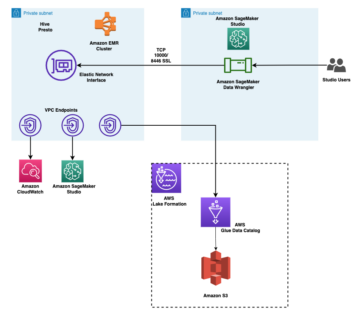
Implement fine-grained access control in Amazon SageMaker Studio and Amazon EMR using Apache Ranger and Microsoft Active Directory | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2374800Time Stamp: Nov 8, 2023
Introducing Amazon MWAA support for Apache Airflow version 2.7.2 and deferrable operators | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2369844Time Stamp: Nov 6, 2023
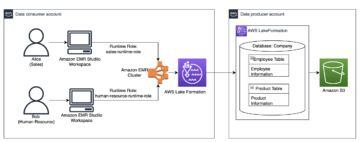
Use IAM runtime roles with Amazon EMR Studio Workspaces and AWS Lake Formation for cross-account fine-grained access control | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2369846Time Stamp: Nov 6, 2023
GoDaddy benchmarking results in up to 24% better price-performance for their Spark workloads with AWS Graviton2 on Amazon EMR Serverless | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2362245Time Stamp: Nov 2, 2023
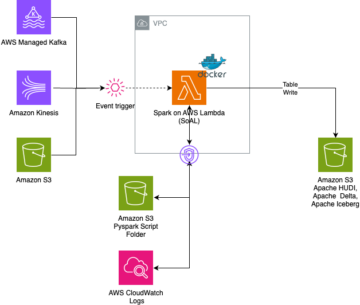
Spark on AWS Lambda: An Apache Spark runtime for AWS Lambda | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2357332Time Stamp: Oct 30, 2023
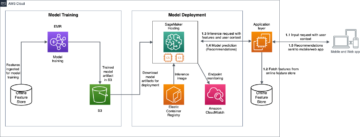
How Meesho built a generalized feed ranker using Amazon SageMaker inference | Amazon Web Services Source Cluster: AWS Machine Learning Source Node: 2339746Time Stamp: Oct 20, 2023
Run Apache Hive workloads using Spark SQL with Amazon EMR on EKS | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2340178Time Stamp: Oct 18, 2023
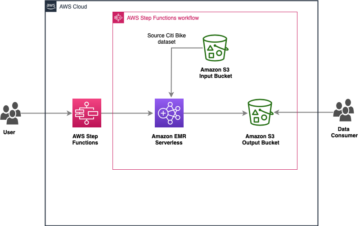
Orchestrate Amazon EMR Serverless jobs with AWS Step functions | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2324264Time Stamp: Oct 12, 2023
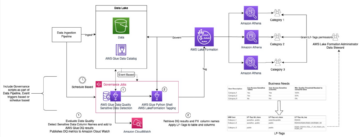
Automated data governance with AWS Glue Data Quality, sensitive data detection, and AWS Lake Formation | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2320824Time Stamp: Oct 10, 2023
Define per-team resource limits for big data workloads using Amazon EMR Serverless | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2311517Time Stamp: Oct 5, 2023
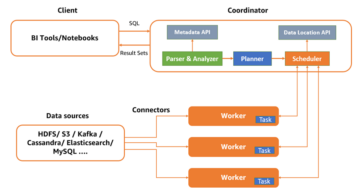
Query big data with resilience using Trino in Amazon EMR with Amazon EC2 Spot Instances for less cost | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2313028Time Stamp: Oct 4, 2023
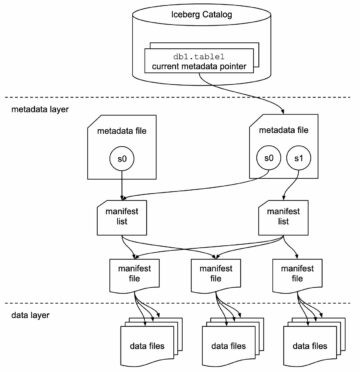
Apache Iceberg optimization: Solving the small files problem in Amazon EMR | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2306630Time Stamp: Oct 3, 2023
Non-JSON ingestion using Amazon Kinesis Data Streams, Amazon MSK, and Amazon Redshift Streaming Ingestion | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2304857Time Stamp: Oct 2, 2023
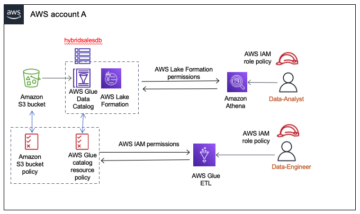
Introducing hybrid access mode for AWS Glue Data Catalog to secure access using AWS Lake Formation and IAM and Amazon S3 policies | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2293765Time Stamp: Sep 26, 2023
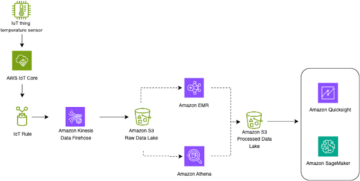
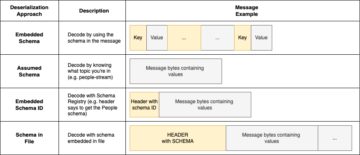
Top 20 Data Engineering Project Ideas [With Source Code] Source Cluster: Analytics Vidhya Source Node: 2282415Time Stamp: Sep 20, 2023
Capacity Management and Amazon EMR Managed Scaling improvements for Amazon EMR on EC2 clusters | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2259056Time Stamp: Sep 7, 2023
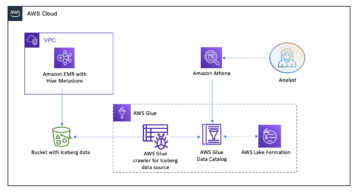
Query your Iceberg tables in data lake using Amazon Redshift (Preview) | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2246746Time Stamp: Aug 31, 2023
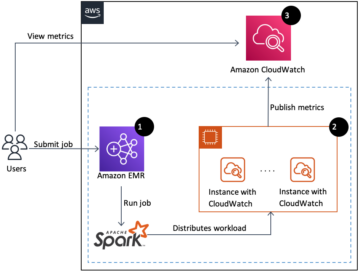
Monitor Apache Spark applications on Amazon EMR with Amazon Cloudwatch | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2243862Time Stamp: Aug 30, 2023
Apply fine-grained data access controls with AWS Lake Formation in Amazon SageMaker Data Wrangler | Amazon Web Services Source Cluster: AWS Machine Learning Source Node: 2226617Time Stamp: Aug 21, 2023
Introducing AWS Glue crawler and create table support for Apache Iceberg format | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2217245Time Stamp: Aug 16, 2023



![Top 20 Data Engineering Project Ideas [With Source Code]](https://platoaistream.net/wp-content/uploads/2023/09/top-20-data-engineering-project-ideas-with-source-code-64-360x225.png)