亚马逊Redshift 是一个快速、可扩展且完全托管的云数据仓库,允许您在结构化和半结构化数据上处理和运行复杂的 SQL 分析工作负载。它还可以帮助您安全地访问操作数据库、数据湖或第三方数据集中的数据,同时最大限度地减少数据移动或复制。数以万计的客户使用 Amazon Redshift 处理大量数据、实现数据分析工作负载现代化并为其业务用户提供见解。
在这篇文章中,我们通过介绍流程的主要阶段、加速实施的可用工具以及常见用例,讨论如何在 Amazon Redshift 中成功进行概念验证。
概念验证概述
概念验证 (POC) 是一个使用代表性数据来验证技术或服务是否满足客户的技术和业务要求的过程。通过根据关键指标测试解决方案,POC 提供见解,使您能够就技术是否适合预期用例做出明智的决策。
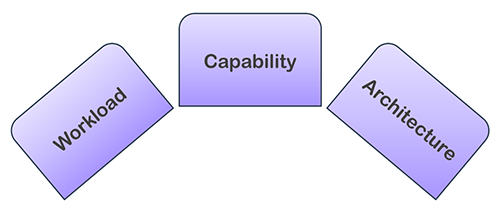
POC 验证主要分为三个领域:
- 工作量 – 选取现有工作负载的代表性部分并在 Amazon Redshift 上进行测试,例如提取、转换和加载 (ETL) 流程、报告或管理
- 能力 – 演示特定的 Amazon Redshift 功能如何实现,例如 与 Amazon Redshift 的零 ETL 集成, 数据共享或 亚马逊红移频谱,可以简化或增强您的整体架构
- 建筑 – 了解 Amazon Redshift 如何与其他 AWS 服务和工具一起融入新的或现有的架构
POC 不是:
- 规划和实施大规模迁移
- 面向用户的部署,例如部署用于长时间用户测试和验证的配置(这更像是一个试点)
- 用例的端到端实现(这更多的是原型)
概念验证过程
为了使 POC 取得成功,建议遵循并应用定义明确且结构化的流程。对于 Amazon Redshift 上的 POC,我们建议采用发现、实施和评估的三阶段流程。

发现阶段
发现阶段被认为是三个阶段中最重要、也是最长的阶段。它通过多个会话定义 POC 的范围以及需要完成和稍后评估的任务列表。范围应包含当前架构以及目标架构的输入和数据点。需要定义并记录以下项目才能确定 POC 的范围:
- 当前状态架构及其挑战
- 业务目标和 POC 的成功标准(例如成本、性能和安全性)及其相关优先级
- 用于评估和解释成功标准的评估标准,例如服务级别协议 (SLA)
- 目标架构(POC实施期间将使用的服务和工具之间的通信)
- 数据集以及表和模式的列表
明确定义范围后,您应该继续定义和规划下一阶段需要运行的任务列表,以实现范围。此外,根据对 Amazon Redshift 最新开发的技术熟悉程度,强烈建议在开始实施阶段之前举办有关 Amazon Redshift 的技术支持会议。
或者,建议使用责任分配矩阵 (RAM),尤其是在大型 POC 中。
实施阶段
实施阶段将前一阶段的输出作为输入。它由以下步骤组成:
- 通过尊重定义的 POC 架构来设置环境。
- 完成数据采集、性能测试等实施任务。
- 收集已完成任务的数据指标和统计数据。
- 分析数据,然后根据需要进行优化。
评估阶段
评估阶段是POC评估,也是该过程的最后一步。它汇总前一阶段的实施结果,对其进行解释,并评估发现阶段中描述的成功标准。
建议尽可能使用百分位数而不是平均值,以获得更好的解释。
挑战
在本节中,我们将讨论您在规划 POC 时可能遇到的主要挑战。
范围
在定义 POC 范围时的发现阶段,您可能会面临挑战,尤其是在复杂的环境中。您应该重点关注需要评估的关键要求和优先成功标准,以避免最终得到一个小型迁移项目而不是 POC。在技术内容(例如数据结构、转换作业和报告查询)方面,请确保识别并考虑尽可能少的内容,这些内容在实施阶段结束时仍将为您提供所有必要的信息。以便评估所定义的成功标准。此外,记录您所做的任何假设。
时间
应为任何 POC 项目定义一个时间段,以确保其保持重点并取得明确的结果。如果没有既定的时间框架,随着需求的变化和不必要的功能的添加,可能会发生范围蔓延。这可能会导致对正在测试的技术或概念的误导性评估。 POC 的持续时间设置取决于工作负载复杂性和资源可用性等因素。如果在没有考虑这些考虑因素的情况下已经承诺了诸如三周之类的期限,则应调整范围和计划内容以切实适合该固定时间段。
价格
云服务采用即用即付模式运行,在 POC 期间准确估计成本可能具有挑战性。超支或低估资源需求可能会影响预算分配。仔细估计 Redshift 集群的初始大小、密切监控资源使用情况并考虑设置服务限制以及 AWS 预算警报以避免意外支出非常重要。
文案
运行 POC 的团队必须准备好迎接最初的技术挑战,特别是在环境设置、数据摄取和性能测试期间。每种数据仓库技术都有自己的设计和架构,有时需要在数据结构或查询级别进行一些初始调整。这是一个预期的挑战,需要在实施阶段时间表中考虑。提前举行技术支持会议可以减轻此类障碍。
Amazon Redshift POC 工具和功能
在本节中,我们将讨论您可以根据正在进行的 POC 的具体要求和性质进行调整的工具。选择与所涉及的范围和技术相一致的工具至关重要。
AWS 分析自动化工具包
AWS 分析自动化工具包 不仅可以自动预置和集成 Amazon Redshift,还可以自动配置和集成数据库迁移服务,例如 AWS 数据库迁移服务 (AWS 数据管理系统), AWS 架构转换工具 (AWS SCT),以及 Apache JMeter。该工具包在大多数 POC 中至关重要,因为它可以自动配置基础设施并设置必要的环境。
AWS SCT
AWS SCT 通过自动将大部分数据库代码和存储对象转换为与目标数据库兼容的格式,使异构数据库迁移可预测、安全且快速。任何无法自动转换的对象都会被明确标记,以便可以手动转换它们以完成迁移。
在 POC 环境中,AWS SCT 通过简化和提高从一个数据库系统到另一个数据库系统的模式转换过程的效率而变得至关重要。鉴于 POC 的时间敏感性,AWS SCT 可以自动执行转换过程,从而促进规划以及时间和工作量的估计。此外,AWS SCT 在识别潜在兼容性问题、数据映射挑战或流程早期阶段的其他障碍方面发挥着重要作用。
而且, 数据库迁移评估报告 总结了无法自动转换为目标数据库的模式的所有操作项。 AWS SCT 入门 是一个简单的过程。另外,请考虑遵循 AWS SCT 的最佳实践.
Amazon Redshift 自动复制
Amazon Redshift 自动复制(预览) 该功能可以自动从以下位置提取数据 亚马逊简单存储服务 (Amazon S3) 使用简单的 SQL 命令转换为 Amazon Redshift。当 Amazon Redshift 自动复制检测到指定 S3 前缀中的新文件时,将调用 COPY 语句并开始加载数据。这还确保最终用户在源文件可用后不久即可在 Amazon Redshift 中获得可用的最新数据。
您可以使用此功能在整个 POC 中提取数据。要了解有关使用 SQL 命令从 Amazon S3 中的文件提取的更多信息,请参阅 使用自动复制(预览版)简化从 Amazon S3 到 Amazon Redshift 的数据摄取。该帖子还向您展示了如何使用 COPY 作业启用自动复制、如何监视作业以及注意事项和最佳实践。
红移自动装载机
自定义 Redshift 自动加载器框架 自动在目标数据库中创建架构和表,并持续将数据从 Amazon S3 加载到 Amazon Redshift。您可以在 POC 的数据摄取阶段使用它。部署和设置 Redshift Auto Loader 框架以将文件从 Amazon S3 传输到 Amazon Redshift 是一个简单的过程。
有关更多信息,请参阅 使用 AWS Glue 和自定义自动加载器框架从 Google BigQuery 迁移到 Amazon Redshift.
Apache JMeter
Apache JMeter 是一个用 Java 编写的开源负载测试应用程序,可用于对 Web 应用程序、后端服务器应用程序、数据库等进行负载测试。在数据库环境中,它是一个非常有价值的工具,可以以一致的方式重复基准测试、模拟并发工作负载以及对不同数据库配置进行可伸缩性测试。
实施 POC 时,对 Amazon Redshift 进行基准测试通常是评估的主要组成部分之一,也是了解不同 Amazon Redshift 配置性价比的关键来源。使用 Apache JMeter,您可以 为 Amazon Redshift 构建高质量基准测试.
工作负载复制器
如果您当前正在使用 Amazon Redshift 并希望复制现有的生产工作负载或隔离 POC 中的特定工作负载,您可以使用 工作负载复制器 在不同配置的 Redshift 集群(ra3.xlplus、ra3.4xl、ra3.16xl、serverless)上运行它们以进行性能评估和比较。
该实用程序能够模拟 COPY 和 UNLOAD 工作负载,并且可以在与生产集群中运行的事务和查询相同的时间间隔内运行事务和查询。然而,评估实用程序的局限性和 AWS身份和访问管理 (IAM) 安全性和合规性要求。
节点配置比较实用程序
如果您使用 Amazon Redshift 并且对 Amazon Redshift 集群中的查询性能有严格的 SLA,或者您想要根据工作负载的性价比探索不同的 Amazon Redshift 配置,您可以使用 Amazon Redshift 节点配置比较实用程序.
此实用程序可帮助并行评估使用不同 Redshift 集群配置的查询性能,并比较最终结果以找到满足您需求的最佳集群配置。同样,如果您已经在使用 Amazon Redshift 并且想要从现有的 DC2 或 DS2 实例迁移到 RA3,您可以参考我们的 升级时有关节点数量和类型的建议。在此之前,您可以在 POC 中使用此实用程序,通过重放过去的工作负载来评估新集群的性能,该实用程序与 Workload Replicator 实用程序集成,以评估不同 Amazon Redshift 配置的性能指标,以满足您的需求。
该实用程序以完全自动化的方式运行,并且具有与工作负载复制器类似的限制。但是,它需要运行该服务的用户对各种服务的完全权限 AWS CloudFormation 叠加。
用例
您有机会通过定义和选择要在 POC 期间验证的业务用例来探索 Amazon Redshift 的各种功能和方面。在本节中,我们将讨论您可以使用 POC 探索的一些特定用例。
功能评估
Amazon Redshift 包含一组功能和选项,可简化数据管道并轻松与其他服务集成。您可以使用 POC 来测试和评估其中一项或多项功能,然后再重构数据管道并在生态系统中实施它们。功能可以是现有功能或新功能,例如 零 ETL 集成, 流式摄取, 联合查询或 机器学习.

工作负载隔离
您可以使用 数据共享 Amazon Redshift 的功能可实现跨不同分析用例的工作负载隔离,并实现业务关键型 SLA,而无需复制或移动数据。
Amazon Redshift 数据共享使生产者集群能够与一个或多个消费者集群共享数据对象,从而消除数据重复。这促进了独立集群之间的协作,允许共享数据以实现创新和分析服务。共享可以发生在各个级别,例如数据库、模式、表、视图、列和用户定义的函数,从而提供细粒度的访问控制。建议使用 Workload Replicator 在工作负载隔离 POC 中进行性能评估和比较。
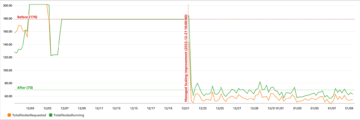
以下示例架构解释了使用数据共享的工作负载隔离。第一个图说明了使用数据共享之前的架构。

下图说明了数据共享的架构。

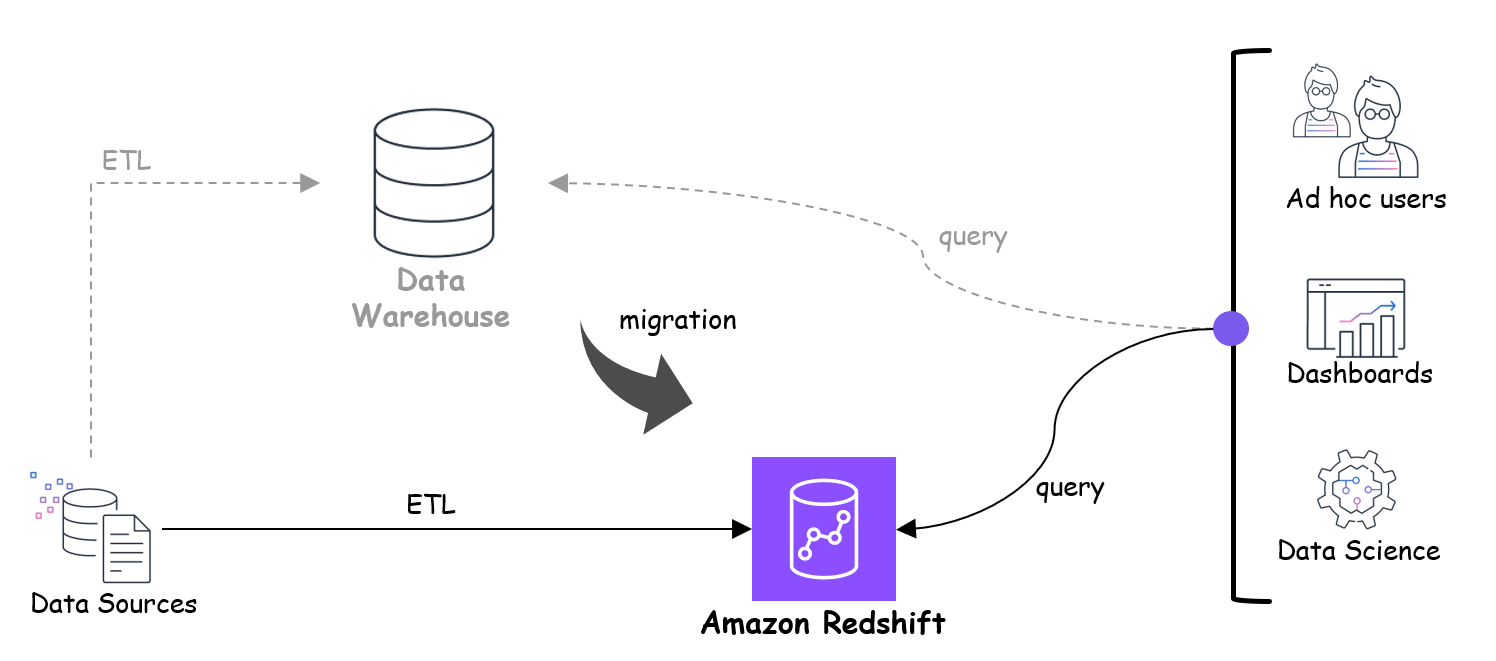
迁移到 Amazon Redshift
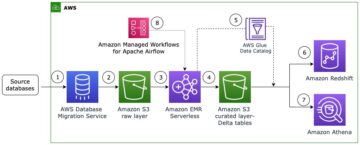
如果您有兴趣从现有数据仓库平台迁移到 Amazon Redshift,您可以通过针对选定的业务用例开发 POC 来尝试 Amazon Redshift。在这种类型的 POC 中,建议使用 AWS Analytics Automation Toolkit 设置环境,使用自动复制或 Redshift Auto Loader 进行数据提取,并使用 AWS SCT 进行架构转换。开发完成后,您可以使用 Apache JMeter 执行性能测试,它提供数据点来衡量性价比并将结果与现有平台进行比较。下图说明了此过程。
迁移到 Amazon Redshift 无服务器
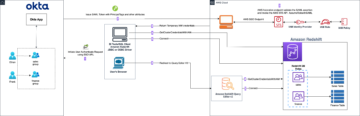
您可以将不可预测且可变的工作负载迁移到 Amazon Redshift 无服务器,这使您能够根据需要进行扩展并按使用量付费,从而使您的基础设施具有可扩展性和成本效益。如果您要将全部工作负载从预配置(DC2、RA3)迁移到无服务器,则可以使用节点配置比较实用程序进行性能评估。下图说明了此工作流程。

结论
在竞争激烈的环境中,对于旨在验证新解决方案的可行性和有效性的企业来说,进行成功的概念验证是一项战略任务。与其他以云为中心的数据仓库相比,Amazon Redshift 为您提供更好的性价比,并提供大量可帮助您实现数据管道现代化和优化的功能。有关更多详细信息,请参阅 Amazon Redshift 继续保持性价比领先地位.
通过本文中讨论的流程以及选择特定用例所需的工具,您可以加快进行 POC 的流程。这使您可以收集数据指标,帮助您了解更大规模实施建议的解决方案的潜在挑战、好处和影响。 POC 提供了评估性价比和可行性的重要数据点,这在决策中发挥着至关重要的作用。
作者简介
 齐亚德·瓦利 是 Amazon Web Services 的加速实验室解决方案架构师。 他在数据库和数据仓库方面拥有 10 多年的经验,喜欢构建可靠、可扩展且高效的解决方案。 工作之余,他喜欢运动和在大自然中度过时光。
齐亚德·瓦利 是 Amazon Web Services 的加速实验室解决方案架构师。 他在数据库和数据仓库方面拥有 10 多年的经验,喜欢构建可靠、可扩展且高效的解决方案。 工作之余,他喜欢运动和在大自然中度过时光。
 奥玛玛·库希德 是 Amazon Web Services 的加速实验室解决方案架构师。她专注于帮助各行业的客户构建可靠、可扩展且高效的解决方案。工作之余,她喜欢与家人共度时光、看电影、听音乐和学习新技术。
奥玛玛·库希德 是 Amazon Web Services 的加速实验室解决方案架构师。她专注于帮助各行业的客户构建可靠、可扩展且高效的解决方案。工作之余,她喜欢与家人共度时光、看电影、听音乐和学习新技术。
 斯里坎特·达斯 是 Amazon Web Services 的加速实验室解决方案架构师。他的专长在于构建强大、可扩展且高效的解决方案。除了专业领域之外,他还在旅行中找到乐趣,并通过社交媒体平台上富有洞察力的博客分享他的经历。
斯里坎特·达斯 是 Amazon Web Services 的加速实验室解决方案架构师。他的专长在于构建强大、可扩展且高效的解决方案。除了专业领域之外,他还在旅行中找到乐趣,并通过社交媒体平台上富有洞察力的博客分享他的经历。
- :具有
- :是
- :不是
- :在哪里
- $UP
- 10
- 100
- 150
- 214
- 352
- 500
- a
- 对,能力--
- 关于
- 加快
- 促进
- ACCESS
- 基本会计和财务报表
- 准确
- 实现
- 横过
- 操作
- 适应
- 添加
- 另外
- 后
- 驳
- 聚集
- 协议
- 致力
- 通知
- 对齐
- 所有类型
- 缓和
- 分配
- 让
- 允许
- 允许
- 沿
- 已经
- 还
- Amazon
- 亚马逊网络服务
- 其中
- 量
- an
- 解析
- 分析
- 和
- 另一个
- 任何
- 阿帕奇
- 应用领域
- 应用领域
- 使用
- 架构
- 架构
- 保健
- 地区
- AS
- 方面
- 评估
- 评定
- 分配
- 相关
- 假设
- At
- 汽车
- 自动化
- 自动化
- 自动化
- 自动表
- 自动
- 自动化和干细胞工程
- 可用性
- 可使用
- 避免
- AWS
- AWS胶水
- 后端
- 基于
- BE
- 因为
- 成为
- 很
- before
- 作为
- 基准
- 标杆
- 好处
- 最佳
- 最佳实践
- 更好
- 之间
- 超越
- BigQuery的
- 博客
- 预算
- 建立
- 建筑物
- 商业
- 企业
- 但是
- by
- CAN
- 能力
- 小心
- 案件
- 例
- 挑战
- 挑战
- 挑战
- 选择
- 清除
- 明确地
- 密切
- 云端技术
- 簇
- 码
- 合作
- 收集
- 列
- 提交
- 相当常见
- 沟通
- 比较
- 相比
- 对照
- 兼容性
- 兼容
- 竞争的
- 完成
- 完成
- 复杂
- 复杂
- 符合
- 组件
- 概念
- 进行
- 进行
- 开展
- 配置
- 配置
- 考虑
- 注意事项
- 考虑
- 一贯
- 由
- 构建
- 消费者
- 包含
- 内容
- 上下文
- 继续
- 一直
- 控制
- 转化
- 转换
- 转换
- 复制
- 仿形
- 价格
- 成本
- 可以
- 数
- 创建
- 标准
- 关键
- 电流
- 目前
- 习俗
- 合作伙伴
- data
- 数据分析
- 数据点
- 数据共享
- 数据仓库
- 数据仓库
- 数据库
- 数据库
- 数据集
- 决定
- 决策
- 定义
- 定义
- 定义
- 演示
- 根据
- 依靠
- 部署
- 部署
- 描述
- 设计
- 详情
- 发展
- 研发支持
- 发展
- 图表
- 不同
- 发现
- 讨论
- 讨论
- 不同
- 文件
- 记录
- 做
- 复制
- 为期
- ,我们将参加
- 每
- 早
- 早期
- 生态系统
- 效用
- 效率
- 高效
- 费力
- 工作的影响。
- 消除
- enable
- 启用
- 使
- 遭遇
- 结束
- 结束
- 提高
- 加强
- 确保
- 环境
- 环境中
- 特别
- 必要
- 成熟
- 评估
- 醚(ETH)
- 评估
- 评估
- 评估
- 评价
- 现有
- 预期
- 体验
- 体验
- 专门知识
- 说明
- 探索
- 扩展
- 提取
- 非常
- 面部彩妆
- 功能有助于
- 促进
- 因素
- 熟悉
- 家庭
- 高效率
- 可行性
- 专栏
- 特征
- 档
- 最后
- 找到最适合您的地方
- 发现
- (名字)
- 适合
- 适合
- 固定
- 专注焦点
- 重点
- 重点
- 遵循
- 以下
- 针对
- 格式
- FRAME
- 骨架
- 止
- ,
- 充分
- 功能
- 功能
- 得到
- 特定
- 理想中
- 去
- 谷歌
- 有
- 有
- he
- 帮助
- 帮助
- 帮助
- 这里
- 高品质
- 高度
- 他的
- 创新中心
- How To
- 但是
- HTML
- HTTP
- HTTPS
- 跨栏
- IAM
- 鉴定
- 确定
- 身分
- if
- 说明
- 影响力故事
- 势在必行
- 实施
- 履行
- 实施
- 启示
- 重要
- in
- 行业
- 信息
- 通知
- 基础设施
- 初始
- 創新
- 输入
- 输入
- 洞察
- 有见地
- 可行的洞见
- 实例
- 代替
- 整合
- 集成
- 积分
- 拟
- 有兴趣
- 解释
- 间隔
- 成
- 调用
- 参与
- 孤立
- 隔离
- 问题
- IT
- 项目
- 它的
- 爪哇岛
- 工作机会
- 喜悦
- JPG
- 键
- 实验室
- 湖泊
- 大
- 大规模
- 大
- 后来
- 最新
- 最新发展
- 铅
- 学习用品
- 学习
- Level
- 各级
- 谎言
- 喜欢
- 限制
- 范围
- 清单
- 听力
- 小
- 加载
- 装载机
- 装载
- 负载
- 位于
- 最长
- 寻找
- 主要
- 主要
- 多数
- 使
- 制作
- 制作
- 管理
- 方式
- 手动
- 制图
- 标
- 矩阵
- 可能..
- 衡量
- 媒体
- 满足
- 会见
- 指标
- 迁移
- 迁移
- 移民
- 最小
- 误导
- 模型
- 现代化
- 显示器
- 更多
- 最先进的
- 运动
- 电影
- 移动
- 多
- 音乐
- 自然
- 必要
- 需求
- 打印车票
- 需要
- 全新
- 新解决方案
- 新技术
- 下页
- 节点
- 对象
- 发生
- of
- 提供
- 经常
- on
- 一
- 那些
- 仅由
- 开放源码
- 操作
- 操作
- ZAP优势
- 优化
- 附加选项
- or
- 秩序
- 其他名称
- 我们的
- 输出
- 产量
- 学校以外
- 超过
- 最划算
- 己
- 并行
- 过去
- 为
- 演出
- 性能
- 期间
- 期
- 权限
- 相
- 阶段
- 飞行员
- 管道
- 计划
- 规划行程
- 平台
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 扮演
- 的PoC
- 点
- 一部分
- 可能
- 帖子
- 潜力
- 做法
- 可预见
- 预览
- 以前
- 优先
- 继续
- 过程
- 制片人
- 生产
- 所以专业
- 项目
- 证明
- 概念验证
- 建议
- 原型
- 提供
- 提供
- 目的
- 查询
- 询问
- 内存
- 准备
- 建议
- 建议
- 参考
- 可靠
- 报告
- 代表
- 岗位要求
- 需要
- 资源
- 关于
- 责任
- 成果
- 健壮
- 角色
- 运行
- 运行
- 同
- 样品
- 可扩展性
- 可扩展性
- 鳞片
- 缩放
- 范围
- 部分
- 安全
- 安全
- 保安
- 看到
- 选
- 选择
- 服务器
- 无服务器
- 服务
- 特色服务
- 会议
- 招生面试
- 集
- 设置
- 格局
- Share
- 共用的,
- 分享
- 共享
- 她
- 转移
- 不久
- 应该
- 作品
- 类似
- 同样
- 简易
- 简化
- 小
- So
- 社会
- 社会化媒体
- 社会化媒体平台
- 方案,
- 解决方案
- 一些
- 有时
- 来源
- 具体的
- 指定
- 花费
- 球
- 运动
- SQL
- 堆
- 阶段
- 实习
- 开始
- 开始
- 开始
- 州/领地
- 声明
- 统计
- 入住
- 步
- 步骤
- 仍
- 存储
- 简单的
- 善用
- 精简
- 严格
- 结构体
- 结构化
- 结构
- 成功
- 成功
- 顺利
- 这样
- 适应性
- 肯定
- 系统
- 采取
- 需要
- 目标
- 任务
- 团队
- 文案
- 技术
- 专业技术
- HAST
- 条款
- test
- 测试
- 测试
- 测试
- 这
- 其
- 他们
- 然后
- 从而
- 博曼
- 他们
- 第三方
- Free Introduction
- 那些
- 数千
- 三
- 通过
- 始终
- 次
- 时间敏感
- 时间表
- 至
- 工具
- 工具箱
- 工具
- 交易
- 转让
- 改造
- 转型
- 旅行
- 尝试
- 调音
- 类型
- 理解
- 意外
- 不必要
- 变幻莫测
- 用法
- 使用
- 用例
- 用过的
- 用户
- 用户
- 使用
- 运用
- 效用
- 验证
- 验证
- 有价值
- 变量
- 各个
- 意见
- 重要
- 想
- 仓库保管
- 仓储服务
- 观看
- we
- 卷筒纸
- 网络应用
- Web服务
- 周
- 井
- 定义明确
- ,尤其是
- 每当
- 是否
- 这
- 而
- 将
- 也完全不需要
- 工作
- 工作流程
- 书面
- 年
- 您
- 您一站式解决方案
- 和风网