Giới thiệu
Việc phát hành ChatGPT của OpenAI đã thu hút rất nhiều sự quan tâm đến các mô hình ngôn ngữ lớn (LLM) và mọi người hiện đang nói về trí tuệ nhân tạo. Nhưng đó không chỉ là những cuộc trò chuyện thân thiện; cộng đồng máy học (ML) đã giới thiệu một thuật ngữ mới gọi là LLMOps. Tất cả chúng ta đều đã nghe nói về MLOps, nhưng LLMOps là gì? Chà, tất cả đều phụ thuộc vào cách chúng tôi xử lý và quản lý những mô hình ngôn ngữ mạnh mẽ này trong suốt vòng đời của chúng.
LLM đang chuyển đổi cách chúng ta tạo và duy trì các sản phẩm do AI điều khiển và sự thay đổi này dẫn đến nhu cầu về các công cụ mới và phương pháp hay nhất. Trong bài viết này, chúng ta sẽ tìm hiểu LLMOps và nền tảng của nó. Chúng tôi cũng sẽ xem xét việc xây dựng các sản phẩm AI bằng LLM khác với các mô hình ML truyền thống như thế nào. Ngoài ra, chúng ta sẽ xem xét MLOps (Hoạt động học máy) khác với LLMOps như thế nào do những khác biệt này. Cuối cùng, chúng ta sẽ thảo luận về những phát triển thú vị mà chúng ta có thể mong đợi trong thế giới không gian LLMOps trong thời gian ngắn.
Mục tiêu học tập:
- Có được sự hiểu biết đúng đắn về LLMOps và sự phát triển của nó.
- Tìm hiểu cách xây dựng mô hình bằng LLMOps thông qua các ví dụ.
- Biết sự khác biệt giữa LLMOps và MLOps.
- Hãy xem qua tương lai của LLMOps.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
LLMOps là gì?
LLMOps là viết tắt của Hoạt động mô hình ngôn ngữ lớn, tương tự như MLOps nhưng được thiết kế đặc biệt cho Mô hình ngôn ngữ lớn (LLM). Nó yêu cầu sử dụng các công cụ mới và các phương pháp hay nhất để xử lý mọi thứ liên quan đến các ứng dụng do LLM cung cấp, từ phát triển đến triển khai và bảo trì liên tục.
Để hiểu rõ hơn về điều này, hãy phân tích ý nghĩa của LLM và MLOps:
- LLM là các mô hình ngôn ngữ lớn có thể tạo ra ngôn ngữ của con người. Họ có hàng tỷ tham số và được đào tạo trên hàng tỷ dữ liệu văn bản.
- MLOps (Hoạt động học máy) là một bộ công cụ và phương pháp được sử dụng để quản lý vòng đời của các ứng dụng được hỗ trợ bởi học máy.
Bây giờ chúng ta đã giải thích những điều cơ bản, hãy đi sâu hơn vào chủ đề này.
Sự cường điệu xung quanh LLMOps là gì?
Thứ nhất, LLM như Chứng nhận và GPT-2 đã xuất hiện từ năm 2018. Tuy nhiên, đến nay, gần 2022 năm sau, chúng ta mới bắt gặp sự trỗi dậy nhanh chóng của ý tưởng về LLMOps. Lý do chính là LLM đã thu hút được nhiều sự chú ý của giới truyền thông với việc phát hành ChatGPT vào tháng XNUMX năm XNUMX.
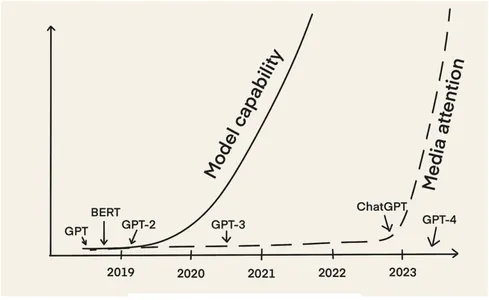
Kể từ đó, chúng tôi đã thấy nhiều loại ứng dụng khác nhau khai thác sức mạnh của LLM. Điều này bao gồm các chatbot khác nhau, từ các ví dụ quen thuộc như trò chuyệnGPT, tới những trợ lý viết lách mang tính cá nhân hơn để chỉnh sửa hoặc tóm tắt (ví dụ: khái niệm AI) và những người có kỹ năng viết quảng cáo (ví dụ: Jatpe và sao chép.ai). Nó cũng bao gồm các trợ lý lập trình để viết và gỡ lỗi mã (ví dụ: Trợ lý GitHub), kiểm tra mã (ví dụ: Bục AI) và xác định sự cố bảo mật (ví dụ: Ổ cắm AI).
Với nhiều người đang phát triển và đưa các ứng dụng dựa trên LLM vào sản xuất, mọi người đang đóng góp kinh nghiệm của mình.
“Thật dễ dàng để tạo ra thứ gì đó thú vị với LLM, nhưng rất khó để tạo ra thứ gì đó sẵn sàng sản xuất với chúng.” - Chip Huyền
Rõ ràng là việc xây dựng các ứng dụng hỗ trợ LLM sẵn sàng cho sản xuất đi kèm với những khó khăn riêng, khác với việc xây dựng các sản phẩm AI bằng mô hình ML cổ điển. Chúng ta phải phát triển các công cụ mới và các phương pháp hay nhất để giải quyết những thách thức này nhằm quản lý vòng đời ứng dụng LLM. Vì vậy, chúng tôi thấy thuật ngữ “LLMOps” được sử dụng rộng rãi hơn.
Các bước liên quan đến LLMOps là gì?
Các bước liên quan đến LLMOps ít nhất cũng tương tự như MLOps. Tuy nhiên, các bước xây dựng một ứng dụng hỗ trợ LLM sẽ khác nhau do sự khởi đầu của các mô hình nền tảng. Thay vì đào tạo LLM từ đầu, trọng tâm là thuần hóa các LLM được đào tạo trước cho các nhiệm vụ sau.
Hơn một năm trước, Andrej Karpathy đã nói về quá trình xây dựng các sản phẩm AI sẽ thay đổi như thế nào trong tương lai:
“Nhưng xu hướng quan trọng nhất là toàn bộ quá trình đào tạo mạng lưới thần kinh từ đầu cho một số nhiệm vụ mục tiêu đang nhanh chóng trở nên lỗi thời do quá trình tinh chỉnh, đặc biệt là với sự xuất hiện của các mô hình cơ sở như GPT. Các mô hình cơ sở này chỉ được đào tạo bởi một số tổ chức có tài nguyên điện toán đáng kể và hầu hết các ứng dụng đều đạt được thông qua tinh chỉnh nhẹ một phần của mạng, kỹ thuật nhanh chóng hoặc một bước tùy chọn xử lý dữ liệu hoặc mô hình thành các mạng suy luận có mục đích đặc biệt, nhỏ hơn. ” - Andrej Karpathy.
Câu trích dẫn này có thể gây ấn tượng ngay lần đầu tiên bạn đọc nó. Nhưng nó tóm tắt chính xác mọi thứ đang diễn ra gần đây, vì vậy hãy mô tả từng bước trong các phần phụ sau.
Bước 1: Lựa chọn mô hình cơ sở
Các mô hình nền tảng hoặc mô hình cơ sở là các LLM được đào tạo trước trên một lượng lớn dữ liệu có thể được sử dụng cho nhiều nhiệm vụ. Bởi vì việc đào tạo mô hình cơ sở từ đầu rất khó, tốn thời gian và cực kỳ tốn kém nên chỉ có một số cơ sở có đủ nguồn lực đào tạo cần thiết.
Để dễ hình dung, theo một nghiên cứu từ Lambda Labs vào năm 2020, việc đào tạo GPT-3 của OpenAI (với 175 tỷ thông số) sẽ cần 355 năm và 4.6 triệu USD khi sử dụng phiên bản đám mây Tesla V100.
AI hiện đang trải qua cái mà cộng đồng gọi là “Khoảnh khắc Linux”. Hiện tại, các nhà phát triển phải lựa chọn giữa hai loại mô hình cơ sở dựa trên sự trao đổi giữa hiệu suất, chi phí, tính dễ sử dụng và tính linh hoạt của mô hình độc quyền hoặc mô hình nguồn mở.
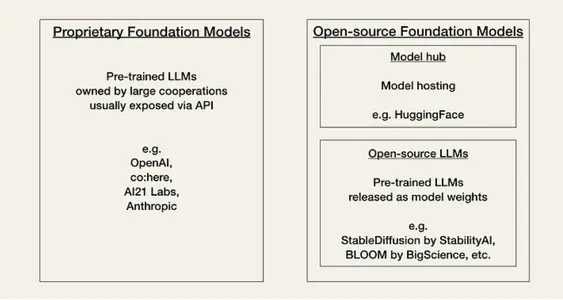
Mô hình độc quyền hoặc độc quyền là các mô hình nền tảng nguồn đóng được sở hữu bởi các công ty có đội ngũ chuyên gia lớn và ngân sách AI lớn. Chúng thường lớn hơn các mô hình nguồn mở và có hiệu suất tốt hơn. Chúng cũng được mua và nhìn chung khá dễ sử dụng. Nhược điểm chính của các mô hình độc quyền là các API (giao diện lập trình ứng dụng) đắt tiền. Ngoài ra, các mô hình nền tảng nguồn đóng cung cấp ít hoặc không có tính linh hoạt trong việc thích ứng cho các nhà phát triển.
Ví dụ về các nhà cung cấp mô hình độc quyền là:
Mô hình nguồn mở thường xuyên được tổ chức và lưu trữ trên ÔmKhuôn Mặt như một trung tâm cộng đồng. Thông thường, chúng là những mẫu nhỏ hơn với khả năng thấp hơn so với những mẫu độc quyền. Nhưng về mặt tích cực, chúng tiết kiệm hơn các mô hình độc quyền và mang lại sự linh hoạt hơn cho các nhà phát triển.
Ví dụ về các mô hình nguồn mở là:
Mã Code:
Bước này liên quan đến việc nhập tất cả các thư viện cần thiết.
from transformers import GPT2LMHeadModel, GPT2Tokenizer # Can you load pre-trained GPT-3 model and tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")Đầu ra của đoạn mã trên:

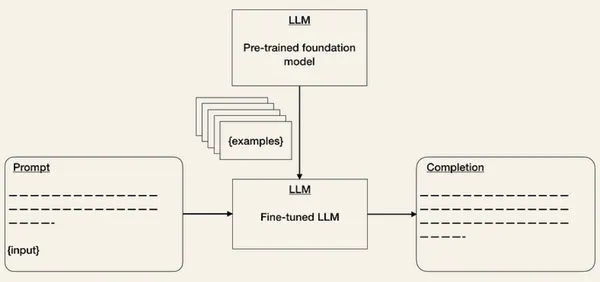
Bước 2: Thích ứng với các nhiệm vụ sau
Khi bạn đã chọn mô hình cơ sở của mình, bạn có thể truy cập LLM thông qua API của nó. Nếu bạn thường làm việc với các API khác, thì việc làm việc với API LLM về cơ bản sẽ có cảm giác hơi kỳ lạ vì không phải lúc nào cũng rõ ràng đầu vào nào sẽ tạo ra đầu ra nào trước đó. Với bất kỳ lời nhắc văn bản nào, API sẽ trả về việc hoàn thành văn bản, cố gắng khớp với mẫu của bạn.
Đây là một ví dụ về cách bạn sẽ sử dụng API OpenAI. Bạn đưa ra đầu vào API dưới dạng lời nhắc, ví dụ: nhắc = “Sửa lỗi này thành tiếng Anh chuẩn:nnAnh ấy chưa đi chợ.”
import openai
openai.api_key = ...
response = openai.Completion.create( engine = "text-davinci-003", prompt = "Correct this to standard English:nnHe no went to the market.", # ... )API sẽ đưa ra một câu trả lời có chứa câu trả lời hoàn thành['choices'][0]['text'] = “Anh ấy không đi chợ.”
Thách thức chính là LLM không mạnh mặc dù rất mạnh, và do đó, câu hỏi quan trọng là: Làm thế nào để bạn có được LLM mang lại kết quả như mong muốn?
Một mối lo ngại mà những người trả lời được đề cập trong cuộc khảo sát trong quá trình sản xuất LLM là độ chính xác của mô hình và ảo giác. Điều đó có nghĩa là việc nhận đầu ra từ API LLM ở định dạng mong muốn của bạn có thể mất một số lần lặp lại và LLM cũng có thể bị ảo giác nếu chúng không có kiến thức cụ thể cần thiết. Để giải quyết những mối lo ngại này, bạn có thể điều chỉnh các mô hình cơ sở cho các nhiệm vụ sau theo những cách sau:
- Kỹ thuật nhanh chóng là một kỹ thuật cải tiến đầu vào sao cho đầu ra phù hợp với mong đợi của bạn. Bạn có thể sử dụng các thủ thuật khác nhau để cải thiện lời nhắc của mình (xem Sách dạy nấu ăn OpenAI). Một phương pháp là cung cấp một số ví dụ về định dạng đầu ra dự kiến. Điều này tương tự như cách học không cần thực hiện hoặc học ít lần. Công cụ như LangChain or mật ong đã có sẵn để giúp bạn quản lý và phiên bản mẫu lời nhắc của mình.

- Tinh chỉnh các mô hình được đào tạo trước là một kỹ thuật được thấy trong ML. Nó có thể giúp cải thiện hiệu suất và độ chính xác của mô hình đối với nhiệm vụ cụ thể của bạn. Mặc dù điều này sẽ làm tăng nỗ lực đào tạo nhưng nó có thể giảm chi phí suy luận. Chi phí của API LLM phụ thuộc vào độ dài chuỗi đầu vào và đầu ra. Do đó, việc giảm số lượng mã thông báo đầu vào sẽ giảm chi phí API vì bạn không còn phải đưa ra ví dụ trong lời nhắc nữa.
- Dữ liệu bên ngoài: Các mô hình cơ sở thường rút ngắn thông tin theo ngữ cảnh (ví dụ: quyền truy cập vào một số tài liệu cụ thể) và có thể nhanh chóng trở nên lỗi thời. Ví dụ: GPT-4 đã được đào tạo về dữ liệu cho đến tháng 2021 năm XNUMX. Vì LLM có thể tưởng tượng ra mọi thứ nếu họ không có đủ thông tin nên chúng tôi cần có khả năng cấp cho họ quyền truy cập vào dữ liệu bên ngoài quan trọng.
- nhúng: Một cách phức tạp hơn một chút là trích xuất thông tin dưới dạng nhúng từ API LLM (ví dụ: mô tả sản phẩm) và xây dựng các ứng dụng dựa trên chúng (ví dụ: tìm kiếm, so sánh, đề xuất).
- Các lựa chọn thay thế: Khi lĩnh vực này phát triển nhanh chóng, sẽ có nhiều ứng dụng LLM hơn trong các sản phẩm AI. Một số ví dụ là điều chỉnh lệnh/điều chỉnh nhắc nhở và tinh chỉnh mô hình.
Mã Code:
from transformers import GPT2LMHeadModel, GPT2Tokenizer, TextDataset, Trainer, TrainingArguments # Load your dataset
dataset = TextDataset(tokenizer=tokenizer, file_path="your_dataset.txt") # Fine-tune the model
training_args = TrainingArguments( output_dir="./your_fine_tuned_model", overwrite_output_dir=True, num_train_epochs=3, per_device_train_batch_size=4,
) trainer = Trainer( model=model, args=training_args, data_collator=data_collator, train_dataset=dataset,
) trainer.train()
trainer.save_model()Bước 3: Đánh giá mô hình
Trong MLOps cổ điển, các mô hình ML được thể hiện trên bộ xác thực giữ lại với số liệu biểu thị hiệu suất của mô hình. Nhưng làm thế nào để bạn đánh giá việc thực hiện LLM? Làm thế nào để bạn quyết định liệu một đầu ra là tốt hay xấu? Hiện tại, có vẻ như các tổ chức đang thử nghiệm A/B mô hình của họ.
Để giúp đánh giá LLM, các công cụ như HoneyHive hoặc HumanLoop đã xuất hiện.
Mã Code:
from transformers import pipeline # Create a text generation pipeline
generator = pipeline("text-generation", model="your_fine_tuned_model") # Generate text and evaluate
generated_text = generator("Prompt text")
print(generated_text)Bước 4: Triển khai và giám sát
Thành tựu của LLM có thể rất khác nhau giữa các bản phát hành. Ví dụ: OpenAI đã cập nhật các mô hình của mình để giảm bớt việc tạo ra nội dung không phù hợp, chẳng hạn như lời nói căm thù. Kết quả là, việc quét cụm từ “như một mô hình ngôn ngữ AI” trên Twitter hiện cho thấy vô số bot.
Hiện đã có các công cụ theo dõi LLM xuất hiện, chẳng hạn như Whylabs hoặc HumanLoop.
Mã Code:
# Import your necessary libraries
from flask import Flask, request, jsonify
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import logging # Initialize Flask app
app = Flask(__name__) # you can load the fine-tuned GPT-2 model and tokenizer
model = GPT2LMHeadModel.from_pretrained("./your_fine_tuned_model")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2") # Set up logging
logging.basicConfig(filename='app.log', level=logging.INFO) # Define a route for text generation
@app.route('/generate_text', methods=['POST'])
def generate_text(): try: data = request.get_json() prompt = data['prompt'] # Generate text generated_text = model.generate( tokenizer.encode(prompt, return_tensors='pt'), max_length=100, # Adjust max length as needed num_return_sequences=1, no_repeat_ngram_size=2, top_k=50, top_p=0.95, )[0] generated_text = tokenizer.decode(generated_text, skip_special_tokens=True) # Log the request and response logging.info(f"Generated text for prompt: {prompt}") logging.info(f"Generated text: {generated_text}") return jsonify({'generated_text': generated_text}) except Exception as e: # Log any exceptions logging.error(f"Error: {str(e)}") return jsonify({'error': 'An error occurred'}), 500 if __name__ == '__main__': app.run(host='0.0.0.0', port=5000)Hoạt động của mã trên:
- Nhập các thư viện cần thiết: Điều này có nghĩa là nhập các thư viện và mô-đun cần thiết. Flask được sử dụng để xây dựng các ứng dụng web, máy biến áp được sử dụng để mang và xử lý mô hình GPT-2 và ghi nhật ký được sử dụng để ghi lại thông tin.
- Khởi tạo ứng dụng Flask.
- Tải mô hình: Bạn có thể tải mô hình GPT-2 đã được huấn luyện trước và mã thông báo tương ứng. Bạn có thể thay thế chúng ./your_fine_tuned_model bằng đường dẫn đến mô hình GPT-2 đã được tinh chỉnh thực sự của bạn.
- Thiết lập ghi nhật ký: Điều này biểu thị việc đăng nhập vào ứng dụng. Nó đặt tên tệp nhật ký thành app.log và đặt cấp độ ghi nhật ký thành INFO.
- Thiết lập bản phác thảo tuyến đường bằng Flask: Nó chỉ định rằng khi một yêu cầu POST được thực hiện tới điểm cuối /generate_text thì hàm generate_text sẽ được gọi.
- Tạo văn bản: Mã này trích xuất dữ liệu JSON từ yêu cầu POST đến. Nó giả định rằng dữ liệu JSON bao gồm trường “nhắc nhở”, đây là văn bản sẽ được sử dụng để tạo văn bản bổ sung.
- Tạo văn bản bằng GPT-2: Phần này sử dụng mô hình GPT-2 và mã thông báo đã tải để tạo văn bản dựa trên lời nhắc được cung cấp. Nó đặt các tham số tạo khác nhau, chẳng hạn như văn bản được tạo có độ dài tối đa, số lượng Sê-ri cần tạo và các tham số lấy mẫu.
- Giải mã và trả về văn bản được tạo: Sau khi tạo văn bản, nó sẽ giải mã chuỗi được tạo và loại bỏ các mã thông báo đặc biệt. Sau đó, nó trả về văn bản được tạo dưới dạng phản hồi JSON.
- Ghi nhật ký yêu cầu và phản hồi: Nó ghi lại lời nhắc của yêu cầu và văn bản được tạo trong tệp nhật ký.
- Xử lý ngoại lệ: Nếu có bất kỳ trường hợp ngoại lệ nào xảy ra trong quá trình tạo văn bản, chúng sẽ được ghi lại và ghi lại dưới dạng lỗi. Đầu ra JSON có thông báo lỗi được trả về cùng với mã trạng thái 500 để biểu thị lỗi máy chủ.
- Chạy ứng dụng Flask: Nó đảm bảo rằng ứng dụng Flask chỉ chạy khi tập lệnh được thực thi ngay lập tức. Nó chạy ứng dụng trên máy chủ '0.0.0.0' và cổng 5000, giúp việc sử dụng bất kỳ địa chỉ IP nào trở nên thuận tiện.
Đầu ra của mã trên:
Dấu nhắc đầu vào:
#{ "prompt": "Once upon a time" } Output prompt: { "generated_text": "Once upon a time, in a faraway land, there lived a..." }import csvLLMOps khác với MLOps như thế nào?
Sự khác biệt giữa MLOps và LLMOps xuất phát từ sự khác biệt trong cách chúng tôi xây dựng các sản phẩm AI bằng mô hình ML cổ điển so với LLM. Sự khác biệt chủ yếu ảnh hưởng đến việc quản lý dữ liệu, thử nghiệm, đánh giá, chi phí và độ trễ.
Data Management
Trong MLOps tiêu chuẩn, chúng ta đã quen với các mô hình ML ngốn dữ liệu. Việc đào tạo một mạng lưới thần kinh từ đầu cần rất nhiều dữ liệu được gắn nhãn và thậm chí việc tinh chỉnh một mô hình được đào tạo trước cũng cần ít nhất vài trăm mẫu. Tuy nhiên, việc làm sạch dữ liệu là điều cần thiết cho quá trình phát triển ML, vì chúng tôi biết và chấp nhận rằng các bộ dữ liệu lớn đều có lỗi.
Trong LLMOps, việc tinh chỉnh cũng tương tự như MLOps. Nhưng kỹ thuật kịp thời là một tình huống học tập không có cơ hội hoặc ít cơ hội. Điều đó có nghĩa là chúng tôi có ít mẫu nhưng được chọn lọc kỹ lưỡng.
Thử nghiệm
Trong MLOps, quá trình điều tra trông giống như việc bạn huấn luyện một mô hình từ đầu hay tinh chỉnh một mô hình được đào tạo trước. Trong cả hai trường hợp, bạn sẽ định tuyến các đầu vào, chẳng hạn như kiến trúc mô hình, siêu tham số và phần bổ sung dữ liệu cũng như các đầu ra, chẳng hạn như số liệu.
Nhưng trong LLMOps, câu hỏi đặt ra là nên thiết kế lời nhắc hay tinh chỉnh. Tuy nhiên, việc tinh chỉnh sẽ trông giống như MLOps trong LLMOps, trong khi kỹ thuật nhắc nhở bao gồm một thiết lập thử nghiệm khác liên quan đến việc quản lý lời nhắc.
Đánh giá
Trong MLOps cổ điển, bộ xác thực giữ lại với số liệu đánh giá sẽ đánh giá hiệu suất của mô hình. Do hiệu suất của LLM khó đánh giá hơn nên hiện tại, các tổ chức dường như đang sử dụng thử nghiệm A/B.
Phí Tổn
Trong khi chi phí của MLOps truyền thống thường nằm ở việc thu thập dữ liệu và đào tạo mô hình thì chi phí của LLMOps lại nằm ở khả năng suy luận. Mặc dù chúng ta có thể mong đợi một số chi phí từ việc sử dụng các API đắt tiền trong quá trình thử nghiệm, nhưng Chip Huyền cho thấy chi phí của những lời nhắc dài chỉ mang tính suy luận.
Tốc độ
Một mối quan tâm khác mà những người trả lời được đề cập trong LLM trong cuộc khảo sát sản xuất là độ trễ. Độ dài hoàn thành của LLM ảnh hưởng đáng kể đến độ trễ. Mặc dù mối lo ngại về độ trễ cũng tồn tại trong MLOps, nhưng chúng nổi bật hơn nhiều trong LLMOps vì đây là vấn đề lớn đối với tốc độ thử nghiệm trong quá trình phát triển và trải nghiệm người dùng trong sản xuất.
Tương lai của LLMOps
LLMOps là một lĩnh vực sắp ra mắt. Với tốc độ phát triển của không gian này, việc đưa ra bất kỳ dự đoán nào đều khó khăn. Thậm chí còn nghi ngờ liệu thuật ngữ “LLMOps” có tồn tại ở đây hay không. Chúng tôi chỉ chắc chắn rằng chúng tôi sẽ thấy nhiều trường hợp sử dụng LLM và công cụ mới cũng như các thử nghiệm tốt nhất để quản lý vòng đời LLM.
Lĩnh vực AI đang phát triển nhanh chóng, có khả năng khiến mọi thứ chúng ta viết hiện nay trở nên lỗi thời sau một tháng. Chúng tôi vẫn đang trong giai đoạn đầu chuyển các ứng dụng hỗ trợ LLM sang sản xuất. Có rất nhiều câu hỏi mà chúng tôi không có câu trả lời và chỉ có thời gian mới cho biết mọi thứ sẽ diễn ra như thế nào:
- Liệu thuật ngữ “LLMOps” có còn tồn tại ở đây không?
- LLMOps sẽ phát triển như thế nào trong bối cảnh MLOps? Chúng sẽ biến đổi cùng nhau hay chúng sẽ trở thành các nhóm hoạt động riêng biệt?
- “Khoảnh khắc Linux” của AI sẽ diễn ra như thế nào?
Chúng tôi có thể nói chắc chắn rằng chúng tôi sẽ sớm thấy nhiều sự phát triển, công cụ mới và các phương pháp hay nhất. Ngoài ra, chúng tôi cũng đang xem xét những nỗ lực nhằm giảm chi phí và độ trễ cho các mô hình cơ sở. Đây chắc chắn là những khoảng thời gian thú vị!
Kết luận
Kể từ khi phát hành ChatGPT của OpenAI, LLM đã trở thành chủ đề nóng trong lĩnh vực AI. Các mô hình học sâu này có thể tạo ra kết quả đầu ra bằng ngôn ngữ của con người, khiến chúng trở thành công cụ mạnh mẽ cho các nhiệm vụ như AI đàm thoại, trợ lý lập trình và trợ lý viết.
Tuy nhiên, việc đưa các ứng dụng hỗ trợ LLM vào sản xuất đặt ra những thách thức riêng, dẫn đến sự xuất hiện của một thuật ngữ mới, “LLMOps”. Nó đề cập đến bộ công cụ và phương pháp hay nhất được sử dụng để quản lý vòng đời của các ứng dụng do LLM cung cấp, bao gồm phát triển, triển khai và bảo trì.
LLMOps có thể được coi là một tiểu thể loại của MLOps. Tuy nhiên, các bước liên quan đến việc xây dựng một ứng dụng hỗ trợ LLM khác với các bước xây dựng ứng dụng bằng mô hình ML cơ bản. Thay vì đào tạo LLM từ đầu, trọng tâm là điều chỉnh LLM được đào tạo trước cho phù hợp với các nhiệm vụ sau. Điều này liên quan đến việc chọn mô hình nền tảng, sử dụng LLM trong các nhiệm vụ sau, đánh giá chúng cũng như triển khai và giám sát mô hình. Mặc dù LLMOps vẫn là một lĩnh vực tương đối mới nhưng nó chắc chắn sẽ tiếp tục phát triển và phát triển khi LLM trở nên phổ biến hơn trong ngành AI.
Các khóa chính:
- LLMOps (Hoạt động mô hình ngôn ngữ lớn) là một lĩnh vực khoa học tập trung vào việc quản lý vòng đời của các mô hình ngôn ngữ hùng mạnh như ChatGPT, chuyển đổi việc tạo và bảo trì các sản phẩm do AI điều khiển.
- Sự gia tăng các ứng dụng sử dụng Mô hình ngôn ngữ lớn (LLM) như GPT-3, GPT-3.5 và GPT-4 đã dẫn đến sự gia tăng của LLMOps.
- Quá trình LLMOps bao gồm việc chọn một mô hình cơ sở, điều chỉnh nó cho phù hợp với các nhiệm vụ cụ thể, đánh giá hiệu suất của mô hình thông qua thử nghiệm A/B và thông báo mối lo ngại về chi phí cũng như độ trễ liên quan đến các ứng dụng do LLM cung cấp.
- LLMOps khác với MLOps truyền thống về mặt quản lý dữ liệu (học vài lần), kiểm tra (kỹ thuật nhanh chóng), đánh giá (thử nghiệm A/B), chi phí (chi phí liên quan đến suy luận) và tốc độ (phản ánh độ trễ).
Nhìn chung, sự gia tăng của LLM và LLMOps mô tả sự thay đổi đáng kể trong việc xây dựng và duy trì các sản phẩm hỗ trợ AI. Tôi hy vọng bạn thích bài viết này. Bạn có thể kết nối với tôi tại đây LinkedIn.
Những câu hỏi thường gặp
Trả lời. Mô hình ngôn ngữ lớn (LLM) là những cải tiến gần đây trong mô hình học sâu để hoạt động trên ngôn ngữ của con người. Mô hình ngôn ngữ lớn là mô hình học sâu được đào tạo để hiểu và tạo văn bản theo kiểu giống con người. Đằng sau hậu trường, một mô hình máy biến áp lớn thực hiện được mọi điều kỳ diệu.
Trả lời. Các bước chính được thực hiện trong LLMOps là:
1. Chọn Mô hình ngôn ngữ lớn được đào tạo trước làm cơ sở cho ứng dụng của bạn.
2. Sửa đổi LLM cho các nhiệm vụ cụ thể bằng cách sử dụng các kỹ thuật như kỹ thuật nhanh chóng và tinh chỉnh.
3. Thường xuyên ước tính hiệu suất của LLM thông qua thử nghiệm A/B và các công cụ như HoneyHive.
4. Triển khai ứng dụng hỗ trợ LLM, liên tục theo dõi hiệu suất của ứng dụng và hợp lý hóa nó.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/09/llmops-for-machine-learning-engineering/
- : có
- :là
- :không phải
- $ LÊN
- 1
- 10
- 11
- 12
- 2018
- 2020
- 2021
- 2022
- 500
- 5000
- 7
- a
- Có khả năng
- Giới thiệu
- ở trên
- Chấp nhận
- truy cập
- Theo
- chính xác
- đạt được
- thành tích
- thích ứng
- thích ứng
- thích nghi
- thêm vào
- Ngoài ra
- địa chỉ
- điều chỉnh
- ảnh hưởng đến
- ảnh hưởng
- Sau
- cách đây
- AI
- Mô hình AI
- Hỗ trợ AI
- Tất cả
- gần như
- dọc theo
- Đã
- Ngoài ra
- Mặc dù
- luôn luôn
- số lượng
- an
- phân tích
- Phân tích Vidhya
- và
- câu trả lời
- Lo âu
- bất kì
- bất cứ điều gì
- api
- API
- ứng dụng
- xuất hiện
- Các Ứng Dụng
- các ứng dụng
- kiến trúc
- LÀ
- nảy sinh
- xung quanh
- đến
- bài viết
- nhân tạo
- trí tuệ nhân tạo
- AS
- hỏi
- trợ lý
- liên kết
- giả định
- At
- cố gắng
- sự chú ý
- có sẵn
- lý lịch
- Bad
- cơ sở
- dựa
- Khái niệm cơ bản
- BE
- bởi vì
- trở nên
- trở thành
- được
- Người mới bắt đầu
- Bắt đầu
- sau
- đằng sau hậu trường
- được
- BEST
- thực hành tốt nhất
- Hơn
- giữa
- lớn
- Tỷ
- tỷ
- cuộc thi viết blog
- cả hai
- chương trình
- mua
- Nghỉ giải lao
- Ngân sách
- xây dựng
- Xây dựng
- nhưng
- by
- gọi là
- Cuộc gọi
- CAN
- khả năng
- bị bắt
- mang
- thực
- trường hợp
- Nguyên nhân
- chắc chắn
- thách thức
- thách thức
- thay đổi
- chatbot
- ChatGPT
- Chip
- Chọn
- lựa chọn
- hoàn cảnh
- Làm sạch
- trong sáng
- đám mây
- mã
- bộ sưu tập
- đến
- cộng đồng
- Các công ty
- sự so sánh
- hoàn thành
- phức tạp
- máy tính
- Liên quan
- Mối quan tâm
- Kết nối
- nội dung
- theo ngữ cảnh
- tiếp tục
- tiếp tục
- liên tục
- góp phần
- Tiện lợi
- đàm thoại
- AI đàm thoại
- cuộc hội thoại
- chuyển đổi
- Mát mẻ
- copywriting
- sửa chữa
- Tương ứng
- Phí Tổn
- Chi phí
- vô số
- tạo
- tạo
- Hiện nay
- dữ liệu
- quản lý dữ liệu
- bộ dữ liệu
- nhiều
- Tháng mười hai
- quyết định
- giảm
- sâu
- học kĩ càng
- định nghĩa
- chắc chắn
- chứng minh
- biểu thị
- phụ thuộc
- triển khai
- triển khai
- triển khai
- mô tả
- thiết kế
- mong muốn
- Mặc dù
- phát triển
- phát triển
- phát triển
- Phát triển
- phát triển
- ĐÃ LÀM
- sự khác biệt
- khác nhau
- khó khăn
- khó khăn
- tùy ý
- thảo luận
- khác biệt
- bổ nhào
- do
- tài liệu
- làm
- dont
- nghi ngờ
- xuống
- nhược điểm
- hai
- suốt trong
- e
- Sớm hơn
- Đầu
- dễ dàng
- dễ sử dụng
- dễ dàng
- những nỗ lực
- xuất hiện
- sự xuất hiện
- chạm trán
- Điểm cuối
- Động cơ
- ky sư
- Kỹ Sư
- Tiếng Anh
- đảm bảo
- lôi
- lỗi
- đặc biệt
- thiết yếu
- ước tính
- Ether (ETH)
- đánh giá
- đánh giá
- đánh giá
- Ngay cả
- mọi người
- tất cả mọi thứ
- phát triển
- phát triển
- chính xác
- kiểm tra
- kiểm tra
- ví dụ
- ví dụ
- Trừ
- ngoại lệ
- Sàn giao dịch
- thú vị
- Thực thi
- thực hiện
- tồn tại
- mở rộng
- mong đợi
- mong đợi
- dự kiến
- đắt tiền
- kinh nghiệm
- Kinh nghiệm
- chuyên gia
- Giải thích
- khai thác
- ngoài
- trích xuất
- Chất chiết xuất
- cực kỳ
- quen
- Thời trang
- cảm thấy
- vài
- lĩnh vực
- Tập tin
- Cuối cùng
- cuối
- Tên
- lần đầu tiên
- năm
- nhấp nháy
- Linh hoạt
- Tập trung
- tập trung
- sau
- tiếp theo
- Trong
- hình thức
- định dạng
- Nền tảng
- thường xuyên
- thân thiện
- từ
- chức năng
- tương lai
- nói chung
- tạo ra
- tạo ra
- tạo
- tạo ra
- thế hệ
- máy phát điện
- được
- nhận được
- Cho
- được
- Go
- đi
- tốt
- Phát triển
- hướng dẫn
- xử lý
- Cứng
- ghét
- lời nói căm thù
- Có
- nghe
- giúp đỡ
- tại đây
- mong
- chủ nhà
- tổ chức
- NÓNG BỨC
- Độ đáng tin của
- Tuy nhiên
- HTTPS
- Hub
- Nhân loại
- một trăm
- Hype
- i
- ý tưởng
- xác định
- if
- hình ảnh
- nhập khẩu
- quan trọng
- nhập khẩu
- nâng cao
- cải tiến
- in
- bao gồm
- Bao gồm
- Incoming
- Tăng lên
- ngành công nghiệp
- Thông tin
- thông tin
- đầu vào
- đầu vào
- lấy cảm hứng từ
- ví dụ
- thay vì
- tổ chức
- Sự thông minh
- quan tâm
- thú vị
- giao diện
- trong
- giới thiệu
- điều tra
- tham gia
- liên quan đến
- liên quan đến
- IP
- Địa chỉ IP
- vấn đề
- IT
- sự lặp lại
- ITS
- json
- chỉ
- Key
- Biết
- kiến thức
- Phòng thí nghiệm
- Quốc gia
- Ngôn ngữ
- Ngôn ngữ
- lớn
- lớn hơn
- Gần đây
- Độ trễ
- một lát sau
- hàng đầu
- học tập
- ít nhất
- Led
- Chiều dài
- ít
- Cấp
- thư viện
- nằm
- vòng đời
- ánh sáng
- trọng lượng nhẹ
- Lượt thích
- ít
- tải
- đăng nhập
- đăng nhập
- khai thác gỗ
- dài
- còn
- Xem
- tìm kiếm
- NHÌN
- Rất nhiều
- thấp hơn
- máy
- học máy
- thực hiện
- ma thuật
- Chủ yếu
- duy trì
- duy trì
- bảo trì
- làm cho
- Làm
- quản lý
- quản lý
- quản lý
- nhiều
- nhiều người
- thị trường
- Trận đấu
- tối đa
- tối đa
- Có thể..
- me
- nghĩa là
- có nghĩa
- Phương tiện truyền thông
- đề cập
- tin nhắn
- phương pháp
- số liệu
- Metrics
- Might
- hùng mạnh
- triệu
- ML
- MLOps
- kiểu mẫu
- mô hình
- sửa đổi
- Modules
- thời điểm
- Màn Hình
- giám sát
- tháng
- chi tiết
- hầu hết
- chủ yếu
- nhiều
- phải
- tên
- cần thiết
- Cần
- cần thiết
- nhu cầu
- mạng
- mạng
- Thần kinh
- mạng lưới thần kinh
- Mới
- Không
- Khái niệm
- tại
- con số
- mục tiêu
- thu được
- xảy ra
- xảy ra
- of
- cung cấp
- thường
- on
- hàng loạt
- ONE
- những
- có thể
- mã nguồn mở
- OpenAI
- Hoạt động
- or
- tổ chức
- Tổ chức
- Nền tảng khác
- ra
- đầu ra
- kết thúc
- riêng
- sở hữu
- thông số
- một phần
- riêng
- con đường
- Họa tiết
- người
- hiệu suất
- riêng
- quan điểm
- đường ống dẫn
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Play
- thêm
- Phổ biến
- Bài đăng
- có khả năng
- quyền lực
- -
- mạnh mẽ
- thực hành
- Dự đoán
- quà
- chủ yếu
- quá trình
- xử lý
- Sản phẩm
- Sản lượng
- Sản phẩm
- Lập trình
- nổi bật
- độc quyền
- cho
- cung cấp
- nhà cung cấp
- công bố
- đặt
- câu hỏi
- Câu hỏi
- Mau
- trích dẫn
- phạm vi
- khác nhau,
- nhanh chóng
- hơn
- Đọc
- thực
- lý do
- gần đây
- khuyến nghị
- ghi
- làm giảm
- giảm
- đề cập
- tinh luyện
- phản ánh
- liên quan
- tương đối
- phát hành
- Phát hành
- thay thế
- trả lời
- yêu cầu
- yêu cầu
- cần phải
- đòi hỏi
- Thông tin
- người trả lời
- phản ứng
- kết quả
- trở lại
- trở về
- Trả về
- Tiết lộ
- Tăng lên
- Route
- chạy
- chạy
- nói
- quét
- cảnh
- Khoa học
- khoa học
- xước
- kịch bản
- Tìm kiếm
- Phần
- an ninh
- xem
- hình như
- dường như
- đã xem
- lựa chọn
- lựa chọn
- riêng biệt
- Tháng Chín
- Trình tự
- Loạt Sách
- máy chủ
- định
- bộ
- thiết lập
- thiết lập
- thay đổi
- ngắn
- Một thời gian ngắn
- nên
- thể hiện
- Chương trình
- có ý nghĩa
- đáng kể
- tương tự
- kể từ khi
- lành nghề
- nhỏ hơn
- lẻn
- So
- một số
- một cái gì đó
- Chẳng bao lâu
- âm thanh
- Không gian
- đặc biệt
- riêng
- đặc biệt
- phát biểu
- tốc độ
- giai đoạn
- Tiêu chuẩn
- đứng
- Trạng thái
- ở lại
- Bước
- Các bước
- Vẫn còn
- hợp lý hóa
- mạnh mẽ
- Học tập
- Stunning
- đáng kể
- như vậy
- đủ
- chắc chắn
- Khảo sát
- Hãy
- Takeaways
- nói
- Mục tiêu
- Nhiệm vụ
- nhiệm vụ
- đội
- kỹ thuật
- nói
- mẫu
- kỳ hạn
- về
- Tesla
- Kiểm tra
- văn bản
- tạo văn bản
- hơn
- việc này
- Sản phẩm
- Khái niệm cơ bản
- Tương lai
- thông tin
- thế giới
- cung cấp their dịch
- Them
- sau đó
- Đó
- Kia là
- họ
- điều
- điều này
- những
- Thông qua
- khắp
- Như vậy
- thời gian
- mất thời gian
- đến
- bên nhau
- Tokens
- nói với
- công cụ
- công cụ
- hàng đầu
- chủ đề
- đối với
- truyền thống
- Train
- đào tạo
- Hội thảo
- Chuyển đổi
- biến áp
- máy biến áp
- biến đổi
- vận chuyển
- điều trị
- khuynh hướng
- thử nghiệm
- thủ thuật
- rắc rối
- thử
- hai
- loại
- hiểu
- sự hiểu biết
- hiểu
- cho đến khi
- sắp tới
- cập nhật
- trên
- upside
- sử dụng
- đã sử dụng
- người sử dang
- Kinh nghiệm người dùng
- sử dụng
- sử dụng
- thường
- Bằng cách sử dụng
- xác nhận
- Thành phố Velo
- phiên bản
- Versus
- rất
- thông qua
- vs
- muốn
- là
- Đường..
- cách
- we
- web
- Ứng dụng web
- webp
- TỐT
- đi
- Điều gì
- Là gì
- khi nào
- liệu
- cái nào
- trong khi
- toàn bộ
- rộng
- Phạm vi rộng
- sẽ
- với
- Công việc
- đang làm việc
- thế giới
- sẽ
- viết
- viết
- năm
- năm
- nhưng
- bạn
- trên màn hình
- zephyrnet
- Học Zero-Shot





