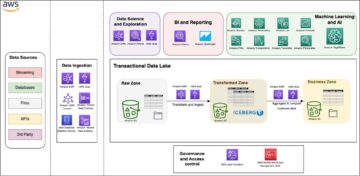
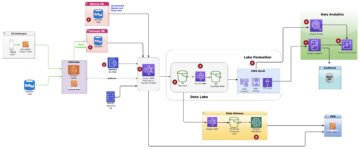
Build a serverless transactional data lake with Apache Iceberg, Amazon EMR Serverless, and Amazon Athena Source Cluster: AWS Big Data Source Node: 2003350Time Stamp: Mar 10, 2023
Top 6 Amazon S3 Interview Questions Source Cluster: Analytics Vidhya Source Node: 1995232Time Stamp: Mar 5, 2023
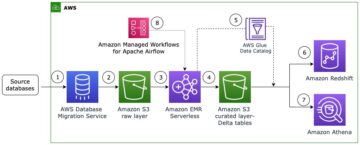
Build incremental data pipelines to load transactional data changes using AWS DMS, Delta 2.0, and Amazon EMR Serverless Source Cluster: AWS Big Data Source Node: 1990644Time Stamp: Mar 3, 2023
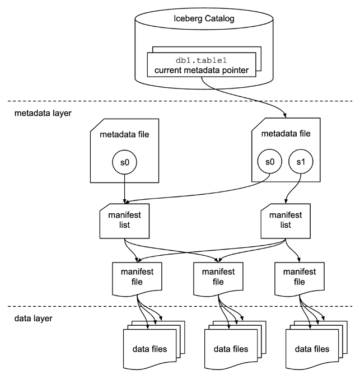
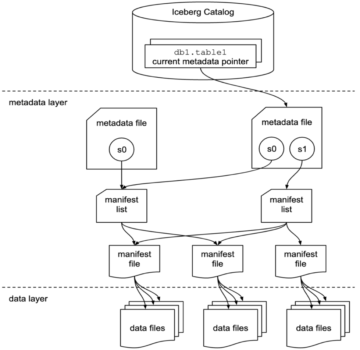
Use Apache Iceberg in a data lake to support incremental data processing Source Cluster: AWS Big Data Source Node: 1988910Time Stamp: Mar 2, 2023
Reduce Amazon EMR cluster costs by up to 19% with new enhancements in Amazon EMR Managed Scaling Source Cluster: AWS Big Data Source Node: 1985656Time Stamp: Feb 28, 2023
How SafeGraph built a reliable, efficient, and user-friendly Apache Spark platform with Amazon EMR on Amazon EKS Source Cluster: AWS Big Data Source Node: 1972501Time Stamp: Feb 21, 2023
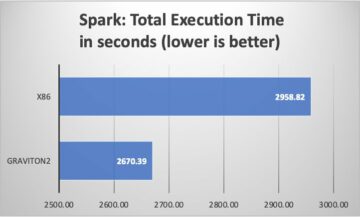
Achieve up to 27% better price-performance for Spark workloads with AWS Graviton2 on Amazon EMR Serverless Source Cluster: AWS Big Data Source Node: 1960090Time Stamp: Feb 15, 2023
Amazon EMR Serverless supports larger worker sizes to run more compute and memory-intensive workloads Source Cluster: AWS Big Data Source Node: 1960092Time Stamp: Feb 15, 2023
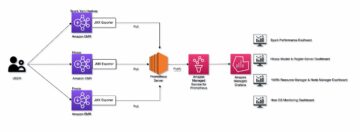
Monitor Apache HBase on Amazon EMR using Amazon Managed Service for Prometheus and Amazon Managed Grafana Source Cluster: AWS Big Data Source Node: 1956703Time Stamp: Feb 13, 2023
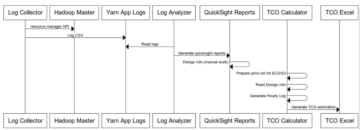
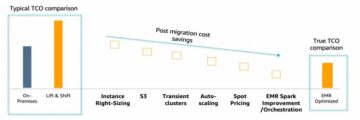
Deep dive into the AWS ProServe Hadoop Migration Delivery Kit TCO tool Source Cluster: AWS Big Data Source Node: 1941984Time Stamp: Feb 6, 2023
Introducing the AWS ProServe Hadoop Migration Delivery Kit TCO tool Source Cluster: AWS Big Data Source Node: 1941986Time Stamp: Feb 6, 2023
How Amazon Devices scaled and optimized real-time demand and supply forecasts using serverless analytics Source Cluster: AWS Big Data Source Node: 1934446Time Stamp: Feb 1, 2023
Amazon EMR launches support for Amazon EC2 C7g (Graviton3) instances to improve cost performance for Spark workloads by 7–13% Source Cluster: AWS Big Data Source Node: 1932903Time Stamp: Feb 1, 2023
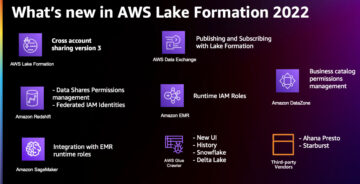
AWS Lake Formation 2022 year in review Source Cluster: AWS Big Data Source Node: 1932905Time Stamp: Jan 31, 2023
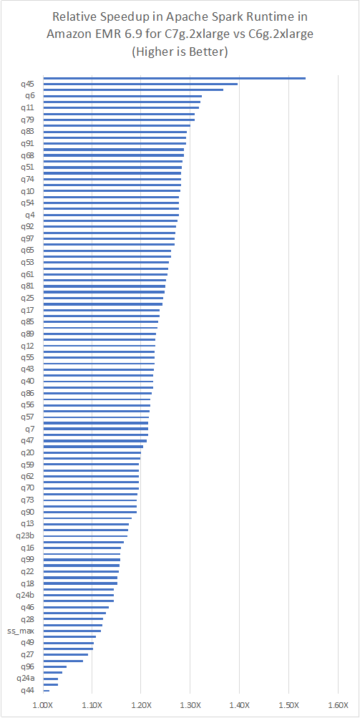
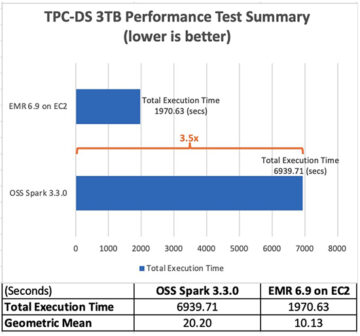
Run Apache Spark workloads 3.5 times faster with Amazon EMR 6.9 Source Cluster: AWS Big Data Source Node: 1929685Time Stamp: Jan 30, 2023
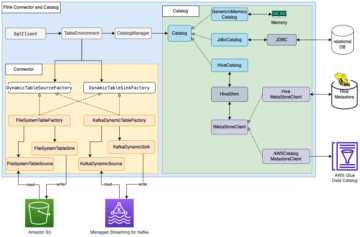
Build a data lake with Apache Flink on Amazon EMR Source Cluster: AWS Big Data Source Node: 1924440Time Stamp: Jan 27, 2023
What’s new in Amazon Redshift – 2022, a year in review Source Cluster: AWS Big Data Source Node: 1906678Time Stamp: Jan 19, 2023
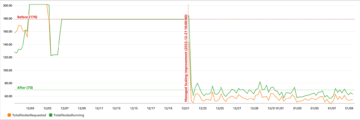
Improve the performance of Apache Iceberg’s metadata file operations using Amazon FSx for Lustre on Amazon EMR Source Cluster: AWS Big Data Source Node: 1893480Time Stamp: Jan 12, 2023
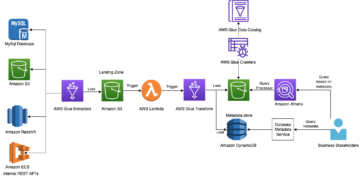
How BookMyShow saved 80% in costs by migrating to an AWS modern data architecture Source Cluster: AWS Big Data Source Node: 1891867Time Stamp: Jan 11, 2023
Add your own libraries and application dependencies to Spark and Hive on Amazon EMR Serverless with custom images Source Cluster: AWS Big Data Source Node: 1888705Time Stamp: Jan 10, 2023