Введение
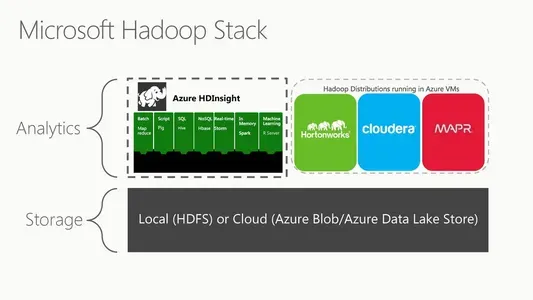
Microsoft Azure HDInsight (или Microsoft HDFS) — это облачная версия распределенной файловой системы Hadoop. Распределенная файловая система работает на общедоступном оборудовании и управляет массивными коллекциями данных. Это полностью управляемая облачная среда для анализа и обработки огромных объемов данных. HDInsight без проблем работает с экосистемой Hadoop, которая включает в себя такие технологии, как MapReduce, Hive, Pig и Spark. Он также совместим с мощными технологиями обработки данных Microsoft, такими как Azure Data Lake Storage и Azure Blob Storage.
Масштабируемость — одна из важнейших характеристик HDInsight. Microsoft Azure HDInsight также имеет функции безопасности корпоративного уровня, включая управление доступом на основе ролей, шифрование и сетевую изоляцию. HDInsight легко интегрируется с другими облачными службами Microsoft, включая Power BI, Azure Stream Analytics и Azure Data Factory. Наконец, это полностью управляемая облачная служба, что означает, что Microsoft несет ответственность за базовую инфраструктуру, обслуживание и обновления.
Цели обучения
- Мы рассмотрим Microsoft HDFS и то, как она работает в контексте важных данных.
- Понимание того, как использовать Azure HDInsight в облаке для обработки и анализа огромных объемов данных.
- Мы рассмотрим инструменты Hadoop, такие как MapReduce, Hive и Spark, и способы их использования с HDInsight.
- Вы также узнаете о функциях различных узлов в HDInsight.
Эта статья была опубликована в рамках Блогатон по Data Science.
Содержание
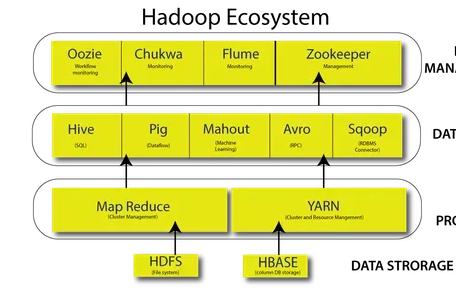
Azure HDInsight — это полностью управляемое облачное решение, в котором используются важные технологии обработки данных, такие как Apache Hadoop и Apache Spark. Это облачная реализация Hadoop для обработки и анализа массивных данных в распределенной системе. Hadoop — это свободно доступная программная среда для обмена огромными наборами данных между вычислительными узлами. Он играет решающую роль в общей инфраструктуре Hadoop. Это распределенная файловая система, которая хранит данные приложений на недорогих стандартных серверах в нескольких местах, что делает их доступными на высоких скоростях. Архитектура HDFS master/slave гарантирует, что даже самые большие наборы данных могут храниться и управляться без потери целостности или производительности.
Распределенной файловой системой HDInsight является HDFS. Когда пользователи отправляют задачи в HDInsight, данные автоматически распределяются между узлами кластера и сохраняются в HDFS. HDInsight также включает другие компоненты экосистемы Hadoop, такие как MapReduce, Hive, Pig и Spark, для обработки и анализа данных в HDFS. HDInsight — это облачная платформа, которая позволяет клиентам использовать возможности Hadoop и продуктов его экосистемы, не требуя управления базовой инфраструктурой. Он использует HDFS в качестве своей файловой системы для облегчения распределенного хранения и обработки данных.
Источник: hkrtrainings.com
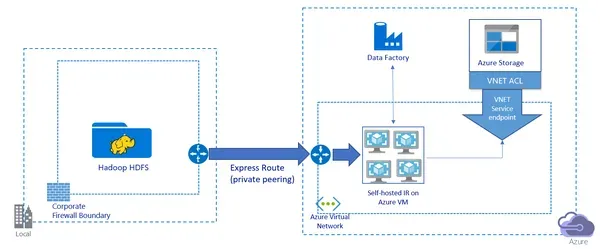
Q2. Как Microsoft Azure Data Lake Storage 2-го поколения работает с HDFS?
Хранилище озера данных Microsoft Azure Gen2 — это облачное хранилище с иерархической файловой системой для хранения и анализа больших объемов данных. Он предназначен для взаимодействия с большими платформами обработки данных, такими как Hadoop и Spark, и плавно взаимодействует с HDFS. Azure Data Lake Storage 2-го поколения включает интерфейс файловой системы, совместимой с Hadoop (HCFS), что позволяет Hadoop и другим инструментам обработки больших данных получать доступ к данным в Data Lake Storage 2-го поколения, как если бы они находились в HDFS. Клиенты могут обрабатывать и анализировать данные, хранящиеся в Data Lake Storage Gen2, с помощью своих существующих инструментов и приложений Hadoop.
Когда задания Hadoop выполняются в HDInsight, данные автоматически распределяются по узлам в кластере и сохраняются в HDFS. Однако Azure Data Lake Storage 2-го поколения может хранить данные непосредственно в учетной записи хранения без создания коллекции HDInsight. Затем к этим данным можно получить доступ с помощью интерфейса HCFS, который обеспечивает ту же функциональность, что и HDFS. Azure Data Lake Storage 2-го поколения также предлагает расширенные функции, такие как интеграция с хранилищем BLOB-объектов Azure, интеграция с Azure Active Directory и функции безопасности корпоративного уровня, такие как управление доступом на основе ролей и шифрование. В целом, Data Lake Storage 2-го поколения представляет собой масштабируемое и безопасное решение для хранения данных, предназначенное для обработки и анализа больших данных, которое легко интегрируется с Hadoop и HDFS.
Q3. Можете ли вы объяснить роль NameNode и DataNode в HDFS?
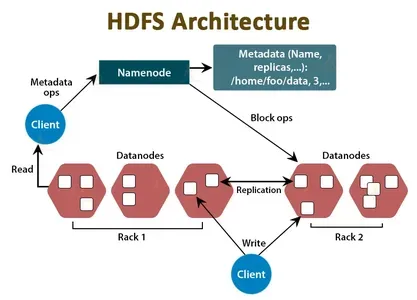
Компоненты NameNode и DataNode HDFS создают распределенную среду хранения и обработки для массивных наборов данных. Вот как они работают:
- Имя Узел: NameNode служит центральным координатором кластера HDFS и хранилищем метаданных. Он поддерживает информацию о расположении файлов, иерархии и свойствах файлов и каталогов. NameNode хранит эту информацию в памяти и на диске и отвечает за управление доступом к данным HDFS. Когда клиентскому приложению необходимо прочитать или записать данные из HDFS, оно сначала обращается к NameNode, чтобы получить расположение данных и другую информацию.
- Узел данных: DataNode — рабочая лошадка HDFS. Он отвечает за хранение блоков данных, составляющих файлы в HDFS. Каждый узел данных управляет хранилищем для подмножества данных в кластере HDFS и дублирует данные на другие узлы данных для обеспечения избыточности и отказоустойчивости. Когда клиентскому приложению необходимо прочитать или записать данные, оно напрямую взаимодействует с узлами данных, которые содержат блоки данных.
Таким образом, NameNode и DataNode совместно создают распределенную файловую систему, способную хранить и обрабатывать массивные наборы данных. NameNode обрабатывает информацию о файле, тогда как DataNode содержит фактические блоки данных. Для обеспечения избыточности данных, отказоустойчивости и быстрого извлечения данных узлы NameNode и DataNode взаимодействуют друг с другом.
Q4. Как HDFS обеспечивает надежность данных и отказоустойчивость?
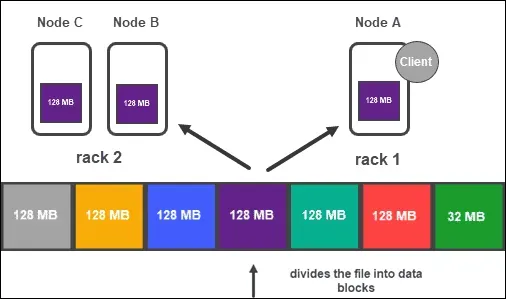
Он предназначен для обеспечения отказоустойчивого хранилища для массивных наборов данных. Это достигается за счет дублирования данных на нескольких узлах кластера, обнаружения и устранения сбоев, а также поддержания надежности и точности хранения данных. HDFS обеспечивает надежность данных и отказоустойчивость следующими способами:
- Он хранит данные в блоках, дублированных на нескольких узлах данных в кластере. Каждый блок по умолчанию реплицируется три раза, хотя это может быть изменено в зависимости от потребностей приложения. Репликация данных по нескольким узлам гарантирует доступность данных на других узлах даже в случае сбоя одного или нескольких узлов.
- Обнаружение сбоев и восстановление: HDFS постоянно проверяет работоспособность узлов данных кластера. Всякий раз, когда DataNode дает сбой или перестает отвечать на запросы, NameNode замечает сбой и дублирует данные отказавшего узла на другие узлы в кластере. Затем NameNode обновляет метаданные, чтобы отразить новые местоположения реплицированных блоков данных.
- Непротиворечивость данных. Используя архитектуру однократной записи и многократного чтения (WORM), HDFS обеспечивает надежное и точное сохранение данных. Данные, которые были записаны в HDFS, не могут быть изменены. Это гарантирует, что непротиворечивость данных сохраняется даже при одновременном доступе к одним и тем же данным нескольких клиентов.
- Размещение блоков. Чтобы гарантировать размещение блоков данных в разных стойках в кластере, HDFS использует стратегию размещения с учетом стоек. Это гарантирует, что даже в случае сбоя всего кадра данные по-прежнему будут доступны на других стойках кластера.
В целом, за счет дублирования данных на нескольких узлах, обнаружения и восстановления после сбоев, обеспечения согласованности данных и использования политики размещения с учетом стойки для сокращения потерь данных из-за сбоев стойки HDFS обеспечивает надежное и отказоустойчивое решение для хранения больших наборов данных.
Q5. Можете ли вы описать, что такое роли NameNode и DataNode в HDFS?
HDFS — это распределенная файловая система, которая хранит и обрабатывает массивные наборы данных на общедоступном оборудовании в кластере. Как объяснялось в предыдущем вопросе, архитектура HDFS включает два ключевых компонента: NameNode и DataNode. Чтобы обеспечить надежность данных и отказоустойчивость, NameNode и DataNodes взаимодействуют. Когда клиенту необходимо прочитать или записать данные из HDFS, он взаимодействует с NameNode, чтобы найти блоки данных. Затем клиент напрямую обсуждает с узлами данных чтение или запись блоков данных.
MapReduce, инфраструктура распределенной обработки данных, часто сочетается с HDFS. MapReduce предназначен для обработки больших наборов данных путем их разделения на более мелкие части, распределения обработки этих частей по кластеру процессоров и агрегирования результатов. Вот как MapReduce взаимодействует с HDFS:
- Входные данные сохраняются в HDFS. MapReduce получает входные данные от HDFS и делит их на более мелкие фрагменты, называемые входными разбиениями.
- Входные разбиения распределяются по кластеру и назначаются определенным заданиям Map с помощью MapReduce. Каждое задание Map обрабатывает одно разделение входных данных и создает промежуточные пары ключ-значение.
- Затем промежуточные пары ключ-значение сортируются и перемешиваются перед отправкой на задания сокращения. Каждое задание Reduce собирает промежуточные входные данные и генерирует окончательный результат.
- Окончательный результат сохраняется в HDFS.
В целом, HDFS и MapReduce совместно создают масштабируемую отказоустойчивую архитектуру для обработки массивных наборов данных. Он предлагает надежное хранилище для входных и выходных данных, тогда как MapReduce распределяет обработку данных по всему кластеру.
Q6. Чем HDFS отличается от других файловых систем и каковы преимущества использования HDFS в среде с огромным объемом данных?
HDFS отличается от стандартных файловых систем во многих важных областях, и эти различия дают несколько преимуществ при работе с огромными объемами данных. Вот некоторые важные отличия и преимущества использования HDFS в среде больших данных:
- Масштабируемость. Обычные файловые системы не предназначены для управления огромными объемами данных, которые часто возникают в ситуациях с большими данными. Он предназначен для горизонтального роста, что означает, что он может вместить петабайты или даже эксабайты данных для хранения и обработки, распределяя данные по кластеру стандартного оборудования.
- Отказоустойчивость: он построен, чтобы быть отказоустойчивым. Он может выдержать сбой отдельных узлов в кластере за счет дублирования данных на нескольких узлах в кластере. Он также имеет методы автоматического обнаружения и восстановления после сбоев узлов.
- Он предназначен для обеспечения высокой пропускной способности как для чтения, так и для записи данных. При работе с огромными файлами HDFS может достигать высоких скоростей чтения и записи, поскольку она специализируется на передаче больших объемов данных.
- Локальность данных: он предназначен для максимальной локальности данных, что означает, что данные хранятся и обрабатываются на одних и тех же узлах кластера, где это возможно. Сокращение передачи данных по сети сводит к минимуму сетевой трафик и повышает производительность.
- Экономическая эффективность: поскольку он предназначен для работы на обычном оборудовании, его можно реализовать на недорогих серверах или в облаке. В результате он обеспечивает недорогой вариант для хранения и обработки больших объемов данных.
В целом преимуществами использования HDFS в контексте больших данных являются масштабируемость, отказоустойчивость, высокая пропускная способность, локализация данных и экономичность. Используя эти функции, организации могут хранить, управлять и анализировать массивные наборы данных более эффективно и экономично, чем традиционные файловые системы.
Заключение
В этой статье мы рассмотрели различные функции Microsoft HDFS, включая ее введение, архитектуру, работу с Azure Data Lake Storage 2-го поколения и ее функции в MapReduce. Мы также ответили на общие вопросы интервью в Amazon и Microsoft. Это важно для приложений больших данных, поскольку обеспечивает масштабируемое и отказоустойчивое хранилище для массивных наборов данных. Понимание конструкции и эксплуатации необходимо инженерам и разработчикам данных, работающим с решениями для больших данных.
Вот несколько основных выводов:
- Это распределенная файловая система, которая хранит и обрабатывает огромные наборы данных на обычном оборудовании в кластере.
- NameNode и DataNode — два основных компонента HDFS. NameNode хранит информацию о файловой системе, тогда как DataNode хранит фактические блоки данных, из которых состоят файлы.
- Он создан, чтобы быть чрезвычайно отказоустойчивым и обеспечивать надежное хранилище для приложений больших данных. Он может вместить петабайты или даже эксабайты данных для хранения и обработки, распределяя данные по кластеру обычных компьютеров.
- MapReduce, инфраструктура распределенной обработки данных, может использоваться в сочетании с HDFS. MapReduce делит огромные наборы данных на более мелкие биты и распределяет их обработку по кластеру процессоров.
- Наконец, Microsoft предоставляет HDInsight, облачный дистрибутив Hadoop, содержащий HDFS, MapReduce и другие компоненты.
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2023/03/top-6-microsoft-hdfs-interview-questions/
- :является
- $UP
- a
- О нас
- доступ
- Доступ
- доступной
- вмещать
- Учетная запись
- точность
- Достигать
- через
- активный
- Active Directory
- продвинутый
- Преимущества
- Позволяющий
- Несмотря на то, что
- Amazon
- среди
- суммы
- анализ
- аналитика
- Аналитика Видхья
- анализировать
- анализ
- и
- Другой
- апаш
- Apache Spark
- Применение
- Приложения
- архитектура
- МЫ
- области
- гайд
- AS
- назначенный
- At
- автоматически
- доступен
- Лазурный
- основанный
- BE
- , так как:
- становится
- до
- не являетесь
- Преимущества
- большой
- Big Data
- Заблокировать
- Блоки
- блогатон
- приносить
- построенный
- by
- под названием
- CAN
- не могу
- возможности
- способный
- центральный
- характеристика
- заряд
- Проверки
- клиент
- клиентов
- облако
- облачные сервисы
- Кластер
- сотрудничать
- лыжных шлемов
- Коллекции
- улавливается
- COM
- сочетание
- сочетании
- товар
- Общий
- совместим
- компоненты
- компьютеры
- вычисление
- заключение
- контакты
- контекст
- беспрестанно
- контроль
- обычный
- Координатор
- Создайте
- Создающий
- решающее значение
- Клиенты
- данным
- Озеро данных
- Потеря данных
- обработка данных
- хранение данных
- Наборы данных
- По умолчанию
- надежный
- описывать
- Проект
- предназначенный
- обнаружение
- застройщиков
- различный
- непосредственно
- усмотрение
- рассеянный
- отчетливый
- распределенный
- распределенная обработка данных
- распределительный
- распределение
- дубликаты
- каждый
- экосистема
- эффективно
- работает
- позволяет
- шифрование
- Инженеры
- огромный
- обеспечивать
- обеспечивает
- корпоративного класса
- корпоративного уровня
- Весь
- Окружающая среда
- существенный
- Даже
- точно,
- существующий
- Объяснять
- объяснены
- чрезвычайно
- содействовал
- завод
- Oшибка
- не удается
- Ошибка
- БЫСТРО
- выполнимый
- Особенности
- Файл
- Файлы
- окончательный
- в заключение
- Найдите
- Во-первых,
- после
- Что касается
- КАДР
- Рамки
- частое
- часто
- от
- полностью
- функция
- функциональность
- Функции
- фундаментальный
- генерирует
- Расти
- гарантия
- гарантии
- Hadoop
- обрабатывать
- Ручки
- Аппаратные средства
- Есть
- Медицина
- здесь
- иерархия
- High
- Hive
- держать
- Как
- How To
- Однако
- HTTPS
- огромный
- реализация
- в XNUMX году
- важную
- in
- включает в себя
- В том числе
- Увеличивает
- individual
- недорогой
- информация
- Инфраструктура
- вход
- Интегрируется
- интеграции.
- целостность
- взаимодействовать
- взаимодействует
- Интерфейс
- интерфейсы
- Intermediate
- Интервью
- вопросы интервью
- Введение
- изоляция
- IT
- ЕГО
- работа
- Джобс
- Основные
- озеро
- большой
- УЧИТЬСЯ
- Кредитное плечо
- такое как
- Локализация
- расположение
- места
- от
- бюджетный
- поддерживает
- техническое обслуживание
- сделать
- ДЕЛАЕТ
- Создание
- управлять
- управляемого
- управление
- управляет
- управления
- карта
- массивный
- Максимизировать
- означает
- Медиа
- Память
- Метаданные
- Microsoft
- Microsoft Azure
- БОЛЕЕ
- самых
- навигационный
- потребности
- сеть
- сетевой трафик
- Новые
- узел
- узлы
- многочисленный
- of
- предлагают
- Предложения
- on
- ONE
- операция
- Опция
- организации
- Другое
- общий
- принадлежащих
- пар
- часть
- производительность
- штук
- Платформа
- Платформы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- пунктов
- политика
- мощностью
- Power BI
- мощный
- Точно
- обработка
- процессоры
- производит
- Продукция
- свойства
- обеспечивать
- приводит
- опубликованный
- Q2
- Q3
- вопрос
- Вопросы
- быстро
- Стоимость
- Читать
- Reading
- получает
- Я выздоровела
- выздоровление
- уменьшить
- снижение
- отражать
- Связанный
- отношения
- надежность
- реплицируются
- копирование
- ответственный
- результат
- Итоги
- обзоре
- Роли
- роли
- Run
- Бег
- то же
- Масштабируемость
- масштабируемые
- Наука
- легко
- безопасный
- безопасность
- Серверы
- служит
- обслуживание
- Услуги
- несколько
- разделение
- показанный
- значительный
- одновременно
- с
- одинарной
- обстоятельства
- меньше
- плавно
- Software
- Решение
- Решения
- некоторые
- Источник
- Искриться
- специализированный
- конкретный
- скорость
- раскол
- расколы
- Распространение
- Спреды
- стандарт
- По-прежнему
- диск
- магазин
- хранить
- магазины
- Стратегия
- поток
- отправить
- такие
- РЕЗЮМЕ
- система
- системы
- переговоры
- задачи
- снижения вреда
- технологии
- который
- Ассоциация
- их
- Их
- Эти
- три
- Через
- по всему
- пропускная способность
- раз
- в
- терпимость
- инструменты
- топ
- традиционный
- трафик
- переводы
- транзит
- лежащий в основе
- понимание
- Updates
- обновления
- пользователей
- использовать
- использовать
- Использующий
- версия
- тома
- способы
- Что
- , которые
- в то время как
- будете
- без
- Работа
- работает
- работает
- червь
- записывать
- письмо
- письменный
- зефирнет