Введение
Оценка глубины изображения заключается в определении того, насколько далеко находятся объекты на изображении. Это важная проблема компьютерного зрения, потому что она помогает в таких вещах, как создание 3D-моделей, дополненная реальность и беспилотные автомобили. В прошлом люди использовали такие методы, как стереозрение или специальные датчики для оценки глубины. Но теперь появился новый метод под названием «Преобразователи предсказания глубины» (DPT), который использует глубокое обучение.
DPT — это тип модели, которая может научиться оценивать глубину, глядя на изображения. В этой статье мы узнаем больше о том, как работают DPT с использованием практического кодирования, почему они полезны и что мы можем делать с ними в различных приложениях.
Цели обучения
- Концепция преобразователей плотного предсказания (DPT) и их роль в оценке глубины изображения.
- Изучите архитектуру DPT, включая комбинацию преобразователей машинного зрения и платформ кодировщик-декодер.
- Реализуйте задачу DPT с помощью Обнимая лицо библиотека трансформаторов.
- Признать потенциальные применения DPT в различных областях.
Эта статья была опубликована в рамках Блогатон по Data Science.
Содержание
Понимание трансформаторов предсказания глубины
Трансформаторы предсказания глубины (DPT) — это уникальный вид модель глубокого обучения который специально разработан для оценки глубины объектов на изображениях. Они используют особый тип архитектуры, называемый преобразователями, который изначально был разработан для обработки языковых данных. Однако DPT адаптируют и применяют эту архитектуру для обработки визуальных данных. Одной из ключевых сильных сторон DPT является их способность фиксировать сложные взаимосвязи между различными частями изображения и моделировать зависимости, которые охватывают большие расстояния. Это позволяет ЦСТ точно предсказывать глубину или расстояние до объектов на изображении.
Архитектура преобразователей предсказания глубины
Трансформаторы предсказания глубины (DPT) объединяют трансформеры зрения с каркасом кодировщика-декодера для оценки глубины изображений. Компонент кодировщика захватывает и кодирует функции, используя механизмы внутреннего внимания, улучшая понимание взаимосвязей между различными частями изображения. Это улучшает разрешение элементов и позволяет фиксировать мелкие детали. Компонент декодера реконструирует плотные прогнозы глубины, сопоставляя закодированные признаки обратно с исходным пространством изображения, используя такие методы, как повышающая дискретизация и сверточные слои. Архитектура DPT позволяет модели учитывать глобальный контекст сцены и моделировать зависимости между различными областями изображения, что приводит к точным прогнозам глубины.
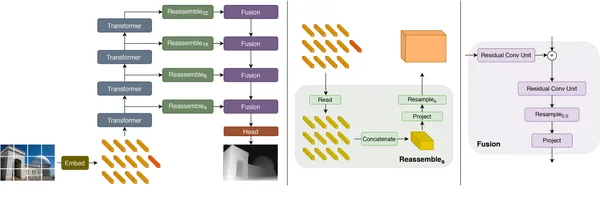
Таким образом, DPT используют преобразователи зрения и структуру кодера-декодера для оценки глубины изображений. Кодер фиксирует особенности и кодирует их с помощью механизмов внутреннего внимания, а декодер реконструирует плотные предсказания глубины. Эта архитектура позволяет DPT фиксировать мелкие детали, учитывать глобальный контекст и генерировать точные прогнозы глубины.
Реализация DPT с использованием Hugging Face Transformer
Мы увидим практическую реализацию DPT с использованием конвейера Huggin Face. Найдите весь код здесь.
Шаг 1: Установка зависимостей
Начнем с установки трансформеры package из репозитория GitHub с помощью следующей команды:
!pip install -q git+https://github.com/huggingface/transformers.git # Install the transformers package from the Hugging Face GitHub repositoryВыполните команду !pip install в Jupyter Notebook или ячейке JupyterLab, чтобы установить пакеты непосредственно в среде ноутбука.
Шаг 2: Определение модели оценки глубины
Предоставленный код определяет модель оценки глубины с использованием архитектуры DPT из библиотеки Hugging Face Transformers.
from transformers import DPTFeatureExtractor, DPTForDepthEstimation # Create a DPT feature extractor
feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-large") # Create a DPT depth estimation model
model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")Код импортирует необходимые классы из библиотеки Transformers, т.е. DPTFeatureExtractor и ДПТфорГлубина Эстиматион. Затем мы создали экземпляр экстрактора функций DPT, вызвав DPTFeatureExtractor.from_pretrained() и загрузка предварительно обученных весов из «Intel/dpt-большоймодель. Аналогичным образом они создают экземпляр модели оценки глубины DPT с помощью DPTForDepthEstimation.from_pretrained() и загружают предварительно обученные веса из той же модели «Intel/dpt-large».
Шаг 3: Загрузка изображения
Теперь мы переходим к предоставлению средств загрузки и подготовки изображения к дальнейшей обработке.
from PIL import Image
import requests # Specify the URL of the image to download
url = 'https://img.freepik.com/free-photo/full-length-shot-pretty-healthy-young-lady-walking-morning-park-with-dog_171337-18880.jpg?w=360&t=st=1689213531~exp=1689214131~hmac=67dea8e3a9c9f847575bb27e690c36c3fec45b056e90a04b68a00d5b4ba8990e' # Download and open the image using PIL
image = Image.open(requests.get(url, stream=True).raw)
Мы импортировали необходимые модули (изображение из PIL и запросы) для обработки изображений и HTTP-запросов соответственно. Он указывает URL-адрес изображения для загрузки, а затем использует запросы.получить() для получения данных изображения. Изображение.открыть() используется для открытия загруженных данных изображения как объекта изображения PIL.
Шаг 4: Проход вперед
import torch # Use torch.no_grad() to disable gradient computation
with torch.no_grad(): # Pass the pixel values through the model outputs = model(pixel_values) # Access the predicted depth values from the outputs predicted_depth = outputs.predicted_depth Приведенный выше код выполняет прямой проход модели для получения прогнозируемых значений глубины для входного изображения. Мы используем факел.no_grad() в качестве менеджера контекста, чтобы отключить вычисление градиента, что помогает уменьшить использование памяти во время логического вывода. Они передают тензор значений пикселей, pixel_values, через модель, используя model(pixel_values), и сохраняют полученные выходные данные в переменной outputs. Затем они получают доступ к предсказанным значениям глубины из outputs.predicted_depth и присваивают их переменной предсказания_глубины.
Шаг 5: Интерполяция и визуализация
Теперь мы выполняем интерполяцию предсказанных значений глубины до исходного размера изображения и преобразуем результат в изображение.
import numpy as np # Interpolate the predicted depth values to the original size
prediction = torch.nn.functional.interpolate( predicted_depth.unsqueeze(1), size=image.size[::-1], mode="bicubic", align_corners=False,
).squeeze() # Convert the interpolated depth values to a numpy array
output = prediction.cpu().numpy() # Scale and format the depth values for visualization
formatted = (output * 255 / np.max(output)).astype('uint8') # Create an image from the formatted depth values
depth = Image.fromarray(formatted)
depth
МЫ ИСПОЛЬЗУЕМ torch.nn.functional.interpolate() для интерполяции предсказанных значений глубины к исходному размеру входного изображения. Затем интерполированные значения глубины преобразуются в NumPy массив с использованием .процессор().numpy(). Затем значения глубины масштабируются и форматируются в диапазоне [0, 255] для визуализации. Наконец, изображение создается из отформатированных значений глубины, используя Изображение.из массива().
После выполнения этого кода переменная `depth` будет содержать изображение глубины, которое мы отображаем как глубину изображения.
Преимущества и преимущества
Преобразователи предсказания глубины предлагают несколько преимуществ по сравнению с традиционными методами оценки глубины изображения. Вот некоторые ключевые моменты, которые необходимо понять о преобразователях предсказания глубины (DPT):
- Лучшее внимание к деталям: DPT используют специальную часть, называемую кодировщиком, для захвата очень мелких деталей и повышения точности прогнозов.
- Понимание общей картины: DPT хорошо понимают, как связаны разные части изображения. Это помогает им понять всю сцену и точно оценить глубину.
- Различные области применения: Используйте DPT во множестве различных задач, таких как создание 3D-моделей, добавление вещей в реальный мир в дополненной реальности и помощь роботам в понимании их окружения.
- Легкость интеграции: Комбинируйте DPT с другими инструментами компьютерного зрения, такими как выделение объектов или разделение изображения на разные части. Это делает оценку глубины еще лучше и точнее.
Потенциальные применения
Оценка глубины изображения с использованием преобразователей предсказания глубины имеет множество полезных применений в различных областях. Вот несколько примеров:
- Автономная навигация: Оценка глубины важна для беспилотных автомобилей, чтобы понимать свое окружение и безопасно ориентироваться на дороге.
- Дополненная реальность: Оценка глубины помогает накладывать виртуальные объекты на реальный мир в приложениях дополненной реальности, благодаря чему они выглядят реалистично и правильно взаимодействуют с окружающей средой.
- 3D-реконструкция: Оценка глубины необходима для создания 3D-моделей объектов или сцен из обычных 2D-изображений, что позволяет нам визуализировать их в трехмерном пространстве.
- Робототехника: Оценка глубины важна для роботов при выполнении таких задач, как подбор объектов, обход препятствий и понимание расположения окружающей среды.
Заключение
Оценка глубины изображения с помощью преобразователей предсказания глубины обеспечивает надежный и точный метод оценки глубины по 2D-изображениям. Используя архитектуру преобразователя и структуру кодировщика-декодера, DPT могут эффективно фиксировать сложные детали, понимать связи между различными частями изображения и генерировать точные прогнозы глубины. Эта технология имеет потенциал для применения в различных областях, таких как автономная навигация, дополненная реальность, 3D-реконструкция и робототехника, предлагая захватывающие возможности для продвижения в этих областях. По мере развития компьютерного зрения преобразователи предсказания глубины будут продолжать играть решающую роль в достижении точной и надежной оценки глубины, что приведет к улучшениям и прорывам во многих приложениях.
Основные выводы
- Оценка глубины изображения с использованием преобразователей предсказания глубины (DPT) — это мощный и точный подход к предсказанию глубины по 2D-изображениям.
- DPT используют архитектуру преобразователя и структуру кодера-декодера для захвата мелких деталей, моделирования долгосрочных зависимостей и создания точных прогнозов глубины.
- DPT могут применяться в автономной навигации, дополненной реальности, трехмерной реконструкции и робототехнике, открывая новые возможности в различных областях.
- По мере развития компьютерного зрения преобразователи предсказания глубины будут продолжать играть важную роль в достижении точной и надежной оценки глубины, способствуя развитию многочисленных приложений.
Часто задаваемые вопросы
A. Преобразователи предсказания глубины (DPT) используют передовые методы для оценки расстояния или глубины объектов на изображениях. Разработайте их так, чтобы они очень точно предсказывали глубину, анализируя детали и отношения между различными частями изображения.
О. В DPT используется другой подход по сравнению со старыми методами. Они используют особый вид архитектуры, называемый трансформерами, который изначально использовался для языковой обработки. Это позволяет DPT лучше понимать изображение и делать более точные прогнозы глубины.
О. Они особенно полезны в беспилотных автомобилях для безопасной навигации, в дополненной реальности, чтобы виртуальные объекты выглядели реалистично в реальном мире, в создании 3D-моделей из обычных изображений и в робототехнике для таких задач, как подбор предметов и обход препятствий.
A. Комбинируйте DPT с другими методами компьютерного зрения, такими как распознавание объектов или разделение изображения на части. Это помогает улучшить общее понимание сцены и делает оценку глубины более точной.
О. DPT — это значительный шаг вперед в улучшении оценки глубины в компьютерном зрении. Они могут улавливать мелкие детали, понимать отношения между объектами и делать точные прогнозы. Это помогает лучше понимать сцены, точнее распознавать объекты и более эффективно воспринимать глубину.
Ссылки Ссылки
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Автомобили / электромобили, Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- Смещения блоков. Модернизация права собственности на экологические компенсации. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2023/07/depth-prediction-transformers/
- :имеет
- :является
- :нет
- $UP
- 1
- 11
- 12
- 14
- 20
- 2D
- 3d
- 9
- a
- способность
- О нас
- выше
- доступ
- точный
- точно
- достижение
- через
- приспосабливать
- добавить
- продвинутый
- достижения
- авансы
- Преимущества
- Позволяющий
- позволяет
- an
- аналитика
- Аналитика Видхья
- анализ
- и
- Применение
- Приложения
- Применить
- Применение
- подхода
- Программы
- архитектура
- МЫ
- области
- массив
- гайд
- AS
- спросил
- At
- внимание
- дополненная
- Дополненная реальность
- автономный
- избегающий
- прочь
- назад
- BE
- , так как:
- Преимущества
- Лучшая
- между
- большой
- Большая фотография
- блогатон
- прорывы
- но
- by
- под названием
- вызова
- CAN
- захватить
- перехватывает
- легковые автомобили
- ячейка
- классов
- код
- Кодирование
- сочетание
- объединять
- сравненный
- компонент
- вычисление
- компьютер
- Компьютерное зрение
- сама концепция
- подключенный
- Коммутация
- Рассматривать
- контекст
- продолжать
- способствовать
- содействие
- конвертировать
- переделанный
- правильно
- Создайте
- создали
- Создающий
- решающее значение
- данным
- глубоко
- глубокое обучение
- Определяет
- плотный
- надежный
- глубина
- Проект
- предназначенный
- подробнее
- развитый
- различный
- непосредственно
- усмотрение
- Дисплей
- расстояние
- do
- доменов
- скачать
- в течение
- e
- фактически
- позволяет
- повышение
- Весь
- Окружающая среда
- существенный
- оценка
- Даже
- Примеры
- захватывающий
- проведение
- Face
- далеко
- Особенность
- Особенности
- несколько
- Поля
- в заключение
- Найдите
- конец
- после
- Что касается
- формат
- вперед
- Рамки
- каркасы
- от
- функциональная
- далее
- порождать
- идти
- GitHub
- Глобальный
- глобальный контекст
- Go
- хорошо
- обрабатывать
- практический
- Есть
- полезный
- помощь
- помогает
- здесь
- Как
- Однако
- HTTP
- HTTPS
- i
- изображение
- изображений
- реализация
- Импортировать
- важную
- импорт
- улучшать
- улучшение
- улучшается
- улучшение
- in
- В том числе
- первоначально
- вход
- устанавливать
- Установка
- пример
- интеграции.
- взаимодействовать
- в
- IT
- JPG
- Jupyter Notebook
- Основные
- Вид
- язык
- слоев
- Планировка
- ведущий
- УЧИТЬСЯ
- изучение
- Кредитное плечо
- Библиотека
- такое как
- загрузка
- погрузка
- Длинное
- посмотреть
- искать
- сделать
- ДЕЛАЕТ
- Создание
- менеджер
- способ
- многих
- отображение
- означает
- механизмы
- Медиа
- Память
- метод
- методы
- модель
- Модели
- Модули
- БОЛЕЕ
- Откройте
- Навигация
- необходимо
- Новые
- следующий
- ноутбук
- сейчас
- многочисленный
- NumPy
- объект
- объекты
- препятствиями
- получать
- of
- предлагают
- предлагающий
- старший
- on
- ONE
- на
- открытый
- открытие
- or
- оригинал
- первоначально
- Другое
- внешний
- выходной
- за
- общий
- принадлежащих
- пакет
- пакеты
- часть
- особенно
- части
- pass
- мимо
- Люди
- выполнять
- выполняет
- картина
- трубопровод
- Pixel
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Играть
- пунктов
- возможности,
- потенциал
- мощный
- практическое
- необходимость
- предсказывать
- предсказанный
- прогнозирования
- прогноз
- Predictions
- подготовка
- Проблема
- обработка
- обеспечивать
- при условии
- приводит
- опубликованный
- целей
- ассортимент
- Сырье
- реальные
- реальный мир
- реалистичный
- Реальность
- признавая
- уменьшить
- районы
- регулярный
- Отношения
- складская
- хранилище
- Запросы
- Постановления
- в результате
- Дорога
- робототехника
- Роботы
- Роли
- безопасно
- то же
- Шкала
- сцена
- Сцены
- Наука
- посмотреть
- самостоятельное вождение
- датчик
- несколько
- показанный
- значительный
- аналогичный
- Размер
- небольшой
- некоторые
- Space
- пролет
- особый
- конкретно
- Начало
- Шаг
- магазин
- сильные
- сильный
- такие
- РЕЗЮМЕ
- Сложность задачи
- задачи
- снижения вреда
- Технологии
- который
- Ассоциация
- их
- Их
- тогда
- Эти
- они
- вещи
- этой
- трехмерный
- Через
- в
- вместе
- инструменты
- факел
- традиционный
- трансформатор
- трансформеры
- напишите
- понимать
- понимание
- созданного
- URL
- us
- Применение
- использование
- используемый
- использования
- через
- Использующий
- ценный
- Наши ценности
- различный
- очень
- Виртуальный
- видение
- визуализация
- визуализации
- законопроект
- we
- WebP
- были
- Что
- , которые
- в то время как
- все
- зачем
- будете
- в
- Работа
- работать вместе
- Мир
- зефирнет