图像创建于 DALL-E
您知道通过情绪分析可以在一定程度上预测选举结果吗?当数据科学应用于现实生活而不是使用模拟数据集时,它既有趣又非常有用。
在本文中,我们将使用 Twitter 数据进行简短的案例研究。最后,您将看到一个对现实生活产生重大影响的案例研究,这肯定会激起您的兴趣。但首先,让我们从基础知识开始。
情感分析是一种方法,用于预测情感,就像数字心理学家一样。有了这个,你创建的心理学家,你将分析的文本的命运将掌握在你的手中。你可以像著名心理学家弗洛伊德那样做,也可以像心理学家一样在场,每次咨询收费 10 美元。
就像你的心理学家倾听并理解你的情绪一样,情绪分析对文本(如评论、评论或推文)执行相同的操作,正如我们将在下一节中所做的那样。为此,我们开始对准备好的数据集进行案例研究。
为了进行情感分析,我们将使用 Kaggle 的数据集。这里这个数据集是使用 twitter api 收集的。这是该数据集的链接: https://www.kaggle.com/datasets/kazanova/sentiment140
现在,让我们开始探索数据集。
探索数据集
现在,在进行情感分析之前,让我们先探索一下我们的数据集。要读取它,请使用编码。因此,我们稍后将添加列名称。您可以增加进行数据探索的方法。标题、信息和描述方法会给你一个很好的提示;让我们看看代码。
import pandas as pd data = pd.read_csv('training.csv', encoding='ISO-8859-1', header=None)
column_names = ['target', 'ids', 'date', 'flag', 'user', 'text']
data.columns = column_names
head = data.head()
info = data.info()
describe = data.describe()
head, info, describe
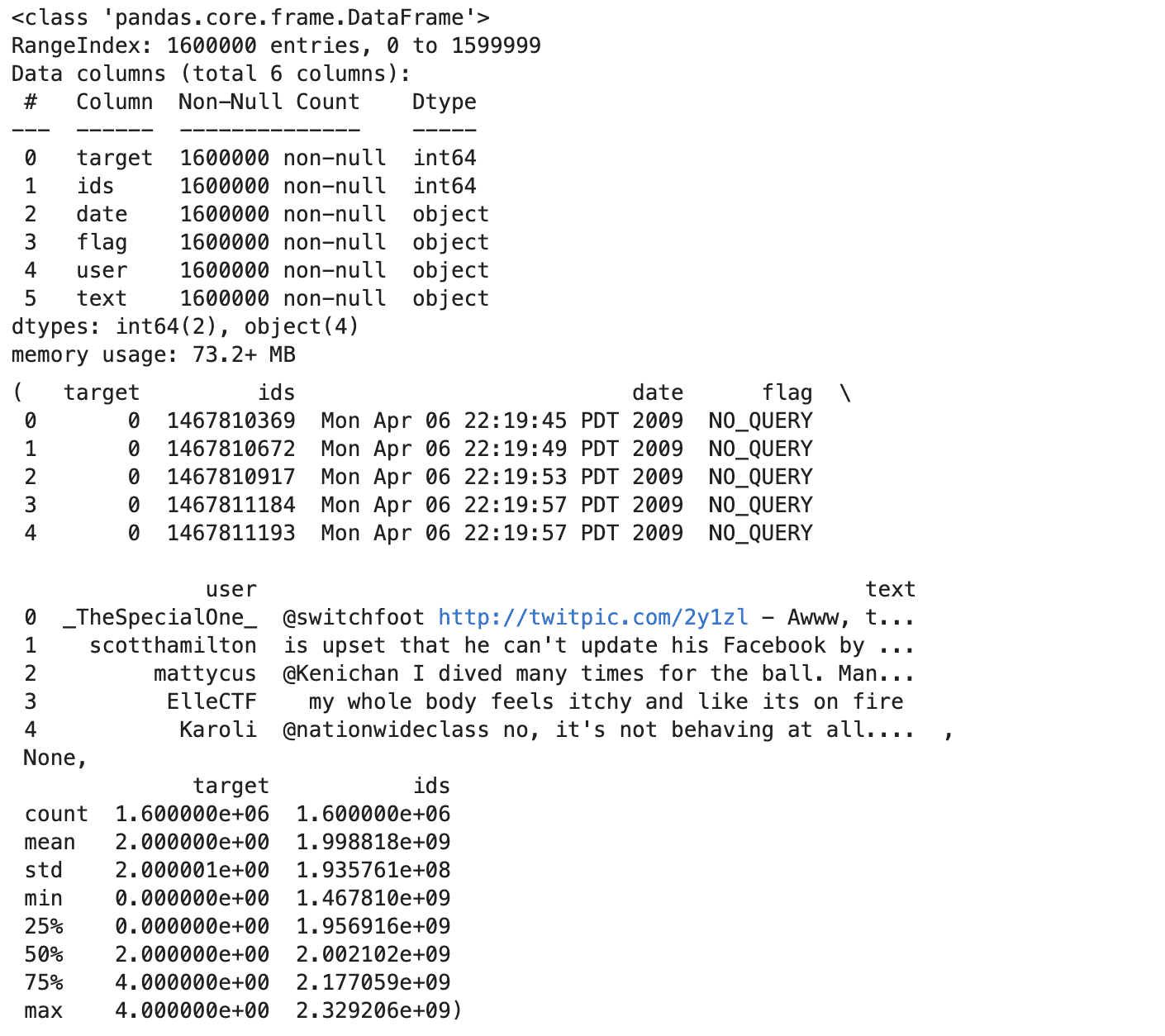
这是输出。
当然,如果您的项目没有图像限制,您可以一一运行这些方法。让我们看看我们从上述探索方法中收集到的见解。
行业洞见
- 该数据集有 1.6 万条推文,任何列中都没有缺失值。
- 每条推文都有一个目标情绪(0 表示负面,2 表示中性,4 表示正面)、ID、时间戳、标志(查询或“NO_QUERY”)、用户名和文本。
- 情绪目标是平衡的,具有相同数量的正面和负面标签。
可视化数据集
太棒了,我们拥有有关数据集的统计和结构知识。现在,让我们创建一些可视化来描绘它。现在,我们都知道最尖锐的情绪,积极的和消极的。要查看将使用哪些单词,我们将使用其中之一 蟒蛇库 称为词云。
该库将根据数据集中单词的频率来可视化您的数据集。如果单词使用频繁,看它的大小就明白了,是正相关的,如果单词大了,就应该使用得很多。
但首先,我们应该选择积极和消极的推文,并使用以下方法将它们组合在一起 python 连接方法 然后。让我们看看代码。
# Separate positive and negative tweets based on the 'target' column
positive_tweets = data[data['target'] == 4]['text']
negative_tweets = data[data['target'] == 0]['text'] # Sample some positive and negative tweets to create word clouds
sample_positive_text = " ".join(text for text in positive_tweets.sample(frac=0.1, random_state=23))
sample_negative_text = " ".join(text for text in negative_tweets.sample(frac=0.1, random_state=23)) # Generate word cloud images for both positive and negative sentiments
wordcloud_positive = WordCloud(width=800, height=400, max_words=200, background_color="white").generate(sample_positive_text)
wordcloud_negative = WordCloud(width=800, height=400, max_words=200, background_color="white").generate(sample_negative_text) # Display the generated image using matplotlib
plt.figure(figsize=(15, 7.5)) # Positive word cloud
plt.subplot(1, 2, 1)
plt.imshow(wordcloud_positive, interpolation='bilinear')
plt.title('Positive Tweets Word Cloud')
plt.axis("off") # Negative word cloud
plt.subplot(1, 2, 2)
plt.imshow(wordcloud_negative, interpolation='bilinear')
plt.title('Negative Tweets Word Cloud')
plt.axis("off") plt.show()
这是输出。
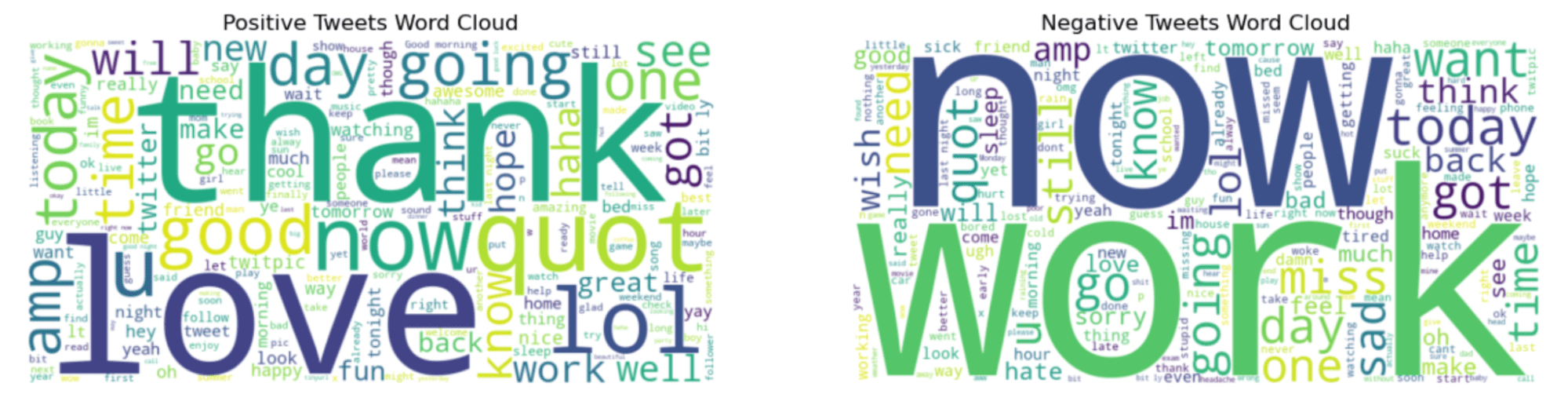
图中左边的“谢谢”和“现在”听起来更积极。然而,“工作”和“现在”看起来很有趣,因为这些词看起来经常出现在负面推文中。
情感分析
要进行情感分析,我们将遵循以下步骤;
- 预处理文本数据
- 分割数据集
- 对数据集进行向量化
- 资料转换
- 标签编码
- 训练神经网络
- 训练模型
- 评估模型(通过绘图)
现在,处理 1.6 万条推文对于您的计算机或平台来说可能是一个巨大的工作量;这就是为什么我一开始选择了 50 万条正面推文和 50 万条负面推文。
# Since we need to use a smaller dataset due to resource constraints, let's sample 100k tweets
# Balanced sampling: 50k positive and 50k negative
sample_size_per_class = 50000 positive_sample = data[data['target'] == 4].sample(n=sample_size_per_class, random_state=23)
negative_sample = data[data['target'] == 0].sample(n=sample_size_per_class, random_state=23) # Combine the samples into one dataset
balanced_sample = pd.concat([positive_sample, negative_sample]) # Check the balance of the sampled data
balanced_sample['target'].value_counts()
接下来,让我们构建神经网络。
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(max_features=10000, ngram_range=(1, 2)) # Train and test split
X_train, X_val, y_train, y_val = train_test_split(balanced_sample['text'], balanced_sample['target'], test_size=0.2, random_state=23) # After vectorizing the text data using TF-IDF
X_train_vectorized = vectorizer.fit_transform(X_train)
X_val_vectorized = vectorizer.transform(X_val) # Convert the sparse matrix to a dense matrix
X_train_vectorized = X_train_vectorized.todense()
X_val_vectorized = X_val_vectorized.todense() # Convert labels to one-hot encoding
encoder = LabelEncoder()
y_train_encoded = to_categorical(encoder.fit_transform(y_train))
y_val_encoded = to_categorical(encoder.transform(y_val)) # Define a simple neural network model
model = Sequential()
model.add(Dense(512, input_shape=(X_train_vectorized.shape[1],), activation='relu'))
model.add(Dense(2, activation='softmax')) # 2 because we have two classes # Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) # Train the model over epochs
history = model.fit(X_train_vectorized, y_train_encoded, epochs=10, batch_size=128, validation_data=(X_val_vectorized, y_val_encoded), verbose=1) # Plotting the model accuracy over epochs
plt.figure(figsize=(10, 6))
plt.plot(history.history['accuracy'], label='Train Accuracy', marker='o')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy', marker='o')
plt.title('Model Accuracy over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
plt.show()
这是输出。
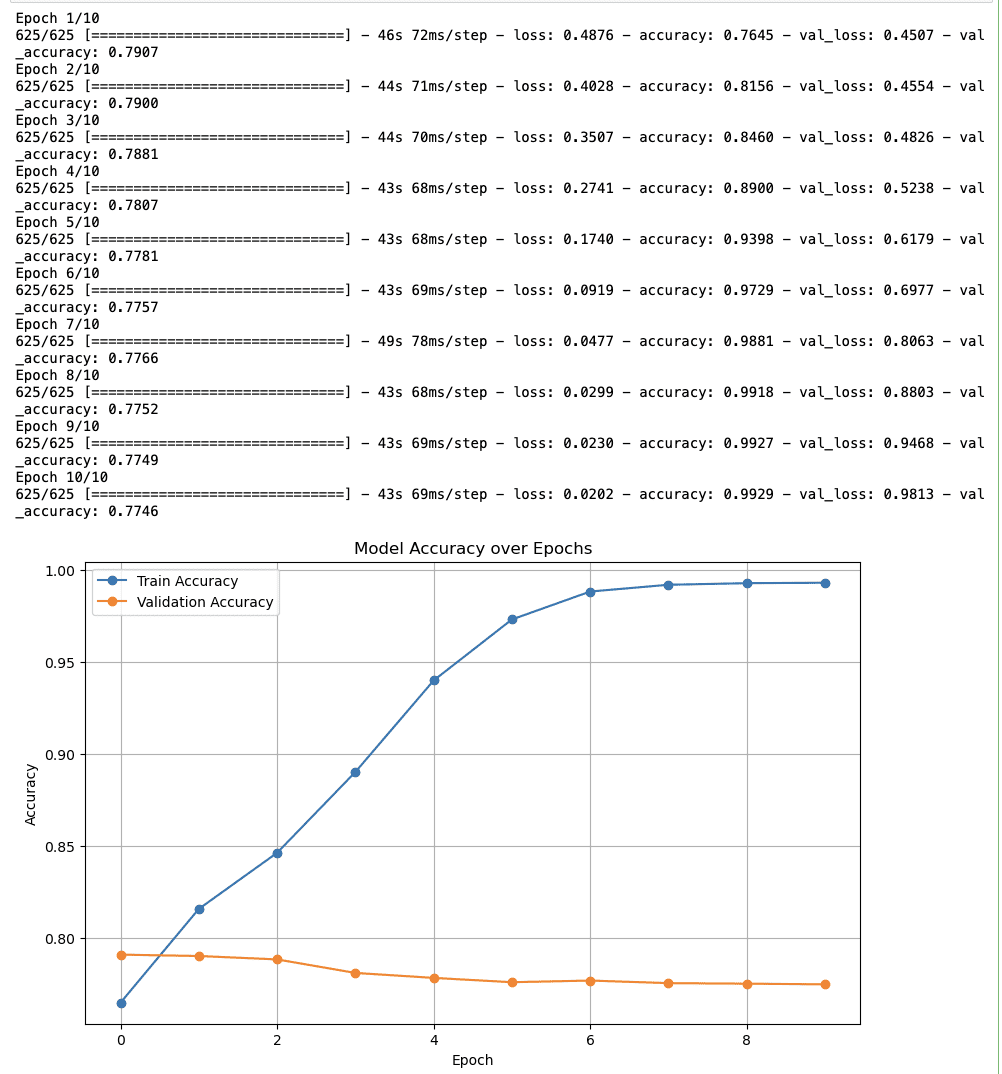
关于情感分析的最终见解
- 训练准确率:准确率从接近 80% 开始,到第十个 epoch 时不断增加到接近 100%。所以,看起来该模型正在有效地学习。
- 验证准确性:验证准确度再次开始在 80% 左右,并快速稳定地持续,这可能表明该模型无法泛化到未见过的数据。
文章一开始就引起了您的兴趣。现在让我们解释一下这背后的真实故事。
使用机器学习算法预测 Twitter 选举结果的论文,
发表在《计算机科学与通信的最新进展》上,提出了一种基于机器学习的预测选举结果的方法。 这里 你可以阅读全文。
总而言之,他们在 94.2 年美联社议会选举中进行了情绪分析,准确率高达 2019%。看起来他们真的很接近了。
如果您计划进行投资组合项目、类似的研究,或者打算进一步了解此案例研究,您可以使用 Twitter API 或 x API。以下是计划: https://developer.twitter.com/en/products/twitter-api

您可以在重大体育或政治事件发生后在 Twitter 上进行主题标签情绪分析。 2024年,美国等一些国家将举行大选,你可以在其中查看 消息.
从这个例子中可以真正看到数据科学的力量。今年,我们将见证世界各地的众多选举,因此,如果您希望引起人们对您的项目的关注,这可能是一个好主意。如果您是正在寻找学习数据科学方法的初学者,您可以找到许多现实生活中的项目, 数据科学面试题,以及博客文章 数据科学项目 在 StrataScratch 上就像这样。
内特·罗西迪 是一名数据科学家和产品战略。 他也是教授分析学的兼职教授,并且是 地层划痕,一个帮助数据科学家准备面试的平台,回答来自顶级公司的真实面试问题。 与他联系 推特:StrataScratch or LinkedIn.
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://www.kdnuggets.com/sentiment-analysis-in-python-going-beyond-bag-of-words?utm_source=rss&utm_medium=rss&utm_campaign=sentiment-analysis-in-python-going-beyond-bag-of-words
- :具有
- :是
- :不是
- :在哪里
- $UP
- 1
- 10
- 100k
- 14
- 15%
- 2%
- 2019
- 2024
- 25
- 35%
- 4
- 5
- 50000
- 6
- 7
- a
- 关于
- 以上
- 根据
- 实现
- Adam
- 加
- 附件
- 进步
- 后
- 之后
- 再次
- 瞄准
- 算法
- 所有类型
- 还
- an
- 分析
- 分析
- 分析
- 和
- 任何
- API
- 应用的
- 保健
- 围绕
- 刊文
- AS
- 组装
- At
- 关注我们
- 袋
- 言语包
- 当前余额
- 均衡
- 基于
- 基础
- BE
- 因为
- before
- 初学者
- 开始
- 背后
- 超越
- 大
- 双线性
- 博客
- 博客文章
- 都
- 建立
- 束
- 但是
- by
- 被称为
- CAN
- 案件
- 案例研究
- 充电
- 查
- 类
- 关闭
- 云端技术
- 码
- 收集
- 集
- 柱
- 列
- 结合
- 注释
- 通信
- 公司
- 一台
- 计算机科学
- 进行
- 分享链接
- 经常
- 约束
- 继续
- 转化
- 兑换
- 可以
- 国家
- 课程
- 创建信息图
- 创建
- data
- 数据科学
- 数据科学家
- 数据集
- 日期
- 定义
- 密
- 描述
- DID
- 数字
- 屏 显:
- do
- 不
- 做
- 美元
- 别
- 画
- 两
- 只
- 选举
- 选举
- 情绪
- 编码
- 结束
- 时代
- 时代
- 等于
- 醚(ETH)
- 事件
- 例子
- 说明
- 勘探
- 探索
- 探索
- 程度
- 著名
- 特色
- 情怀
- 找到最适合您的地方
- 姓氏:
- 遵循
- 针对
- 创办人
- 频率
- 频繁
- 止
- 进一步
- 生成
- 产生
- 给
- Go
- 去
- 非常好
- 得到了
- 图形
- 大
- 手
- 包括hashtag
- 有
- he
- 头
- 元首
- 帮助
- 此处
- 他
- 历史
- 但是
- HTTPS
- i
- ID
- 主意
- IDS
- if
- 图片
- 图片
- 影响力故事
- 进口
- in
- 增加
- 增加
- 表明
- info
- 可行的洞见
- 打算
- 兴趣
- 有趣
- 专属采访
- 面试问题
- 面试
- 成
- IT
- 加入
- 只是
- 掘金队
- 凯拉斯
- 知道
- 知识
- 标签
- 层
- 学习用品
- 学习
- 左
- 让
- 自学资料库
- 生活
- 喜欢
- 极限
- 友情链接
- 监听
- 看
- 看起来像
- 寻找
- LOOKS
- 占地
- 机
- 机器学习
- 主要
- 许多
- matplotlib
- 矩阵
- 方法
- 方法
- 可能
- 百万
- 失踪
- 模型
- 模型
- 更多
- 名称
- 近
- 几乎
- 需求
- 负
- 篮网
- 网络
- 网络
- 神经
- 神经网络
- 神经网络
- 一般
- 下页
- 没有
- 现在
- 数
- 众多
- of
- 折扣
- 经常
- on
- 一
- or
- 我们的
- 产量
- 超过
- 大熊猫
- 纸类
- 为
- 演出
- 图片
- 计划
- 计划
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 政治
- 个人档案
- 积极
- 帖子
- 功率
- 预测
- 都曾预测
- 预测
- Prepare
- 礼物
- 产品
- 教授
- 项目
- 项目
- 蟒蛇
- 询问
- 有疑问吗?
- 很快
- 宁
- 阅读
- 准备
- 真实
- 现实生活
- 真
- 最近
- 关系
- 复牌
- 研究
- 资源
- 成果
- 评论
- 运行
- s
- 同
- 样品
- 科学
- 科学家
- 科学家
- 搜索
- 部分
- 看到
- 看到
- 选择
- 选
- 情绪
- 情怀
- 分开
- 会议
- 最犀利
- 应该
- 显著
- 简易
- 自
- 情况
- 尺寸
- 小
- So
- 一些
- 听起来
- 疏
- 稀疏矩阵
- 分裂
- 运动
- 开始
- 启动
- 州
- 统计
- 稳步
- 步骤
- 故事
- 策略
- 结构
- 学习
- 概要
- 一定
- 目标
- 目标
- 教诲
- tensorflow
- 第十
- test
- 文本
- 比
- 这
- 基础知识
- 图
- 其
- 他们
- 那里。
- 博曼
- 他们
- 事
- Free Introduction
- 今年
- 时间戳
- 至
- 一起
- 最佳
- 培训
- 产品培训
- true
- 鸣叫
- 鸣叫
- 二
- 理解
- 理解
- 联合的
- 美国
- 使用
- 用过的
- 有用
- 用户
- 用户名
- 运用
- 验证
- 价值观
- 非常
- 想像
- 是
- 方法
- we
- ,尤其是
- 这
- 白色
- 全
- 为什么
- 将
- 见证
- Word
- 话
- 加工
- 全世界
- X
- 年
- 您
- 您一站式解决方案
- 和风网