائم کرنے
- ہونا چاہئے
- دکھایا گیا
- شوز
- سائن ان کریں
- اہم
- نمایاں طور پر
- اسی طرح
- سادہ
- ایک
- ٹکڑا
- حل
- حل
- کبھی کبھی
- خلا
- مہارت دیتا ہے
- خاص طور پر
- کی وضاحت
- تیزی
- رفتار
- موقف
- کھڑا ہے
- شروع کریں
- شروع
- شروع
- ذخیرہ
- سٹریم
- محرومی
- کوشش کرتا ہے
- بعد میں
- بعد میں
- اس طرح
- موزوں
- خلاصہ
- اعلی
- حمایت
- تائید
- کی حمایت کرتا ہے
- حد تک
- سبقت
- کے نظام
- سسٹمز
- موزوں
- لے لو
- کاموں
- ٹیم
- ٹیکنالوجی
- ٹیکنالوجی
- شرائط
- ٹیسٹنگ
- متن
- متن کی نسل
- کہ
- ۔
- زمین کی تزئین کی
- ان
- تو
- یہ
- وہ
- اس
- ان
- کے ذریعے
- تھرو پٹ
- کرنے کے لئے
- ٹوکن
- ٹوکن
- سب سے اوپر
- موضوع
- موضوعات
- ٹریڈ مارک
- روایتی
- کوشش
- دو
- بنیادی
- افہام و تفہیم
- یونٹ
- بے مثال۔
- بے مثال
- us
- استعمالی
- استعمال کیا جاتا ہے
- رکن کا
- کا استعمال کرتے ہوئے
- استعمال
- متغیر
- کی طرف سے
- لنک
- دورہ
- vs
- تھا
- we
- ویبپی
- کیا
- کیا ہے
- جس
- جبکہ
- گے
- ساتھ
- کے اندر
- کام کر
- گا
- لکھنا
- سال
- سال
- جی ہاں
- آپ
- زیفیرنیٹ