مختلف سائز اور صنعتی عمودی پر پھیلی بہت سی تنظیمیں اب بھی اپنے روزمرہ کے کاموں کو چلانے کے لیے دستاویزات کی بڑی مقدار پر انحصار کرتی ہیں۔ اس کاروباری چیلنج کو حل کرنے کے لیے، صارفین AWS سے ذہین دستاویز پراسیسنگ خدمات جیسے کہ استعمال کر رہے ہیں۔ ایمیزون ٹیکسٹ اور ایمیزون کی تعریف مدد کرنے کے لئے نکالنے اور عمل آٹومیشن. اس سے پہلے کہ آپ متن، کلیدی قدر کے جوڑے، میزیں، اور ہستیوں کو نکال سکیں، آپ کو ملٹی پیج پی ڈی ایف دستاویزات کو تقسیم کرنے کے قابل ہونے کی ضرورت ہے جن میں اکثر متضاد فارم کی اقسام ہوتی ہیں۔ مثال کے طور پر، مارگیج پروسیسنگ میں، ایک بروکر یا لون پروسیسنگ کرنے والے فرد کو ایک مضبوط پی ڈی ایف لون پیکج کو تقسیم کرنے کی ضرورت ہو سکتی ہے، جس میں رہن کی درخواست (Fannie Mae فارم 1003)، W2s، آمدنی کی تصدیق، 1040 ٹیکس فارمز اور مزید شامل ہوں۔
اس مسئلے سے نمٹنے کے لیے، تنظیمیں قواعد پر مبنی پروسیسنگ کا استعمال کرتی ہیں: فارم کے عنوانات، صفحہ نمبر، فارم کی لمبائی وغیرہ کے ذریعے دستاویز کی اقسام کی شناخت کرنا۔ یہ نقطہ نظر غلطی کا شکار ہیں اور پیمانہ کرنا مشکل ہے، خاص طور پر جب فارم کی اقسام میں کئی تغیرات ہو سکتے ہیں۔ اس کے مطابق، یہ حل عملی طور پر تیزی سے ٹوٹ جاتے ہیں اور انسانی مداخلت کی ضرورت کو بڑھا دیتے ہیں۔
اس پوسٹ میں، ہم یہ دکھاتے ہیں کہ کس طرح آپ اپنی مرضی کے مطابق قواعد بنائے یا ورک فلو پر کارروائی کیے بغیر، فارم کے کسی بھی سیٹ کے لیے چھوٹے کوڈ کے ساتھ اپنا دستاویز تقسیم کرنے کا حل کیسے بنا سکتے ہیں۔
حل جائزہ
اس پوسٹ کے لیے، ہم یہ ظاہر کرنے کے لیے کہ آپ Amazon Textract اور Amazon Comprehend کو ایک ذہین دستاویز اسپلٹر بنانے کے لیے کس طرح استعمال کر سکتے ہیں جو کہ پہلے کے طریقوں سے زیادہ مضبوط ہے۔ رہن کی درخواستوں کے لیے دستاویزات پر کارروائی کرتے وقت، قرض لینے والا ایک ملٹی پیج پی ڈی ایف جمع کراتا ہے جو مختلف صفحات کی لمبائی کے متنوع دستاویز کی اقسام سے بنا ہوتا ہے۔ معلومات نکالنے کے لیے، صارف (مثال کے طور پر، ایک بینک) کو اس PDF کو توڑنا چاہیے۔
اگرچہ ہم رہن کے فارم کے لیے ایک مخصوص مثال دکھاتے ہیں، آپ عام طور پر اس نقطہ نظر کو پی ڈی ایف دستاویزات کے تقریباً کسی بھی سیٹ پر پیمانہ اور لاگو کر سکتے ہیں۔
ہم دستاویز سے ڈیٹا نکالنے کے لیے Amazon Textract کا استعمال کرتے ہیں اور تربیت دینے کے لیے Amazon Comprehend ہم آہنگ ڈیٹاسیٹ بناتے ہیں۔ دستاویز کی درجہ بندی کا ماڈل. اس کے بعد، ہم درجہ بندی کے ماڈل کو تربیت دیتے ہیں اور درجہ بندی کا اختتامی نقطہ بناتے ہیں جو حقیقی وقت میں دستاویز کا تجزیہ کر سکے۔ ذہن میں رکھیں کہ Amazon Textract اور Amazon Comprehend درجہ بندی کے اختتامی نکات پر چارجز ہوتے ہیں، اس لیے دیکھیں ایمیزون ٹیکسٹ کی قیمتوں کا تعین اور ایمیزون کی قیمتوں کو سمجھنا مزید معلومات کے لیے. آخر میں، ہم دکھاتے ہیں کہ ہم کس طرح اس اختتامی نقطہ کے ساتھ دستاویزات کی درجہ بندی کر سکتے ہیں اور درجہ بندی کے نتائج کی بنیاد پر دستاویزات کو تقسیم کر سکتے ہیں۔
یہ حل درج ذیل AWS خدمات کا استعمال کرتا ہے:
شرائط
آپ کو اس حل کی تعمیر اور تعیناتی کے لیے درج ذیل شرائط کو پورا کرنے کی ضرورت ہے:
- انسٹال Python 3.8.x
- انسٹال jq
- انسٹال AWS SAM CLI.
- انسٹال میں Docker.
- اس بات کو یقینی بنائیں کہ آپ ہیں پائپ نصب.
- انسٹال اور ترتیب دیں la AWS کمانڈ لائن انٹرفیس (AWS CLI)۔
- سیٹ کریں آپ کی AWS اسناد۔
حل میں بہترین طریقے سے کام کرنے کے لیے ڈیزائن کیا گیا ہے۔ us-east-1 اور us-west-2 Amazon Textract کے لیے زیادہ ڈیفالٹ کوٹے کا فائدہ اٹھانے کے لیے علاقے۔ مخصوص علاقائی کام کے بوجھ کے لیے، رجوع کریں۔ ایمیزون ٹیکسٹریکٹ اینڈ پوائنٹس اور کوٹا. یقینی بنائیں کہ آپ پورے حل کے لیے ایک ہی علاقہ استعمال کرتے ہیں۔
ریپو کو کلون کریں۔
شروع کرنے کے لیے، درج ذیل کمانڈ کو چلا کر ریپوزٹری کو کلون کریں۔ پھر ہم ورکنگ ڈائرکٹری میں سوئچ کرتے ہیں:
حل ورک فلو
حل تین ورک فلو پر مشتمل ہے:
- ورک فلو 1_اینڈ پوائنٹ بلڈر - تربیتی دستاویزات لیتا ہے اور Amazon Comprehend پر اپنی مرضی کے مطابق درجہ بندی کا اختتامی نقطہ بناتا ہے۔
- workflow2_docsplitter - دستاویز کو تقسیم کرنے کی خدمت کے طور پر کام کرتا ہے، جہاں دستاویزات کو کلاس کے لحاظ سے تقسیم کیا جاتا ہے۔ اس میں تخلیق کردہ درجہ بندی کے اختتامی نقطہ کا استعمال کیا گیا ہے۔
workflow1. - workflow3_local - ان صارفین کے لیے ہے جو انتہائی ریگولیٹڈ صنعتوں میں ہیں اور ایمیزون S3 میں ڈیٹا کو برقرار نہیں رکھ سکتے ہیں۔ یہ ورک فلو کے مقامی ورژن پر مشتمل ہے۔
workflow1اورworkflow2.
آئیے ہر ورک فلو اور وہ کیسے کام کرتے ہیں اس میں گہرا غوطہ لگائیں۔
ورک فلو 1: پی ڈی ایف، جے پی جی، یا پی این جی دستاویزات سے ایک ایمیزون کمپریہنڈ کلاسیفائر بنائیں
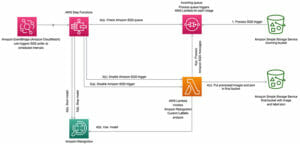
پہلا ورک فلو Amazon S3 پر ذخیرہ شدہ دستاویزات لیتا ہے اور انہیں Amazon Textract کے ذریعے دستاویزات سے ڈیٹا نکالنے کے لیے کئی مراحل کے ذریعے بھیجتا ہے۔ اس کے بعد، نکالا گیا ڈیٹا Amazon Comprehend کسٹم درجہ بندی کا اختتامی نقطہ بنانے کے لیے استعمال کیا جاتا ہے۔ یہ مندرجہ ذیل آرکیٹیکچر ڈایاگرام میں ظاہر ہوتا ہے۔

شروع کرنے کے لئے workflow1، آپ کو تربیتی ڈیٹاسیٹ فائلوں پر مشتمل فولڈر کا Amazon S3 URI درکار ہے (یہ تصاویر، سنگل پیج PDFs، یا ملٹی پیج PDFs ہو سکتے ہیں)۔ فولڈر کی ساخت اس طرح ہونی چاہیے:
متبادل طور پر، ساخت میں اضافی نیسٹڈ سب ڈائرکٹریاں ہو سکتی ہیں:
کلاس سب ڈائرکٹریز کے نام (دوسری ڈائرکٹری لیول) Amazon Comprehend کسٹم کلاسیفیکیشن ماڈل میں استعمال ہونے والی کلاسوں کے نام بن جاتے ہیں۔ مثال کے طور پر، درج ذیل فائل کے ڈھانچے میں، کے لیے کلاس form123.pdf is tax_forms:
ورک فلو شروع کرنے کے لیے، درج ذیل مراحل کو مکمل کریں:
- ڈیٹا سیٹ کو اپنی ملکیت کی S3 بالٹی میں اپ لوڈ کریں۔
تجویز یہ ہے کہ ہر کلاس کے لیے 50 سے زیادہ نمونے ہوں جن کی آپ درجہ بندی کرنا چاہتے ہیں۔ مندرجہ ذیل اسکرین شاٹ اس دستاویز کی کلاس کی ساخت کی ایک مثال دکھاتا ہے۔

- تعمیر کرو
sam-appدرج ذیل کمانڈز چلا کر (ضرورت کے مطابق فراہم کردہ کمانڈز میں ترمیم کریں):
اسٹیپ فنکشنز اسٹیٹ مشین کے لیے بلڈ کا آؤٹ پٹ ایک اے آر این ہے۔
- جب تعمیر مکمل ہو جائے، تشریف لے جائیں۔ ریاستی مشینیں۔ اسٹیپ فنکشنز کنسول پر صفحہ۔
- اپنی بنائی ہوئی ریاستی مشین کا انتخاب کریں۔

- میں سے انتخاب کریں عمل درآمد شروع کریں۔.
- درج ذیل مطلوبہ ان پٹ پیرامیٹرز درج کریں:
- میں سے انتخاب کریں عمل درآمد شروع کریں۔.

ریاستی مشین ورک فلو شروع کرتی ہے۔ ڈیٹاسیٹ کے سائز کے لحاظ سے اس میں کئی گھنٹے لگ سکتے ہیں۔ مندرجہ ذیل اسکرین شاٹ ہماری ریاستی مشین کو ترقی میں دکھاتا ہے۔

ریاستی مشین مکمل ہونے پر، گراف میں ہر قدم سبز ہوتا ہے، جیسا کہ درج ذیل اسکرین شاٹ میں دکھایا گیا ہے۔

اختتامی نقطہ کو دیکھنے کے لیے آپ ایمیزون کمپریہنڈ کنسول پر جا سکتے ہیں۔

اب آپ نے اپنی دستاویزات کا استعمال کرتے ہوئے اپنا کسٹم کلاسیفائر بنایا ہے۔ یہ اختتام کی نشاندہی کرتا ہے۔ workflow1.
ورک فلو 2: ایک اختتامی نقطہ بنائیں
دوسرا ورک فلو اختتامی نقطہ لیتا ہے جس میں آپ نے تخلیق کیا ہے۔ workflow1 اور دستاویزات کو ان کلاسوں کی بنیاد پر تقسیم کرتا ہے جن کے ساتھ ماڈل کو تربیت دی گئی ہے۔ یہ مندرجہ ذیل آرکیٹیکچر ڈایاگرام میں دکھایا گیا ہے۔

شروع کرنے کے لئے workflow2، ہم تعمیر کرتے ہیں۔ sam-app. ضرورت کے مطابق فراہم کردہ کمانڈز میں ترمیم کریں:
اسٹیک بننے کے بعد، آپ کو لوڈ بیلنسر DNS پر موصول ہوتا ہے۔ نتائج CloudFormation اسٹیک کا ٹیب۔ آپ اس اختتامی نقطہ پر درخواستیں کرنا شروع کر سکتے ہیں۔

نمونہ کی درخواست میں دستیاب ہے۔ workflow2_docsplitter/sample_request_folder/sample_s3_request.py فائل API تین پیرامیٹرز لیتا ہے: S3 بالٹی کا نام، دستاویز Amazon S3 URI، اور Amazon Comprehend درجہ بندی اختتامی نقطہ ARN۔ ورک فلو 2 صرف پی ڈی ایف ان پٹ کو سپورٹ کرتا ہے۔
اپنے ٹیسٹ کے لیے، ہم 11 صفحات پر مشتمل رہن کی دستاویز کا استعمال کرتے ہیں جس میں دستاویز کی پانچ مختلف اقسام ہیں۔






API کا جواب تمام تقسیم شدہ دستاویزات کے ساتھ .zip فائل کے لیے Amazon S3 URI ہے۔ آپ اس فائل کو اس بالٹی میں بھی تلاش کر سکتے ہیں جو آپ نے اپنی API کال میں فراہم کی تھی۔

آبجیکٹ کو ڈاؤن لوڈ کریں اور کلاس کی بنیاد پر تقسیم شدہ دستاویزات کا جائزہ لیں۔

یہ اختتام کی نشاندہی کرتا ہے۔ workflow2. ہم نے اب دکھایا ہے کہ ہم دستاویزات کی درجہ بندی اور تقسیم کرنے کے لیے کس طرح اپنی مرضی کے مطابق Amazon Comprehend درجہ بندی کا اختتامی نقطہ استعمال کر سکتے ہیں۔
ورک فلو 3: مقامی دستاویز کی تقسیم
ہمارا تیسرا ورک فلو اسی مقصد کی پیروی کرتا ہے۔ workflow1 اور workflow2 ایک Amazon Comprehend اینڈ پوائنٹ بنانے کے لیے؛ تاہم، تمام پروسیسنگ آپ کی مقامی مشین کا استعمال کرتے ہوئے ایک Amazon Comprehend مطابقت پذیر CSV فائل تیار کرنے کے لیے کی جاتی ہے۔ یہ ورک فلو انتہائی ریگولیٹڈ صنعتوں میں صارفین کے لیے بنایا گیا تھا جہاں Amazon S3 پر PDF دستاویزات کو برقرار رکھنا ممکن نہیں ہو سکتا۔ درج ذیل آرکیٹیکچر ڈایاگرام مقامی اینڈ پوائنٹ بلڈر ورک فلو کی بصری نمائندگی ہے۔

درج ذیل خاکہ مقامی دستاویز کے اسپلٹر فن تعمیر کو واضح کرتا ہے۔

حل کے لئے تمام کوڈ میں دستیاب ہے۔ workflow3_local/local_endpointbuilder.py Amazon Comprehend درجہ بندی کے اختتامی نقطہ کی تعمیر کے لیے فائل workflow3_local/local_docsplitter.py تقسیم کے لیے دستاویزات بھیجنے کے لیے۔
نتیجہ
دستاویز کی تقسیم ایک کامیاب اور ذہین دستاویز پروسیسنگ ورک فلو کی تعمیر کی کلید ہے۔ یہ اب بھی کاروبار کے لیے ایک بہت ہی متعلقہ مسئلہ ہے، خاص طور پر تنظیمیں جو اپنے روزمرہ کے کاموں کے لیے متعدد دستاویزات کی اقسام کو جمع کرتی ہیں۔ کچھ مثالوں میں پروسیسنگ انشورنس کلیم دستاویزات، انشورنس پالیسی کی درخواستیں، SEC دستاویزات، ٹیکس فارم، اور آمدنی کی تصدیق کے فارم شامل ہیں۔
اس پوسٹ میں، ہم نے لون پروسیسنگ کے لیے استعمال ہونے والی عام دستاویزات کا ایک سیٹ لیا، Amazon Textract کا استعمال کرتے ہوئے ڈیٹا نکالا، اور Amazon Comprehend کسٹم درجہ بندی کا اختتامی نقطہ بنایا۔ اس اختتامی نقطہ کے ساتھ، ہم نے آنے والی دستاویزات کی درجہ بندی کی اور انہیں ان کی متعلقہ کلاس کی بنیاد پر تقسیم کیا۔ آپ اس عمل کو دستاویزات کے تقریباً کسی بھی سیٹ پر لاگو کر سکتے ہیں جس میں مختلف صنعتوں میں درخواستیں ہیں، جیسے کہ صحت کی دیکھ بھال اور مالیاتی خدمات۔ Amazon Textract کے بارے میں مزید جاننے کے لیے، ویب صفحہ ملاحظہ کریں.
مصنفین کے بارے میں
 ادیتی رجنیش واٹر لو یونیورسٹی میں سافٹ ویئر انجینئرنگ کے پہلے سال کا طالب علم ہے۔ اس کی دلچسپیوں میں کمپیوٹر ویژن، نیچرل لینگویج پروسیسنگ اور ایج کمپیوٹنگ شامل ہیں۔ وہ کمیونٹی پر مبنی STEM آؤٹ ریچ اور وکالت کے بارے میں بھی پرجوش ہے۔ اپنے فارغ وقت میں، وہ راک چڑھنے، پیانو بجاتے، یا کامل اسکون کو بیک کرنے کا طریقہ سیکھتی ہوئی پائی جاتی ہے۔
ادیتی رجنیش واٹر لو یونیورسٹی میں سافٹ ویئر انجینئرنگ کے پہلے سال کا طالب علم ہے۔ اس کی دلچسپیوں میں کمپیوٹر ویژن، نیچرل لینگویج پروسیسنگ اور ایج کمپیوٹنگ شامل ہیں۔ وہ کمیونٹی پر مبنی STEM آؤٹ ریچ اور وکالت کے بارے میں بھی پرجوش ہے۔ اپنے فارغ وقت میں، وہ راک چڑھنے، پیانو بجاتے، یا کامل اسکون کو بیک کرنے کا طریقہ سیکھتی ہوئی پائی جاتی ہے۔
 راج پاٹھک کینیڈا اور ریاستہائے متحدہ میں فارچیون 50 اور درمیانے درجے کے FSI (بینکنگ، انشورنس، کیپٹل مارکیٹس) کے صارفین کے حل کے معمار اور تکنیکی مشیر ہیں۔ راج دستاویز نکالنے، رابطہ مرکز کی تبدیلی اور کمپیوٹر ویژن میں ایپلی کیشنز کے ساتھ مشین لرننگ میں مہارت رکھتا ہے۔
راج پاٹھک کینیڈا اور ریاستہائے متحدہ میں فارچیون 50 اور درمیانے درجے کے FSI (بینکنگ، انشورنس، کیپٹل مارکیٹس) کے صارفین کے حل کے معمار اور تکنیکی مشیر ہیں۔ راج دستاویز نکالنے، رابطہ مرکز کی تبدیلی اور کمپیوٹر ویژن میں ایپلی کیشنز کے ساتھ مشین لرننگ میں مہارت رکھتا ہے۔
- '
- 100
- 7
- ایڈیشنل
- فائدہ
- مشیر
- وکالت
- تمام
- ایمیزون
- ایمیزون کی تعریف
- ایمیزون ٹیکسٹ
- تجزیہ
- اے پی آئی
- درخواست
- ایپلی کیشنز
- فن تعمیر
- دلائل
- AWS
- سوئنگ
- بینک
- بینکنگ
- بروکر
- تعمیر
- بلڈر
- عمارت
- کاروبار
- کاروبار
- فون
- کینیڈا
- دارالحکومت
- کیپٹل مارکیٹس
- چیلنج
- بوجھ
- دعوے
- درجہ بندی
- کوڈ
- کامن
- کمپیوٹر ویژن
- کمپیوٹنگ
- تخلیق
- اسناد
- گاہکوں
- اعداد و شمار
- DNS
- میں Docker
- دستاویزات
- ایج
- کنارے کمپیوٹنگ
- اختتام پوائنٹ
- انجنیئرنگ
- ڈیٹا نکالیں
- نکالنے
- آخر
- مالی
- مالیاتی خدمات
- پہلا
- فارم
- جاؤ
- GitHub کے
- سبز
- صحت کی دیکھ بھال
- کس طرح
- کیسے
- HTTPS
- IAM
- انکم
- اضافہ
- صنعتوں
- صنعت
- معلومات
- انشورنس
- IT
- کلیدی
- زبان
- بڑے
- شروع
- جانیں
- سیکھنے
- سطح
- لائن
- لوڈ
- قرض
- مقامی
- مشین لرننگ
- Markets
- ماڈل
- رہن
- نام
- قدرتی زبان
- قدرتی زبان عملیات
- تعداد
- آپریشنز
- تنظیمیں
- پالیسی
- ازگر
- اصل وقت
- وسائل
- جواب
- نتائج کی نمائش
- کا جائزہ لینے کے
- قوانین
- رن
- چل رہا ہے
- پیمانے
- SEC
- سیریز
- سروسز
- مقرر
- سائز
- So
- سافٹ ویئر کی
- سافٹ ویئر انجینئرنگ
- حل
- حل
- مہارت دیتا ہے
- تقسیم
- شروع
- حالت
- امریکہ
- تنا
- طالب علم
- کامیاب
- کی حمایت کرتا ہے
- سوئچ کریں
- ٹیکس
- ٹیکنیکل
- ٹیسٹ
- گراف
- وقت
- ٹریننگ
- تبدیلی
- متحدہ
- ریاست ہائے متحدہ امریکہ
- یونیورسٹی
- URI
- توثیق
- نقطہ نظر
- ڈبلیو
- کام
- کام کا بہاؤ
- X