The 2021 edition of the most beloved conference in Artificial Intelligence is here to end the year with a ‘grand finale’. The growth of the conference hasn’t ceased: last year’s conference — which we also reviewed — had 1899 main-track papers accepted, compared to this year’s 2334.

Some of the published papers have been on arxiv.org for some time now and have already had an impact. For instance, here’s a list of the top 10 most cited NeurIPS papers even before the conference starts. This is the first good starting point to browse the program and watch the authors present their work.
| Citations | Title | Authors |
|---|---|---|
| 37 | Differentially Private Learning with Adaptive Clipping | Galen Andrew et al. |
| 19 | MLP-Mixer: An all-MLP Architecture for Vision | Tolostikhin et al. |
| 19 | Revisiting ResNets: Improved Training and Scaling Strategies | Irwan Bello et al. |
| 11 | Intriguing Properties of Contrastive Losses | Ting Chen et al. |
| 11 | Variational Bayesian Reinforcement Learning with Regret Bounds | Brendan O’Donoghe |
| 11 | Gradient Starvation: A Learning Proclivity in Neural Networks | Mohammad Pezeshki et al. |
| 10 | Uncertainty Quantification and Deep Ensembles | Rahul Rahaman et al. |
| 10 | Deep learning is adaptive to intrinsic dimensionality of model smoothness in anisotropic Besov space | Taiji Suzuki et al. |
| 10 | COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining | Yu Meng et al. |
| 10 | Pay Attention to MLPs | Hanxiao Liu et al. |
Making sense of this impressive lineup is no easy feat, but with some help from the AI Research Navigator at Zeta Alpha, we went through the most relevant NeurIPS papers by citations, spotlight presentations, and some recommendations from the platform and we identified some cool works we’d like to highlight; some are already well known, and some are more of a hidden gem. Of course, these picks do not aim to be a comprehensive overview — we’ll miss many topics such as ML theory, Federated Learning, meta-learning, fairness — but there’s only so much we can fit in a blog post!
The best papers awards have been announced, which is also a good starting point though slightly theory heavy for our taste.
If this in-depth educational content is useful for you, subscribe to our AI research mailing list to be alerted when we release new material.
1. A 3D Generative Model for Structure-Based Drug Design |  Code
Code
By Shitong Luo, Jiaqi Guan, Jianzhu Ma, and Jian Peng.
 Why → Bio ML has been one of the most prominent areas of application and progress of machine learning techniques. This is a recent example of how generative models can be used in drug design based on protein bindings.
Why → Bio ML has been one of the most prominent areas of application and progress of machine learning techniques. This is a recent example of how generative models can be used in drug design based on protein bindings.
 Key insights → The idea of Masked Language Modeling (corrupting a sequence by masking some elements and trying to reconstruct it) proves to be also useful to generate molecules: masking single atoms and ‘reconstructing’ how they should be filled up. By doing this process iteratively (e.g. ‘autoregressively’) this becomes a generative model that can output candidate molecules.
Key insights → The idea of Masked Language Modeling (corrupting a sequence by masking some elements and trying to reconstruct it) proves to be also useful to generate molecules: masking single atoms and ‘reconstructing’ how they should be filled up. By doing this process iteratively (e.g. ‘autoregressively’) this becomes a generative model that can output candidate molecules.
The main advancement of this paper with respect to previous works is that the generation of molecules is conditioned to particular protein binding sites, giving researchers a better mechanism to find molecule candidates to act as a drug for a particular purpose.

For this, several tricks are required for training, such as building an encoder that’s invariant to rigid transformations (translation and rotation), cause molecules don’t care about how they’re oriented. The results are not groundbreaking and there are still caveats to the method, such as the fact that it can often output molecules that are not physically possible, but this research direction is a certainly promising one for the future of drug development.
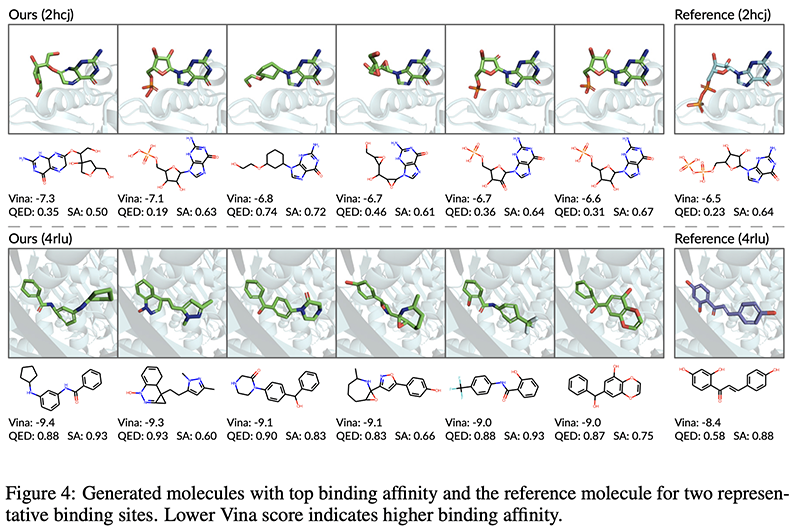
Other works on ML for molecule structures at NeurIPS: Multi-Scale Representation Learning on Proteins, Hit and Lead Discovery with Explorative RL and Fragment-based Molecule Generation, Flow Network based Generative Models for Non-Iterative Diverse Candidate Generation.
2. The Emergence of Objectness: Learning Zero-shot Segmentation from Videos | Code
By Runtao Liu, Zhirong Wu, Stella Yu, and Stephen Lin.
Authors’ TL;DR → We present an applicable zero-shot model for object segmentation by learning from unlabeled videos.
Why → Humans can easily track objects which we have never seen and don’t recognize… Machines should do the same!
Key insights → The notion of objectness is often referred to as one of the important human priors that enable us to see and reason about what we see. The key here is that we don’t need to know what the object is to know it’s an object. On the contrary, when training a neural network for image segmentation in a supervised fashion, the model will only learn to segment objects seen during training.
This paper proposes to use video data and clever tricks to set up a self-supervised training approach that leverages how objects and foreground tend to behave differently in recordings. This is reminiscent of Facebook’s DINO [1], which uncovered how after training self-supervisedly with images, Transformers’ attention matrices resembled some sort of proto-segmentation.
In this case, the authors use a combination of single frame reconstruction loss (the segmentation network) and a motion network that tries to output a feature map of how pixels move in an image. This lets them predict a future frame given a reconstruction and a motion map, which is self-supervised end-to-end.
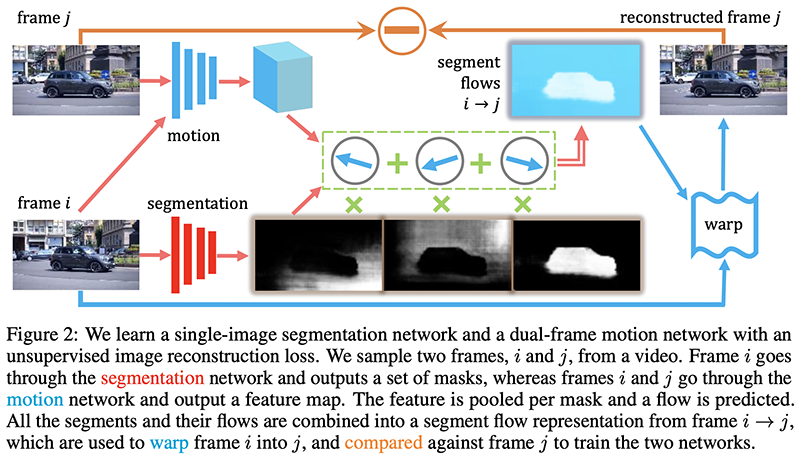
Many more tricks and considerations are required to make this work, and the results are still not earth-shattering. Still, leveraging non-labeled data for Computer Vision using videos is a key development for the future of Machine Learning, so this line of work is bound to be impactful.
Other interesting Computer Vision papers at NeurIPS: Scaling Vision with Sparse Mixture of Experts (we already covered a few months ago!) Pay Attention to MLPs (also covered back in June), Intriguing Properties of Vision Transformers, Compressed Video Contrastive Learning.
3. Multimodal Few-Shot Learning with Frozen Language Models |  Website
Website
By Maria Tsimpoukelli, Jacob Menick, Serkan Cabi, S. M. Ali Eslami, Oriol Vinyals, Felix Hill.
Authors’ TL;DR → We present a simple approach for transferring abilities of a frozen language model to a multi-modal setting (vision and language).
Why → Prompting is here to stay: now multimodal and async. Can you leverage the information in a pre-trained Language Model for vision tasks without re-training it? Well sort of… keep reading.
Key insights → The idea this paper proposes is fairly simple: train a Language Model, freeze it such that its parameters remain fixed, and then train an image encoder to encode an image into a prompt for that language model to perform a specific task. I like to conceptualize it as “learning an image-conditional prompt (image through a NN) for the model to perform a task”.
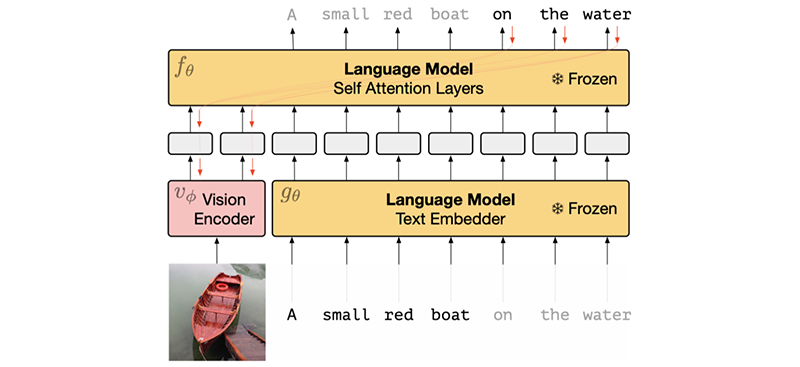
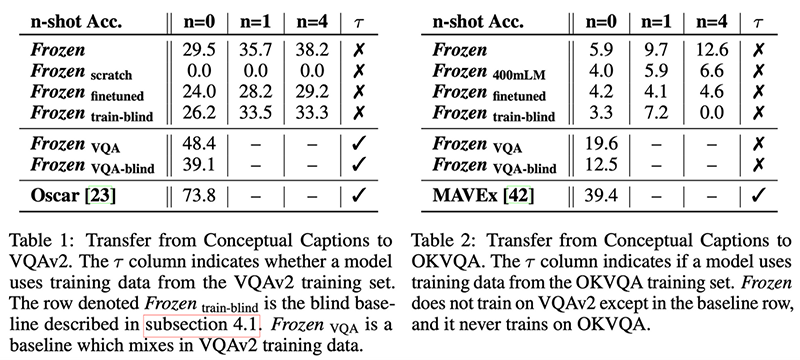
It’s a promising research direction but the results are not very impressive (yet?) in terms of absolute performance. However, it is interesting to compare the model which is fully finetuned with multimodal data (Frozen finetuned) versus one that keeps the Language Model frozen (Frozen VQA-blind): only the latter shows good generalization from the training dataset (Conceptual Captions [4]) onto the target evaluation dataset (VQAv2 [5]), still being far from a fully supervised model.
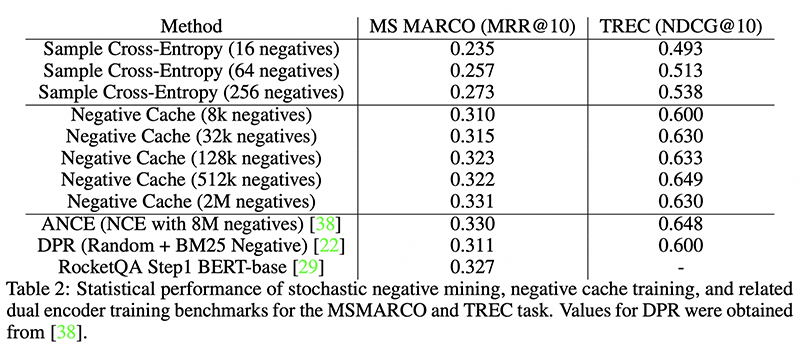
4. Efficient Training of Retrieval Models using Negative Cache
By Erik Lindgren, Sashank Reddi, Ruiqi Guo, and Sanjiv Kumar.
Authors’ TL;DR → We develop a streaming negative cache for efficient training of retrieval models.
Why → Negative sampling in dense retrieval is one of the most salient topics in the domain of neural IR! This seems to be an important step.
Key insights → A dense retrieval model aims to encode passages and queries into vectors to perform nearest neighbor search to find relevant matches. For training, a contrastive loss is often used where the similarity of positive pairs is maximized and that of negative pairs is minimized. Ideally, one could use a whole document collection as ‘negative samples’, but this would be prohibitively expensive, so instead, negative sampling techniques are often used.
One of the challenges of negative sampling techniques is that the final model quality strongly depends on how many negative samples are used — the more the better — but using many negative samples is computationally very expensive. This has led to popular proposals such as ANCE [2] where negative samples are carefully mixed with ‘hard negatives’ from an asynchronously updated index to improve a model performance at a reasonable computational cost.
In this work, the authors propose an elegant solution consisting of caching embeddings of documents when they’re calculated and only update them progressively, so instead of needing to perform a full forward pass in the encoder for all the negative samples, a large portion of cached documents are used instead, which is much faster.
This results in an arguably more elegant and simple approach that is superior empirically to existing methods.
Other information retrieval papers you might like at NeurIPS: End-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering, One Question Answering Model for Many Languages with Cross-lingual Dense Passage Retrieval, SPANN: Highly-efficient Billion-scale Approximate Nearest Neighborhood Search.
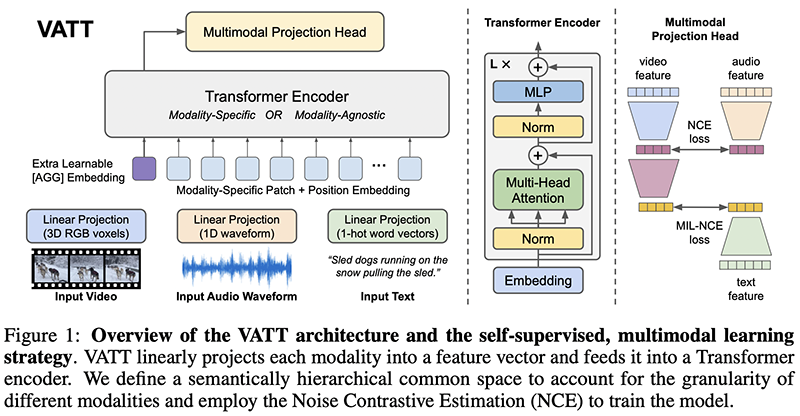
5. VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
By Hassan Akbari, Liangzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong.
Authors’ TL;DR → A pure Transformer-based pipeline for learning semantic representations from raw video, audio, and text without supervision.
Why → Another step towards the promised multimodal future land.
Key insights → A still under-explored area for large transformer models to explore is that of multimodality. This work aims at constructing representations for video, audio, and text via self-supervised learning of data in those modalities using variants of contrastive losses jointly, so the three modalities inhabit the same embedding space. To do so, they use Noise Contrastive Estimation (NCE) and use matching audio/video-frame/text triplets as positive pairs and non-matching triplets (e.g. non-corresponding segments of a video) as negative samples.
This method is similar to previous multimodal networks such as “Self-Supervised MultiModal Versatile Networks” [3], with the main difference being that it relies on a pure Transformer architecture. It achieves SOTA in major video benchmark kinetics while avoiding supervised pre-training (e.g. using large scale Imagenet labels to pre-train the model), and using only self-supervised techniques.
6. Robust Predictable Control | Website
By Ben Eysenbach, Russ R. Salakhutdinov and Sergey Levine.
Authors’ TL;DR → We propose a method for learning robust and predictable policies in RL using ideas from compression.
Why → Excellent bird-eye paper to understand some of the fundamental challenges of Reinforcement Learning through the lens of compression.
Key insights → Despite environment observations being often high dimensional (e.g. millions of pixels from images), the amount of bits of information required for an agent to make decisions is often low (e.g. doing lane keeping of a car with camera sensing). Following this insight, the authors propose Robust Predictable Control (RPC), a generic approach to learning policies that use few bits of information.
To do so, they ground their analysis on the information-theoretical perspective of how much information a model needs to predict a future state: the more predictable a state the more easily a policy can be compressed. This becomes a regularisation factor for agents to learn to ‘play it safe’ most of the time (e.g. a self-driving system will tend to avoid high uncertainty situations).

The specifics of the algorithm are much more complex so you’ll need to read the paper carefully if you want to dig into them. Beyond the particular implementation and the good empirical results, this seems to be a useful perspective to think of the tradeoffs one finds when navigating environments with uncertainty.
More on Reinforcement Learning at NeurIPS: Behavior From the Void: Unsupervised Active Pre-Training, Emergent Discrete Communication in Semantic Spaces, Near-Optimal Offline Reinforcement Learning via Double Variance Reduction.
7. FLEX: Unifying Evaluation for Few-Shot NLP |  Leaderboard | Code
Leaderboard | Code
By Jonathan Bragg, Arman Cohan, Kyle Lo, and Iz Beltagy.
Authors’ TL;DR → FLEX Principles, benchmark, and leaderboard unifying best practices for evaluating few-shot NLP; and UniFew, a simple and strong prompt-based model by unifying pre-training and downstream task formats.
Why → Few-shot learning has been the NLP cool kid for some time now. It’s time it gets its own benchmark!
Key insights → Since GPT-3 [4] broke into the scene in May 2020 with surprising zero and few-shot performance on NLP tasks thanks to ‘prompting’, it has been standard for new large language models to benchmark themselves in the zero/few-shot setting. Often, the same tasks and datasets were used for finetuned models, but in this benchmark, zero/few-shot setting is a first-class citizen.
This benchmark coming from the Allen Institute for AI seeks to standardize the patterns seen in the NLP few-shot literature, such as The principles upon which this benchmark is built are: diversity of transfer types, variable number of shots and classes, unbalanced training sets, textual labels, no extra meta-testing data, principled sample size design and proper reporting of confidence intervals, standard deviations, and individual results. Hopefully, this will facilitate apples-to-apples comparison between large language models, which isn’t guaranteed when evaluation practices are a bit all over the place: the devil is in the details!
The authors also open-source the Python toolkit used to create the benchmark, along with their own baseline for this benchmark called UniFew, and compare it to a popular recent approach “Making pre-trained language models better few-shot learners” [5] and “Few-shot Text Classification with Distributional Signatures” [6].

Other NLP papers you might like at NeurIPS: COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining.
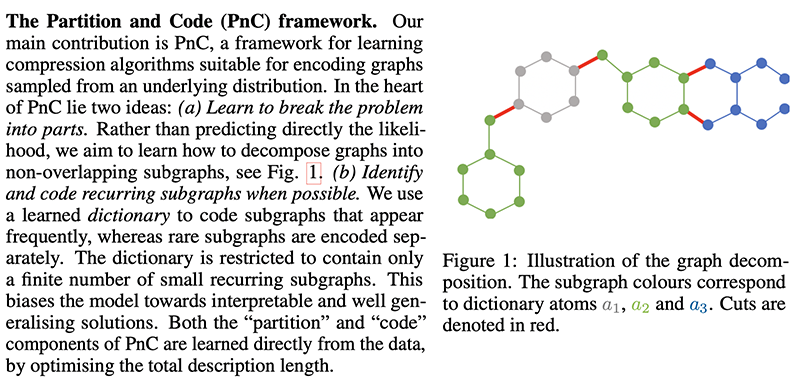
8. Partition and Code: Learning how to Compress Graphs
By Georgios Bouritsas, Andreas Loukas, Nikolaos Karalias, and Michael Bronstein.
Authors’ TL;DR → We introduce a flexible, end-to-end machine learning framework for lossless graph compression based on graph partitioning, dictionary learning and entropy coding
Why → Compressing regular data (i.e. a sequence of symbols like 1s and 0s) has been extensively studied since Shannon’s introduction of Information Theory in 1948, however, compressing graphs has different peculiarities that are less well understood. Here’s a study on how to compress graphs from first principles.
Key insights → 3 peculiarities need to be considered when designing a compression algorithm for graphs:
- Graph Isomorphisms: graphs don’t have an inherent ordering of vertices, unlike data sequences or arrays, so an optimally compressed codeword representation of a graph should be invariant to such isomorphisms.
- Evaluating the likelihood of a graph: a theoretically optimal encoder relies on knowing the likelihood of possible each possible data configuration and assigning a code whose scale is proportional to the logarithm of such likelihood (e.g. more likely graphs get more compressed into shorter codes and vice-versa). Calculating such likelihood is generally intractable due to the combinatoric explosion of medium to large graphs! The problem needs decomposition…
- If one builds a complex model to estimate the likelihood of graphs and compress based on that, the size of this model itself needs to be accounted for! Generally speaking, the more complex the model the better it’ll be able to compress data, but the larger it will be, thus incurring a tradeoff between how many bits one spends to store a model vs. how many bits one spends in storing each compressed graph instance.
While the authors don’t claim to propose an optimal solution, they present a practical one that loosely works as follows: partition graphs into common subgraphs for which you keep a dictionary of codewords whose length is proportional to the logarithm of each subgraph likelihood. The method is fully differentiable so it can be optimized with gradient descent for any given dataset of graphs.
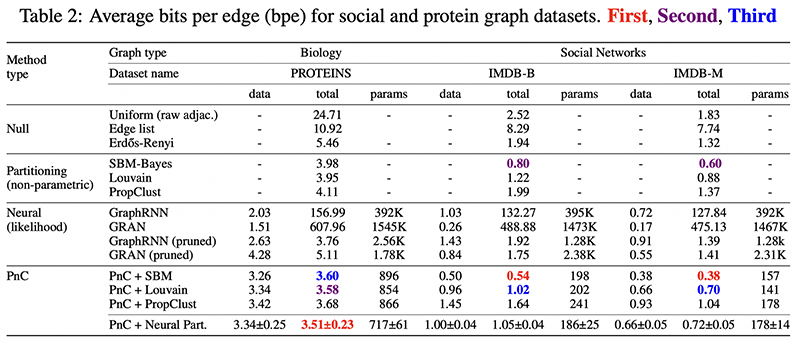
When compared empirically to existing methods, it outperforms them, but it’s still an open question to what degree this will be used, given the introduced complexity. Regardless of their particular proposal, this is an excellent paper to understand how to compress things from the ground up.
Other interesting Graph Neural Network papers at NeurIPS: SIMONe: View-Invariant, Temporally-Abstracted Object Representations via Unsupervised Video Decomposition, VQ-GNN: A Universal Framework to Scale up Graph Neural Networks using Vector Quantization, GemNet: Universal Directional Graph Neural Networks for Molecules.
9. Learning to Draw: Emergent Communication through Sketching | Code
By Daniela Mihai and Jonathon Hare.
Authors’ TL;DR → We use self-supervised play to train artificial agents to communicate by drawing and then show that with the appropriate inductive bias a human can successfully play the same games with the pretrained drawing agent.
Why → This one’s fun.
Key insights → Two models learn to communicate about images by drawing: a sender model needs to create a depiction of an image using a differentiable rasterizer that outputs ‘strokes’, and a receiver model needs to pick out which image the sender was representing out of a pool of images.
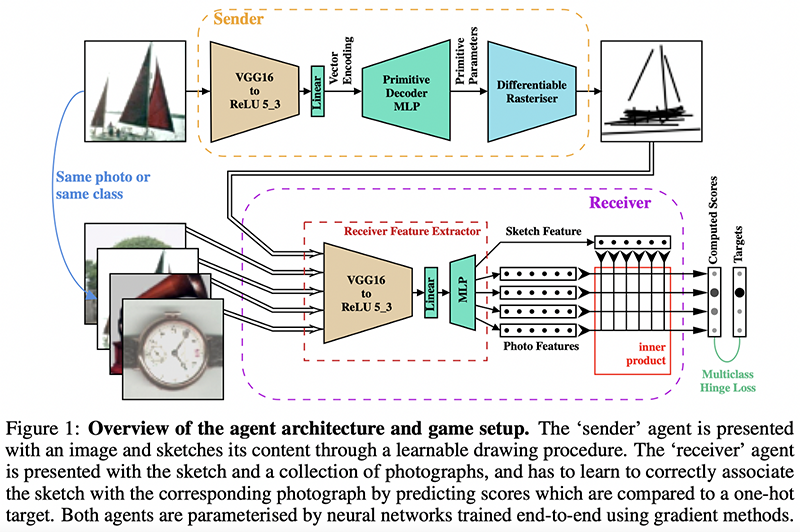
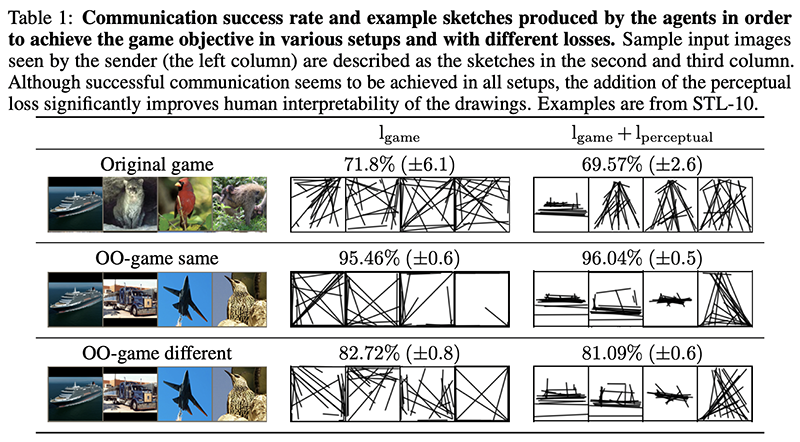
An interesting observation is how without further constraints, the sender and receiver come up with drawing representations that are not human interpretable. But they try a clever regularization trick to incentivize human interpretability: adding a ‘perceptual loss’ at the early vision stage (i.e. in early layers of the encoder model) such that activations in the model for the original image and the drawing resemble each other. This is inspired by empirical observations of how neuronal activations in humans are similar for a given picture and a drawing of it.
10. Fixes That Fail: Self-Defeating Improvements in Machine-Learning Systems
By Ruihan Wu, Chuan Guo, Awni Hannun and Laurens van der Maaten.
Authors’ TL;DR → We generally study machine learning models in isolation. But AI systems consist of many machine learning models. Can improving a model make the system worse? Yes.
Why → The modules that form an AI system can interact in complex and unintuitive ways. This thought-provoking paper studies how making subparts of a system better can make the overall system worse.
Key insights → While this paper doesn’t propose any particularly impressive method, it’s interesting food for thought to always keep at the back of your head. The authors study and formalize the important problem of how and why a system composed of various ML subsystems might become worse when individual parts are improved. This is of high importance in the practical domain cause many AI systems are composed.

The theoretical analysis runs much deeper than this, but the main gist of it is that it’s probably true that you can degrade the performance of an AI system by improving each of its parts, so think twice before re-training that one ML pipeline component!
Here’s where our selection ends. Unfortunately, we couldn’t include many interesting works that were absolutely worthy of highlighting, so you’ll need to dive into the full list of conference papers to find them. For instance, you might want to check out the latest Schmidhuber’s Meta Learning Backpropagation And Improving It, or how Resnets are not dead Revisiting ResNets: Improved Training and Scaling Strategies, or the latest equivariance NN E(n) Equivariant Normalizing Flows? We’ll have to stop here out of respect for your time. We hope you enjoyed it, you can continue exploring the conference on our platform.
References
[1] “Emerging Properties in Self-Supervised Vision Transformers” by Mathilde Caron et al. 2021.
[2] “Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval” by Lee Xiong et al. 2020.
[3] “Self-Supervised MultiModal Versatile Networks” by Jean-Baptiste Alayrac et al. 2020.
[4] “Language Models are Few-Shot Learners” by Tom B. Brown et al. 2020.
[5] “Making pre-trained language models better few-shot learners” by Tianyu Gao, Adam Fisch, Danqi Chen, 2021.
[6] “Few-shot Text Classification with Distributional Signatures” by Yujia Bao, Menghua Wu, Shiyu Chang, Regina Barzilay, 2019.
This article was originally published on Zeta Alpha and re-published to TOPBOTS with permission from the author.
Enjoy this article? Sign up for more AI updates.
We’ll let you know when we release more technical education.
The post NeurIPS 2021 – 10 Papers You Shouldn’t Miss appeared first on TOPBOTS.
- '
- "
- &
- 10
- 11
- 2019
- 2020
- 2021
- 3d
- 7
- 9
- About
- Absolute
- Act
- active
- agents
- AI
- ai research
- algorithm
- All
- already
- amount
- analysis
- Another
- applicable
- Application
- approach
- architecture
- AREA
- article
- artificial
- artificial intelligence
- audio
- authors
- awards
- Baseline
- become
- being
- beloved
- Benchmark
- BEST
- best practices
- Biggest
- Bit
- Blog
- Building
- builds
- captions
- car
- care
- Cause
- challenge
- challenges
- citizen
- classification
- code
- collection
- combination
- coming
- Common
- Communication
- compared
- complex
- Conference
- confidence
- Configuration
- content
- control
- could
- data
- decade
- deeper
- Design
- designing
- develop
- Development
- different
- discovery
- Diversity
- documents
- Doesn’t
- domain
- double
- drug
- Early
- easily
- edition
- Education
- educational
- efficient
- ends
- Environment
- estimate
- ethics
- Event
- example
- excellent
- explore
- Fashion
- faster
- Feature
- finds
- First
- fit
- following
- food
- form
- Forward
- FRAME
- Framework
- full
- fun
- further
- future
- Games
- GAO
- generate
- generation
- generative
- GitHub
- Giving
- good
- groundbreaking
- Growth
- head
- height
- help
- here
- High
- Highlight
- How
- How To
- HTTPS
- human
- Humans
- idea
- image
- Impact
- implementation
- importance
- important
- improve
- incentivize
- include
- index
- individual
- information
- insights
- inspired
- Intelligence
- isolation
- IT
- itself
- keeping
- Key
- known
- Labels
- language
- Languages
- large
- larger
- latest
- lead
- LEARN
- learning
- Led
- Leverage
- leverages
- leveraging
- Line
- List
- literature
- machine
- machine learning
- Machines
- major
- Making
- map
- matching
- material
- medium
- millions
- mixed
- ML
- model
- models
- months
- more
- most
- move
- Natural
- network
- networks
- Noise
- Notion
- number
- open
- optimized
- Other
- Paper
- performance
- perspective
- picture
- platform
- Play
- Point
- policies
- policy
- pool
- Popular
- positive
- possible
- predict
- present
- Presentations
- private
- Problem
- process
- Program
- prominent
- promising
- proposal
- propose
- proves
- purpose
- quality
- question
- Raw
- Reader
- Reading
- reasonable
- release
- relevant
- required
- research
- researchers
- Results
- robotics
- Safety
- Scale
- scaling
- Search
- segmentation
- sense
- set
- setting
- similar
- Simple
- Sites
- Size
- So
- solution
- Space
- Spotlight
- Stage
- starts
- State
- stay
- Stephen
- store
- streaming
- strong
- studies
- Study
- Successfully
- superior
- system
- Systems
- Target
- tasks
- Technical
- techniques
- Through
- time
- top
- Topics
- towards
- track
- Training
- Transferring
- Translation
- understand
- Universal
- Update
- Updates
- us
- use
- various
- versatile
- Versus
- Video
- Videos
- vision
- W
- Watch
- What
- without
- Work
- works
- wu
- year
- Yuan
- zero






